 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayoutDiffuse: Adapting Foundational Diffusion Models for Layout-to-Image Generation
Feb 16, 2023



Layout-to-image generation refers to the task of synthesizing photo-realistic images based on semantic layouts. In this paper, we propose LayoutDiffuse that adapts a foundational diffusion model pretrained on large-scale image or text-image datasets for layout-to-image generation. By adopting a novel neural adaptor based on layout attention and task-aware prompts, our method trains efficiently, generates images with both high perceptual quality and layout alignment, and needs less data. Experiments on three datasets show that our method significantly outperforms other 10 generative models based on GANs, VQ-VAE, and diffusion models.
GFM: Building Geospatial Foundation Models via Continual Pretraining
Feb 09, 2023Geospatial technologies are becoming increasingly essential in our world for a large range of tasks, such as earth monitoring and natural disaster response. To help improve the applicability and performance of deep learning models on these geospatial tasks, various works have pursued the idea of a geospatial foundation model, i.e., training networks from scratch on a large corpus of remote sensing imagery. However, this approach often requires a significant amount of data and training time to achieve suitable performance, especially when employing large state-of-the-art transformer models. In light of these challenges, we investigate a sustainable approach to building geospatial foundation models. In our investigations, we discover two important factors in the process. First, we find that the selection of pretraining data matters, even within the geospatial domain. We therefore gather a concise yet effective dataset for pretraining. Second, we find that available pretrained models on diverse datasets like ImageNet-22k should not be ignored when building geospatial foundation models, as their representations are still surprisingly effective. Rather, by leveraging their representations, we can build strong models for geospatial applications in a sustainable manner. To this end, we formulate a multi-objective continual pretraining approach for training sustainable geospatial foundation models. We experiment on a wide variety of downstream datasets and tasks, achieving strong performance across the board in comparison to ImageNet baselines and state-of-the-art geospatial pretrained models.
Parameter-Efficient Fine-Tuning Design Spaces
Jan 04, 2023



Parameter-efficient fine-tuning aims to achieve performance comparable to fine-tuning, using fewer trainable parameters. Several strategies (e.g., Adapters, prefix tuning, BitFit, and LoRA) have been proposed. However, their designs are hand-crafted separately, and it remains unclear whether certain design patterns exist for parameter-efficient fine-tuning. Thus, we present a parameter-efficient fine-tuning design paradigm and discover design patterns that are applicable to different experimental settings. Instead of focusing on designing another individual tuning strategy, we introduce parameter-efficient fine-tuning design spaces that parameterize tuning structures and tuning strategies. Specifically, any design space is characterized by four components: layer grouping, trainable parameter allocation, tunable groups, and strategy assignment. Starting from an initial design space, we progressively refine the space based on the model quality of each design choice and make greedy selection at each stage over these four components. We discover the following design patterns: (i) group layers in a spindle pattern; (ii) allocate the number of trainable parameters to layers uniformly; (iii) tune all the groups; (iv) assign proper tuning strategies to different groups. These design patterns result in new parameter-efficient fine-tuning methods. We show experimentally that these methods consistently and significantly outperform investigated parameter-efficient fine-tuning strategies across different backbone models and different tasks in natural language processing.
Learning Multimodal Data Augmentation in Feature Space
Dec 29, 2022



The ability to jointly learn from multiple modalities, such as text, audio, and visual data, is a defining feature of intelligent systems. While there have been promising advances in designing neural networks to harness multimodal data, the enormous success of data augmentation currently remains limited to single-modality tasks like image classification. Indeed, it is particularly difficult to augment each modality while preserving the overall semantic structure of the data; for example, a caption may no longer be a good description of an image after standard augmentations have been applied, such as translation. Moreover, it is challenging to specify reasonable transformations that are not tailored to a particular modality. In this paper, we introduce LeMDA, Learning Multimodal Data Augmentation, an easy-to-use method that automatically learns to jointly augment multimodal data in feature space, with no constraints on the identities of the modalities or the relationship between modalities. We show that LeMDA can (1) profoundly improve the performance of multimodal deep learning architectures, (2) apply to combinations of modalities that have not been previously considered, and (3) achieve state-of-the-art results on a wide range of applications comprised of image, text, and tabular data.
SPT: Semi-Parametric Prompt Tuning for Multitask Prompted Learning
Dec 21, 2022



Pre-trained large language models can efficiently interpolate human-written prompts in a natural way. Multitask prompted learning can help generalization through a diverse set of tasks at once, thus enhancing the potential for more effective downstream fine-tuning. To perform efficient multitask-inference in the same batch, parameter-efficient fine-tuning methods such as prompt tuning have been proposed. However, the existing prompt tuning methods may lack generalization. We propose SPT, a semi-parametric prompt tuning method for multitask prompted learning. The novel component of SPT is a memory bank from where memory prompts are retrieved based on discrete prompts. Extensive experiments, such as (i) fine-tuning a full language model with SPT on 31 different tasks from 8 different domains and evaluating zero-shot generalization on 9 heldout datasets under 5 NLP task categories and (ii) pretraining SPT on the GLUE datasets and evaluating fine-tuning on the SuperGLUE datasets, demonstrate effectiveness of SPT.
Are Multimodal Models Robust to Image and Text Perturbations?
Dec 15, 2022



Multimodal image-text models have shown remarkable performance in the past few years. However, evaluating their robustness against distribution shifts is crucial before adopting them in real-world applications. In this paper, we investigate the robustness of 9 popular open-sourced image-text models under common perturbations on five tasks (image-text retrieval, visual reasoning, visual entailment, image captioning, and text-to-image generation). In particular, we propose several new multimodal robustness benchmarks by applying 17 image perturbation and 16 text perturbation techniques on top of existing datasets. We observe that multimodal models are not robust to image and text perturbations, especially to image perturbations. Among the tested perturbation methods, character-level perturbations constitute the most severe distribution shift for text, and zoom blur is the most severe shift for image data. We also introduce two new robustness metrics (MMI and MOR) for proper evaluations of multimodal models. We hope our extensive study sheds light on new directions for the development of robust multimodal models.
First De-Trend then Attend: Rethinking Attention for Time-Series Forecasting
Dec 15, 2022



Transformer-based models have gained large popularity and demonstrated promising results in long-term time-series forecasting in recent years. In addition to learning attention in time domain, recent works also explore learning attention in frequency domains (e.g., Fourier domain, wavelet domain), given that seasonal patterns can be better captured in these domains. In this work, we seek to understand the relationships between attention models in different time and frequency domains. Theoretically, we show that attention models in different domains are equivalent under linear conditions (i.e., linear kernel to attention scores). Empirically, we analyze how attention models of different domains show different behaviors through various synthetic experiments with seasonality, trend and noise, with emphasis on the role of softmax operation therein. Both these theoretical and empirical analyses motivate us to propose a new method: TDformer (Trend Decomposition Transformer), that first applies seasonal-trend decomposition, and then additively combines an MLP which predicts the trend component with Fourier attention which predicts the seasonal component to obtain the final prediction. Extensive experiments on benchmark time-series forecasting datasets demonstrate that TDformer achieves state-of-the-art performance against existing attention-based models.
A Transformer-Based Substitute Recommendation Model Incorporating Weakly Supervised Customer Behavior Data
Nov 04, 2022



The substitute-based recommendation is widely used in E-commerce to provide better alternatives to customers. However, existing research typically uses the customer behavior signals like co-view and view-but-purchase-another to capture the substitute relationship. Despite its intuitive soundness, we find that such an approach might ignore the functionality and characteristics of products. In this paper, we adapt substitute recommendation into language matching problem by taking product title description as model input to consider product functionality. We design a new transformation method to de-noise the signals derived from production data. In addition, we consider multilingual support from the engineering point of view. Our proposed end-to-end transformer-based model achieves both successes from offline and online experiments. The proposed model has been deployed in a large-scale E-commerce website for 11 marketplaces in 6 languages. Our proposed model is demonstrated to increase revenue by 19% based on an online A/B experiment.
Visual Prompt Tuning for Test-time Domain Adaptation
Oct 10, 2022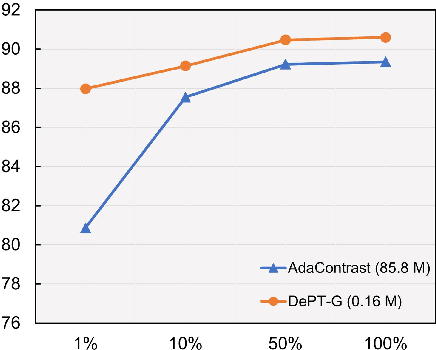
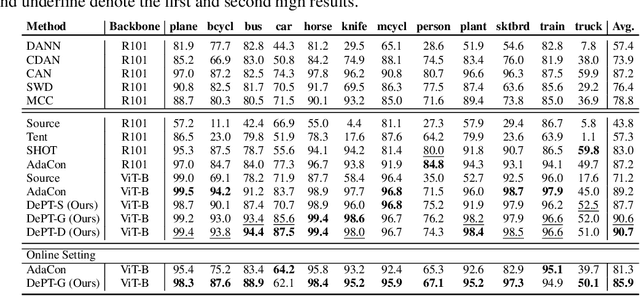
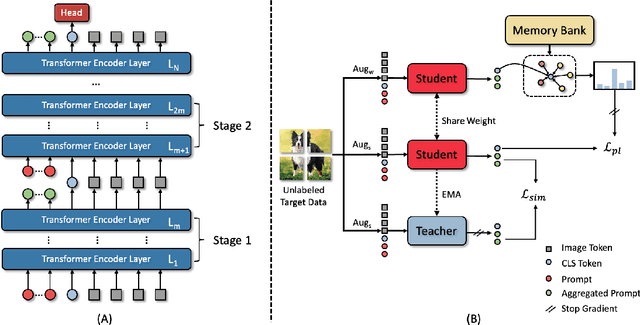
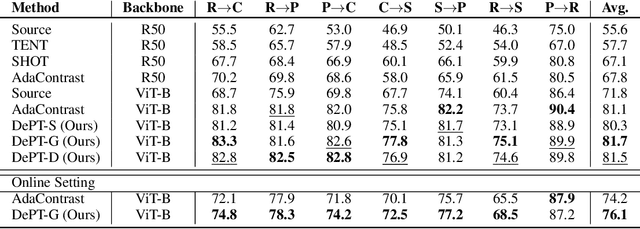
Models should have the ability to adapt to unseen data during test-time to avoid performance drop caused by inevitable distribution shifts in real-world deployment scenarios. In this work, we tackle the practical yet challenging test-time adaptation (TTA) problem, where a model adapts to the target domain without accessing the source data. We propose a simple recipe called data-efficient prompt tuning (DePT) with two key ingredients. First, DePT plugs visual prompts into the vision Transformer and only tunes these source-initialized prompts during adaptation. We find such parameter-efficient finetuning can efficiently adapt the model representation to the target domain without overfitting to the noise in the learning objective. Second, DePT bootstraps the source representation to the target domain by memory bank-based online pseudo labeling. A hierarchical self-supervised regularization specially designed for prompts is jointly optimized to alleviate error accumulation during self-training. With much fewer tunable parameters, DePT demonstrates not only state-of-the-art performance on major adaptation benchmarks, but also superior data efficiency, i.e., adaptation with only 1\% or 10\% data without much performance degradation compared to 100\% data. In addition, DePT is also versatile to be extended to online or multi-source TTA settings.
Earthformer: Exploring Space-Time Transformers for Earth System Forecasting
Jul 12, 2022
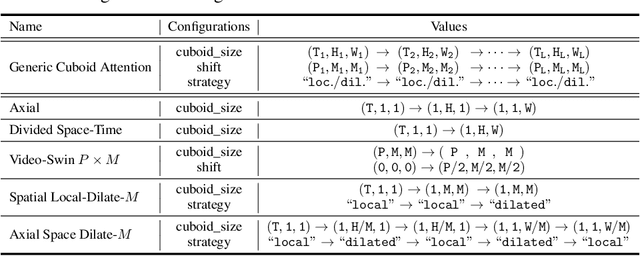
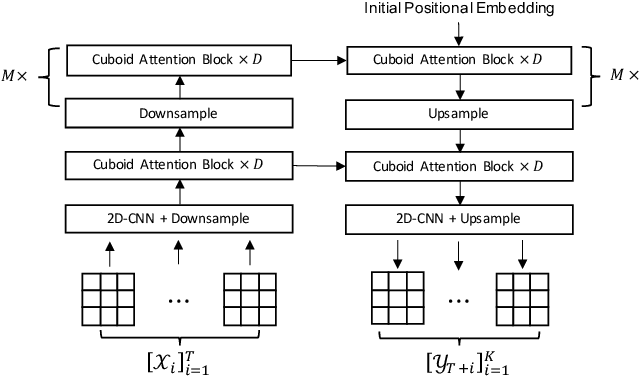
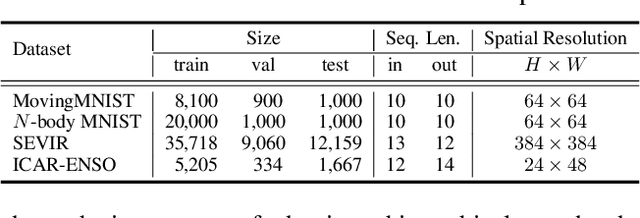
Conventionally, Earth system (e.g., weather and climate) forecasting relies on numerical simulation with complex physical models and are hence both expensive in computation and demanding on domain expertise. With the explosive growth of the spatiotemporal Earth observation data in the past decade, data-driven models that apply Deep Learning (DL) are demonstrating impressive potential for various Earth system forecasting tasks. The Transformer as an emerging DL architecture, despite its broad success in other domains, has limited adoption in this area. In this paper, we propose Earthformer, a space-time Transformer for Earth system forecasting. Earthformer is based on a generic, flexible and efficient space-time attention block, named Cuboid Attention. The idea is to decompose the data into cuboids and apply cuboid-level self-attention in parallel. These cuboids are further connected with a collection of global vectors. We conduct experiments on the MovingMNIST dataset and a newly proposed chaotic N-body MNIST dataset to verify the effectiveness of cuboid attention and figure out the best design of Earthformer. Experiments on two real-world benchmarks about precipitation nowcasting and El Nino/Southern Oscillation (ENSO) forecasting show Earthformer achieves state-of-the-art performance.