 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond I.I.D.: Three Levels of Generalization for Question Answering on Knowledge Bases
Dec 13, 2020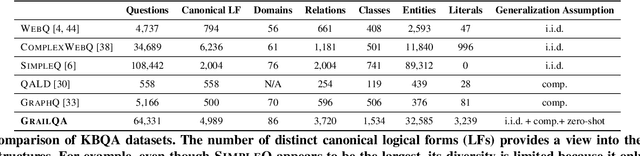
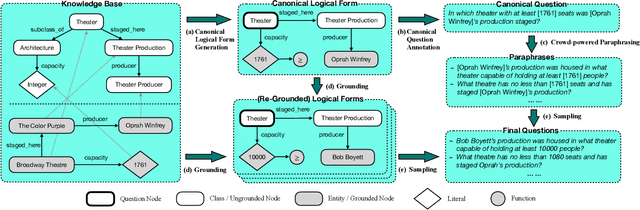

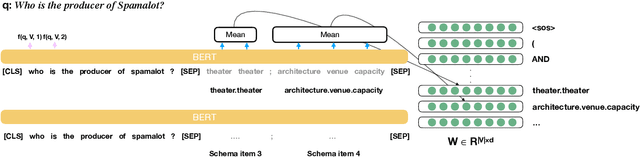
Existing studies on question answering on knowledge bases (KBQA) mainly operate with the standard i.i.d assumption, i.e., training distribution over questions is the same as the test distribution. However, i.i.d may be neither reasonably achievable nor desirable on large-scale KBs because 1) true user distribution is hard to capture and 2) randomly sample training examples from the enormous space would be highly data-inefficient. Instead, we suggest that KBQA models should have three levels of built-in generalization: i.i.d, compositional, and zero-shot. To facilitate the development of KBQA models with stronger generalization, we construct and release a new large-scale, high-quality dataset with 64,331 questions, GrailQA, and provide evaluation settings for all three levels of generalization. In addition, we propose a novel BERT-based KBQA model. The combination of our dataset and model enables us to thoroughly examine and demonstrate, for the first time, the key role of pre-trained contextual embeddings like BERT in the generalization of KBQA.
Inter-Series Attention Model for COVID-19 Forecasting
Oct 25, 2020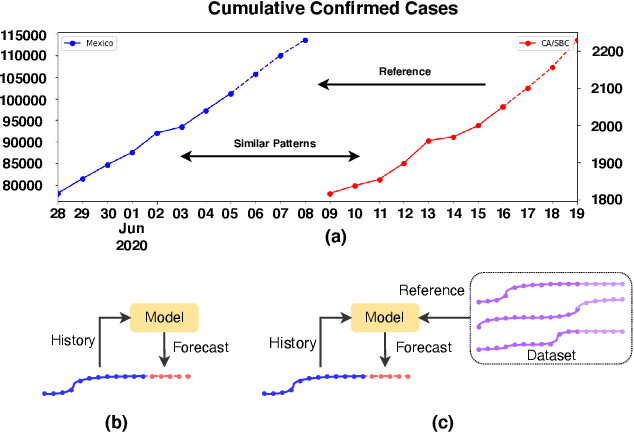

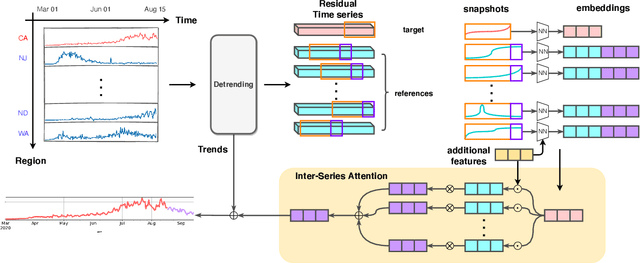
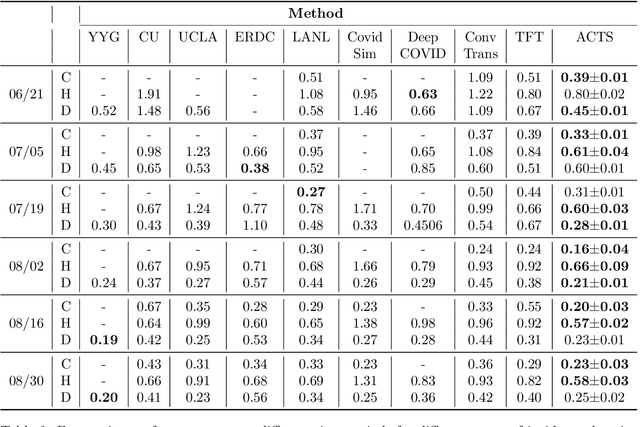
COVID-19 pandemic has an unprecedented impact all over the world since early 2020. During this public health crisis, reliable forecasting of the disease becomes critical for resource allocation and administrative planning. The results from compartmental models such as SIR and SEIR are popularly referred by CDC and news media. With more and more COVID-19 data becoming available, we examine the following question: Can a direct data-driven approach without modeling the disease spreading dynamics outperform the well referred compartmental models and their variants? In this paper, we show the possibility. It is observed that as COVID-19 spreads at different speed and scale in different geographic regions, it is highly likely that similar progression patterns are shared among these regions within different time periods. This intuition lead us to develop a new neural forecasting model, called Attention Crossing Time Series (\textbf{ACTS}), that makes forecasts via comparing patterns across time series obtained from multiple regions. The attention mechanism originally developed for natural language processing can be leveraged and generalized to materialize this idea. Among 13 out of 18 testings including forecasting newly confirmed cases, hospitalizations and deaths, \textbf{ACTS} outperforms all the leading COVID-19 forecasters highlighted by CDC.
CoCo: Controllable Counterfactuals for Evaluating Dialogue State Trackers
Oct 24, 2020

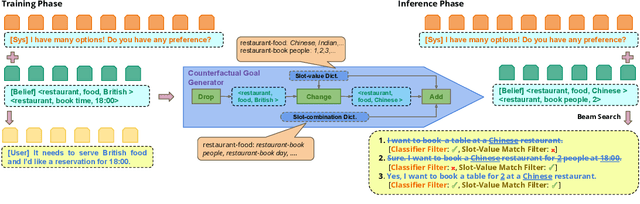
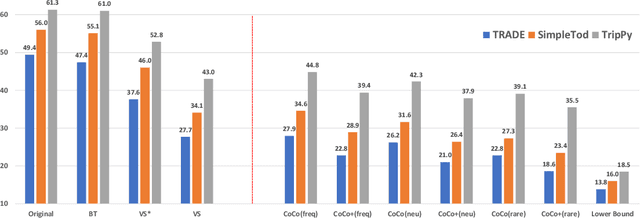
Dialogue state trackers have made significant progress on benchmark datasets, but their generalization capability to novel and realistic scenarios beyond the held-out conversations is less understood. We propose controllable counterfactuals (CoCo) to bridge this gap and evaluate dialogue state tracking (DST) models on novel scenarios, i.e., would the system successfully tackle the request if the user responded differently but still consistently with the dialogue flow? CoCo leverages turn-level belief states as counterfactual conditionals to produce novel conversation scenarios in two steps: (i) counterfactual goal generation at turn-level by dropping and adding slots followed by replacing slot values, (ii) counterfactual conversation generation that is conditioned on (i) and consistent with the dialogue flow. Evaluating state-of-the-art DST models on MultiWOZ dataset with CoCo-generated counterfactuals results in a significant performance drop of up to 30.8% (from 49.4% to 18.6%) in absolute joint goal accuracy. In comparison, widely used techniques like paraphrasing only affect the accuracy by at most 2%. Human evaluations show that CoCo-generated conversations perfectly reflect the underlying user goal with more than 95% accuracy and are as human-like as the original conversations, further strengthening its reliability and promise to be adopted as part of the robustness evaluation of DST models.
KGPT: Knowledge-Grounded Pre-Training for Data-to-Text Generation
Oct 11, 2020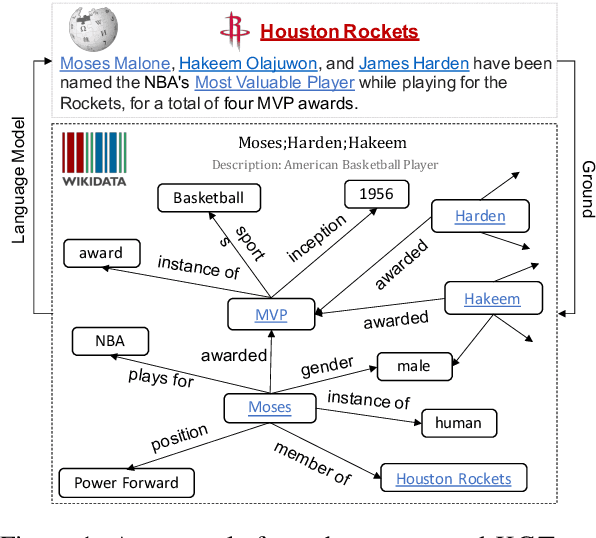

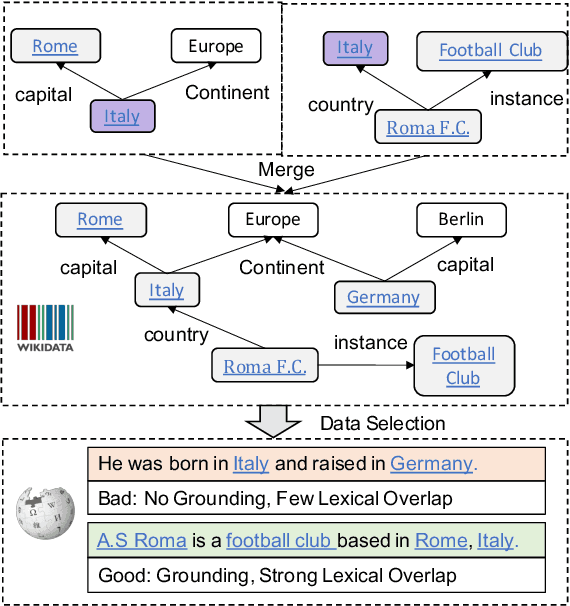
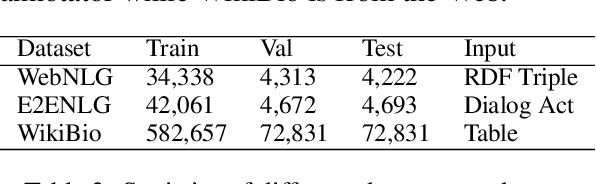
Data-to-text generation has recently attracted substantial interests due to its wide applications. Existing methods have shown impressive performance on an array of tasks. However, they rely on a significant amount of labeled data for each task, which is costly to acquire and thus limits their application to new tasks and domains. In this paper, we propose to leverage pre-training and transfer learning to address this issue. We propose a knowledge-grounded pre-training (KGPT), which consists of two parts, 1) a general knowledge-grounded generation model to generate knowledge-enriched text. 2) a pre-training paradigm on a massive knowledge-grounded text corpus crawled from the web. The pre-trained model can be fine-tuned on various data-to-text generation tasks to generate task-specific text. We adopt three settings, namely fully-supervised, zero-shot, few-shot to evaluate its effectiveness. Under the fully-supervised setting, our model can achieve remarkable gains over the known baselines. Under zero-shot setting, our model without seeing any examples achieves over 30 ROUGE-L on WebNLG while all other baselines fail. Under the few-shot setting, our model only needs about one-fifteenth as many labeled examples to achieve the same level of performance as baseline models. These experiments consistently prove the strong generalization ability of our proposed framework https://github.com/wenhuchen/KGPT.
Neural Assistant: Joint Action Prediction, Response Generation, and Latent Knowledge Reasoning
Oct 31, 2019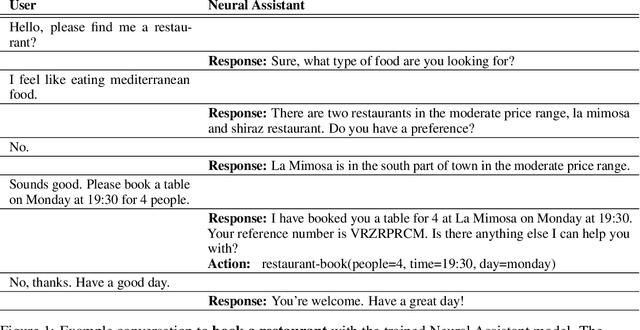
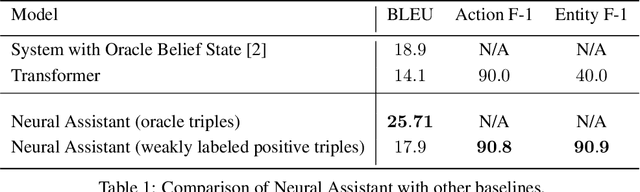
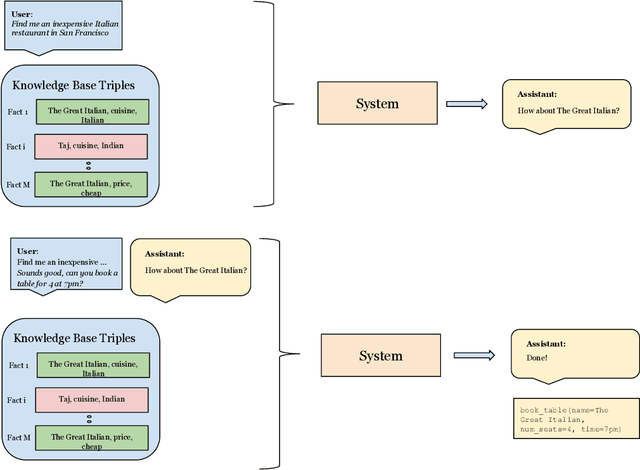
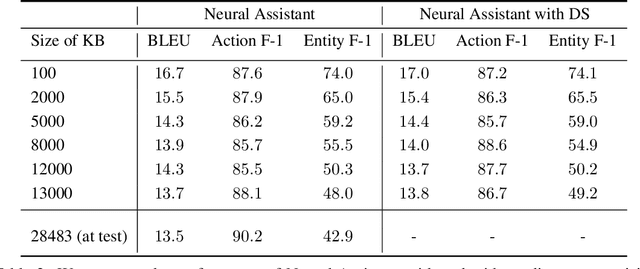
Task-oriented dialog presents a difficult challenge encompassing multiple problems including multi-turn language understanding and generation, knowledge retrieval and reasoning, and action prediction. Modern dialog systems typically begin by converting conversation history to a symbolic object referred to as belief state by using supervised learning. The belief state is then used to reason on an external knowledge source whose result along with the conversation history is used in action prediction and response generation tasks independently. Such a pipeline of individually optimized components not only makes the development process cumbersome but also makes it non-trivial to leverage session-level user reinforcement signals. In this paper, we develop Neural Assistant: a single neural network model that takes conversation history and an external knowledge source as input and jointly produces both text response and action to be taken by the system as output. The model learns to reason on the provided knowledge source with weak supervision signal coming from the text generation and the action prediction tasks, hence removing the need for belief state annotations. In the MultiWOZ dataset, we study the effect of distant supervision, and the size of knowledge base on model performance. We find that the Neural Assistant without belief states is able to incorporate external knowledge information achieving higher factual accuracy scores compared to Transformer. In settings comparable to reported baseline systems, Neural Assistant when provided with oracle belief state significantly improves language generation performance.
You May Not Need Order in Time Series Forecasting
Oct 21, 2019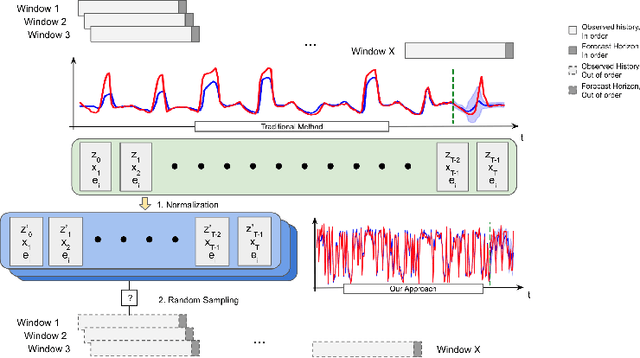
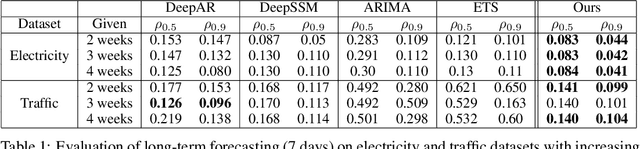
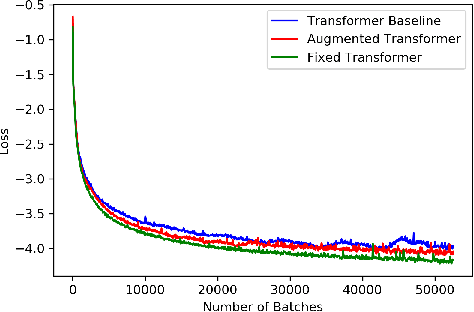
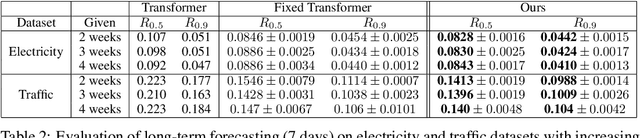
Time series forecasting with limited data is a challenging yet critical task. While transformers have achieved outstanding performances in time series forecasting, they often require many training samples due to the large number of trainable parameters. In this paper, we propose a training technique for transformers that prepares the training windows through random sampling. As input time steps need not be consecutive, the number of distinct samples increases from linearly to combinatorially many. By breaking the temporal order, this technique also helps transformers to capture dependencies among time steps in finer granularity. We achieve competitive results compared to the state-of-the-art on real-world datasets.
Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting
Jun 29, 2019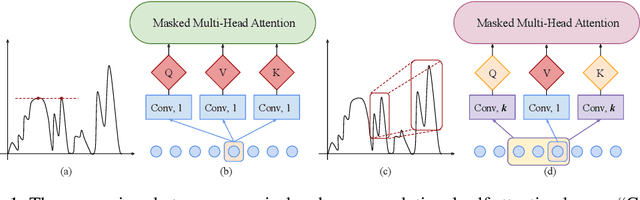
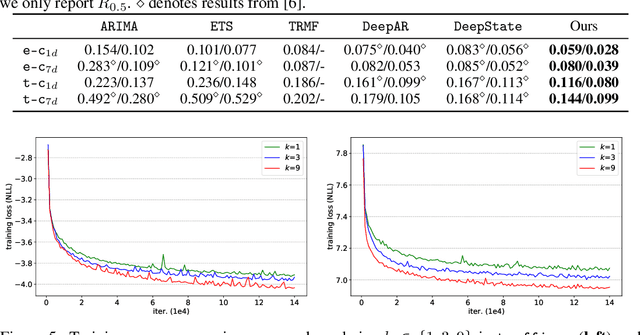
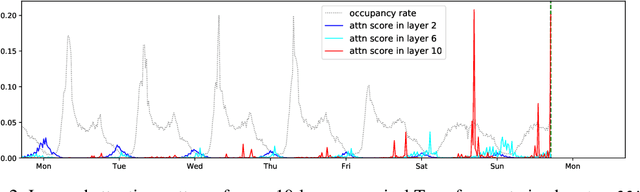

Time series forecasting is an important problem across many domains, including predictions of solar plant energy output, electricity consumption, and traffic jam situation. In this paper, we propose to tackle such forecasting problem with Transformer. Although impressed by its performance in our preliminary study, we found its two major weaknesses: (1) locality-agnostics: the point-wise dot-product self attention in canonical Transformer architecture is insensitive to local context, which can make the model prone to anomalies in time series; (2) memory bottleneck: space complexity of canonical Transformer grows quadratically with sequence length $L$, making modeling long time series infeasible. In order to solve these two issues, we first propose convolutional self attention by producing queries and keys with causal convolution so that local context can be better incorporated into attention mechanism. Then, we propose LogSparse Transformer with only $O(L(\log L)^{2})$ memory cost, improving the time series forecasting in finer granularity under constrained memory budget. Our experiments on both synthetic data and real-world datasets show that it compares favorably to the state-of-the-art.
Semantically Conditioned Dialog Response Generation via Hierarchical Disentangled Self-Attention
Jun 09, 2019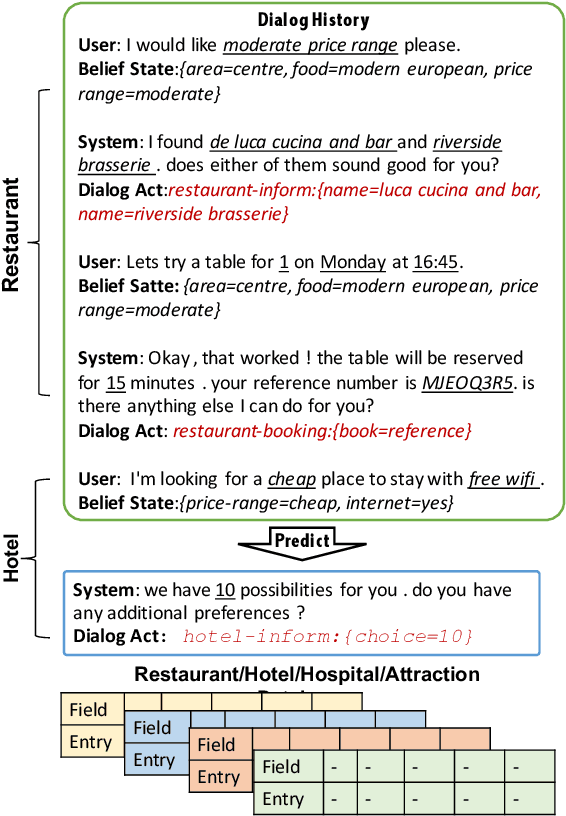

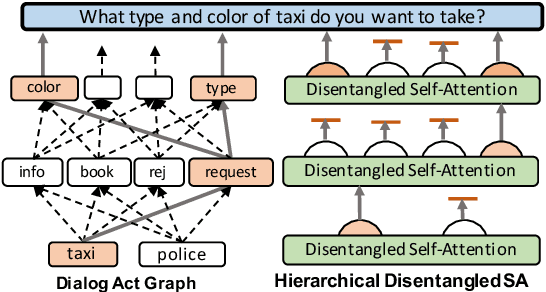
Semantically controlled neural response generation on limited-domain has achieved great performance. However, moving towards multi-domain large-scale scenarios are shown to be difficult because the possible combinations of semantic inputs grow exponentially with the number of domains. To alleviate such scalability issue, we exploit the structure of dialog acts to build a multi-layer hierarchical graph, where each act is represented as a root-to-leaf route on the graph. Then, we incorporate such graph structure prior as an inductive bias to build a hierarchical disentangled self-attention network, where we disentangle attention heads to model designated nodes on the dialog act graph. By activating different (disentangled) heads at each layer, combinatorially many dialog act semantics can be modeled to control the neural response generation. On the large-scale Multi-Domain-WOZ dataset, our model can yield a significant improvement over the baselines on various automatic and human evaluation metrics.
Global Textual Relation Embedding for Relational Understanding
Jun 03, 2019
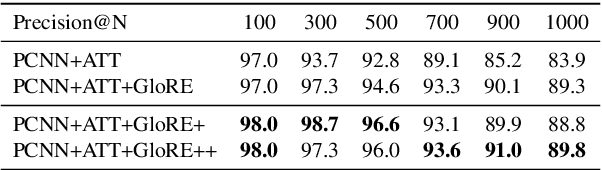
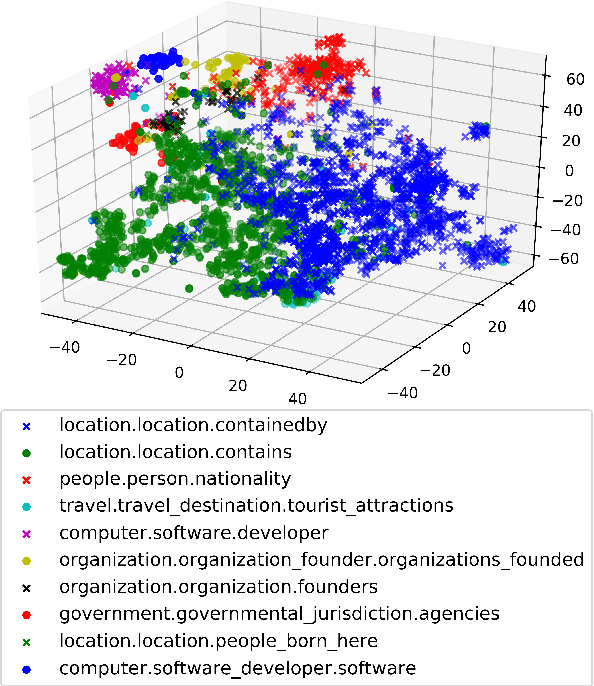
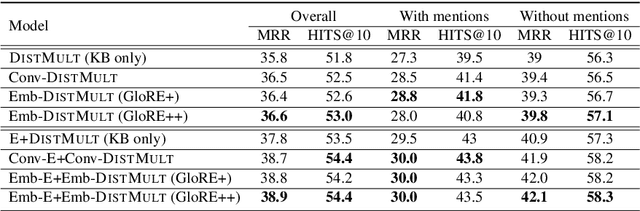
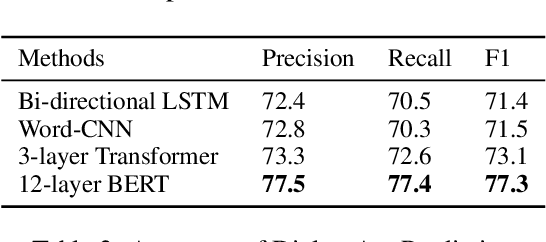
Pre-trained embeddings such as word embeddings and sentence embeddings are fundamental tools facilitating a wide range of downstream NLP tasks. In this work, we investigate how to learn a general-purpose embedding of textual relations, defined as the shortest dependency path between entities. Textual relation embedding provides a level of knowledge between word/phrase level and sentence level, and we show that it can facilitate downstream tasks requiring relational understanding of the text. To learn such an embedding, we create the largest distant supervision dataset by linking the entire English ClueWeb09 corpus to Freebase. We use global co-occurrence statistics between textual and knowledge base relations as the supervision signal to train the embedding. Evaluation on two relational understanding tasks demonstrates the usefulness of the learned textual relation embedding. The data and code can be found at https://github.com/czyssrs/GloREPlus
How Large a Vocabulary Does Text Classification Need? A Variational Approach to Vocabulary Selection
Apr 03, 2019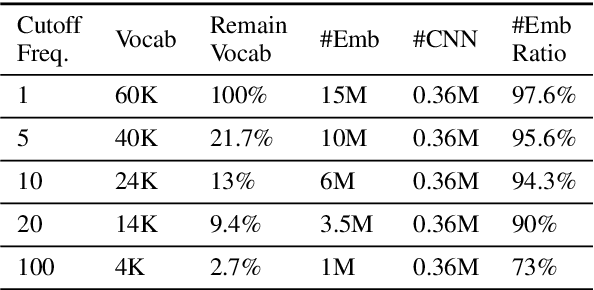


With the rapid development in deep learning, deep neural networks have been widely adopted in many real-life natural language applications. Under deep neural networks, a pre-defined vocabulary is required to vectorize text inputs. The canonical approach to select pre-defined vocabulary is based on the word frequency, where a threshold is selected to cut off the long tail distribution. However, we observed that such simple approach could easily lead to under-sized vocabulary or over-sized vocabulary issues. Therefore, we are interested in understanding how the end-task classification accuracy is related to the vocabulary size and what is the minimum required vocabulary size to achieve a specific performance. In this paper, we provide a more sophisticated variational vocabulary dropout (VVD) based on variational dropout to perform vocabulary selection, which can intelligently select the subset of the vocabulary to achieve the required performance. To evaluate different algorithms on the newly proposed vocabulary selection problem, we propose two new metrics: Area Under Accuracy-Vocab Curve and Vocab Size under X\% Accuracy Drop. Through extensive experiments on various NLP classification tasks, our variational framework is shown to significantly outperform the frequency-based and other selection baselines on these metrics.