 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel-Level Relation to Attentive Aggregation with Neighborhood-Homogeneity Constraint for Point Cloud Analysis
May 04, 2026In 3D point cloud understanding, the core challenge lies in accurately capturing discriminative features within complex neighborhoods, which directly affects the execution precision of downstream tasks such as embodied AI and autonomous driving. Existing methods explore feature correlation discrimination but are limited to point-level spatial distribution or channel responses, enabling only coarse-grained level evaluation. For modern multi-scale point cloud networks, such coarse-grained metrics inevitably incur significant information loss in deeper layers. To address this issue, we propose a novel network equipped with a channel-level metric-based enhancement mechanism, termed the PointCRA network. Our core idea is to introduce temporal trend variation as a new evaluation dimension to avoid the information loss caused by weight dimension collapse in existing spatial and channel attention mechanisms. On this basis, we construct a multi-level calibration framework guided by neighborhood homogeneity for weight calibration, and design a dedicated loss function to enhance channel discriminability. The module effectively leverages the intrinsic feature priors of deep networks to adaptively correct the feature aggregation process, offering strong interpretability with low parameter overhead. Furthermore, our proposed method exhibits strong transferability, interpretability, and parameter efficiency. We validate the proposed method effectiveness on diverse datasets and benchmark models, and further demonstrate its rationality through extensive analytical experiments. Our PointCRA achieves 77.5% mIoU on the S3DIS dataset, 90.4% OA on the ScanObjectNN dataset, and 87.4% instance mIoU on the ShapeNetPart dataset. The code and pretrained weights are publicly available on GitHub:
Explicit Multimodal Graph Modeling for Human-Object Interaction Detection
Sep 16, 2025Transformer-based methods have recently become the prevailing approach for Human-Object Interaction (HOI) detection. However, the Transformer architecture does not explicitly model the relational structures inherent in HOI detection, which impedes the recognition of interactions. In contrast, Graph Neural Networks (GNNs) are inherently better suited for this task, as they explicitly model the relationships between human-object pairs. Therefore, in this paper, we propose \textbf{M}ultimodal \textbf{G}raph \textbf{N}etwork \textbf{M}odeling (MGNM) that leverages GNN-based relational structures to enhance HOI detection. Specifically, we design a multimodal graph network framework that explicitly models the HOI task in a four-stage graph structure. Furthermore, we introduce a multi-level feature interaction mechanism within our graph network. This mechanism leverages multi-level vision and language features to enhance information propagation across human-object pairs. Consequently, our proposed MGNM achieves state-of-the-art performance on two widely used benchmarks: HICO-DET and V-COCO. Moreover, when integrated with a more advanced object detector, our method demonstrates a significant performance gain and maintains an effective balance between rare and non-rare classes.
DeepAccident: A Motion and Accident Prediction Benchmark for V2X Autonomous Driving
Apr 10, 2023



Safety is the primary priority of autonomous driving. Nevertheless, no published dataset currently supports the direct and explainable safety evaluation for autonomous driving. In this work, we propose DeepAccident, a large-scale dataset generated via a realistic simulator containing diverse accident scenarios that frequently occur in real-world driving. The proposed DeepAccident dataset contains 57K annotated frames and 285K annotated samples, approximately 7 times more than the large-scale nuScenes dataset with 40k annotated samples. In addition, we propose a new task, end-to-end motion and accident prediction, based on the proposed dataset, which can be used to directly evaluate the accident prediction ability for different autonomous driving algorithms. Furthermore, for each scenario, we set four vehicles along with one infrastructure to record data, thus providing diverse viewpoints for accident scenarios and enabling V2X (vehicle-to-everything) research on perception and prediction tasks. Finally, we present a baseline V2X model named V2XFormer that demonstrates superior performance for motion and accident prediction and 3D object detection compared to the single-vehicle model.
Subtype-aware Unsupervised Domain Adaptation for Medical Diagnosis
Jan 11, 2021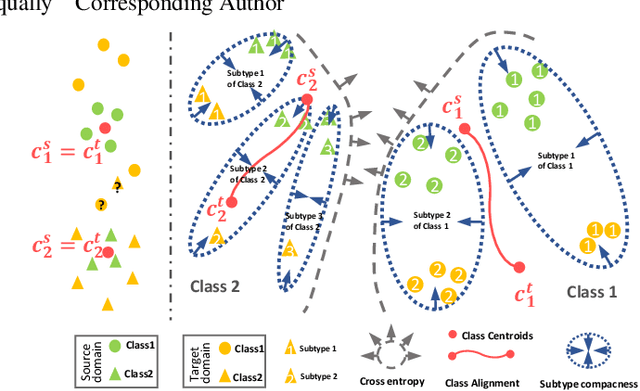
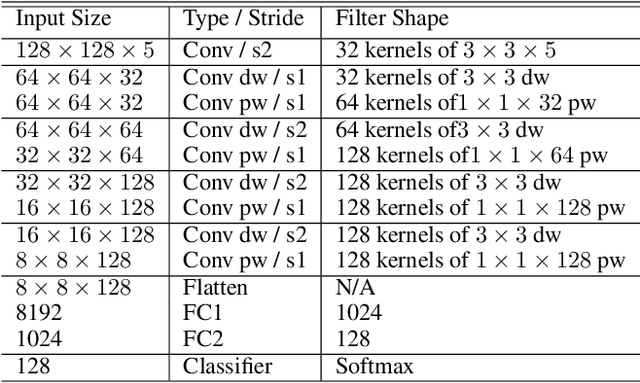
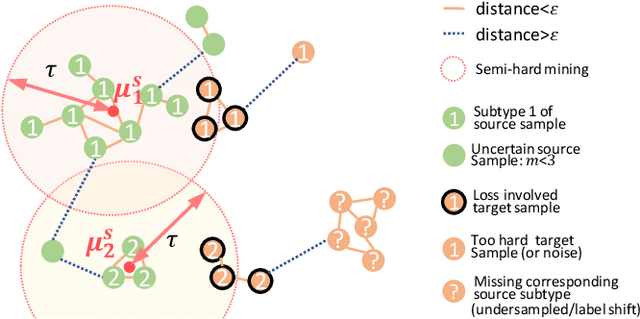
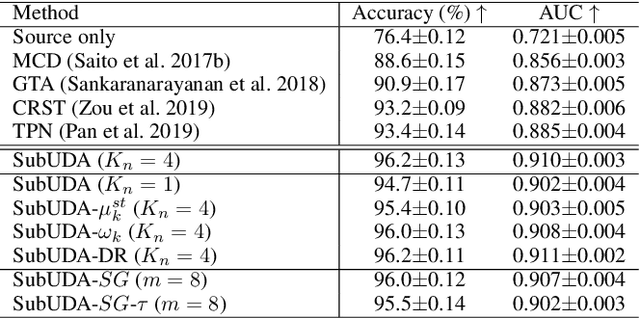
Recent advances in unsupervised domain adaptation (UDA) show that transferable prototypical learning presents a powerful means for class conditional alignment, which encourages the closeness of cross-domain class centroids. However, the cross-domain inner-class compactness and the underlying fine-grained subtype structure remained largely underexplored. In this work, we propose to adaptively carry out the fine-grained subtype-aware alignment by explicitly enforcing the class-wise separation and subtype-wise compactness with intermediate pseudo labels. Our key insight is that the unlabeled subtypes of a class can be divergent to one another with different conditional and label shifts, while inheriting the local proximity within a subtype. The cases of with or without the prior information on subtype numbers are investigated to discover the underlying subtype structure in an online fashion. The proposed subtype-aware dynamic UDA achieves promising results on medical diagnosis tasks.