 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Length Generalization in Sequence Prediction via Spectral Filtering
Nov 01, 2024



We consider the problem of length generalization in sequence prediction. We define a new metric of performance in this setting -- the Asymmetric-Regret -- which measures regret against a benchmark predictor with longer context length than available to the learner. We continue by studying this concept through the lens of the spectral filtering algorithm. We present a gradient-based learning algorithm that provably achieves length generalization for linear dynamical systems. We conclude with proof-of-concept experiments which are consistent with our theory.
FutureFill: Fast Generation from Convolutional Sequence Models
Oct 02, 2024



We address the challenge of efficient auto-regressive generation in sequence prediction models by introducing FutureFill: a method for fast generation that applies to any sequence prediction algorithm based on convolutional operators. Our approach reduces the generation time requirement from linear to square root relative to the context length. Additionally, FutureFill requires a prefill cache sized only by the number of tokens generated, which is smaller than the cache requirements for standard convolutional and attention-based models. We validate our theoretical findings with experimental evidence demonstrating correctness and efficiency gains in a synthetic generation task.
Spectral State Space Models
Dec 11, 2023



This paper studies sequence modeling for prediction tasks with long range dependencies. We propose a new formulation for state space models based on learning linear dynamical systems with the spectral filtering algorithm [HSZ17]. This gives rise to a novel sequence prediction architecture we call spectral state space models. The resulting models are evaluated on synthetic dynamical systems. These evaluations support the theoretical benefits of spectral filtering for tasks requiring very long range memory.
Online Learning for Obstacle Avoidance
Jun 14, 2023



We approach the fundamental problem of obstacle avoidance for robotic systems via the lens of online learning. In contrast to prior work that either assumes worst-case realizations of uncertainty in the environment or a stationary stochastic model of uncertainty, we propose a method that is efficient to implement and provably grants instance-optimality with respect to perturbations of trajectories generated from an open-loop planner (in the sense of minimizing worst-case regret). The resulting policy adapts online to realizations of uncertainty and provably compares well with the best obstacle avoidance policy in hindsight from a rich class of policies. The method is validated in simulation on a dynamical system environment and compared to baseline open-loop planning and robust Hamilton- Jacobi reachability techniques. Further, it is implemented on a hardware example where a quadruped robot traverses a dense obstacle field and encounters input disturbances due to time delays, model uncertainty, and dynamics nonlinearities.
Benchmarking Neural Network Training Algorithms
Jun 12, 2023



Training algorithms, broadly construed, are an essential part of every deep learning pipeline. Training algorithm improvements that speed up training across a wide variety of workloads (e.g., better update rules, tuning protocols, learning rate schedules, or data selection schemes) could save time, save computational resources, and lead to better, more accurate, models. Unfortunately, as a community, we are currently unable to reliably identify training algorithm improvements, or even determine the state-of-the-art training algorithm. In this work, using concrete experiments, we argue that real progress in speeding up training requires new benchmarks that resolve three basic challenges faced by empirical comparisons of training algorithms: (1) how to decide when training is complete and precisely measure training time, (2) how to handle the sensitivity of measurements to exact workload details, and (3) how to fairly compare algorithms that require hyperparameter tuning. In order to address these challenges, we introduce a new, competitive, time-to-result benchmark using multiple workloads running on fixed hardware, the AlgoPerf: Training Algorithms benchmark. Our benchmark includes a set of workload variants that make it possible to detect benchmark submissions that are more robust to workload changes than current widely-used methods. Finally, we evaluate baseline submissions constructed using various optimizers that represent current practice, as well as other optimizers that have recently received attention in the literature. These baseline results collectively demonstrate the feasibility of our benchmark, show that non-trivial gaps between methods exist, and set a provisional state-of-the-art for future benchmark submissions to try and surpass.
Adaptive Gradient Methods at the Edge of Stability
Jul 29, 2022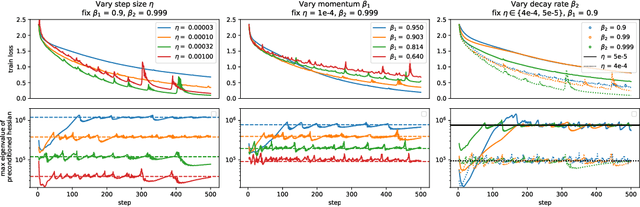
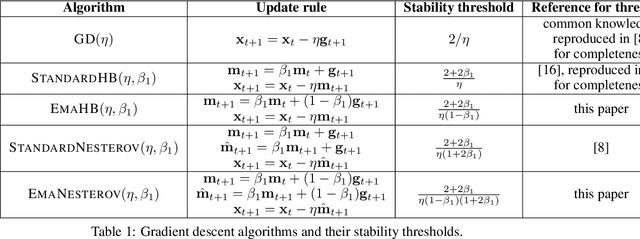
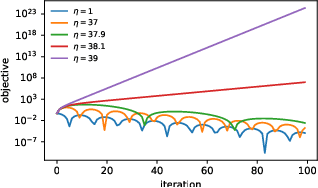

Very little is known about the training dynamics of adaptive gradient methods like Adam in deep learning. In this paper, we shed light on the behavior of these algorithms in the full-batch and sufficiently large batch settings. Specifically, we empirically demonstrate that during full-batch training, the maximum eigenvalue of the preconditioned Hessian typically equilibrates at a certain numerical value -- the stability threshold of a gradient descent algorithm. For Adam with step size $\eta$ and $\beta_1 = 0.9$, this stability threshold is $38/\eta$. Similar effects occur during minibatch training, especially as the batch size grows. Yet, even though adaptive methods train at the ``Adaptive Edge of Stability'' (AEoS), their behavior in this regime differs in a significant way from that of non-adaptive methods at the EoS. Whereas non-adaptive algorithms at the EoS are blocked from entering high-curvature regions of the loss landscape, adaptive gradient methods at the AEoS can keep advancing into high-curvature regions, while adapting the preconditioner to compensate. Our findings can serve as a foundation for the community's future understanding of adaptive gradient methods in deep learning.
Machine Learning for Mechanical Ventilation Control (Extended Abstract)
Nov 23, 2021Mechanical ventilation is one of the most widely used therapies in the ICU. However, despite broad application from anaesthesia to COVID-related life support, many injurious challenges remain. We frame these as a control problem: ventilators must let air in and out of the patient's lungs according to a prescribed trajectory of airway pressure. Industry-standard controllers, based on the PID method, are neither optimal nor robust. Our data-driven approach learns to control an invasive ventilator by training on a simulator itself trained on data collected from the ventilator. This method outperforms popular reinforcement learning algorithms and even controls the physical ventilator more accurately and robustly than PID. These results underscore how effective data-driven methodologies can be for invasive ventilation and suggest that more general forms of ventilation (e.g., non-invasive, adaptive) may also be amenable.
Machine Learning for Mechanical Ventilation Control
Feb 26, 2021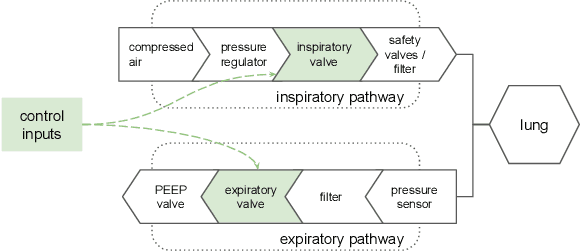
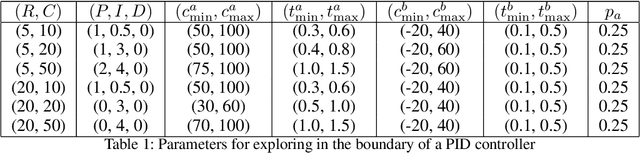
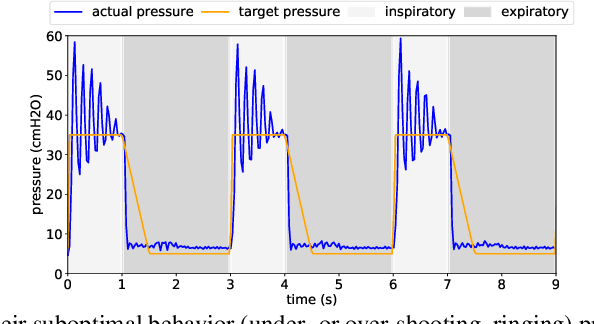
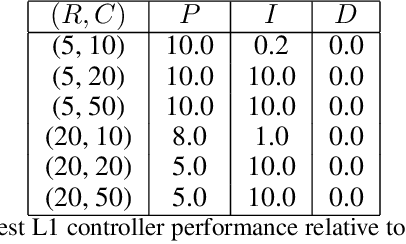
We consider the problem of controlling an invasive mechanical ventilator for pressure-controlled ventilation: a controller must let air in and out of a sedated patient's lungs according to a trajectory of airway pressures specified by a clinician. Hand-tuned PID controllers and similar variants have comprised the industry standard for decades, yet can behave poorly by over- or under-shooting their target or oscillating rapidly. We consider a data-driven machine learning approach: First, we train a simulator based on data we collect from an artificial lung. Then, we train deep neural network controllers on these simulators.We show that our controllers are able to track target pressure waveforms significantly better than PID controllers. We further show that a learned controller generalizes across lungs with varying characteristics much more readily than PID controllers do.
Deluca -- A Differentiable Control Library: Environments, Methods, and Benchmarking
Feb 19, 2021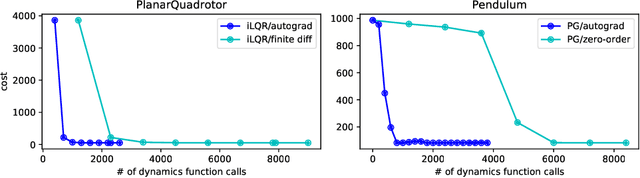
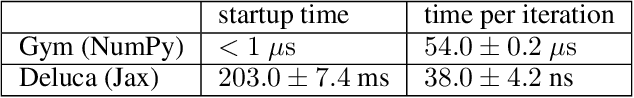
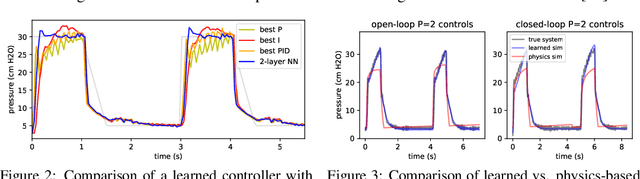
We present an open-source library of natively differentiable physics and robotics environments, accompanied by gradient-based control methods and a benchmark-ing suite. The introduced environments allow auto-differentiation through the simulation dynamics, and thereby permit fast training of controllers. The library features several popular environments, including classical control settings from OpenAI Gym. We also provide a novel differentiable environment, based on deep neural networks, that simulates medical ventilation. We give several use-cases of new scientific results obtained using the library. This includes a medical ventilator simulator and controller, an adaptive control method for time-varying linear dynamical systems, and new gradient-based methods for control of linear dynamical systems with adversarial perturbations.
Continual Learning in Generative Adversarial Nets
May 23, 2017



Developments in deep generative models have allowed for tractable learning of high-dimensional data distributions. While the employed learning procedures typically assume that training data is drawn i.i.d. from the distribution of interest, it may be desirable to model distinct distributions which are observed sequentially, such as when different classes are encountered over time. Although conditional variations of deep generative models permit multiple distributions to be modeled by a single network in a disentangled fashion, they are susceptible to catastrophic forgetting when the distributions are encountered sequentially. In this paper, we adapt recent work in reducing catastrophic forgetting to the task of training generative adversarial networks on a sequence of distinct distributions, enabling continual generative modeling.