 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIMBA: ABidirectional Retrieval Forward Simulation Framework for Modeling FY-4A GIIRS Hyperspectral Infrared Radiances Toward NWP Applications
Jun 18, 2026Hyperspectral infrared observations are an important data source for numerical weather prediction (NWP) because they provide rich information on the vertical structure of atmospheric temperature and humidity. However, most existing deep learning methods mainly focus on one-way retrieval from radiances to atmospheric profiles, while the reverse radiance simulation process and the consistency between atmospheric state space and radiance observation space are insufficiently considered. In this study, we propose SIMBA, a unified bidirectional retrieval-forward simulation framework for FY-4A GIIRS hyperspectral infrared radiance modeling toward NWP applications. The framework jointly performs atmospheric profile retrieval and radiance reconstruction, introduces a cycle-consistency constraint to strengthen the coupling between the two processes, and employs a bidirectional Mamba state-space module to capture long-range dependencies along pressure levels. Using collocated FY-4A GIIRS observations and ERA5 reanalysis data, the proposed method is evaluated for temperature retrieval, specific humidity retrieval, long-wave radiance reconstruction, and medium-wave radiance reconstruction. Experimental results show that SIMBA outperforms several representative deep learning baselines across both retrieval and reconstruction tasks, while ablation experiments confirm the contribution of the bidirectional design and cycle-consistency mechanism. These results demonstrate that the proposed framework is effective for joint atmospheric profile retrieval and hyperspectral infrared radiance modeling, and suggest potential for future Jacobian-related analysis and NWP-oriented extensions.
SGMAGNet: A Baseline Model for 3D Cloud Phase Structure Reconstruction on a New Passive Active Satellite Benchmark
Sep 19, 2025Cloud phase profiles are critical for numerical weather prediction (NWP), as they directly affect radiative transfer and precipitation processes. In this study, we present a benchmark dataset and a baseline framework for transforming multimodal satellite observations into detailed 3D cloud phase structures, aiming toward operational cloud phase profile retrieval and future integration with NWP systems to improve cloud microphysics parameterization. The multimodal observations consist of (1) high--spatiotemporal--resolution, multi-band visible (VIS) and thermal infrared (TIR) imagery from geostationary satellites, and (2) accurate vertical cloud phase profiles from spaceborne lidar (CALIOP\slash CALIPSO) and radar (CPR\slash CloudSat). The dataset consists of synchronized image--profile pairs across diverse cloud regimes, defining a supervised learning task: given VIS/TIR patches, predict the corresponding 3D cloud phase structure. We adopt SGMAGNet as the main model and compare it with several baseline architectures, including UNet variants and SegNet, all designed to capture multi-scale spatial patterns. Model performance is evaluated using standard classification metrics, including Precision, Recall, F1-score, and IoU. The results demonstrate that SGMAGNet achieves superior performance in cloud phase reconstruction, particularly in complex multi-layer and boundary transition regions. Quantitatively, SGMAGNet attains a Precision of 0.922, Recall of 0.858, F1-score of 0.763, and an IoU of 0.617, significantly outperforming all baselines across these key metrics.
Targeted aspect based multimodal sentiment analysis:an attention capsule extraction and multi-head fusion network
Mar 13, 2021
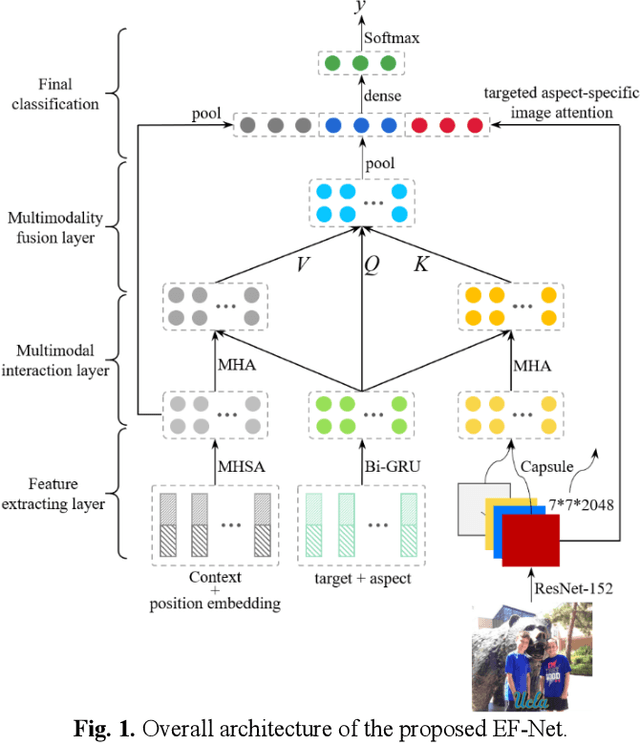
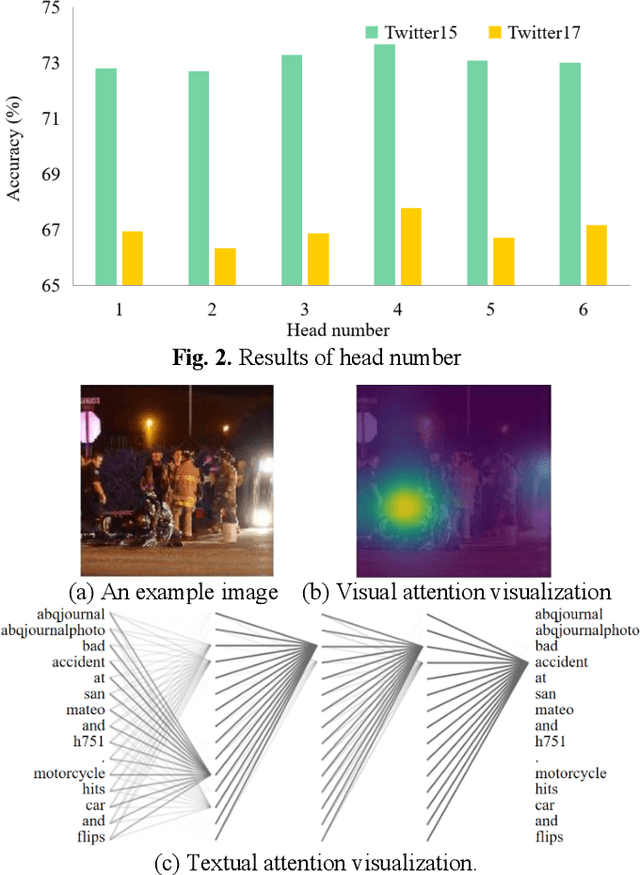
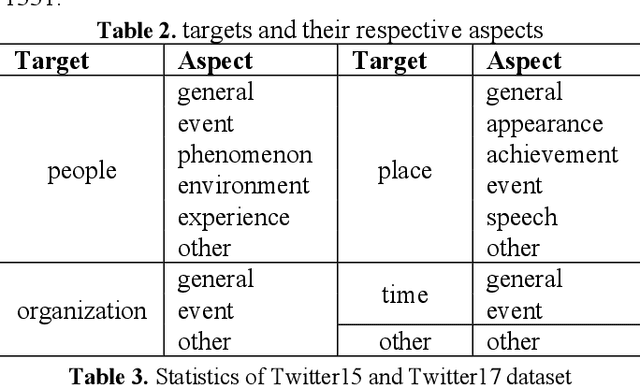
Multimodal sentiment analysis has currently identified its significance in a variety of domains. For the purpose of sentiment analysis, different aspects of distinguishing modalities, which correspond to one target, are processed and analyzed. In this work, we propose the targeted aspect-based multimodal sentiment analysis (TABMSA) for the first time. Furthermore, an attention capsule extraction and multi-head fusion network (EF-Net) on the task of TABMSA is devised. The multi-head attention (MHA) based network and the ResNet-152 are employed to deal with texts and images, respectively. The integration of MHA and capsule network aims to capture the interaction among the multimodal inputs. In addition to the targeted aspect, the information from the context and the image is also incorporated for sentiment delivered. We evaluate the proposed model on two manually annotated datasets. the experimental results demonstrate the effectiveness of our proposed model for this new task.