 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEigeNet: Geometry-Informed Multi-Modal Learning for Few-shot Novel View RIR Prediction
May 27, 2026Predicting spatially varying Room Impulse Response (RIR) from sparse observations is a critical but highly challenging inverse problem for immersive spatial audio rendering. In this work, we present EIGENET, a geometry-informed multi-modal framework for few-shot novel view RIR prediction. At its core is a Cross-view Alternate-attention Transformer that iteratively refines local intra-view acoustic structures and global cross-view spatial relationships. We empirically demonstrate that this architecture is capable of making full use of the multi-view multi-modal context while performing spatial-temporal reasoning for RIR prediction. Inspired by acoustic ray tracing, we design a geometry-informed modulation block to formulate the connection between geometric features and RIR power spectrum. In the mean time, an auxiliary loss is introduced to transform the single-target waveform prediction into a multi-task learning framework. Through ablation studies, we demonstrate that this design yields consistent performance gains regardless of the underlying backbone, thereby confirming its foundational utility and architecture-agnostic generalizability for RIR prediction task. Evaluated on both simulated and real-world benchmarks, EIGENET achieves both state-of-the-art performance in few-shot novel view RIR prediction and sim-to-real generalization. Codes and checkpoints are available on https://github.com/FEAfeatherTHER/EigeNet.
Aliasing-Free Neural Audio Synthesis
Dec 23, 2025



Neural vocoders and codecs reconstruct waveforms from acoustic representations, which directly impact the audio quality. Among existing methods, upsampling-based time-domain models are superior in both inference speed and synthesis quality, achieving state-of-the-art performance. Still, despite their success in producing perceptually natural sound, their synthesis fidelity remains limited due to the aliasing artifacts brought by the inadequately designed model architectures. In particular, the unconstrained nonlinear activation generates an infinite number of harmonics that exceed the Nyquist frequency, resulting in ``folded-back'' aliasing artifacts. The widely used upsampling layer, ConvTranspose, copies the mirrored low-frequency parts to fill the empty high-frequency region, resulting in ``mirrored'' aliasing artifacts. Meanwhile, the combination of its inherent periodicity and the mirrored DC bias also brings ``tonal artifact,'' resulting in constant-frequency ringing. This paper aims to solve these issues from a signal processing perspective. Specifically, we apply oversampling and anti-derivative anti-aliasing to the activation function to obtain its anti-aliased form, and replace the problematic ConvTranspose layer with resampling to avoid the ``tonal artifact'' and eliminate aliased components. Based on our proposed anti-aliased modules, we introduce Pupu-Vocoder and Pupu-Codec, and release high-quality pre-trained checkpoints to facilitate audio generation research. We build a test signal benchmark to illustrate the effectiveness of the anti-aliased modules, and conduct experiments on speech, singing voice, music, and audio to validate our proposed models. Experimental results confirm that our lightweight Pupu-Vocoder and Pupu-Codec models can easily outperform existing systems on singing voice, music, and audio, while achieving comparable performance on speech.
AnyAccomp: Generalizable Accompaniment Generation via Quantized Melodic Bottleneck
Sep 17, 2025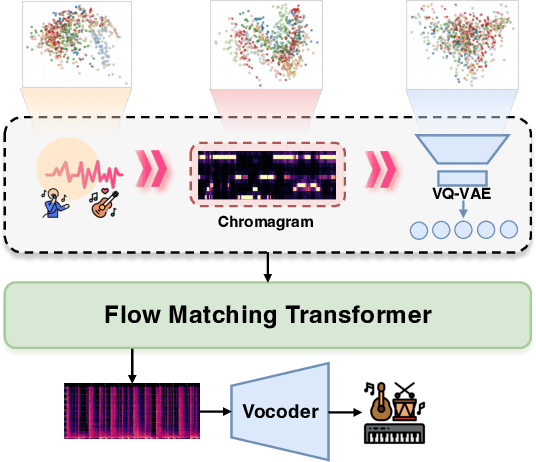
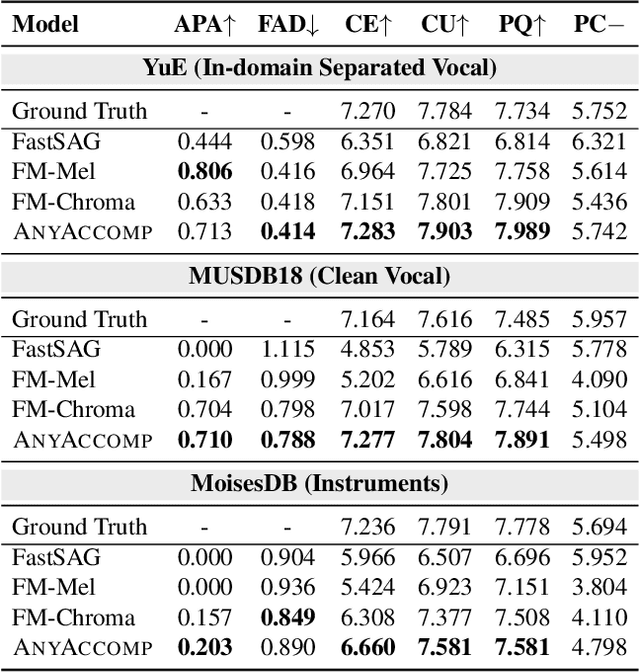
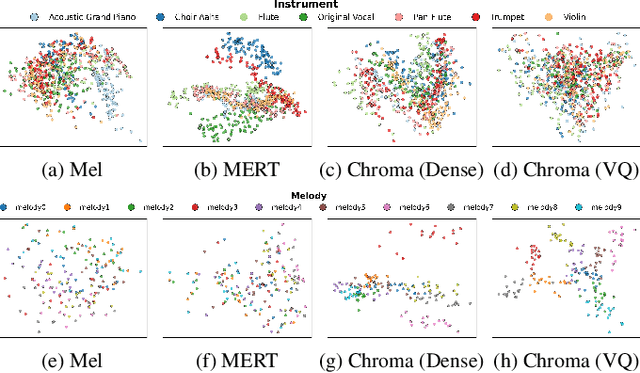
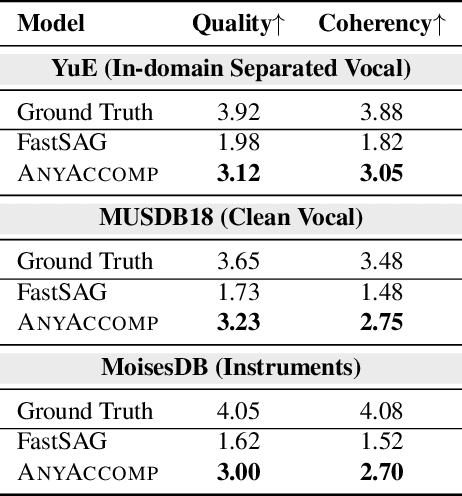
Singing Accompaniment Generation (SAG) is the process of generating instrumental music for a given clean vocal input. However, existing SAG techniques use source-separated vocals as input and overfit to separation artifacts. This creates a critical train-test mismatch, leading to failure on clean, real-world vocal inputs. We introduce AnyAccomp, a framework that resolves this by decoupling accompaniment generation from source-dependent artifacts. AnyAccomp first employs a quantized melodic bottleneck, using a chromagram and a VQ-VAE to extract a discrete and timbre-invariant representation of the core melody. A subsequent flow-matching model then generates the accompaniment conditioned on these robust codes. Experiments show AnyAccomp achieves competitive performance on separated-vocal benchmarks while significantly outperforming baselines on generalization test sets of clean studio vocals and, notably, solo instrumental tracks. This demonstrates a qualitative leap in generalization, enabling robust accompaniment for instruments - a task where existing models completely fail - and paving the way for more versatile music co-creation tools. Demo audio and code: https://anyaccomp.github.io
The CCF AATC 2025: Speech Restoration Challenge
Sep 16, 2025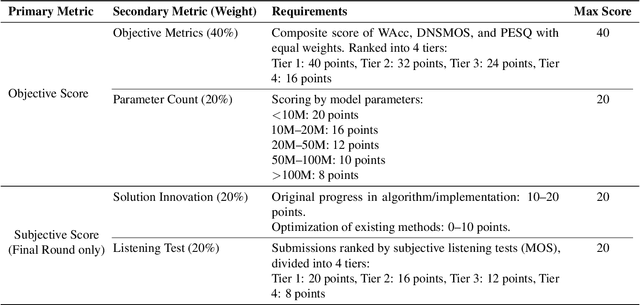
Real-world speech communication is often hampered by a variety of distortions that degrade quality and intelligibility. While many speech enhancement algorithms target specific degradations like noise or reverberation, they often fall short in realistic scenarios where multiple distortions co-exist and interact. To spur research in this area, we introduce the Speech Restoration Challenge as part of the China Computer Federation (CCF) Advanced Audio Technology Competition (AATC) 2025. This challenge focuses on restoring speech signals affected by a composite of three degradation types: (1) complex acoustic degradations including non-stationary noise and reverberation; (2) signal-chain artifacts such as those from MP3 compression; and (3) secondary artifacts introduced by other pre-processing enhancement models. We describe the challenge's background, the design of the task, the comprehensive dataset creation methodology, and the detailed evaluation protocol, which assesses both objective performance and model complexity. Homepage: https://ccf-aatc.org.cn/.
Multi-Metric Preference Alignment for Generative Speech Restoration
Aug 24, 2025Recent generative models have significantly advanced speech restoration tasks, yet their training objectives often misalign with human perceptual preferences, resulting in suboptimal quality. While post-training alignment has proven effective in other generative domains like text and image generation, its application to generative speech restoration remains largely under-explored. This work investigates the challenges of applying preference-based post-training to this task, focusing on how to define a robust preference signal and curate high-quality data to avoid reward hacking. To address these challenges, we propose a multi-metric preference alignment strategy. We construct a new dataset, GenSR-Pref, comprising 80K preference pairs, where each chosen sample is unanimously favored by a complementary suite of metrics covering perceptual quality, signal fidelity, content consistency, and timbre preservation. This principled approach ensures a holistic preference signal. Applying Direct Preference Optimization (DPO) with our dataset, we observe consistent and significant performance gains across three diverse generative paradigms: autoregressive models (AR), masked generative models (MGM), and flow-matching models (FM) on various restoration benchmarks, in both objective and subjective evaluations. Ablation studies confirm the superiority of our multi-metric strategy over single-metric approaches in mitigating reward hacking. Furthermore, we demonstrate that our aligned models can serve as powerful ''data annotators'', generating high-quality pseudo-labels to serve as a supervision signal for traditional discriminative models in data-scarce scenarios like singing voice restoration. Demo Page:https://gensr-pref.github.io
SingNet: Towards a Large-Scale, Diverse, and In-the-Wild Singing Voice Dataset
May 14, 2025The lack of a publicly-available large-scale and diverse dataset has long been a significant bottleneck for singing voice applications like Singing Voice Synthesis (SVS) and Singing Voice Conversion (SVC). To tackle this problem, we present SingNet, an extensive, diverse, and in-the-wild singing voice dataset. Specifically, we propose a data processing pipeline to extract ready-to-use training data from sample packs and songs on the internet, forming 3000 hours of singing voices in various languages and styles. Furthermore, to facilitate the use and demonstrate the effectiveness of SingNet, we pre-train and open-source various state-of-the-art (SOTA) models on Wav2vec2, BigVGAN, and NSF-HiFiGAN based on our collected singing voice data. We also conduct benchmark experiments on Automatic Lyric Transcription (ALT), Neural Vocoder, and Singing Voice Conversion (SVC). Audio demos are available at: https://singnet-dataset.github.io/.
Metis: A Foundation Speech Generation Model with Masked Generative Pre-training
Feb 05, 2025We introduce Metis, a foundation model for unified speech generation. Unlike previous task-specific or multi-task models, Metis follows a pre-training and fine-tuning paradigm. It is pre-trained on large-scale unlabeled speech data using masked generative modeling and then fine-tuned to adapt to diverse speech generation tasks. Specifically, 1) Metis utilizes two discrete speech representations: SSL tokens derived from speech self-supervised learning (SSL) features, and acoustic tokens directly quantized from waveforms. 2) Metis performs masked generative pre-training on SSL tokens, utilizing 300K hours of diverse speech data, without any additional condition. 3) Through fine-tuning with task-specific conditions, Metis achieves efficient adaptation to various speech generation tasks while supporting multimodal input, even when using limited data and trainable parameters. Experiments demonstrate that Metis can serve as a foundation model for unified speech generation: Metis outperforms state-of-the-art task-specific or multi-task systems across five speech generation tasks, including zero-shot text-to-speech, voice conversion, target speaker extraction, speech enhancement, and lip-to-speech, even with fewer than 20M trainable parameters or 300 times less training data. Audio samples are are available at https://metis-demo.github.io/.
Overview of the Amphion Toolkit (v0.2)
Jan 26, 2025



Amphion is an open-source toolkit for Audio, Music, and Speech Generation, designed to lower the entry barrier for junior researchers and engineers in these fields. It provides a versatile framework that supports a variety of generation tasks and models. In this report, we introduce Amphion v0.2, the second major release developed in 2024. This release features a 100K-hour open-source multilingual dataset, a robust data preparation pipeline, and novel models for tasks such as text-to-speech, audio coding, and voice conversion. Furthermore, the report includes multiple tutorials that guide users through the functionalities and usage of the newly released models.
AnyEnhance: A Unified Generative Model with Prompt-Guidance and Self-Critic for Voice Enhancement
Jan 26, 2025



We introduce AnyEnhance, a unified generative model for voice enhancement that processes both speech and singing voices. Based on a masked generative model, AnyEnhance is capable of handling both speech and singing voices, supporting a wide range of enhancement tasks including denoising, dereverberation, declipping, super-resolution, and target speaker extraction, all simultaneously and without fine-tuning. AnyEnhance introduces a prompt-guidance mechanism for in-context learning, which allows the model to natively accept a reference speaker's timbre. In this way, it could boost enhancement performance when a reference audio is available and enable the target speaker extraction task without altering the underlying architecture. Moreover, we also introduce a self-critic mechanism into the generative process for masked generative models, yielding higher-quality outputs through iterative self-assessment and refinement. Extensive experiments on various enhancement tasks demonstrate AnyEnhance outperforms existing methods in terms of both objective metrics and subjective listening tests. Demo audios are publicly available at https://amphionspace.github.io/anyenhance/.
LOKI: A Comprehensive Synthetic Data Detection Benchmark using Large Multimodal Models
Oct 13, 2024



With the rapid development of AI-generated content, the future internet may be inundated with synthetic data, making the discrimination of authentic and credible multimodal data increasingly challenging. Synthetic data detection has thus garnered widespread attention, and the performance of large multimodal models (LMMs) in this task has attracted significant interest. LMMs can provide natural language explanations for their authenticity judgments, enhancing the explainability of synthetic content detection. Simultaneously, the task of distinguishing between real and synthetic data effectively tests the perception, knowledge, and reasoning capabilities of LMMs. In response, we introduce LOKI, a novel benchmark designed to evaluate the ability of LMMs to detect synthetic data across multiple modalities. LOKI encompasses video, image, 3D, text, and audio modalities, comprising 18K carefully curated questions across 26 subcategories with clear difficulty levels. The benchmark includes coarse-grained judgment and multiple-choice questions, as well as fine-grained anomaly selection and explanation tasks, allowing for a comprehensive analysis of LMMs. We evaluated 22 open-source LMMs and 6 closed-source models on LOKI, highlighting their potential as synthetic data detectors and also revealing some limitations in the development of LMM capabilities. More information about LOKI can be found at https://opendatalab.github.io/LOKI/