 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFavia: Forensic Agent for Vulnerability-fix Identification and Analysis
Feb 13, 2026Identifying vulnerability-fixing commits corresponding to disclosed CVEs is essential for secure software maintenance but remains challenging at scale, as large repositories contain millions of commits of which only a small fraction address security issues. Existing automated approaches, including traditional machine learning techniques and recent large language model (LLM)-based methods, often suffer from poor precision-recall trade-offs. Frequently evaluated on randomly sampled commits, we uncover that they are substantially underestimating real-world difficulty, where candidate commits are already security-relevant and highly similar. We propose Favia, a forensic, agent-based framework for vulnerability-fix identification that combines scalable candidate ranking with deep and iterative semantic reasoning. Favia first employs an efficient ranking stage to narrow the search space of commits. Each commit is then rigorously evaluated using a ReAct-based LLM agent. By providing the agent with a pre-commit repository as environment, along with specialized tools, the agent tries to localize vulnerable components, navigates the codebase, and establishes causal alignment between code changes and vulnerability root causes. This evidence-driven process enables robust identification of indirect, multi-file, and non-trivial fixes that elude single-pass or similarity-based methods. We evaluate Favia on CVEVC, a large-scale dataset we made that comprises over 8 million commits from 3,708 real-world repositories, and show that it consistently outperforms state-of-the-art traditional and LLM-based baselines under realistic candidate selection, achieving the strongest precision-recall trade-offs and highest F1-scores.
From Exploration to Revelation: Detecting Dark Patterns in Mobile Apps
Nov 27, 2024Mobile apps are essential in daily life, yet they often employ dark patterns, such as visual tricks to highlight certain options or linguistic tactics to nag users into making purchases, to manipulate user behavior. Current research mainly uses manual methods to detect dark patterns, a process that is time-consuming and struggles to keep pace with continually updating and emerging apps. While some studies targeted at automated detection, they are constrained to static patterns and still necessitate manual app exploration. To bridge these gaps, we present AppRay, an innovative system that seamlessly blends task-oriented app exploration with automated dark pattern detection, reducing manual efforts. Our approach consists of two steps: First, we harness the commonsense knowledge of large language models for targeted app exploration, supplemented by traditional random exploration to capture a broader range of UI states. Second, we developed a static and dynamic dark pattern detector powered by a contrastive learning-based multi-label classifier and a rule-based refiner to perform detection. We contributed two datasets, AppRay-Dark and AppRay-Light, with 2,185 unique deceptive patterns (including 149 dynamic instances) across 18 types from 876 UIs and 871 benign UIs. These datasets cover both static and dynamic dark patterns while preserving UI relationships. Experimental results confirm that AppRay can efficiently explore the app and identify a wide range of dark patterns with great performance.
Pop Quiz! Do Pre-trained Code Models Possess Knowledge of Correct API Names?
Sep 14, 2023



Recent breakthroughs in pre-trained code models, such as CodeBERT and Codex, have shown their superior performance in various downstream tasks. The correctness and unambiguity of API usage among these code models are crucial for achieving desirable program functionalities, requiring them to learn various API fully qualified names structurally and semantically. Recent studies reveal that even state-of-the-art pre-trained code models struggle with suggesting the correct APIs during code generation. However, the reasons for such poor API usage performance are barely investigated. To address this challenge, we propose using knowledge probing as a means of interpreting code models, which uses cloze-style tests to measure the knowledge stored in models. Our comprehensive study examines a code model's capability of understanding API fully qualified names from two different perspectives: API call and API import. Specifically, we reveal that current code models struggle with understanding API names, with pre-training strategies significantly affecting the quality of API name learning. We demonstrate that natural language context can assist code models in locating Python API names and generalize Python API name knowledge to unseen data. Our findings provide insights into the limitations and capabilities of current pre-trained code models, and suggest that incorporating API structure into the pre-training process can improve automated API usage and code representations. This work provides significance for advancing code intelligence practices and direction for future studies. All experiment results, data and source code used in this work are available at \url{https://doi.org/10.5281/zenodo.7902072}.
Generating Informative CVE Description From ExploitDB Posts by Extractive Summarization
Jan 05, 2021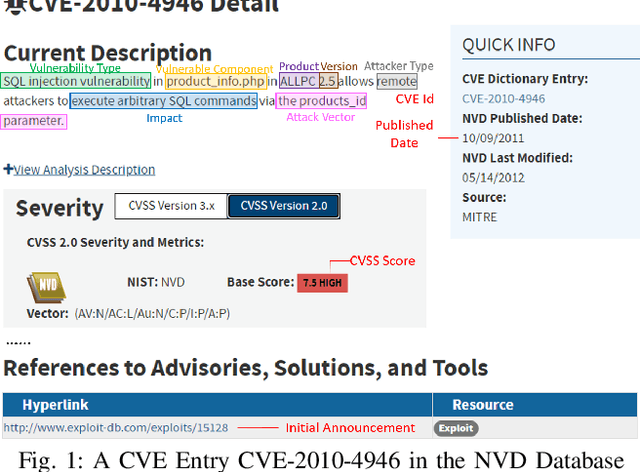
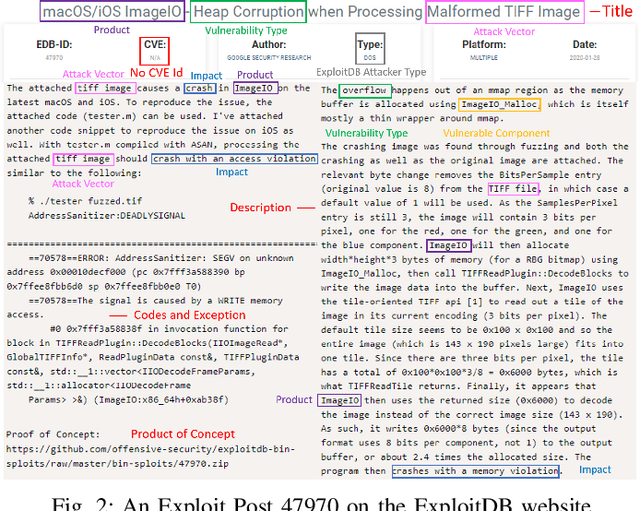
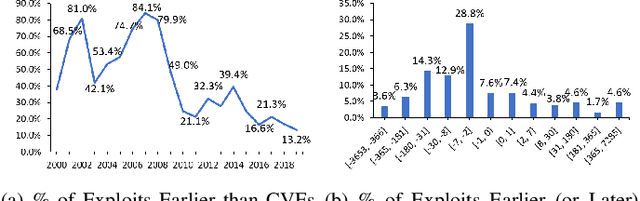
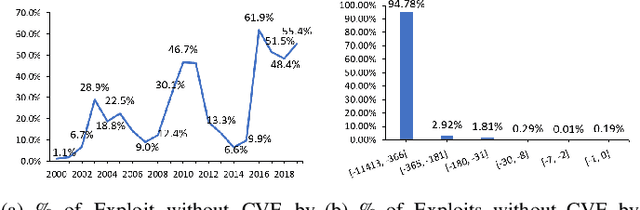
ExploitDB is one of the important public websites, which contributes a large number of vulnerabilities to official CVE database. Over 60\% of these vulnerabilities have high- or critical-security risks. Unfortunately, over 73\% of exploits appear publicly earlier than the corresponding CVEs, and about 40\% of exploits do not even have CVEs. To assist in documenting CVEs for the ExploitDB posts, we propose an open information method to extract 9 key vulnerability aspects (vulnerable product/version/component, vulnerability type, vendor, attacker type, root cause, attack vector and impact) from the verbose and noisy ExploitDB posts. The extracted aspects from an ExploitDB post are then composed into a CVE description according to the suggested CVE description templates, which is must-provided information for requesting new CVEs. Through the evaluation on 13,017 manually labeled sentences and the statistically sampling of 3,456 extracted aspects, we confirm the high accuracy of our extraction method. Compared with 27,230 reference CVE descriptions. Our composed CVE descriptions achieve high ROUGH-L (0.38), a longest common subsequence based metric for evaluating text summarization methods.