 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtean Compiler: An Agile Framework to Drive Fine-grain Phase Ordering
Feb 05, 2026The phase ordering problem has been a long-standing challenge since the late 1970s, yet it remains an open problem due to having a vast optimization space and an unbounded nature, making it an open-ended problem without a finite solution, one can limit the scope by reducing the number and the length of optimizations. Traditionally, such locally optimized decisions are made by hand-coded algorithms tuned for a small number of benchmarks, often requiring significant effort to be retuned when the benchmark suite changes. In the past 20 years, Machine Learning has been employed to construct performance models to improve the selection and ordering of compiler optimizations, however, the approaches are not baked into the compiler seamlessly and never materialized to be leveraged at a fine-grained scope of code segments. This paper presents Protean Compiler: An agile framework to enable LLVM with built-in phase-ordering capabilities at a fine-grained scope. The framework also comprises a complete library of more than 140 handcrafted static feature collection methods at varying scopes, and the experimental results showcase speedup gains of up to 4.1% on average and up to 15.7% on select Cbench applications wrt LLVM's O3 by just incurring a few extra seconds of build time on Cbench. Additionally, Protean compiler allows for an easy integration with third-party ML frameworks and other Large Language Models, and this two-step optimization shows a gain of 10.1% and 8.5% speedup wrt O3 on Cbench's Susan and Jpeg applications. Protean compiler is seamlessly integrated into LLVM and can be used as a new, enhanced, full-fledged compiler. We plan to release the project to the open-source community in the near future.
A TRRIP Down Memory Lane: Temperature-Based Re-Reference Interval Prediction For Instruction Caching
Sep 17, 2025Modern mobile CPU software pose challenges for conventional instruction cache replacement policies due to their complex runtime behavior causing high reuse distance between executions of the same instruction. Mobile code commonly suffers from large amounts of stalls in the CPU frontend and thus starvation of the rest of the CPU resources. Complexity of these applications and their code footprint are projected to grow at a rate faster than available on-chip memory due to power and area constraints, making conventional hardware-centric methods for managing instruction caches to be inadequate. We present a novel software-hardware co-design approach called TRRIP (Temperature-based Re-Reference Interval Prediction) that enables the compiler to analyze, classify, and transform code based on "temperature" (hot/cold), and to provide the hardware with a summary of code temperature information through a well-defined OS interface based on using code page attributes. TRRIP's lightweight hardware extension employs code temperature attributes to optimize the instruction cache replacement policy resulting in the eviction rate reduction of hot code. TRRIP is designed to be practical and adoptable in real mobile systems that have strict feature requirements on both the software and hardware components. TRRIP can reduce the L2 MPKI for instructions by 26.5% resulting in geomean speedup of 3.9%, on top of RRIP cache replacement running mobile code already optimized using PGO.
AVG-DICE: Stationary Distribution Correction by Regression
Mar 03, 2025Off-policy policy evaluation (OPE), an essential component of reinforcement learning, has long suffered from stationary state distribution mismatch, undermining both stability and accuracy of OPE estimates. While existing methods correct distribution shifts by estimating density ratios, they often rely on expensive optimization or backward Bellman-based updates and struggle to outperform simpler baselines. We introduce AVG-DICE, a computationally simple Monte Carlo estimator for the density ratio that averages discounted importance sampling ratios, providing an unbiased and consistent correction. AVG-DICE extends naturally to nonlinear function approximation using regression, which we roughly tune and test on OPE tasks based on Mujoco Gym environments and compare with state-of-the-art density-ratio estimators using their reported hyperparameters. In our experiments, AVG-DICE is at least as accurate as state-of-the-art estimators and sometimes offers orders-of-magnitude improvements. However, a sensitivity analysis shows that best-performing hyperparameters may vary substantially across different discount factors, so a re-tuning is suggested.
Toward Understanding In-context vs. In-weight Learning
Oct 30, 2024



It has recently been demonstrated empirically that in-context learning emerges in transformers when certain distributional properties are present in the training data, but this ability can also diminish upon further training. We provide a new theoretical understanding of these phenomena by identifying simplified distributional properties that give rise to the emergence and eventual disappearance of in-context learning. We do so by first analyzing a simplified model that uses a gating mechanism to choose between an in-weight and an in-context predictor. Through a combination of a generalization error and regret analysis we identify conditions where in-context and in-weight learning emerge. These theoretical findings are then corroborated experimentally by comparing the behaviour of a full transformer on the simplified distributions to that of the stylized model, demonstrating aligned results. We then extend the study to a full large language model, showing how fine-tuning on various collections of natural language prompts can elicit similar in-context and in-weight learning behaviour.
Offline-to-online Reinforcement Learning for Image-based Grasping with Scarce Demonstrations
Oct 19, 2024



Offline-to-online reinforcement learning (O2O RL) aims to obtain a continually improving policy as it interacts with the environment, while ensuring the initial behaviour is satisficing. This satisficing behaviour is necessary for robotic manipulation where random exploration can be costly due to catastrophic failures and time. O2O RL is especially compelling when we can only obtain a scarce amount of (potentially suboptimal) demonstrations$\unicode{x2014}$a scenario where behavioural cloning (BC) is known to suffer from distribution shift. Previous works have outlined the challenges in applying O2O RL algorithms under the image-based environments. In this work, we propose a novel O2O RL algorithm that can learn in a real-life image-based robotic vacuum grasping task with a small number of demonstrations where BC fails majority of the time. The proposed algorithm replaces the target network in off-policy actor-critic algorithms with a regularization technique inspired by neural tangent kernel. We demonstrate that the proposed algorithm can reach above 90% success rate in under two hours of interaction time, with only 50 human demonstrations, while BC and two commonly-used RL algorithms fail to achieve similar performance.
Value-Penalized Auxiliary Control from Examples for Learning without Rewards or Demonstrations
Jul 03, 2024Learning from examples of success is an appealing approach to reinforcement learning that eliminates many of the disadvantages of using hand-crafted reward functions or full expert-demonstration trajectories, both of which can be difficult to acquire, biased, or suboptimal. However, learning from examples alone dramatically increases the exploration challenge, especially for complex tasks. This work introduces value-penalized auxiliary control from examples (VPACE); we significantly improve exploration in example-based control by adding scheduled auxiliary control and examples of auxiliary tasks. Furthermore, we identify a value-calibration problem, where policy value estimates can exceed their theoretical limits based on successful data. We resolve this problem, which is exacerbated by learning auxiliary tasks, through the addition of an above-success-level value penalty. Across three simulated and one real robotic manipulation environment, and 21 different main tasks, we show that our approach substantially improves learning efficiency. Videos, code, and datasets are available at https://papers.starslab.ca/vpace.
ACPO: AI-Enabled Compiler-Driven Program Optimization
Dec 15, 2023



The key to performance optimization of a program is to decide correctly when a certain transformation should be applied by a compiler. Traditionally, such profitability decisions are made by hand-coded algorithms tuned for a very small number of benchmarks, usually requiring a great deal of effort to be retuned when the benchmark suite changes. This is an ideal opportunity to apply machine-learning models to speed up the tuning process; while this realization has been around since the late 90s, only recent advancements in ML enabled a practical application of ML to compilers as an end-to-end framework. Even so, seamless integration of ML into the compiler would require constant rebuilding of the compiler when models are updated. This paper presents ACPO: \textbf{\underline{A}}I-Enabled \textbf{\underline{C}}ompiler-driven \textbf{\underline{P}}rogram \textbf{\underline{O}}ptimization; a novel framework to provide LLVM with simple and comprehensive tools to benefit from employing ML models for different optimization passes. We first showcase the high-level view, class hierarchy, and functionalities of ACPO and subsequently, demonstrate \taco{a couple of use cases of ACPO by ML-enabling the Loop Unroll and Function Inlining passes and describe how ACPO can be leveraged to optimize other passes. Experimental results reveal that ACPO model for Loop Unroll is able to gain on average 4\% and 3\%, 5.4\%, 0.2\% compared to LLVM's O3 optimization when deployed on Polybench, Coral-2, CoreMark, and Graph-500, respectively. Furthermore, by adding the Inliner model as well, ACPO is able to provide up to 4.5\% and 2.4\% on Polybench and Cbench compared with LLVM's O3 optimization, respectively.
A Statistical Guarantee for Representation Transfer in Multitask Imitation Learning
Nov 02, 2023


Transferring representation for multitask imitation learning has the potential to provide improved sample efficiency on learning new tasks, when compared to learning from scratch. In this work, we provide a statistical guarantee indicating that we can indeed achieve improved sample efficiency on the target task when a representation is trained using sufficiently diverse source tasks. Our theoretical results can be readily extended to account for commonly used neural network architectures with realistic assumptions. We conduct empirical analyses that align with our theoretical findings on four simulated environments$\unicode{x2014}$in particular leveraging more data from source tasks can improve sample efficiency on learning in the new task.
Learning from Guided Play: Improving Exploration for Adversarial Imitation Learning with Simple Auxiliary Tasks
Dec 30, 2022



Adversarial imitation learning (AIL) has become a popular alternative to supervised imitation learning that reduces the distribution shift suffered by the latter. However, AIL requires effective exploration during an online reinforcement learning phase. In this work, we show that the standard, naive approach to exploration can manifest as a suboptimal local maximum if a policy learned with AIL sufficiently matches the expert distribution without fully learning the desired task. This can be particularly catastrophic for manipulation tasks, where the difference between an expert and a non-expert state-action pair is often subtle. We present Learning from Guided Play (LfGP), a framework in which we leverage expert demonstrations of multiple exploratory, auxiliary tasks in addition to a main task. The addition of these auxiliary tasks forces the agent to explore states and actions that standard AIL may learn to ignore. Additionally, this particular formulation allows for the reusability of expert data between main tasks. Our experimental results in a challenging multitask robotic manipulation domain indicate that LfGP significantly outperforms both AIL and behaviour cloning, while also being more expert sample efficient than these baselines. To explain this performance gap, we provide further analysis of a toy problem that highlights the coupling between a local maximum and poor exploration, and also visualize the differences between the learned models from AIL and LfGP.
MLGOPerf: An ML Guided Inliner to Optimize Performance
Jul 19, 2022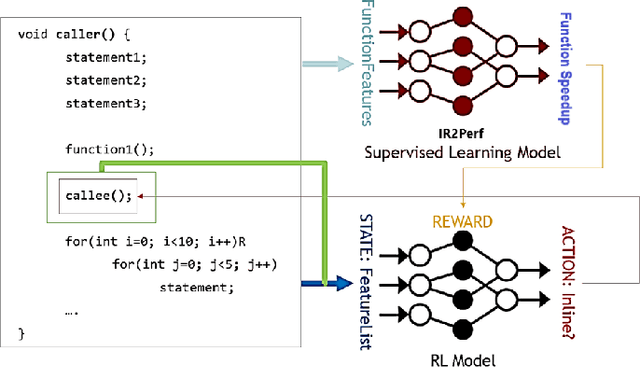
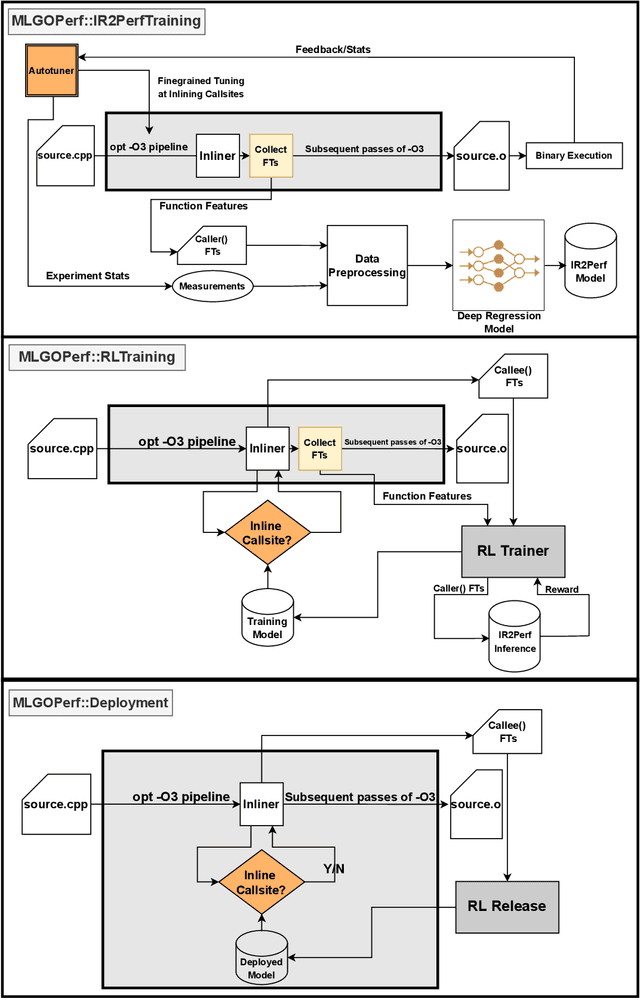
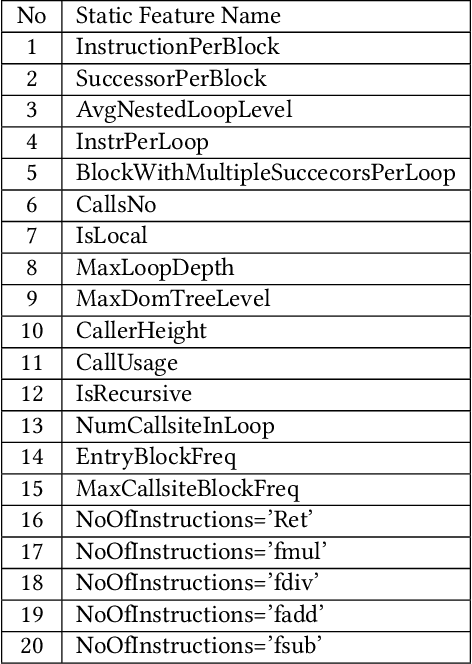
For the past 25 years, we have witnessed an extensive application of Machine Learning to the Compiler space; the selection and the phase-ordering problem. However, limited works have been upstreamed into the state-of-the-art compilers, i.e., LLVM, to seamlessly integrate the former into the optimization pipeline of a compiler to be readily deployed by the user. MLGO was among the first of such projects and it only strives to reduce the code size of a binary with an ML-based Inliner using Reinforcement Learning. This paper presents MLGOPerf; the first end-to-end framework capable of optimizing performance using LLVM's ML-Inliner. It employs a secondary ML model to generate rewards used for training a retargeted Reinforcement learning agent, previously used as the primary model by MLGO. It does so by predicting the post-inlining speedup of a function under analysis and it enables a fast training framework for the primary model which otherwise wouldn't be practical. The experimental results show MLGOPerf is able to gain up to 1.8% and 2.2% with respect to LLVM's optimization at O3 when trained for performance on SPEC CPU2006 and Cbench benchmarks, respectively. Furthermore, the proposed approach provides up to 26% increased opportunities to autotune code regions for our benchmarks which can be translated into an additional 3.7% speedup value.