 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiggerGait: Unlocking Gait Recognition with Layer-wise Representations from Large Vision Models
May 23, 2025



Large vision models (LVM) based gait recognition has achieved impressive performance. However, existing LVM-based approaches may overemphasize gait priors while neglecting the intrinsic value of LVM itself, particularly the rich, distinct representations across its multi-layers. To adequately unlock LVM's potential, this work investigates the impact of layer-wise representations on downstream recognition tasks. Our analysis reveals that LVM's intermediate layers offer complementary properties across tasks, integrating them yields an impressive improvement even without rich well-designed gait priors. Building on this insight, we propose a simple and universal baseline for LVM-based gait recognition, termed BiggerGait. Comprehensive evaluations on CCPG, CAISA-B*, SUSTech1K, and CCGR\_MINI validate the superiority of BiggerGait across both within- and cross-domain tasks, establishing it as a simple yet practical baseline for gait representation learning. All the models and code will be publicly available.
Benchmarking Unified Face Attack Detection via Hierarchical Prompt Tuning
May 19, 2025Presentation Attack Detection and Face Forgery Detection are designed to protect face data from physical media-based Presentation Attacks and digital editing-based DeepFakes respectively. But separate training of these two models makes them vulnerable to unknown attacks and burdens deployment environments. The lack of a Unified Face Attack Detection model to handle both types of attacks is mainly due to two factors. First, there's a lack of adequate benchmarks for models to explore. Existing UAD datasets have limited attack types and samples, restricting the model's ability to address advanced threats. To address this, we propose UniAttackDataPlus (UniAttackData+), the most extensive and sophisticated collection of forgery techniques to date. It includes 2,875 identities and their 54 kinds of falsified samples, totaling 697,347 videos. Second, there's a lack of a reliable classification criterion. Current methods try to find an arbitrary criterion within the same semantic space, which fails when encountering diverse attacks. So, we present a novel Visual-Language Model-based Hierarchical Prompt Tuning Framework (HiPTune) that adaptively explores multiple classification criteria from different semantic spaces. We build a Visual Prompt Tree to explore various classification rules hierarchically. Then, by adaptively pruning the prompts, the model can select the most suitable prompts to guide the encoder to extract discriminative features at different levels in a coarse-to-fine way. Finally, to help the model understand the classification criteria in visual space, we propose a Dynamically Prompt Integration module to project the visual prompts to the text encoder for more accurate semantics. Experiments on 12 datasets have shown the potential to inspire further innovations in the UAD field.
MonoCoP: Chain-of-Prediction for Monocular 3D Object Detection
May 08, 2025



Accurately predicting 3D attributes is crucial for monocular 3D object detection (Mono3D), with depth estimation posing the greatest challenge due to the inherent ambiguity in mapping 2D images to 3D space. While existing methods leverage multiple depth cues (e.g., estimating depth uncertainty, modeling depth error) to improve depth accuracy, they overlook that accurate depth prediction requires conditioning on other 3D attributes, as these attributes are intrinsically inter-correlated through the 3D to 2D projection, which ultimately limits overall accuracy and stability. Inspired by Chain-of-Thought (CoT) in large language models (LLMs), this paper proposes MonoCoP, which leverages a Chain-of-Prediction (CoP) to predict attributes sequentially and conditionally via three key designs. First, it employs a lightweight AttributeNet (AN) for each 3D attribute to learn attribute-specific features. Next, MonoCoP constructs an explicit chain to propagate these learned features from one attribute to the next. Finally, MonoCoP uses a residual connection to aggregate features for each attribute along the chain, ensuring that later attribute predictions are conditioned on all previously processed attributes without forgetting the features of earlier ones. Experimental results show that our MonoCoP achieves state-of-the-art (SoTA) performance on the KITTI leaderboard without requiring additional data and further surpasses existing methods on the Waymo and nuScenes frontal datasets.
Person Recognition at Altitude and Range: Fusion of Face, Body Shape and Gait
May 07, 2025
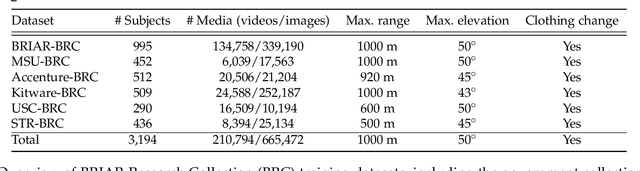

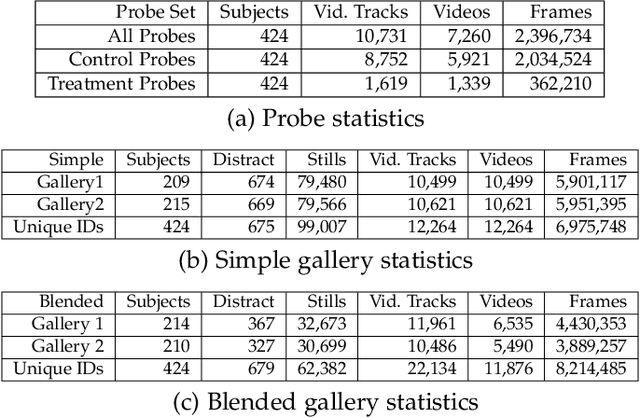
We address the problem of whole-body person recognition in unconstrained environments. This problem arises in surveillance scenarios such as those in the IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) program, where biometric data is captured at long standoff distances, elevated viewing angles, and under adverse atmospheric conditions (e.g., turbulence and high wind velocity). To this end, we propose FarSight, a unified end-to-end system for person recognition that integrates complementary biometric cues across face, gait, and body shape modalities. FarSight incorporates novel algorithms across four core modules: multi-subject detection and tracking, recognition-aware video restoration, modality-specific biometric feature encoding, and quality-guided multi-modal fusion. These components are designed to work cohesively under degraded image conditions, large pose and scale variations, and cross-domain gaps. Extensive experiments on the BRIAR dataset, one of the most comprehensive benchmarks for long-range, multi-modal biometric recognition, demonstrate the effectiveness of FarSight. Compared to our preliminary system, this system achieves a 34.1% absolute gain in 1:1 verification accuracy (TAR@0.1% FAR), a 17.8% increase in closed-set identification (Rank-20), and a 34.3% reduction in open-set identification errors (FNIR@1% FPIR). Furthermore, FarSight was evaluated in the 2025 NIST RTE Face in Video Evaluation (FIVE), which conducts standardized face recognition testing on the BRIAR dataset. These results establish FarSight as a state-of-the-art solution for operational biometric recognition in challenging real-world conditions.
H-MoRe: Learning Human-centric Motion Representation for Action Analysis
Apr 14, 2025



In this paper, we propose H-MoRe, a novel pipeline for learning precise human-centric motion representation. Our approach dynamically preserves relevant human motion while filtering out background movement. Notably, unlike previous methods relying on fully supervised learning from synthetic data, H-MoRe learns directly from real-world scenarios in a self-supervised manner, incorporating both human pose and body shape information. Inspired by kinematics, H-MoRe represents absolute and relative movements of each body point in a matrix format that captures nuanced motion details, termed world-local flows. H-MoRe offers refined insights into human motion, which can be integrated seamlessly into various action-related applications. Experimental results demonstrate that H-MoRe brings substantial improvements across various downstream tasks, including gait recognition(CL@R1: +16.01%), action recognition(Acc@1: +8.92%), and video generation(FVD: -67.07%). Additionally, H-MoRe exhibits high inference efficiency (34 fps), making it suitable for most real-time scenarios. Models and code will be released upon publication.
RICCARDO: Radar Hit Prediction and Convolution for Camera-Radar 3D Object Detection
Apr 12, 2025Radar hits reflect from points on both the boundary and internal to object outlines. This results in a complex distribution of radar hits that depends on factors including object category, size, and orientation. Current radar-camera fusion methods implicitly account for this with a black-box neural network. In this paper, we explicitly utilize a radar hit distribution model to assist fusion. First, we build a model to predict radar hit distributions conditioned on object properties obtained from a monocular detector. Second, we use the predicted distribution as a kernel to match actual measured radar points in the neighborhood of the monocular detections, generating matching scores at nearby positions. Finally, a fusion stage combines context with the kernel detector to refine the matching scores. Our method achieves the state-of-the-art radar-camera detection performance on nuScenes. Our source code is available at https://github.com/longyunf/riccardo.
SapiensID: Foundation for Human Recognition
Apr 07, 2025Existing human recognition systems often rely on separate, specialized models for face and body analysis, limiting their effectiveness in real-world scenarios where pose, visibility, and context vary widely. This paper introduces SapiensID, a unified model that bridges this gap, achieving robust performance across diverse settings. SapiensID introduces (i) Retina Patch (RP), a dynamic patch generation scheme that adapts to subject scale and ensures consistent tokenization of regions of interest, (ii) a masked recognition model (MRM) that learns from variable token length, and (iii) Semantic Attention Head (SAH), an module that learns pose-invariant representations by pooling features around key body parts. To facilitate training, we introduce WebBody4M, a large-scale dataset capturing diverse poses and scale variations. Extensive experiments demonstrate that SapiensID achieves state-of-the-art results on various body ReID benchmarks, outperforming specialized models in both short-term and long-term scenarios while remaining competitive with dedicated face recognition systems. Furthermore, SapiensID establishes a strong baseline for the newly introduced challenge of Cross Pose-Scale ReID, demonstrating its ability to generalize to complex, real-world conditions.
Refined Geometry-guided Head Avatar Reconstruction from Monocular RGB Video
Mar 27, 2025High-fidelity reconstruction of head avatars from monocular videos is highly desirable for virtual human applications, but it remains a challenge in the fields of computer graphics and computer vision. In this paper, we propose a two-phase head avatar reconstruction network that incorporates a refined 3D mesh representation. Our approach, in contrast to existing methods that rely on coarse template-based 3D representations derived from 3DMM, aims to learn a refined mesh representation suitable for a NeRF that captures complex facial nuances. In the first phase, we train 3DMM-stored NeRF with an initial mesh to utilize geometric priors and integrate observations across frames using a consistent set of latent codes. In the second phase, we leverage a novel mesh refinement procedure based on an SDF constructed from the density field of the initial NeRF. To mitigate the typical noise in the NeRF density field without compromising the features of the 3DMM, we employ Laplace smoothing on the displacement field. Subsequently, we apply a second-phase training with these refined meshes, directing the learning process of the network towards capturing intricate facial details. Our experiments demonstrate that our method further enhances the NeRF rendering based on the initial mesh and achieves performance superior to state-of-the-art methods in reconstructing high-fidelity head avatars with such input.
Rethinking Vision-Language Model in Face Forensics: Multi-Modal Interpretable Forged Face Detector
Mar 26, 2025Deepfake detection is a long-established research topic vital for mitigating the spread of malicious misinformation. Unlike prior methods that provide either binary classification results or textual explanations separately, we introduce a novel method capable of generating both simultaneously. Our method harnesses the multi-modal learning capability of the pre-trained CLIP and the unprecedented interpretability of large language models (LLMs) to enhance both the generalization and explainability of deepfake detection. Specifically, we introduce a multi-modal face forgery detector (M2F2-Det) that employs tailored face forgery prompt learning, incorporating the pre-trained CLIP to improve generalization to unseen forgeries. Also, M2F2-Det incorporates an LLM to provide detailed textual explanations of its detection decisions, enhancing interpretability by bridging the gap between natural language and subtle cues of facial forgeries. Empirically, we evaluate M2F2-Det on both detection and explanation generation tasks, where it achieves state-of-the-art performance, demonstrating its effectiveness in identifying and explaining diverse forgeries.
Iron Sharpens Iron: Defending Against Attacks in Machine-Generated Text Detection with Adversarial Training
Feb 18, 2025



Machine-generated Text (MGT) detection is crucial for regulating and attributing online texts. While the existing MGT detectors achieve strong performance, they remain vulnerable to simple perturbations and adversarial attacks. To build an effective defense against malicious perturbations, we view MGT detection from a threat modeling perspective, that is, analyzing the model's vulnerability from an adversary's point of view and exploring effective mitigations. To this end, we introduce an adversarial framework for training a robust MGT detector, named GREedy Adversary PromoTed DefendER (GREATER). The GREATER consists of two key components: an adversary GREATER-A and a detector GREATER-D. The GREATER-D learns to defend against the adversarial attack from GREATER-A and generalizes the defense to other attacks. GREATER-A identifies and perturbs the critical tokens in embedding space, along with greedy search and pruning to generate stealthy and disruptive adversarial examples. Besides, we update the GREATER-A and GREATER-D synchronously, encouraging the GREATER-D to generalize its defense to different attacks and varying attack intensities. Our experimental results across 9 text perturbation strategies and 5 adversarial attacks show that our GREATER-D reduces the Attack Success Rate (ASR) by 10.61% compared with SOTA defense methods while our GREATER-A is demonstrated to be more effective and efficient than SOTA attack approaches.