 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGENMANIP: LLM-driven Simulation for Generalizable Instruction-Following Manipulation
Jun 12, 2025



Robotic manipulation in real-world settings remains challenging, especially regarding robust generalization. Existing simulation platforms lack sufficient support for exploring how policies adapt to varied instructions and scenarios. Thus, they lag behind the growing interest in instruction-following foundation models like LLMs, whose adaptability is crucial yet remains underexplored in fair comparisons. To bridge this gap, we introduce GenManip, a realistic tabletop simulation platform tailored for policy generalization studies. It features an automatic pipeline via LLM-driven task-oriented scene graph to synthesize large-scale, diverse tasks using 10K annotated 3D object assets. To systematically assess generalization, we present GenManip-Bench, a benchmark of 200 scenarios refined via human-in-the-loop corrections. We evaluate two policy types: (1) modular manipulation systems integrating foundation models for perception, reasoning, and planning, and (2) end-to-end policies trained through scalable data collection. Results show that while data scaling benefits end-to-end methods, modular systems enhanced with foundation models generalize more effectively across diverse scenarios. We anticipate this platform to facilitate critical insights for advancing policy generalization in realistic conditions. Project Page: https://genmanip.axi404.top/.
Neuromorphic Sequential Arena: A Benchmark for Neuromorphic Temporal Processing
May 28, 2025Temporal processing is vital for extracting meaningful information from time-varying signals. Recent advancements in Spiking Neural Networks (SNNs) have shown immense promise in efficiently processing these signals. However, progress in this field has been impeded by the lack of effective and standardized benchmarks, which complicates the consistent measurement of technological advancements and limits the practical applicability of SNNs. To bridge this gap, we introduce the Neuromorphic Sequential Arena (NSA), a comprehensive benchmark that offers an effective, versatile, and application-oriented evaluation framework for neuromorphic temporal processing. The NSA includes seven real-world temporal processing tasks from a diverse range of application scenarios, each capturing rich temporal dynamics across multiple timescales. Utilizing NSA, we conduct extensive comparisons of recently introduced spiking neuron models and neural architectures, presenting comprehensive baselines in terms of task performance, training speed, memory usage, and energy efficiency. Our findings emphasize an urgent need for efficient SNN designs that can consistently deliver high performance across tasks with varying temporal complexities while maintaining low computational costs. NSA enables systematic tracking of advancements in neuromorphic algorithm research and paves the way for developing effective and efficient neuromorphic temporal processing systems.
Active Contact Engagement for Aerial Navigation in Unknown Environments with Glass
May 01, 2025Autonomous aerial robots are increasingly being deployed in real-world scenarios, where transparent glass obstacles present significant challenges to reliable navigation. Researchers have investigated the use of non-contact sensors and passive contact-resilient aerial vehicle designs to detect glass surfaces, which are often limited in terms of robustness and efficiency. In this work, we propose a novel approach for robust autonomous aerial navigation in unknown environments with transparent glass obstacles, combining the strengths of both sensor-based and contact-based glass detection. The proposed system begins with the incremental detection and information maintenance about potential glass surfaces using visual sensor measurements. The vehicle then actively engages in touch actions with the visually detected potential glass surfaces using a pair of lightweight contact-sensing modules to confirm or invalidate their presence. Following this, the volumetric map is efficiently updated with the glass surface information and safe trajectories are replanned on the fly to circumvent the glass obstacles. We validate the proposed system through real-world experiments in various scenarios, demonstrating its effectiveness in enabling efficient and robust autonomous aerial navigation in complex real-world environments with glass obstacles.
RoboGround: Robotic Manipulation with Grounded Vision-Language Priors
Apr 30, 2025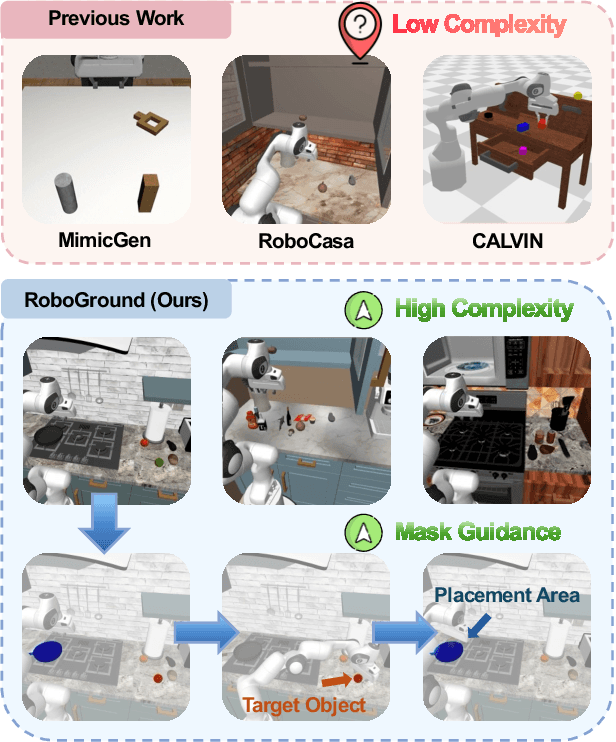

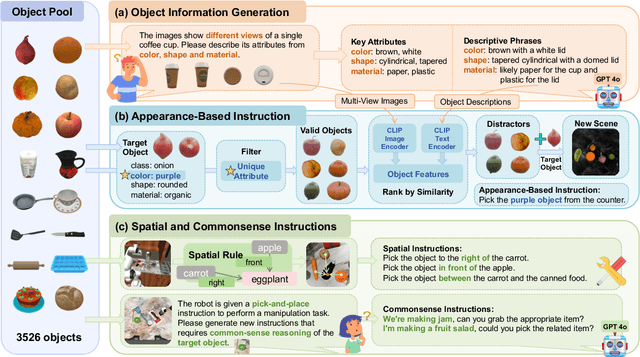
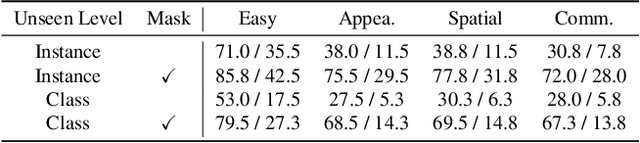
Recent advancements in robotic manipulation have highlighted the potential of intermediate representations for improving policy generalization. In this work, we explore grounding masks as an effective intermediate representation, balancing two key advantages: (1) effective spatial guidance that specifies target objects and placement areas while also conveying information about object shape and size, and (2) broad generalization potential driven by large-scale vision-language models pretrained on diverse grounding datasets. We introduce RoboGround, a grounding-aware robotic manipulation system that leverages grounding masks as an intermediate representation to guide policy networks in object manipulation tasks. To further explore and enhance generalization, we propose an automated pipeline for generating large-scale, simulated data with a diverse set of objects and instructions. Extensive experiments show the value of our dataset and the effectiveness of grounding masks as intermediate guidance, significantly enhancing the generalization abilities of robot policies.
Spiking Neural Networks for Temporal Processing: Status Quo and Future Prospects
Feb 13, 2025



Temporal processing is fundamental for both biological and artificial intelligence systems, as it enables the comprehension of dynamic environments and facilitates timely responses. Spiking Neural Networks (SNNs) excel in handling such data with high efficiency, owing to their rich neuronal dynamics and sparse activity patterns. Given the recent surge in the development of SNNs, there is an urgent need for a comprehensive evaluation of their temporal processing capabilities. In this paper, we first conduct an in-depth assessment of commonly used neuromorphic benchmarks, revealing critical limitations in their ability to evaluate the temporal processing capabilities of SNNs. To bridge this gap, we further introduce a benchmark suite consisting of three temporal processing tasks characterized by rich temporal dynamics across multiple timescales. Utilizing this benchmark suite, we perform a thorough evaluation of recently introduced SNN approaches to elucidate the current status of SNNs in temporal processing. Our findings indicate significant advancements in recently developed spiking neuron models and neural architectures regarding their temporal processing capabilities, while also highlighting a performance gap in handling long-range dependencies when compared to state-of-the-art non-spiking models. Finally, we discuss the key challenges and outline potential avenues for future research.
Leveraging LLM Agents for Translating Network Configurations
Jan 15, 2025Configuration translation is a critical and frequent task in network operations. When a network device is damaged or outdated, administrators need to replace it to maintain service continuity. The replacement devices may originate from different vendors, necessitating configuration translation to ensure seamless network operation. However, translating configurations manually is a labor-intensive and error-prone process. In this paper, we propose an intent-based framework for translating network configuration with Large Language Model (LLM) Agents. The core of our approach is an Intent-based Retrieval Augmented Generation (IRAG) module that systematically splits a configuration file into fragments, extracts intents, and generates accurate translations. We also design a two-stage verification method to validate the syntax and semantics correctness of the translated configurations. We implement and evaluate the proposed method on real-world network configurations. Experimental results show that our method achieves 97.74% syntax correctness, outperforming state-of-the-art methods in translation accuracy.
Neural Reflectance Fields for Radio-Frequency Ray Tracing
Jan 05, 2025Ray tracing is widely employed to model the propagation of radio-frequency (RF) signal in complex environment. The modelling performance greatly depends on how accurately the target scene can be depicted, including the scene geometry and surface material properties. The advances in computer vision and LiDAR make scene geometry estimation increasingly accurate, but there still lacks scalable and efficient approaches to estimate the material reflectivity in real-world environment. In this work, we tackle this problem by learning the material reflectivity efficiently from the path loss of the RF signal from the transmitters to receivers. Specifically, we want the learned material reflection coefficients to minimize the gap between the predicted and measured powers of the receivers. We achieve this by translating the neural reflectance field from optics to RF domain by modelling both the amplitude and phase of RF signals to account for the multipath effects. We further propose a differentiable RF ray tracing framework that optimizes the neural reflectance field to match the signal strength measurements. We simulate a complex real-world environment for experiments and our simulation results show that the neural reflectance field can successfully learn the reflection coefficients for all incident angles. As a result, our approach achieves better accuracy in predicting the powers of receivers with significantly less training data compared to existing approaches.
S3TU-Net: Structured Convolution and Superpixel Transformer for Lung Nodule Segmentation
Nov 19, 2024



The irregular and challenging characteristics of lung adenocarcinoma nodules in computed tomography (CT) images complicate staging diagnosis, making accurate segmentation critical for clinicians to extract detailed lesion information. In this study, we propose a segmentation model, S3TU-Net, which integrates multi-dimensional spatial connectors and a superpixel-based visual transformer. S3TU-Net is built on a multi-view CNN-Transformer hybrid architecture, incorporating superpixel algorithms, structured weighting, and spatial shifting techniques to achieve superior segmentation performance. The model leverages structured convolution blocks (DWF-Conv/D2BR-Conv) to extract multi-scale local features while mitigating overfitting. To enhance multi-scale feature fusion, we introduce the S2-MLP Link, integrating spatial shifting and attention mechanisms at the skip connections. Additionally, the residual-based superpixel visual transformer (RM-SViT) effectively merges global and local features by employing sparse correlation learning and multi-branch attention to capture long-range dependencies, with residual connections enhancing stability and computational efficiency. Experimental results on the LIDC-IDRI dataset demonstrate that S3TU-Net achieves a DSC, precision, and IoU of 89.04%, 90.73%, and 90.70%, respectively. Compared to recent methods, S3TU-Net improves DSC by 4.52% and sensitivity by 3.16%, with other metrics showing an approximate 2% increase. In addition to comparison and ablation studies, we validated the generalization ability of our model on the EPDB private dataset, achieving a DSC of 86.40%.
Provable Length Generalization in Sequence Prediction via Spectral Filtering
Nov 01, 2024



We consider the problem of length generalization in sequence prediction. We define a new metric of performance in this setting -- the Asymmetric-Regret -- which measures regret against a benchmark predictor with longer context length than available to the learner. We continue by studying this concept through the lens of the spectral filtering algorithm. We present a gradient-based learning algorithm that provably achieves length generalization for linear dynamical systems. We conclude with proof-of-concept experiments which are consistent with our theory.
Toward Understanding In-context vs. In-weight Learning
Oct 30, 2024



It has recently been demonstrated empirically that in-context learning emerges in transformers when certain distributional properties are present in the training data, but this ability can also diminish upon further training. We provide a new theoretical understanding of these phenomena by identifying simplified distributional properties that give rise to the emergence and eventual disappearance of in-context learning. We do so by first analyzing a simplified model that uses a gating mechanism to choose between an in-weight and an in-context predictor. Through a combination of a generalization error and regret analysis we identify conditions where in-context and in-weight learning emerge. These theoretical findings are then corroborated experimentally by comparing the behaviour of a full transformer on the simplified distributions to that of the stylized model, demonstrating aligned results. We then extend the study to a full large language model, showing how fine-tuning on various collections of natural language prompts can elicit similar in-context and in-weight learning behaviour.