 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Temporal Fusion for Video-based Person Re-identification on Semantic and Time Aspect
Nov 28, 2019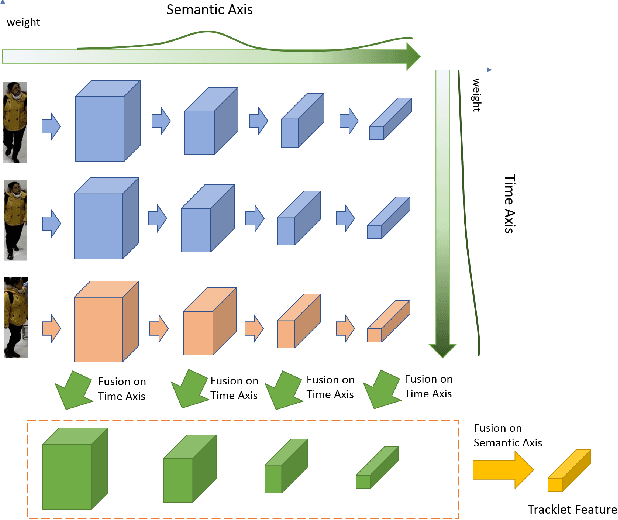
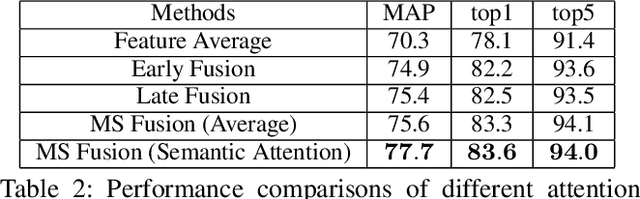
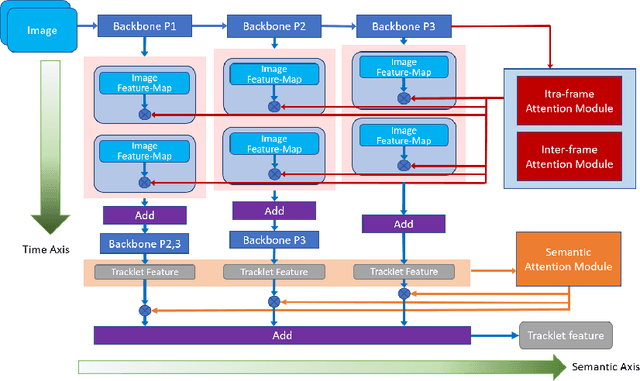
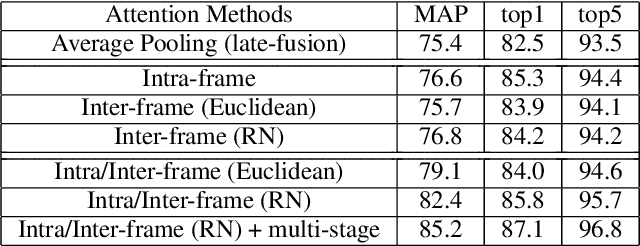
Recently, the research interest of person re-identification (ReID) has gradually turned to video-based methods, which acquire a person representation by aggregating frame features of an entire video. However, existing video-based ReID methods do not consider the semantic difference brought by the outputs of different network stages, which potentially compromises the information richness of the person features. Furthermore, traditional methods ignore important relationship among frames, which causes information redundancy in fusion along the time axis. To address these issues, we propose a novel general temporal fusion framework to aggregate frame features on both semantic aspect and time aspect. As for the semantic aspect, a multi-stage fusion network is explored to fuse richer frame features at multiple semantic levels, which can effectively reduce the information loss caused by the traditional single-stage fusion. While, for the time axis, the existing intra-frame attention method is improved by adding a novel inter-frame attention module, which effectively reduces the information redundancy in temporal fusion by taking the relationship among frames into consideration. The experimental results show that our approach can effectively improve the video-based re-identification accuracy, achieving the state-of-the-art performance.
Semi-Supervised Adversarial Monocular Depth Estimation
Aug 06, 2019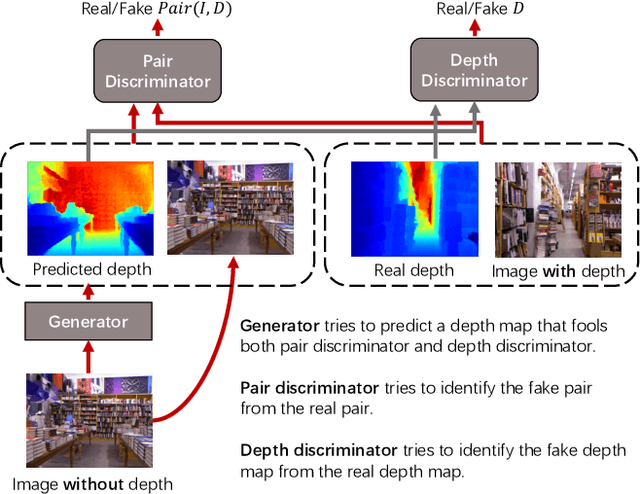
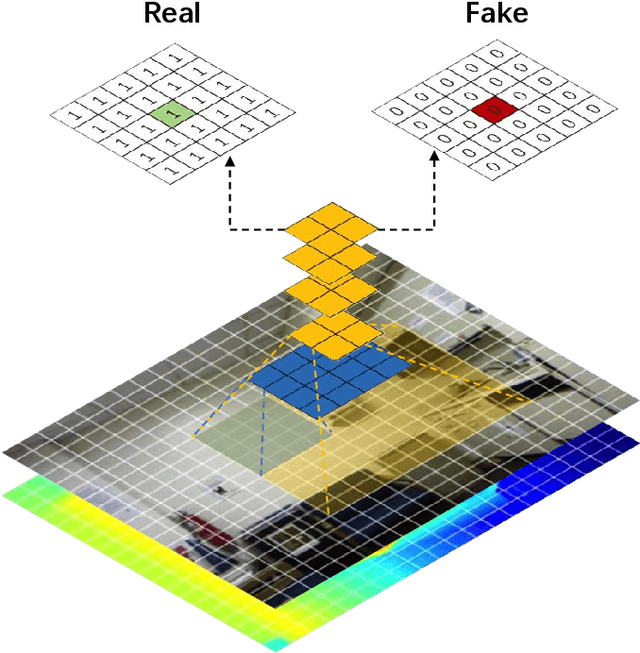
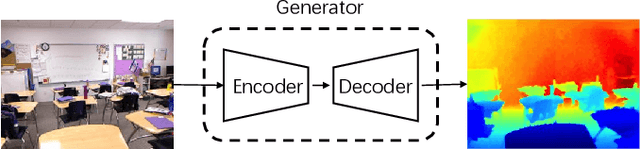
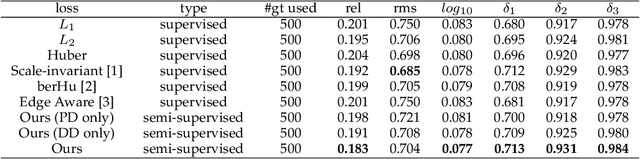
In this paper, we address the problem of monocular depth estimation when only a limited number of training image-depth pairs are available. To achieve a high regression accuracy, the state-of-the-art estimation methods rely on CNNs trained with a large number of image-depth pairs, which are prohibitively costly or even infeasible to acquire. Aiming to break the curse of such expensive data collections, we propose a semi-supervised adversarial learning framework that only utilizes a small number of image-depth pairs in conjunction with a large number of easily-available monocular images to achieve high performance. In particular, we use one generator to regress the depth and two discriminators to evaluate the predicted depth , i.e., one inspects the image-depth pair while the other inspects the depth channel alone. These two discriminators provide their feedbacks to the generator as the loss to generate more realistic and accurate depth predictions. Experiments show that the proposed approach can (1) improve most state-of-the-art models on the NYUD v2 dataset by effectively leveraging additional unlabeled data sources; (2) reach state-of-the-art accuracy when the training set is small, e.g., on the Make3D dataset; (3) adapt well to an unseen new dataset (Make3D in our case) after training on an annotated dataset (KITTI in our case).
Unsupervised Person Re-identification by Soft Multilabel Learning
Apr 08, 2019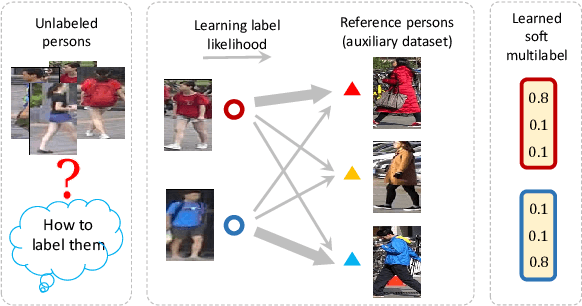
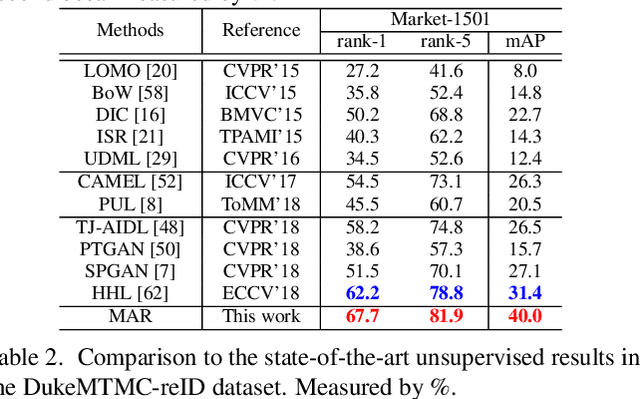
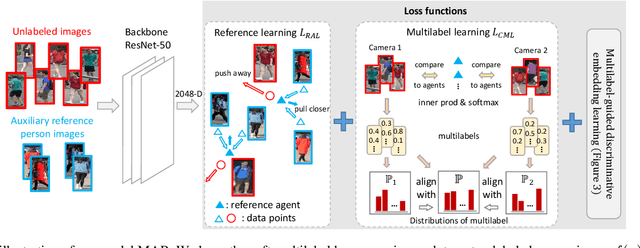
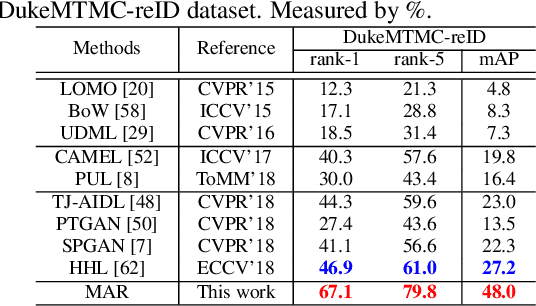
Although unsupervised person re-identification (RE-ID) has drawn increasing research attentions due to its potential to address the scalability problem of supervised RE-ID models, it is very challenging to learn discriminative information in the absence of pairwise labels across disjoint camera views. To overcome this problem, we propose a deep model for the soft multilabel learning for unsupervised RE-ID. The idea is to learn a soft multilabel (real-valued label likelihood vector) for each unlabeled person by comparing (and representing) the unlabeled person with a set of known reference persons from an auxiliary domain. We propose the soft multilabel-guided hard negative mining to learn a discriminative embedding for the unlabeled target domain by exploring the similarity consistency of the visual features and the soft multilabels of unlabeled target pairs. Since most target pairs are cross-view pairs, we develop the cross-view consistent soft multilabel learning to achieve the learning goal that the soft multilabels are consistently good across different camera views. To enable effecient soft multilabel learning, we introduce the reference agent learning to represent each reference person by a reference agent in a joint embedding. We evaluate our unified deep model on Market-1501 and DukeMTMC-reID. Our model outperforms the state-of-the-art unsupervised RE-ID methods by clear margins. Code is available at https://github.com/KovenYu/MAR.
A Coarse-to-fine Pyramidal Model for Person Re-identification via Multi-Loss Dynamic Training
Oct 30, 2018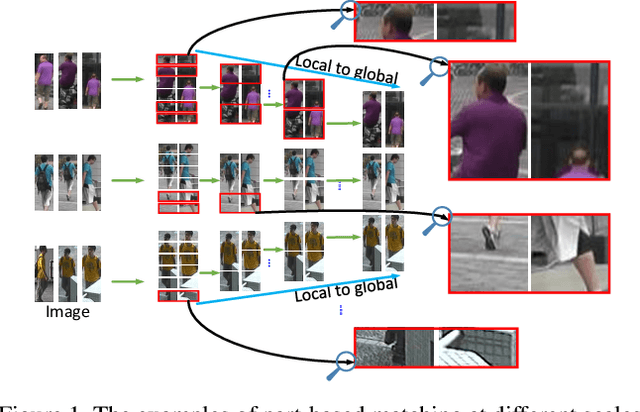
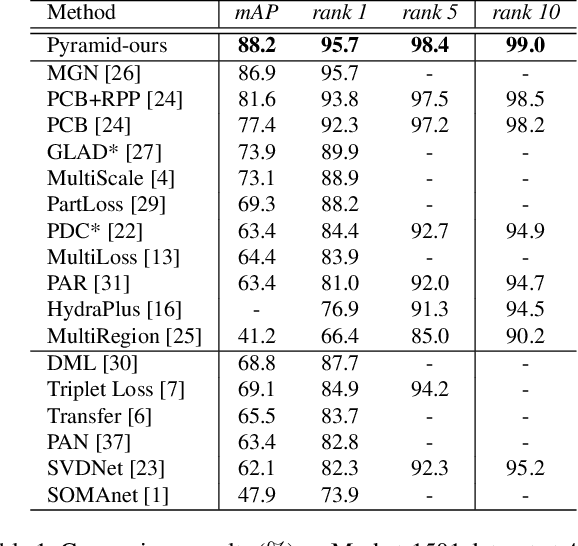
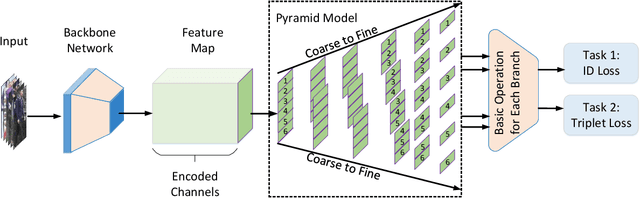
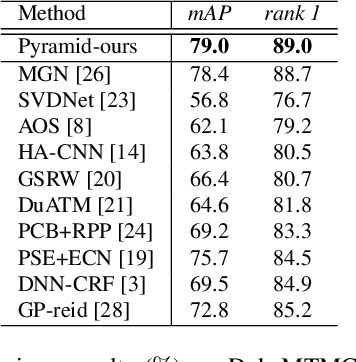
Most existing Re-IDentification (Re-ID) methods are highly dependent on precise bounding boxes that enable images to be aligned with each other. However, due to the inevitable challenging scenarios, current detection models often output inaccurate bounding boxes yet, which inevitably worsen the performance of these Re-ID algorithms. In this paper, to relax the requirement, we propose a novel coarse-to-fine pyramid model that not only incorporates local and global information, but also integrates the gradual cues between them. The pyramid model is able to match the cues at different scales and then search for the correct image of the same identity even when the image pair are not aligned. In addition, in order to learn discriminative identity representation, we explore a dynamic training scheme to seamlessly unify two losses and extract appropriate shared information between them. Experimental results clearly demonstrate that the proposed method achieves the state-of-the-art results on three datasets and it is worth noting that our approach exceeds the current best method by 9.5% on the most challenging dataset CUHK03.
Adversarial Attribute-Image Person Re-identification
Jul 04, 2018
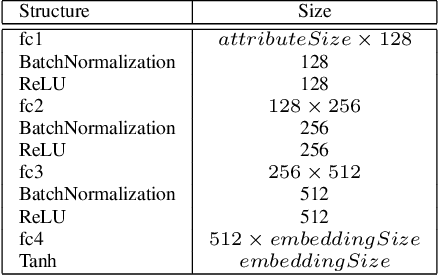
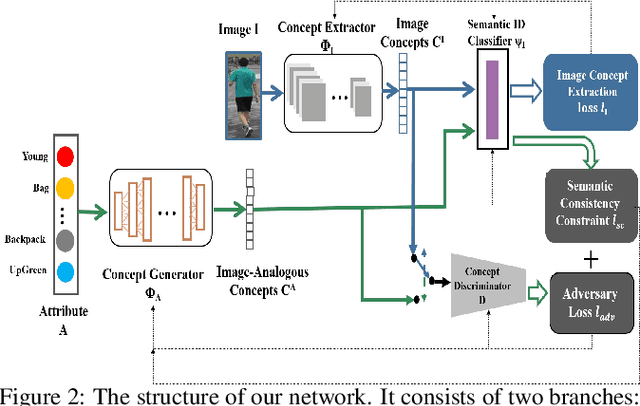
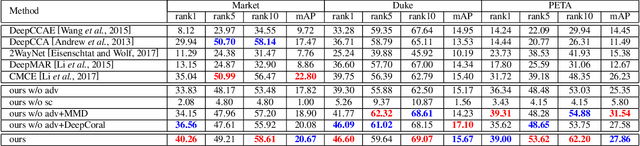
While attributes have been widely used for person re-identification (Re-ID) which aims at matching the same person images across disjoint camera views, they are used either as extra features or for performing multi-task learning to assist the image-image matching task. However, how to find a set of person images according to a given attribute description, which is very practical in many surveillance applications, remains a rarely investigated cross-modality matching problem in person Re-ID. In this work, we present this challenge and formulate this task as a joint space learning problem. By imposing an attribute-guided attention mechanism for images and a semantic consistent adversary strategy for attributes, each modality, i.e., images and attributes, successfully learns semantically correlated concepts under the guidance of the other. We conducted extensive experiments on three attribute datasets and demonstrated that the proposed joint space learning method is so far the most effective method for the attribute-image cross-modality person Re-ID problem.
Automatic Script Identification in the Wild
May 12, 2015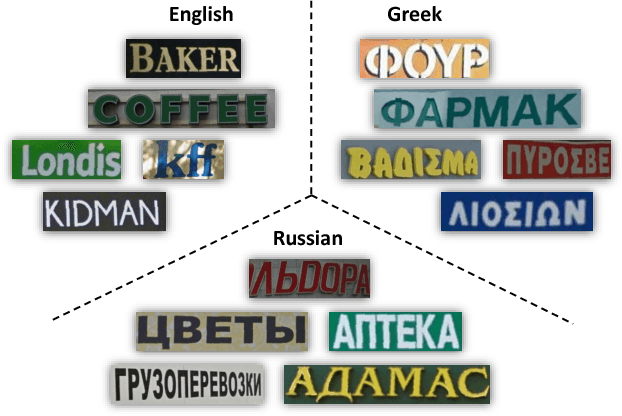


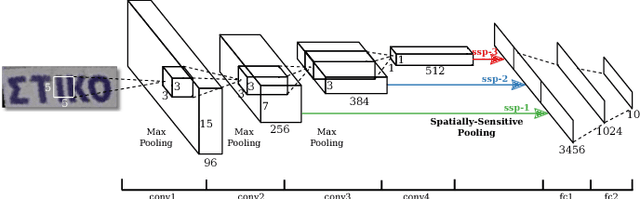
With the rapid increase of transnational communication and cooperation, people frequently encounter multilingual scenarios in various situations. In this paper, we are concerned with a relatively new problem: script identification at word or line levels in natural scenes. A large-scale dataset with a great quantity of natural images and 10 types of widely used languages is constructed and released. In allusion to the challenges in script identification in real-world scenarios, a deep learning based algorithm is proposed. The experiments on the proposed dataset demonstrate that our algorithm achieves superior performance, compared with conventional image classification methods, such as the original CNN architecture and LLC.