 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Communication-Efficient Federated Domain Adaptation via Random Features
Nov 08, 2023



Modern machine learning (ML) models have grown to a scale where training them on a single machine becomes impractical. As a result, there is a growing trend to leverage federated learning (FL) techniques to train large ML models in a distributed and collaborative manner. These models, however, when deployed on new devices, might struggle to generalize well due to domain shifts. In this context, federated domain adaptation (FDA) emerges as a powerful approach to address this challenge. Most existing FDA approaches typically focus on aligning the distributions between source and target domains by minimizing their (e.g., MMD) distance. Such strategies, however, inevitably introduce high communication overheads and can be highly sensitive to network reliability. In this paper, we introduce RF-TCA, an enhancement to the standard Transfer Component Analysis approach that significantly accelerates computation without compromising theoretical and empirical performance. Leveraging the computational advantage of RF-TCA, we further extend it to FDA setting with FedRF-TCA. The proposed FedRF-TCA protocol boasts communication complexity that is \emph{independent} of the sample size, while maintaining performance that is either comparable to or even surpasses state-of-the-art FDA methods. We present extensive experiments to showcase the superior performance and robustness (to network condition) of FedRF-TCA.
Semi-supervised Contrastive Learning with Similarity Co-calibration
May 16, 2021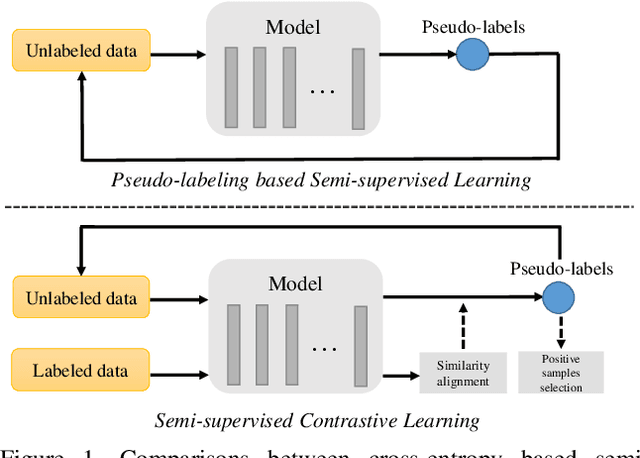
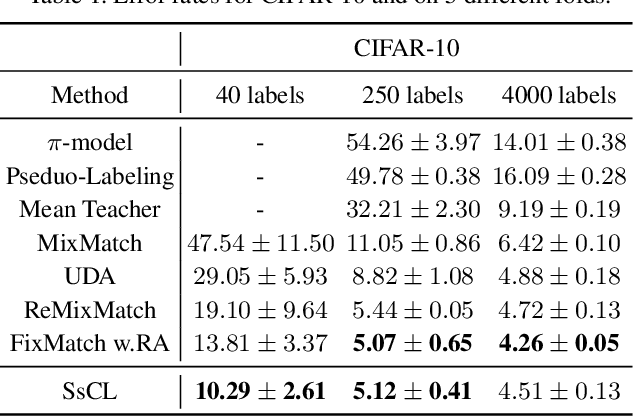
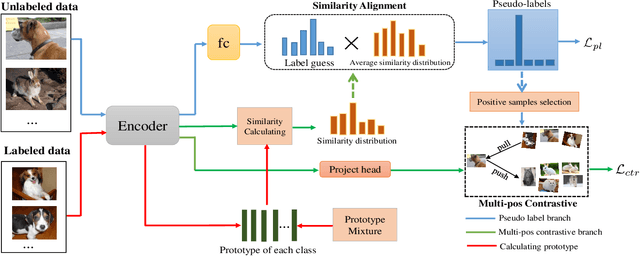
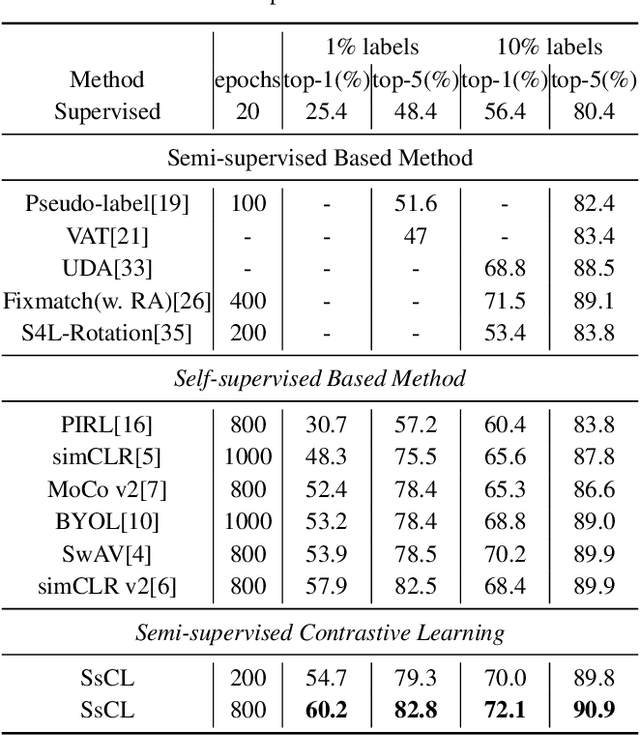
Semi-supervised learning acts as an effective way to leverage massive unlabeled data. In this paper, we propose a novel training strategy, termed as Semi-supervised Contrastive Learning (SsCL), which combines the well-known contrastive loss in self-supervised learning with the cross entropy loss in semi-supervised learning, and jointly optimizes the two objectives in an end-to-end way. The highlight is that different from self-training based semi-supervised learning that conducts prediction and retraining over the same model weights, SsCL interchanges the predictions over the unlabeled data between the two branches, and thus formulates a co-calibration procedure, which we find is beneficial for better prediction and avoid being trapped in local minimum. Towards this goal, the contrastive loss branch models pairwise similarities among samples, using the nearest neighborhood generated from the cross entropy branch, and in turn calibrates the prediction distribution of the cross entropy branch with the contrastive similarity. We show that SsCL produces more discriminative representation and is beneficial to few shot learning. Notably, on ImageNet with ResNet50 as the backbone, SsCL achieves 60.2% and 72.1% top-1 accuracy with 1% and 10% labeled samples, respectively, which significantly outperforms the baseline, and is better than previous semi-supervised and self-supervised methods.