 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Pointly-Supervised Instance Segmentation
Jul 23, 2022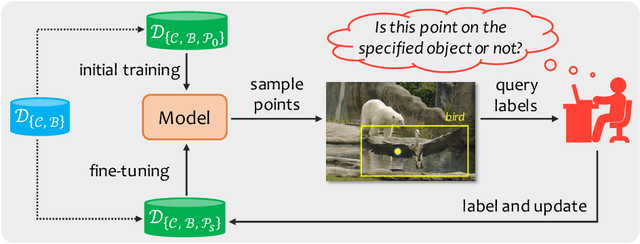
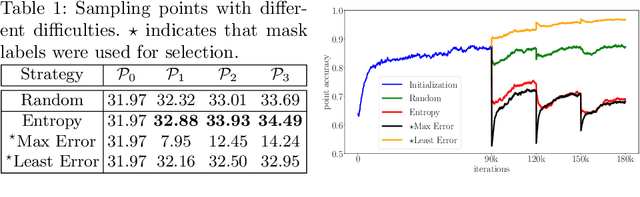
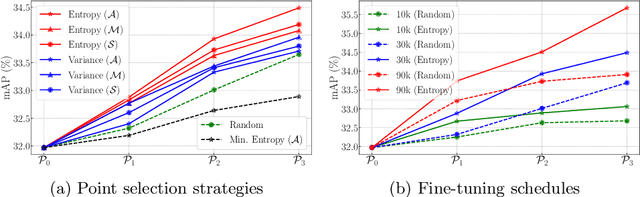

The requirement of expensive annotations is a major burden for training a well-performed instance segmentation model. In this paper, we present an economic active learning setting, named active pointly-supervised instance segmentation (APIS), which starts with box-level annotations and iteratively samples a point within the box and asks if it falls on the object. The key of APIS is to find the most desirable points to maximize the segmentation accuracy with limited annotation budgets. We formulate this setting and propose several uncertainty-based sampling strategies. The model developed with these strategies yields consistent performance gain on the challenging MS-COCO dataset, compared against other learning strategies. The results suggest that APIS, integrating the advantages of active learning and point-based supervision, is an effective learning paradigm for label-efficient instance segmentation.
SARNet: Semantic Augmented Registration of Large-Scale Urban Point Clouds
Jun 27, 2022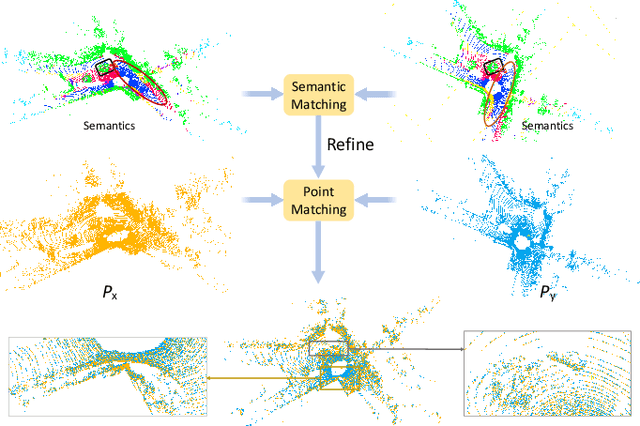
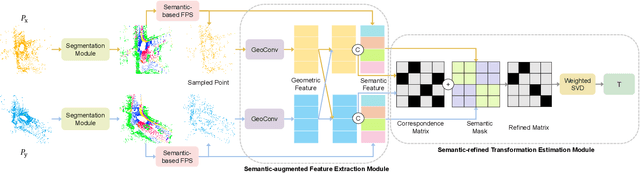
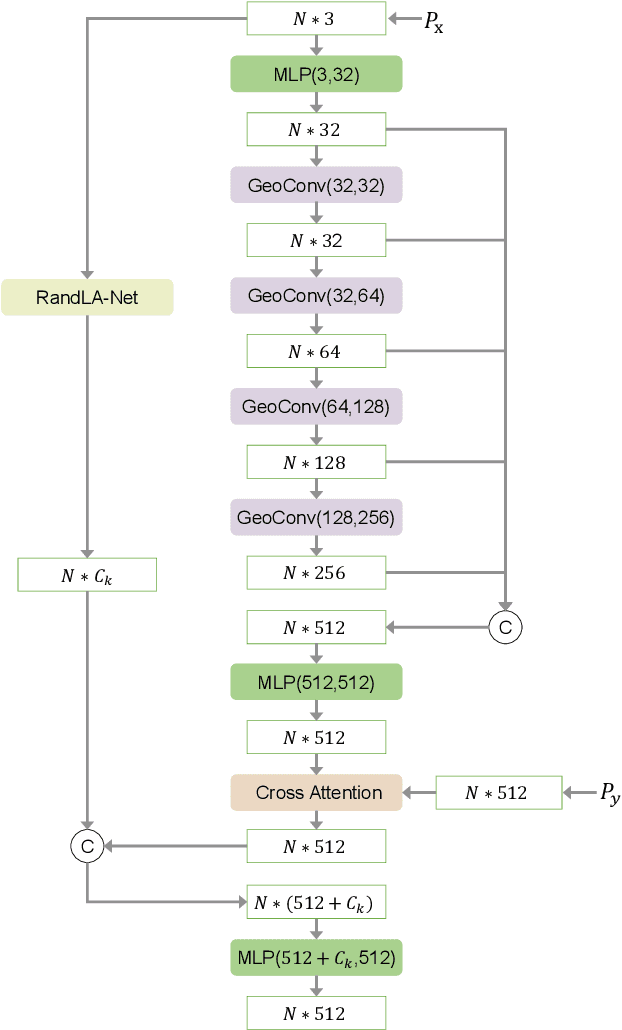
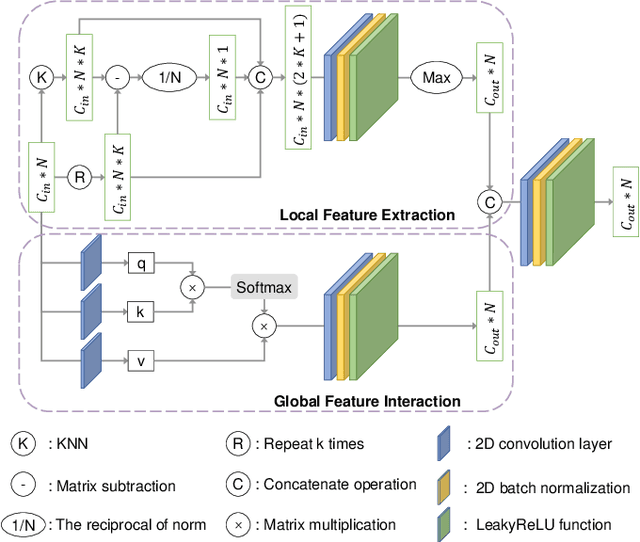
Registering urban point clouds is a quite challenging task due to the large-scale, noise and data incompleteness of LiDAR scanning data. In this paper, we propose SARNet, a novel semantic augmented registration network aimed at achieving efficient registration of urban point clouds at city scale. Different from previous methods that construct correspondences only in the point-level space, our approach fully exploits semantic features as assistance to improve registration accuracy. Specifically, we extract per-point semantic labels with advanced semantic segmentation networks and build a prior semantic part-to-part correspondence. Then we incorporate the semantic information into a learning-based registration pipeline, consisting of three core modules: a semantic-based farthest point sampling module to efficiently filter out outliers and dynamic objects; a semantic-augmented feature extraction module for learning more discriminative point descriptors; a semantic-refined transformation estimation module that utilizes prior semantic matching as a mask to refine point correspondences by reducing false matching for better convergence. We evaluate the proposed SARNet extensively by using real-world data from large regions of urban scenes and comparing it with alternative methods. The code is available at https://github.com/WinterCodeForEverything/SARNet.
Masked Autoencoders are Robust Data Augmentors
Jun 10, 2022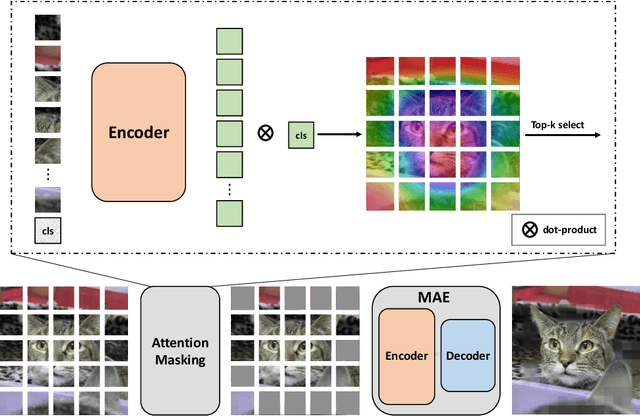
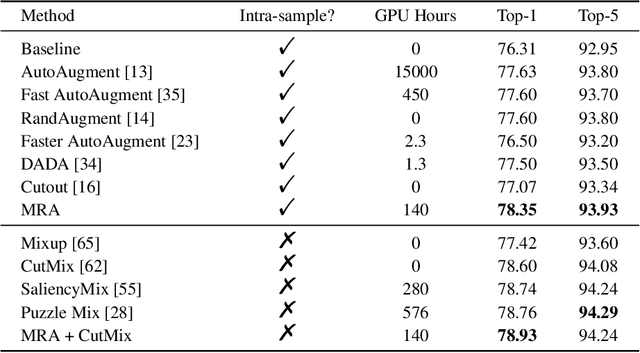
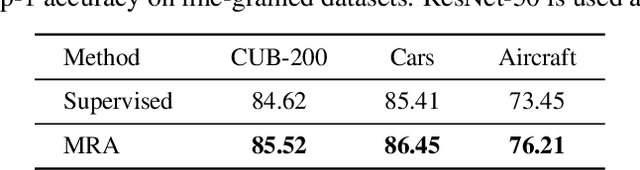

Deep neural networks are capable of learning powerful representations to tackle complex vision tasks but expose undesirable properties like the over-fitting issue. To this end, regularization techniques like image augmentation are necessary for deep neural networks to generalize well. Nevertheless, most prevalent image augmentation recipes confine themselves to off-the-shelf linear transformations like scale, flip, and colorjitter. Due to their hand-crafted property, these augmentations are insufficient to generate truly hard augmented examples. In this paper, we propose a novel perspective of augmentation to regularize the training process. Inspired by the recent success of applying masked image modeling to self-supervised learning, we adopt the self-supervised masked autoencoder to generate the distorted view of the input images. We show that utilizing such model-based nonlinear transformation as data augmentation can improve high-level recognition tasks. We term the proposed method as \textbf{M}ask-\textbf{R}econstruct \textbf{A}ugmentation (MRA). The extensive experiments on various image classification benchmarks verify the effectiveness of the proposed augmentation. Specifically, MRA consistently enhances the performance on supervised, semi-supervised as well as few-shot classification. The code will be available at \url{https://github.com/haohang96/MRA}.
Fast Dynamic Radiance Fields with Time-Aware Neural Voxels
May 30, 2022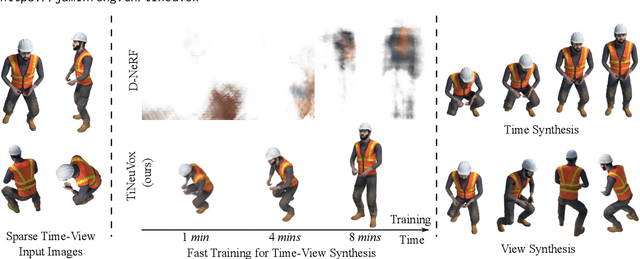

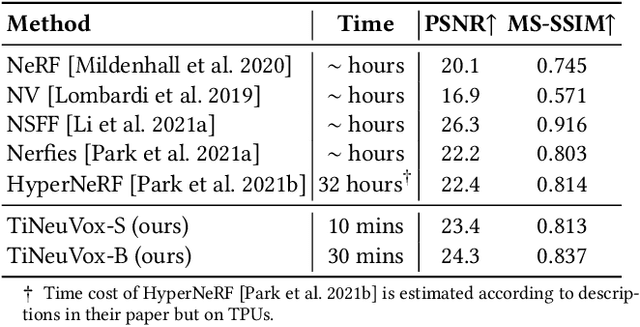
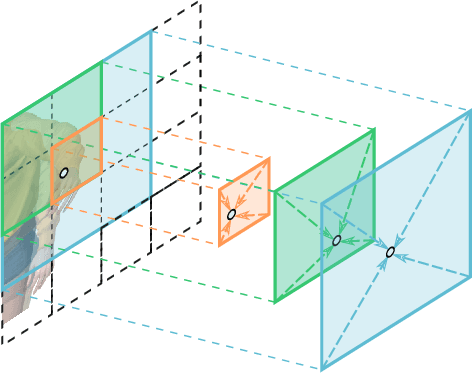
Neural radiance fields (NeRF) have shown great success in modeling 3D scenes and synthesizing novel-view images. However, most previous NeRF methods take much time to optimize one single scene. Explicit data structures, e.g. voxel features, show great potential to accelerate the training process. However, voxel features face two big challenges to be applied to dynamic scenes, i.e. modeling temporal information and capturing different scales of point motions. We propose a radiance field framework by representing scenes with time-aware voxel features, named as TiNeuVox. A tiny coordinate deformation network is introduced to model coarse motion trajectories and temporal information is further enhanced in the radiance network. A multi-distance interpolation method is proposed and applied on voxel features to model both small and large motions. Our framework significantly accelerates the optimization of dynamic radiance fields while maintaining high rendering quality. Empirical evaluation is performed on both synthetic and real scenes. Our TiNeuVox completes training with only 8 minutes and 8-MB storage cost while showing similar or even better rendering performance than previous dynamic NeRF methods.
Gradient Concealment: Free Lunch for Defending Adversarial Attacks
May 21, 2022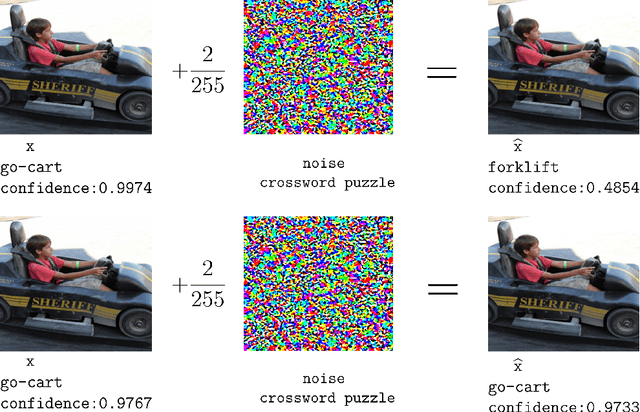
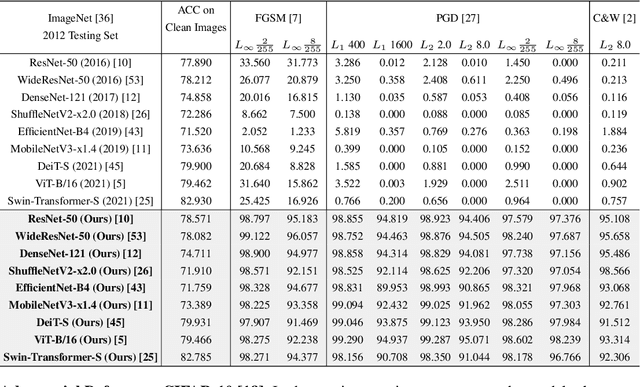
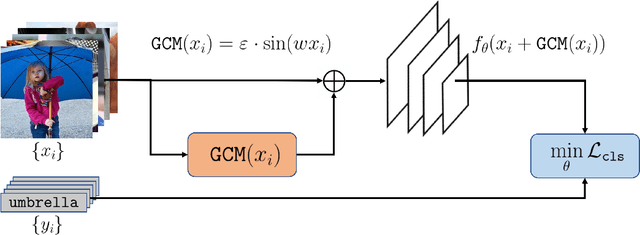
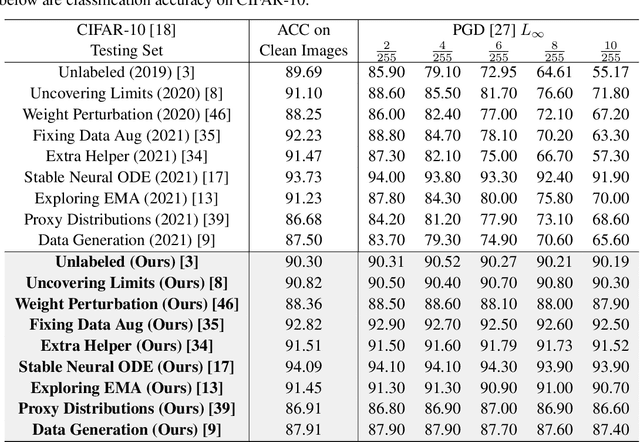
Recent studies show that the deep neural networks (DNNs) have achieved great success in various tasks. However, even the \emph{state-of-the-art} deep learning based classifiers are extremely vulnerable to adversarial examples, resulting in sharp decay of discrimination accuracy in the presence of enormous unknown attacks. Given the fact that neural networks are widely used in the open world scenario which can be safety-critical situations, mitigating the adversarial effects of deep learning methods has become an urgent need. Generally, conventional DNNs can be attacked with a dramatically high success rate since their gradient is exposed thoroughly in the white-box scenario, making it effortless to ruin a well trained classifier with only imperceptible perturbations in the raw data space. For tackling this problem, we propose a plug-and-play layer that is training-free, termed as \textbf{G}radient \textbf{C}oncealment \textbf{M}odule (GCM), concealing the vulnerable direction of gradient while guaranteeing the classification accuracy during the inference time. GCM reports superior defense results on the ImageNet classification benchmark, improving up to 63.41\% top-1 attack robustness (AR) when faced with adversarial inputs compared to the vanilla DNNs. Moreover, we use GCM in the CVPR 2022 Robust Classification Challenge, currently achieving \textbf{2nd} place in Phase II with only a tiny version of ConvNext. The code will be made available.
Beyond Masking: Demystifying Token-Based Pre-Training for Vision Transformers
Mar 27, 2022


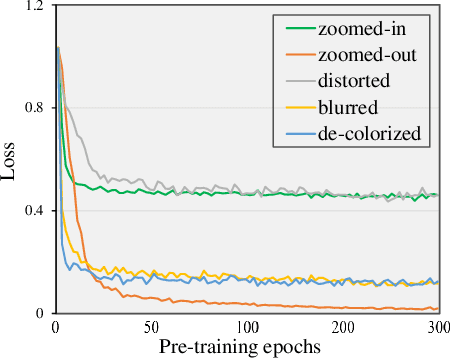
The past year has witnessed a rapid development of masked image modeling (MIM). MIM is mostly built upon the vision transformers, which suggests that self-supervised visual representations can be done by masking input image parts while requiring the target model to recover the missing contents. MIM has demonstrated promising results on downstream tasks, yet we are interested in whether there exist other effective ways to `learn by recovering missing contents'. In this paper, we investigate this topic by designing five other learning objectives that follow the same procedure as MIM but degrade the input image in different ways. With extensive experiments, we manage to summarize a few design principles for token-based pre-training of vision transformers. In particular, the best practice is obtained by keeping the original image style and enriching spatial masking with spatial misalignment -- this design achieves superior performance over MIM in a series of downstream recognition tasks without extra computational cost. The code is available at https://github.com/sunsmarterjie/beyond_masking.
Deep Point Cloud Simplification for High-quality Surface Reconstruction
Mar 17, 2022
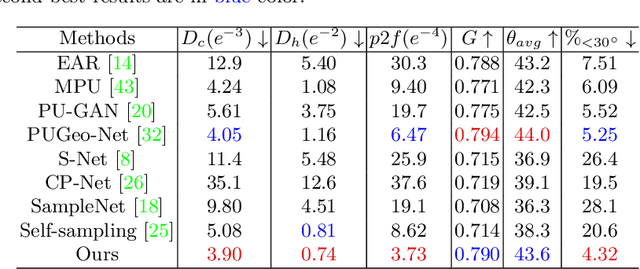


The growing size of point clouds enlarges consumptions of storage, transmission, and computation of 3D scenes. Raw data is redundant, noisy, and non-uniform. Therefore, simplifying point clouds for achieving compact, clean, and uniform points is becoming increasingly important for 3D vision and graphics tasks. Previous learning based methods aim to generate fewer points for scene understanding, regardless of the quality of surface reconstruction, leading to results with low reconstruction accuracy and bad point distribution. In this paper, we propose a novel point cloud simplification network (PCS-Net) dedicated to high-quality surface mesh reconstruction while maintaining geometric fidelity. We first learn a sampling matrix in a feature-aware simplification module to reduce the number of points. Then we propose a novel double-scale resampling module to refine the positions of the sampled points, to achieve a uniform distribution. To further retain important shape features, an adaptive sampling strategy with a novel saliency loss is designed. With our PCS-Net, the input non-uniform and noisy point cloud can be simplified in a feature-aware manner, i.e., points near salient features are consolidated but still with uniform distribution locally. Experiments demonstrate the effectiveness of our method and show that we outperform previous simplification or reconstruction-oriented upsampling methods.
MTLDesc: Looking Wider to Describe Better
Mar 14, 2022
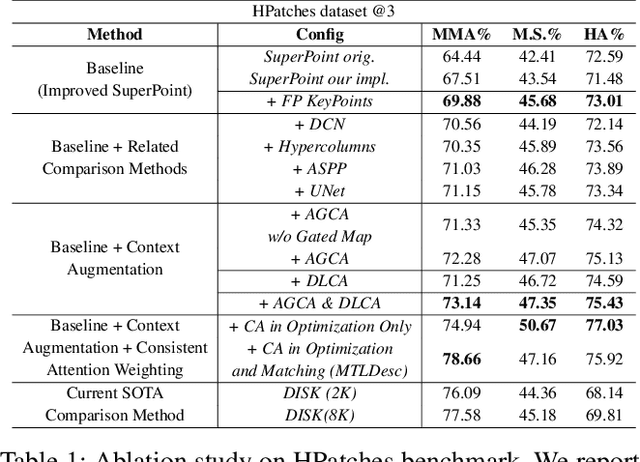
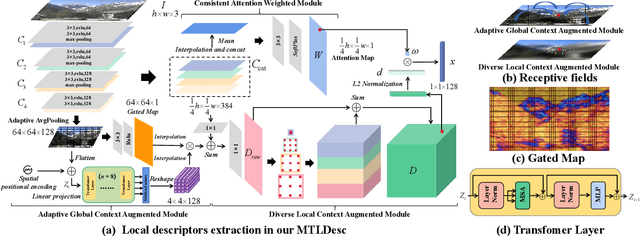
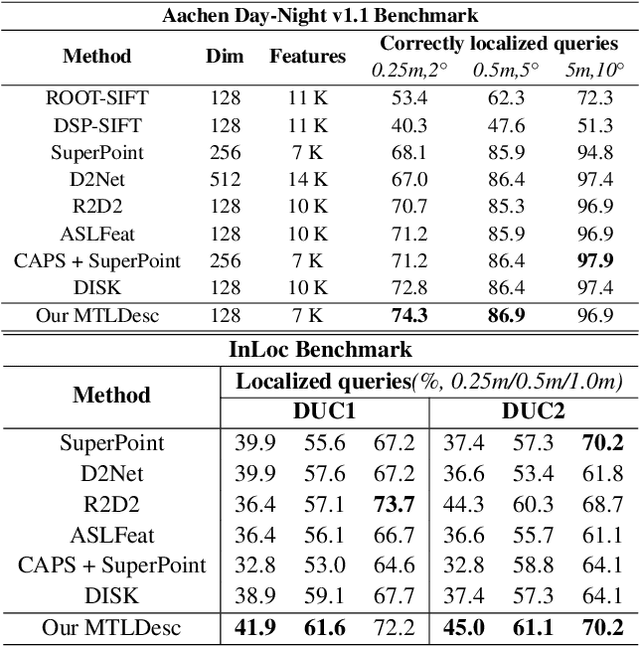
Limited by the locality of convolutional neural networks, most existing local features description methods only learn local descriptors with local information and lack awareness of global and surrounding spatial context. In this work, we focus on making local descriptors "look wider to describe better" by learning local Descriptors with More Than just Local information (MTLDesc). Specifically, we resort to context augmentation and spatial attention mechanisms to make our MTLDesc obtain non-local awareness. First, Adaptive Global Context Augmented Module and Diverse Local Context Augmented Module are proposed to construct robust local descriptors with context information from global to local. Second, Consistent Attention Weighted Triplet Loss is designed to integrate spatial attention awareness into both optimization and matching stages of local descriptors learning. Third, Local Features Detection with Feature Pyramid is given to obtain more stable and accurate keypoints localization. With the above innovations, the performance of our MTLDesc significantly surpasses the prior state-of-the-art local descriptors on HPatches, Aachen Day-Night localization and InLoc indoor localization benchmarks.
TAPE: Task-Agnostic Prior Embedding for Image Restoration
Mar 11, 2022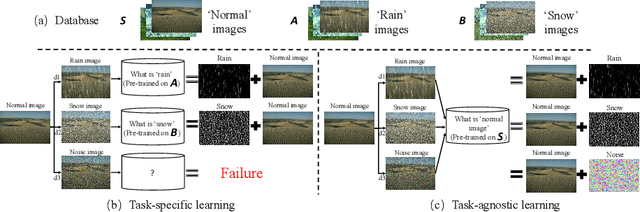

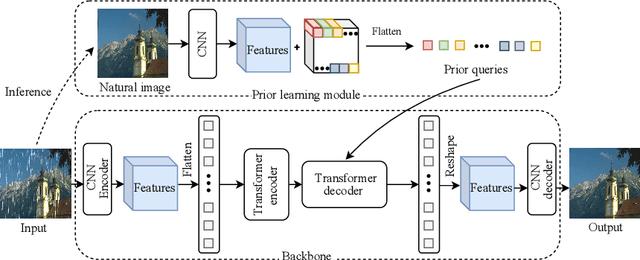

Learning an generalized prior for natural image restoration is an important yet challenging task. Early methods mostly involved handcrafted priors including normalized sparsity, L0 gradients, dark channel priors, etc. Recently, deep neural networks have been used to learn various image priors but do not guarantee to generalize. In this paper, we propose a novel approach that embeds a task-agnostic prior into a transformer. Our approach, named Task-Agnostic Prior Embedding (TAPE), consists of three stages, namely, task-agnostic pre-training, task-agnostic fine-tuning, and task-specific fine-tuning, where the first one embeds prior knowledge about natural images into the transformer and the latter two extracts the knowledge to assist downstream image restoration. Experiments on various types of degradation validate the effectiveness of TAPE. The image restoration performance in terms of PSNR is improved by as much as 1.45 dB and even outperforms task-specific algorithms. More importantly, TAPE shows the ability of disentangling generalized image priors from degraded images, which enjoys favorable transfer ability to unknown downstream tasks.
The KFIoU Loss for Rotated Object Detection
Feb 01, 2022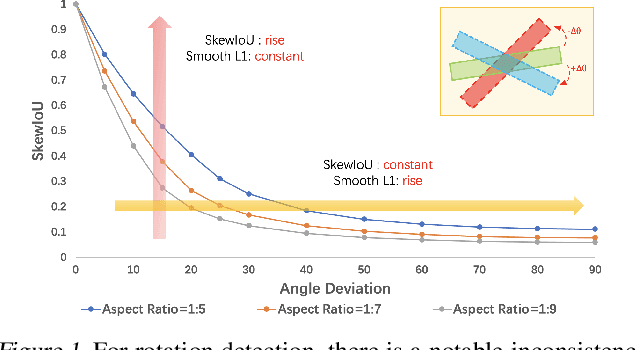
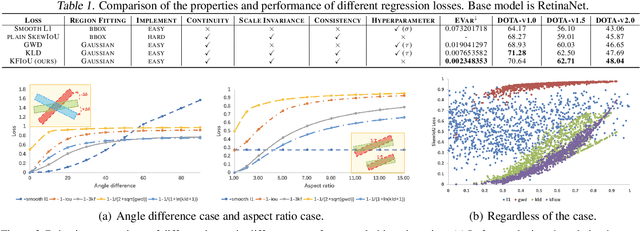
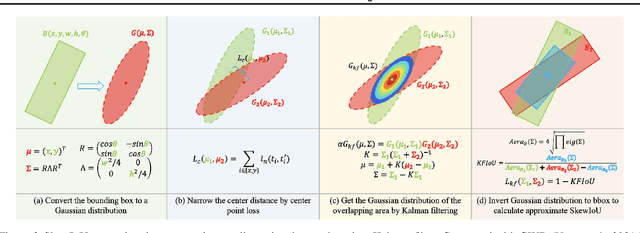

Differing from the well-developed horizontal object detection area whereby the computing-friendly IoU based loss is readily adopted and well fits with the detection metrics. In contrast, rotation detectors often involve a more complicated loss based on SkewIoU which is unfriendly to gradient-based training. In this paper, we argue that one effective alternative is to devise an approximate loss who can achieve trend-level alignment with SkewIoU loss instead of the strict value-level identity. Specifically, we model the objects as Gaussian distribution and adopt Kalman filter to inherently mimic the mechanism of SkewIoU by its definition, and show its alignment with the SkewIoU at trend-level. This is in contrast to recent Gaussian modeling based rotation detectors e.g. GWD, KLD that involves a human-specified distribution distance metric which requires additional hyperparameter tuning. The resulting new loss called KFIoU is easier to implement and works better compared with exact SkewIoU, thanks to its full differentiability and ability to handle the non-overlapping cases. We further extend our technique to the 3-D case which also suffers from the same issues as 2-D detection. Extensive results on various public datasets (2-D/3-D, aerial/text/face images) with different base detectors show the effectiveness of our approach.