 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEverMemBench: Benchmarking Long-Term Interactive Memory in Large Language Models
Feb 03, 2026Long-term conversational memory is essential for LLM-based assistants, yet existing benchmarks focus on dyadic, single-topic dialogues that fail to capture real-world complexity. We introduce EverMemBench, a benchmark featuring multi-party, multi-group conversations spanning over 1 million tokens with temporally evolving information, cross-topic interleaving, and role-specific personas. EverMemBench evaluates memory systems across three dimensions through 1,000+ QA pairs: fine-grained recall, memory awareness, and user profile understanding. Our evaluation reveals critical limitations: (1) multi-hop reasoning collapses in multi-party settings, with even oracle models achieving only 26%; (2) temporal reasoning remains unsolved, requiring version semantics beyond timestamp matching; (3) memory awareness is bottlenecked by retrieval, where current similarity-based methods fail to bridge the semantic gap between queries and implicitly relevant memories. EverMemBench provides a challenging testbed for developing next-generation memory architectures.
Beyond the Needle's Illusion: Decoupled Evaluation of Evidence Access and Use under Semantic Interference at 326M-Token Scale
Jan 28, 2026Long-context LLM agents must access the right evidence from large environments and use it faithfully. However, the popular Needle-in-a-Haystack (NIAH) evaluation mostly measures benign span localization. The needle is near-unique, and the haystack is largely irrelevant. We introduce EverMemBench-S (EMB-S), an adversarial NIAH-style benchmark built on a 326M-token MemoryBank. While the full MemoryBank spans 326M tokens for retrieval-based (RAG) evaluation, we evaluate native long-context models only at scales that fit within each model's context window (up to 1M tokens in this work) to ensure a fair comparison. EMB-S pairs queries with collision-tested near-miss hard negatives and gold evidence sets spanning one or more documents, validated via human screening and LLM verification. We also propose a decoupled diagnostic protocol that reports evidence access (document-ID localization) separately from end-to-end QA quality under full-context prompting. This enables consistent diagnosis for both native long-context prompting and retrieval pipelines. Across a reference-corpus ladder from domain-isolated 64K contexts to a globally shared 326M-token environment, we observe a clear reality gap. Systems that saturate benign NIAH degrade sharply in evidence access under semantic interference. These results indicate that semantic discrimination, not context length alone, is the dominant bottleneck for long-context memory at scale.
Explore-Construct-Filter: An Automated Framework for Rich and Reliable API Knowledge Graph Construction
Feb 19, 2025The API Knowledge Graph (API KG) is a structured network that models API entities and their relations, providing essential semantic insights for tasks such as API recommendation, code generation, and API misuse detection. However, constructing a knowledge-rich and reliable API KG presents several challenges. Existing schema-based methods rely heavily on manual annotations to design KG schemas, leading to excessive manual overhead. On the other hand, schema-free methods, due to the lack of schema guidance, are prone to introducing noise, reducing the KG's reliability. To address these issues, we propose the Explore-Construct-Filter framework, an automated approach for API KG construction based on large language models (LLMs). This framework consists of three key modules: 1) KG exploration: LLMs simulate the workflow of annotators to automatically design a schema with comprehensive type triples, minimizing human intervention; 2) KG construction: Guided by the schema, LLMs extract instance triples to construct a rich yet unreliable API KG; 3) KG filtering: Removing invalid type triples and suspicious instance triples to construct a rich and reliable API KG. Experimental results demonstrate that our method surpasses the state-of-the-art method, achieving a 25.2% improvement in F1 score. Moreover, the Explore-Construct-Filter framework proves effective, with the KG exploration module increasing KG richness by 133.6% and the KG filtering module improving reliability by 26.6%. Finally, cross-model experiments confirm the generalizability of our framework.
Vision-Based Defect Classification and Weight Estimation of Rice Kernels
Oct 06, 2022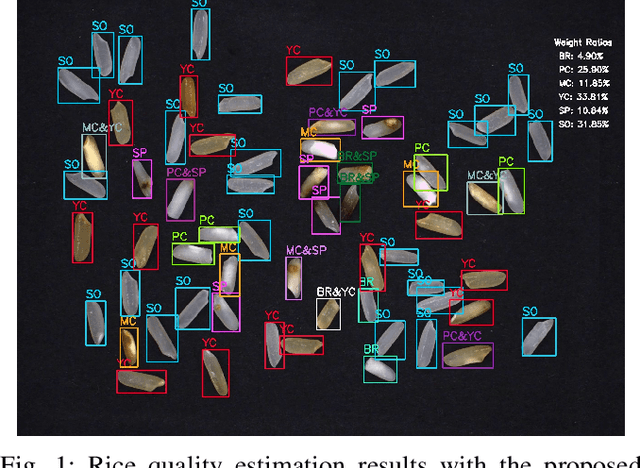



Rice is one of the main staple food in many areas of the world. The quality estimation of rice kernels are crucial in terms of both food safety and socio-economic impact. This was usually carried out by quality inspectors in the past, which may result in both objective and subjective inaccuracies. In this paper, we present an automatic visual quality estimation system of rice kernels, to classify the sampled rice kernels according to their types of flaws, and evaluate their quality via the weight ratios of the perspective kernel types. To compensate for the imbalance of different kernel numbers and classify kernels with multiple flaws accurately, we propose a multi-stage workflow which is able to locate the kernels in the captured image and classify their properties. We define a novel metric to measure the relative weight of each kernel in the image from its area, such that the relative weight of each type of kernels with regard to the all samples can be computed and used as the basis for rice quality estimation. Various experiments are carried out to show that our system is able to output precise results in a contactless way and replace tedious and error-prone manual works.
A Novel Speech-Driven Lip-Sync Model with CNN and LSTM
May 02, 2022

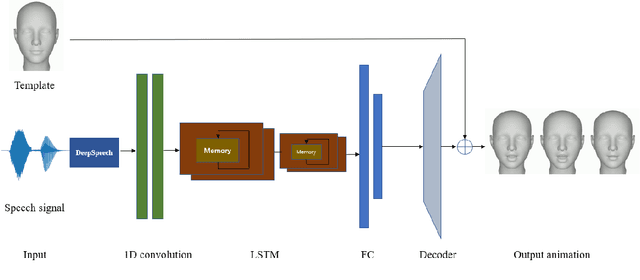
Generating synchronized and natural lip movement with speech is one of the most important tasks in creating realistic virtual characters. In this paper, we present a combined deep neural network of one-dimensional convolutions and LSTM to generate vertex displacement of a 3D template face model from variable-length speech input. The motion of the lower part of the face, which is represented by the vertex movement of 3D lip shapes, is consistent with the input speech. In order to enhance the robustness of the network to different sound signals, we adapt a trained speech recognition model to extract speech feature, and a velocity loss term is adopted to reduce the jitter of generated facial animation. We recorded a series of videos of a Chinese adult speaking Mandarin and created a new speech-animation dataset to compensate the lack of such public data. Qualitative and quantitative evaluations indicate that our model is able to generate smooth and natural lip movements synchronized with speech.
AVA: Adversarial Vignetting Attack against Visual Recognition
May 12, 2021
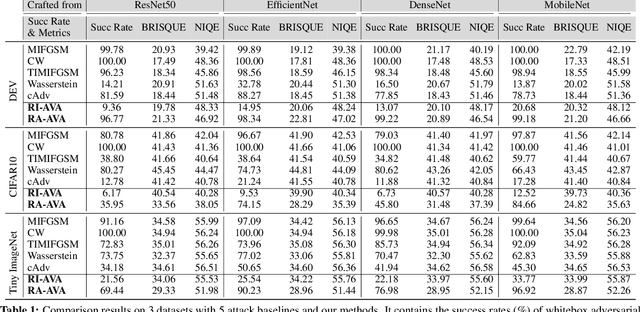
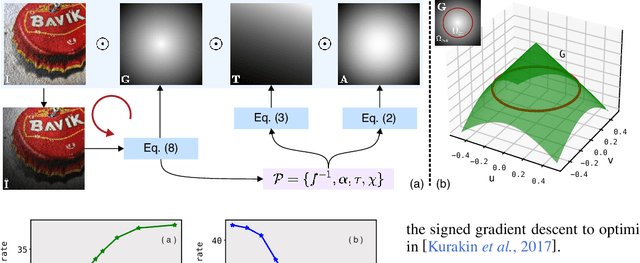
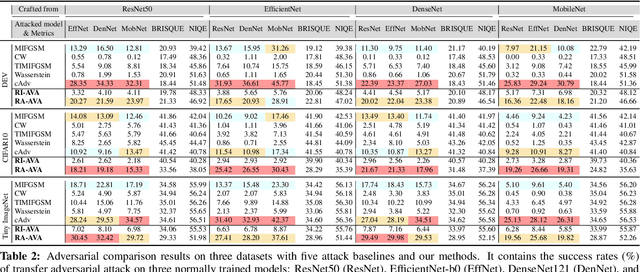
Vignetting is an inherited imaging phenomenon within almost all optical systems, showing as a radial intensity darkening toward the corners of an image. Since it is a common effect for photography and usually appears as a slight intensity variation, people usually regard it as a part of a photo and would not even want to post-process it. Due to this natural advantage, in this work, we study vignetting from a new viewpoint, i.e., adversarial vignetting attack (AVA), which aims to embed intentionally misleading information into vignetting and produce a natural adversarial example without noise patterns. This example can fool the state-of-the-art deep convolutional neural networks (CNNs) but is imperceptible to humans. To this end, we first propose the radial-isotropic adversarial vignetting attack (RI-AVA) based on the physical model of vignetting, where the physical parameters (e.g., illumination factor and focal length) are tuned through the guidance of target CNN models. To achieve higher transferability across different CNNs, we further propose radial-anisotropic adversarial vignetting attack (RA-AVA) by allowing the effective regions of vignetting to be radial-anisotropic and shape-free. Moreover, we propose the geometry-aware level-set optimization method to solve the adversarial vignetting regions and physical parameters jointly. We validate the proposed methods on three popular datasets, i.e., DEV, CIFAR10, and Tiny ImageNet, by attacking four CNNs, e.g., ResNet50, EfficientNet-B0, DenseNet121, and MobileNet-V2, demonstrating the advantages of our methods over baseline methods on both transferability and image quality.
IndoNLG: Benchmark and Resources for Evaluating Indonesian Natural Language Generation
Apr 16, 2021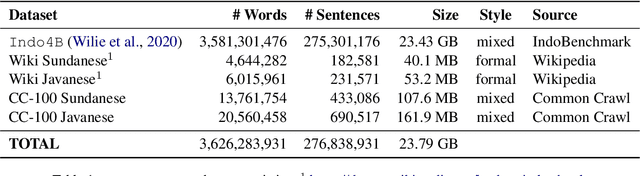
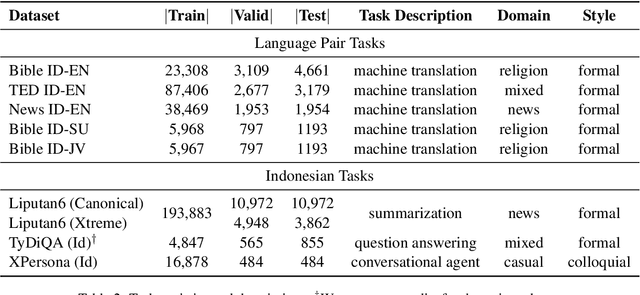
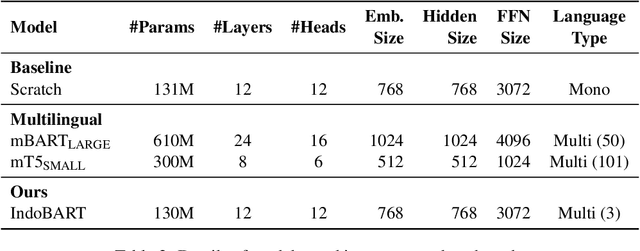
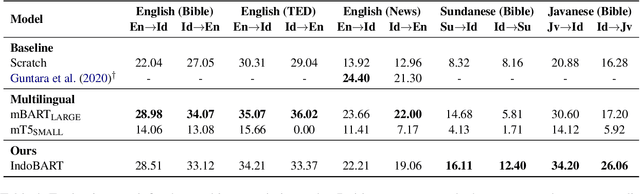
A benchmark provides an ecosystem to measure the advancement of models with standard datasets and automatic and human evaluation metrics. We introduce IndoNLG, the first such benchmark for the Indonesian language for natural language generation (NLG). It covers six tasks: summarization, question answering, open chitchat, as well as three different language-pairs of machine translation tasks. We provide a vast and clean pre-training corpus of Indonesian, Sundanese, and Javanese datasets called Indo4B-Plus, which is used to train our pre-trained NLG model, IndoBART. We evaluate the effectiveness and efficiency of IndoBART by conducting extensive evaluation on all IndoNLG tasks. Our findings show that IndoBART achieves competitive performance on Indonesian tasks with five times fewer parameters compared to the largest multilingual model in our benchmark, mBART-LARGE (Liu et al., 2020), and an almost 4x and 2.5x faster inference time on the CPU and GPU respectively. We additionally demonstrate the ability of IndoBART to learn Javanese and Sundanese, and it achieves decent performance on machine translation tasks.
Stereo Correspondence and Reconstruction of Endoscopic Data Challenge
Jan 28, 2021

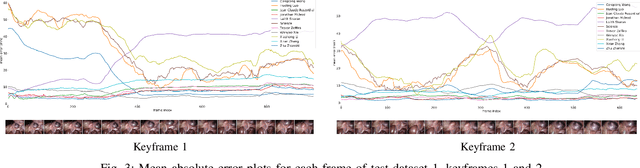
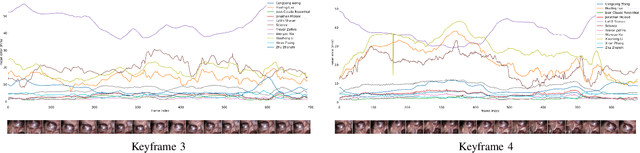
The stereo correspondence and reconstruction of endoscopic data sub-challenge was organized during the Endovis challenge at MICCAI 2019 in Shenzhen, China. The task was to perform dense depth estimation using 7 training datasets and 2 test sets of structured light data captured using porcine cadavers. These were provided by a team at Intuitive Surgical. 10 teams participated in the challenge day. This paper contains 3 additional methods which were submitted after the challenge finished as well as a supplemental section from these teams on issues they found with the dataset.
Generating Informative CVE Description From ExploitDB Posts by Extractive Summarization
Jan 05, 2021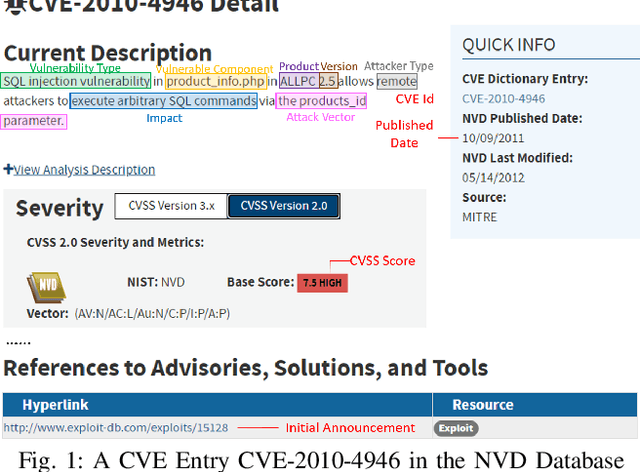
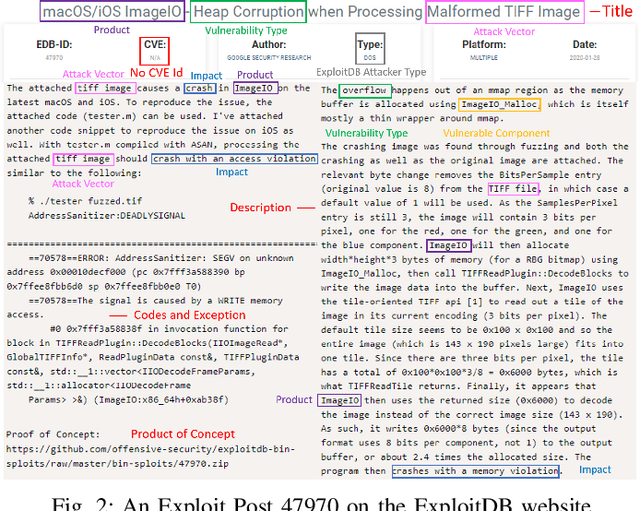
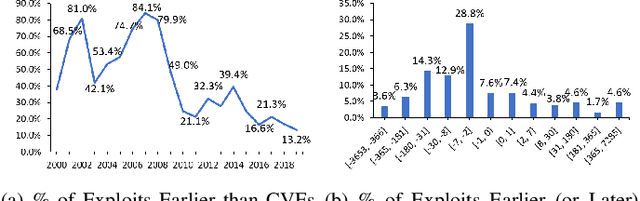
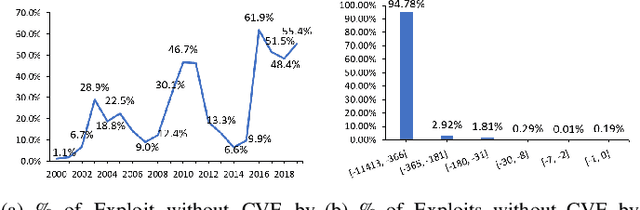
ExploitDB is one of the important public websites, which contributes a large number of vulnerabilities to official CVE database. Over 60\% of these vulnerabilities have high- or critical-security risks. Unfortunately, over 73\% of exploits appear publicly earlier than the corresponding CVEs, and about 40\% of exploits do not even have CVEs. To assist in documenting CVEs for the ExploitDB posts, we propose an open information method to extract 9 key vulnerability aspects (vulnerable product/version/component, vulnerability type, vendor, attacker type, root cause, attack vector and impact) from the verbose and noisy ExploitDB posts. The extracted aspects from an ExploitDB post are then composed into a CVE description according to the suggested CVE description templates, which is must-provided information for requesting new CVEs. Through the evaluation on 13,017 manually labeled sentences and the statistically sampling of 3,456 extracted aspects, we confirm the high accuracy of our extraction method. Compared with 27,230 reference CVE descriptions. Our composed CVE descriptions achieve high ROUGH-L (0.38), a longest common subsequence based metric for evaluating text summarization methods.
IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding
Oct 08, 2020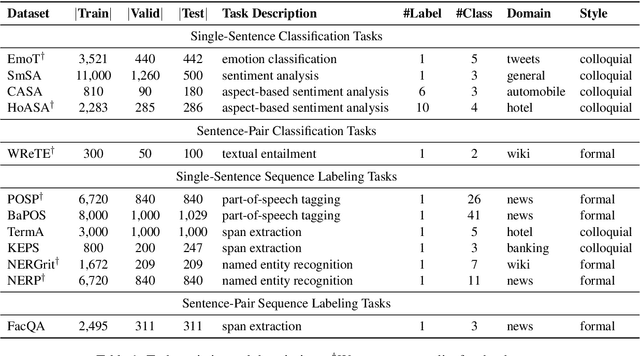
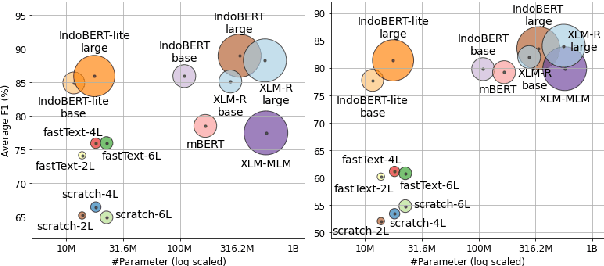
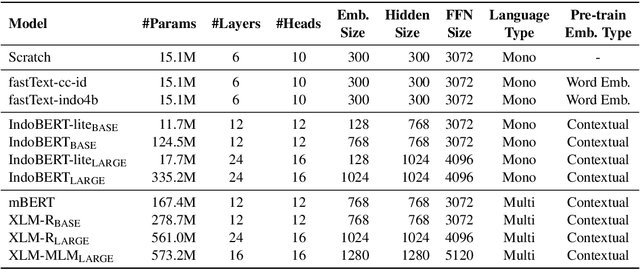
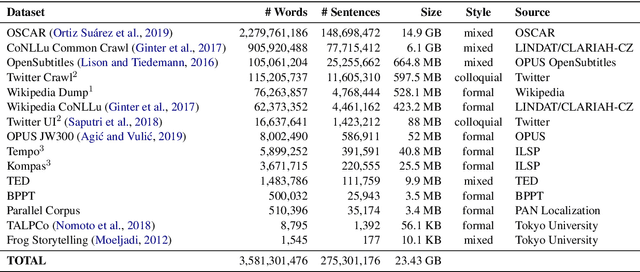
Although Indonesian is known to be the fourth most frequently used language over the internet, the research progress on this language in the natural language processing (NLP) is slow-moving due to a lack of available resources. In response, we introduce the first-ever vast resource for the training, evaluating, and benchmarking on Indonesian natural language understanding (IndoNLU) tasks. IndoNLU includes twelve tasks, ranging from single sentence classification to pair-sentences sequence labeling with different levels of complexity. The datasets for the tasks lie in different domains and styles to ensure task diversity. We also provide a set of Indonesian pre-trained models (IndoBERT) trained from a large and clean Indonesian dataset Indo4B collected from publicly available sources such as social media texts, blogs, news, and websites. We release baseline models for all twelve tasks, as well as the framework for benchmark evaluation, and thus it enables everyone to benchmark their system performances.