 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMambaOVSR: Multiscale Fusion with Global Motion Modeling for Chinese Opera Video Super-Resolution
Nov 09, 2025



Chinese opera is celebrated for preserving classical art. However, early filming equipment limitations have degraded videos of last-century performances by renowned artists (e.g., low frame rates and resolution), hindering archival efforts. Although space-time video super-resolution (STVSR) has advanced significantly, applying it directly to opera videos remains challenging. The scarcity of datasets impedes the recovery of high frequency details, and existing STVSR methods lack global modeling capabilities, compromising visual quality when handling opera's characteristic large motions. To address these challenges, we pioneer a large scale Chinese Opera Video Clip (COVC) dataset and propose the Mamba-based multiscale fusion network for space-time Opera Video Super-Resolution (MambaOVSR). Specifically, MambaOVSR involves three novel components: the Global Fusion Module (GFM) for motion modeling through a multiscale alternating scanning mechanism, and the Multiscale Synergistic Mamba Module (MSMM) for alignment across different sequence lengths. Additionally, our MambaVR block resolves feature artifacts and positional information loss during alignment. Experimental results on the COVC dataset show that MambaOVSR significantly outperforms the SOTA STVSR method by an average of 1.86 dB in terms of PSNR. Dataset and Code will be publicly released.
DiSE: A diffusion probabilistic model for automatic structure elucidation of organic compounds
Oct 30, 2025Automatic structure elucidation is essential for self-driving laboratories as it enables the system to achieve truly autonomous. This capability closes the experimental feedback loop, ensuring that machine learning models receive reliable structure information for real-time decision-making and optimization. Herein, we present DiSE, an end-to-end diffusion-based generative model that integrates multiple spectroscopic modalities, including MS, 13C and 1H chemical shifts, HSQC, and COSY, to achieve automated yet accurate structure elucidation of organic compounds. By learning inherent correlations among spectra through data-driven approaches, DiSE achieves superior accuracy, strong generalization across chemically diverse datasets, and robustness to experimental data despite being trained on calculated spectra. DiSE thus represents a significant advance toward fully automated structure elucidation, with broad potential in natural product research, drug discovery, and self-driving laboratories.
When Benchmarks Age: Temporal Misalignment through Large Language Model Factuality Evaluation
Oct 08, 2025The rapid evolution of large language models (LLMs) and the real world has outpaced the static nature of widely used evaluation benchmarks, raising concerns about their reliability for evaluating LLM factuality. While substantial works continue to rely on the popular but old benchmarks, their temporal misalignment with real-world facts and modern LLMs, and their effects on LLM factuality evaluation remain underexplored. Therefore, in this work, we present a systematic investigation of this issue by examining five popular factuality benchmarks and eight LLMs released across different years. An up-to-date fact retrieval pipeline and three metrics are tailored to quantify benchmark aging and its impact on LLM factuality evaluation. Experimental results and analysis illustrate that a considerable portion of samples in the widely used factuality benchmarks are outdated, leading to unreliable assessments of LLM factuality. We hope our work can provide a testbed to assess the reliability of a benchmark for LLM factuality evaluation and inspire more research on the benchmark aging issue. Codes are available in https://github.com/JiangXunyi/BenchAge.
On Predictability of Reinforcement Learning Dynamics for Large Language Models
Oct 02, 2025Recent advances in reasoning capabilities of large language models (LLMs) are largely driven by reinforcement learning (RL), yet the underlying parameter dynamics during RL training remain poorly understood. This work identifies two fundamental properties of RL-induced parameter updates in LLMs: (1) Rank-1 Dominance, where the top singular subspace of the parameter update matrix nearly fully determines reasoning improvements, recovering over 99\% of performance gains; and (2) Rank-1 Linear Dynamics, where this dominant subspace evolves linearly throughout training, enabling accurate prediction from early checkpoints. Extensive experiments across 8 LLMs and 7 algorithms validate the generalizability of these properties. More importantly, based on these findings, we propose AlphaRL, a plug-in acceleration framework that extrapolates the final parameter update using a short early training window, achieving up to 2.5 speedup while retaining \textgreater 96\% of reasoning performance without extra modules or hyperparameter tuning. This positions our finding as a versatile and practical tool for large-scale RL, opening a path toward principled, interpretable, and efficient training paradigm for LLMs.
An Adaptive ICP LiDAR Odometry Based on Reliable Initial Pose
Sep 26, 2025As a key technology for autonomous navigation and positioning in mobile robots, light detection and ranging (LiDAR) odometry is widely used in autonomous driving applications. The Iterative Closest Point (ICP)-based methods have become the core technique in LiDAR odometry due to their efficient and accurate point cloud registration capability. However, some existing ICP-based methods do not consider the reliability of the initial pose, which may cause the method to converge to a local optimum. Furthermore, the absence of an adaptive mechanism hinders the effective handling of complex dynamic environments, resulting in a significant degradation of registration accuracy. To address these issues, this paper proposes an adaptive ICP-based LiDAR odometry method that relies on a reliable initial pose. First, distributed coarse registration based on density filtering is employed to obtain the initial pose estimation. The reliable initial pose is then selected by comparing it with the motion prediction pose, reducing the initial error between the source and target point clouds. Subsequently, by combining the current and historical errors, the adaptive threshold is dynamically adjusted to accommodate the real-time changes in the dynamic environment. Finally, based on the reliable initial pose and the adaptive threshold, point-to-plane adaptive ICP registration is performed from the current frame to the local map, achieving high-precision alignment of the source and target point clouds. Extensive experiments on the public KITTI dataset demonstrate that the proposed method outperforms existing approaches and significantly enhances the accuracy of LiDAR odometry.
The CCF AATC 2025: Speech Restoration Challenge
Sep 16, 2025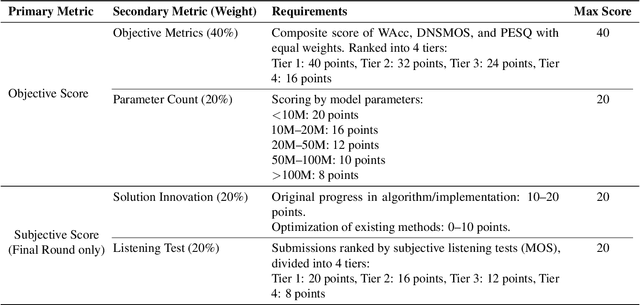
Real-world speech communication is often hampered by a variety of distortions that degrade quality and intelligibility. While many speech enhancement algorithms target specific degradations like noise or reverberation, they often fall short in realistic scenarios where multiple distortions co-exist and interact. To spur research in this area, we introduce the Speech Restoration Challenge as part of the China Computer Federation (CCF) Advanced Audio Technology Competition (AATC) 2025. This challenge focuses on restoring speech signals affected by a composite of three degradation types: (1) complex acoustic degradations including non-stationary noise and reverberation; (2) signal-chain artifacts such as those from MP3 compression; and (3) secondary artifacts introduced by other pre-processing enhancement models. We describe the challenge's background, the design of the task, the comprehensive dataset creation methodology, and the detailed evaluation protocol, which assesses both objective performance and model complexity. Homepage: https://ccf-aatc.org.cn/.
WildScore: Benchmarking MLLMs in-the-Wild Symbolic Music Reasoning
Sep 05, 2025Recent advances in Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities across various vision-language tasks. However, their reasoning abilities in the multimodal symbolic music domain remain largely unexplored. We introduce WildScore, the first in-the-wild multimodal symbolic music reasoning and analysis benchmark, designed to evaluate MLLMs' capacity to interpret real-world music scores and answer complex musicological queries. Each instance in WildScore is sourced from genuine musical compositions and accompanied by authentic user-generated questions and discussions, capturing the intricacies of practical music analysis. To facilitate systematic evaluation, we propose a systematic taxonomy, comprising both high-level and fine-grained musicological ontologies. Furthermore, we frame complex music reasoning as multiple-choice question answering, enabling controlled and scalable assessment of MLLMs' symbolic music understanding. Empirical benchmarking of state-of-the-art MLLMs on WildScore reveals intriguing patterns in their visual-symbolic reasoning, uncovering both promising directions and persistent challenges for MLLMs in symbolic music reasoning and analysis. We release the dataset and code.
CMFDNet: Cross-Mamba and Feature Discovery Network for Polyp Segmentation
Aug 25, 2025Automated colonic polyp segmentation is crucial for assisting doctors in screening of precancerous polyps and diagnosis of colorectal neoplasms. Although existing methods have achieved promising results, polyp segmentation remains hindered by the following limitations,including: (1) significant variation in polyp shapes and sizes, (2) indistinct boundaries between polyps and adjacent tissues, and (3) small-sized polyps are easily overlooked during the segmentation process. Driven by these practical difficulties, an innovative architecture, CMFDNet, is proposed with the CMD module, MSA module, and FD module. The CMD module, serving as an innovative decoder, introduces a cross-scanning method to reduce blurry boundaries. The MSA module adopts a multi-branch parallel structure to enhance the recognition ability for polyps with diverse geometries and scale distributions. The FD module establishes dependencies among all decoder features to alleviate the under-detection of polyps with small-scale features. Experimental results show that CMFDNet outperforms six SOTA methods used for comparison, especially on ETIS and ColonDB datasets, where mDice scores exceed the best SOTA method by 1.83% and 1.55%, respectively.
Foundation Model Insights and a Multi-Model Approach for Superior Fine-Grained One-shot Subset Selection
Jun 17, 2025



One-shot subset selection serves as an effective tool to reduce deep learning training costs by identifying an informative data subset based on the information extracted by an information extractor (IE). Traditional IEs, typically pre-trained on the target dataset, are inherently dataset-dependent. Foundation models (FMs) offer a promising alternative, potentially mitigating this limitation. This work investigates two key questions: (1) Can FM-based subset selection outperform traditional IE-based methods across diverse datasets? (2) Do all FMs perform equally well as IEs for subset selection? Extensive experiments uncovered surprising insights: FMs consistently outperform traditional IEs on fine-grained datasets, whereas their advantage diminishes on coarse-grained datasets with noisy labels. Motivated by these finding, we propose RAM-APL (RAnking Mean-Accuracy of Pseudo-class Labels), a method tailored for fine-grained image datasets. RAM-APL leverages multiple FMs to enhance subset selection by exploiting their complementary strengths. Our approach achieves state-of-the-art performance on fine-grained datasets, including Oxford-IIIT Pet, Food-101, and Caltech-UCSD Birds-200-2011.
Advancing Multimodal Reasoning Capabilities of Multimodal Large Language Models via Visual Perception Reward
Jun 08, 2025Enhancing the multimodal reasoning capabilities of Multimodal Large Language Models (MLLMs) is a challenging task that has attracted increasing attention in the community. Recently, several studies have applied Reinforcement Learning with Verifiable Rewards (RLVR) to the multimodal domain in order to enhance the reasoning abilities of MLLMs. However, these works largely overlook the enhancement of multimodal perception capabilities in MLLMs, which serve as a core prerequisite and foundational component of complex multimodal reasoning. Through McNemar's test, we find that existing RLVR method fails to effectively enhance the multimodal perception capabilities of MLLMs, thereby limiting their further improvement in multimodal reasoning. To address this limitation, we propose Perception-R1, which introduces a novel visual perception reward that explicitly encourages MLLMs to perceive the visual content accurately, thereby can effectively incentivizing both their multimodal perception and reasoning capabilities. Specifically, we first collect textual visual annotations from the CoT trajectories of multimodal problems, which will serve as visual references for reward assignment. During RLVR training, we employ a judging LLM to assess the consistency between the visual annotations and the responses generated by MLLM, and assign the visual perception reward based on these consistency judgments. Extensive experiments on several multimodal reasoning benchmarks demonstrate the effectiveness of our Perception-R1, which achieves state-of-the-art performance on most benchmarks using only 1,442 training data.