 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Edit: Open-Domain Image Manipulation with Open-Vocabulary Instructions
Aug 04, 2020
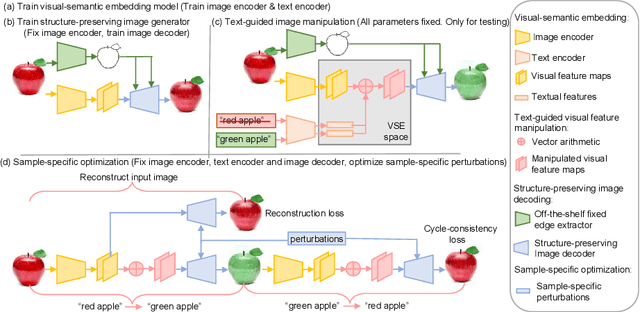


We propose a novel algorithm, named Open-Edit, which is the first attempt on open-domain image manipulation with open-vocabulary instructions. It is a challenging task considering the large variation of image domains and the lack of training supervision. Our approach takes advantage of the unified visual-semantic embedding space pretrained on a general image-caption dataset, and manipulates the embedded visual features by applying text-guided vector arithmetic on the image feature maps. A structure-preserving image decoder then generates the manipulated images from the manipulated feature maps. We further propose an on-the-fly sample-specific optimization approach with cycle-consistency constraints to regularize the manipulated images and force them to preserve details of the source images. Our approach shows promising results in manipulating open-vocabulary color, texture, and high-level attributes for various scenarios of open-domain images.
Point Cloud Completion by Learning Shape Priors
Aug 02, 2020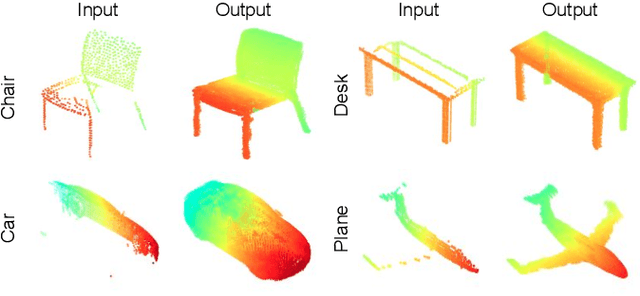
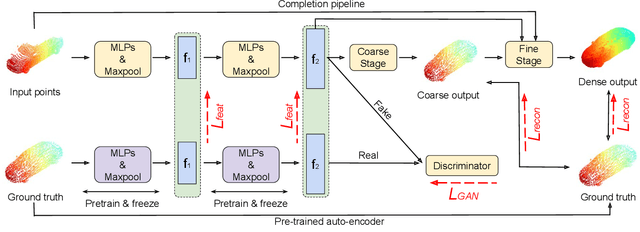
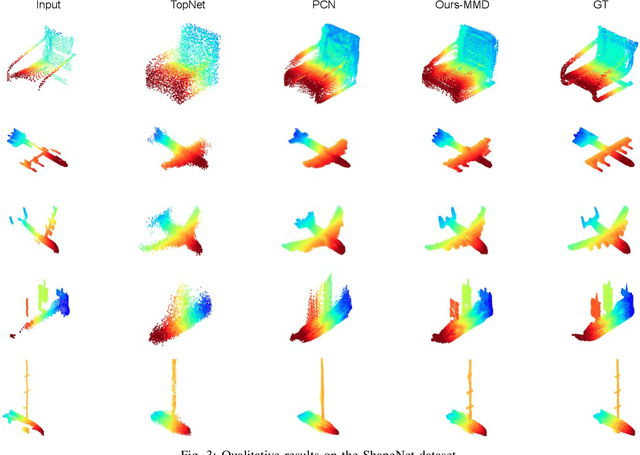
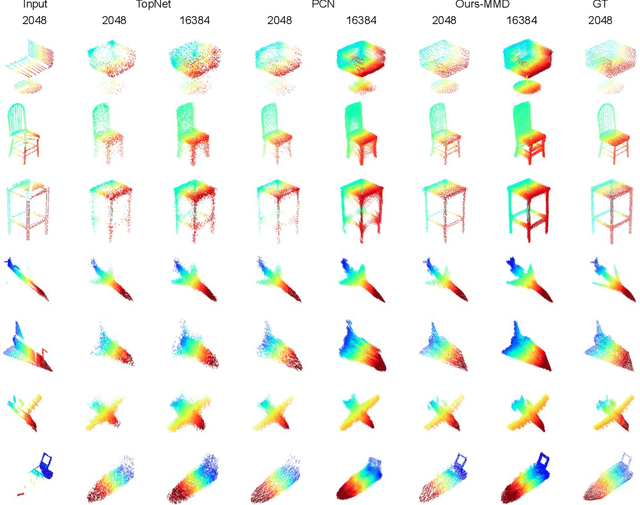
In view of the difficulty in reconstructing object details in point cloud completion, we propose a shape prior learning method for object completion. The shape priors include geometric information in both complete and the partial point clouds. We design a feature alignment strategy to learn the shape prior from complete points, and a coarse to fine strategy to incorporate partial prior in the fine stage. To learn the complete objects prior, we first train a point cloud auto-encoder to extract the latent embeddings from complete points. Then we learn a mapping to transfer the point features from partial points to that of the complete points by optimizing feature alignment losses. The feature alignment losses consist of a L2 distance and an adversarial loss obtained by Maximum Mean Discrepancy Generative Adversarial Network (MMD-GAN). The L2 distance optimizes the partial features towards the complete ones in the feature space, and MMD-GAN decreases the statistical distance of two point features in a Reproducing Kernel Hilbert Space. We achieve state-of-the-art performances on the point cloud completion task. Our code is available at https://github.com/xiaogangw/point-cloud-completion-shape-prior.
Gradient Regularized Contrastive Learning for Continual Domain Adaptation
Jul 25, 2020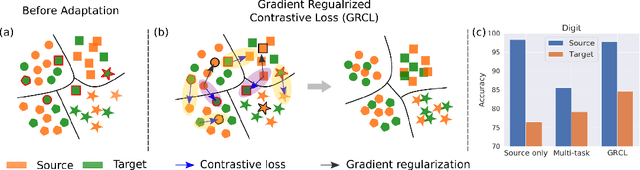
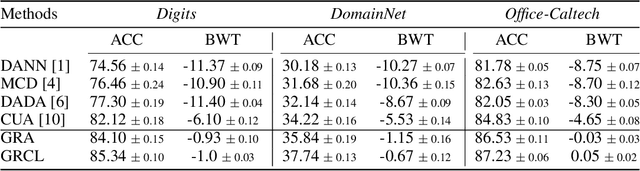
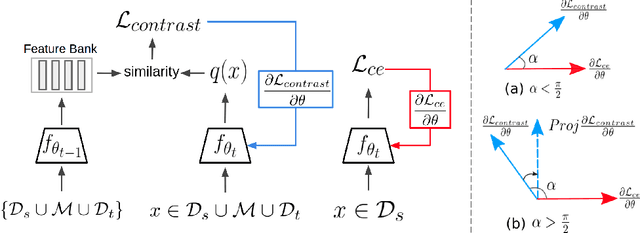

Human beings can quickly adapt to environmental changes by leveraging learning experience. However, the poor ability of adapting to dynamic environments remains a major challenge for AI models. To better understand this issue, we study the problem of continual domain adaptation, where the model is presented with a labeled source domain and a sequence of unlabeled target domains. There are two major obstacles in this problem: domain shifts and catastrophic forgetting. In this work, we propose Gradient Regularized Contrastive Learning to solve the above obstacles. At the core of our method, gradient regularization plays two key roles: (1) enforces the gradient of contrastive loss not to increase the supervised training loss on the source domain, which maintains the discriminative power of learned features; (2) regularizes the gradient update on the new domain not to increase the classification loss on the old target domains, which enables the model to adapt to an in-coming target domain while preserving the performance of previously observed domains. Hence our method can jointly learn both semantically discriminative and domain-invariant features with labeled source domain and unlabeled target domains. The experiments on Digits, DomainNet and Office-Caltech benchmarks demonstrate the strong performance of our approach when compared to the state-of-the-art.
Sep-Stereo: Visually Guided Stereophonic Audio Generation by Associating Source Separation
Jul 20, 2020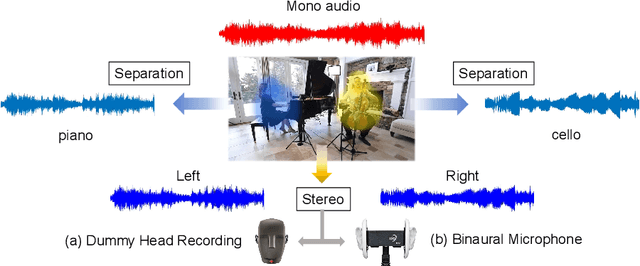
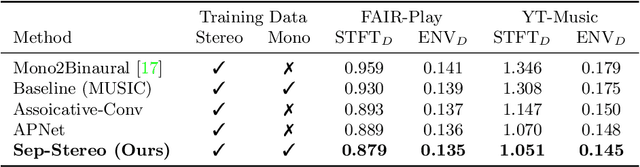
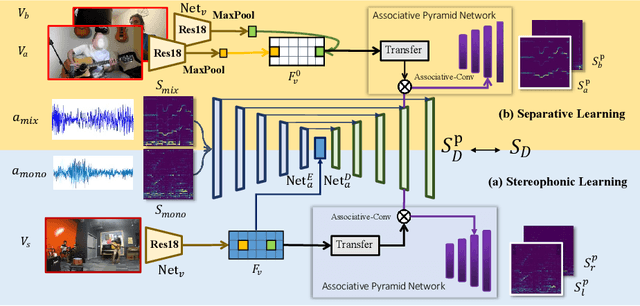
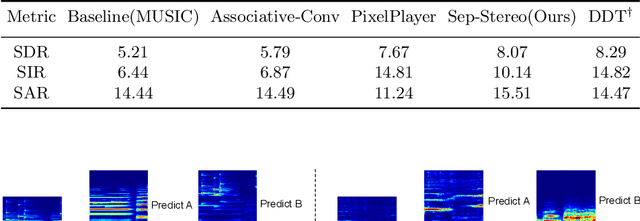
Stereophonic audio is an indispensable ingredient to enhance human auditory experience. Recent research has explored the usage of visual information as guidance to generate binaural or ambisonic audio from mono ones with stereo supervision. However, this fully supervised paradigm suffers from an inherent drawback: the recording of stereophonic audio usually requires delicate devices that are expensive for wide accessibility. To overcome this challenge, we propose to leverage the vastly available mono data to facilitate the generation of stereophonic audio. Our key observation is that the task of visually indicated audio separation also maps independent audios to their corresponding visual positions, which shares a similar objective with stereophonic audio generation. We integrate both stereo generation and source separation into a unified framework, Sep-Stereo, by considering source separation as a particular type of audio spatialization. Specifically, a novel associative pyramid network architecture is carefully designed for audio-visual feature fusion. Extensive experiments demonstrate that our framework can improve the stereophonic audio generation results while performing accurate sound separation with a shared backbone.
PIE-NET: Parametric Inference of Point Cloud Edges
Jul 09, 2020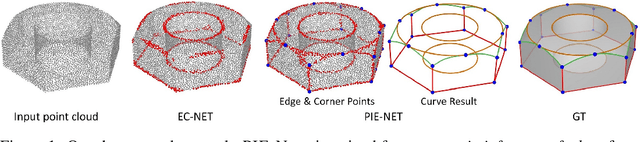

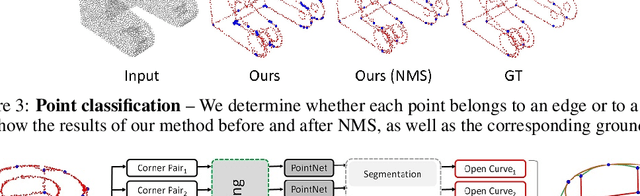
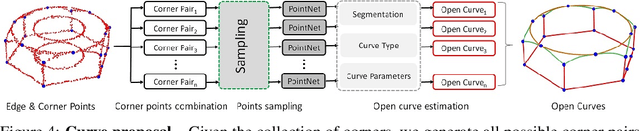
We introduce an end-to-end learnable technique to robustly identify feature edges in 3D point cloud data. We represent these edges as a collection of parametric curves (i.e.,lines, circles, and B-splines). Accordingly, our deep neural network, coined PIE-NET, is trained for parametric inference of edges. The network relies on a "region proposal" architecture, where a first module proposes an over-complete collection of edge and corner points, and a second module ranks each proposal to decide whether it should be considered. We train and evaluate our method on the ABC dataset, a large dataset of CAD models, and compare our results to those produced by traditional (non-learning) processing pipelines, as well as a recent deep learning based edge detector (EC-NET). Our results significantly improve over the state-of-the-art from both a quantitative and qualitative standpoint.
3D Human Mesh Regression with Dense Correspondence
Jun 10, 2020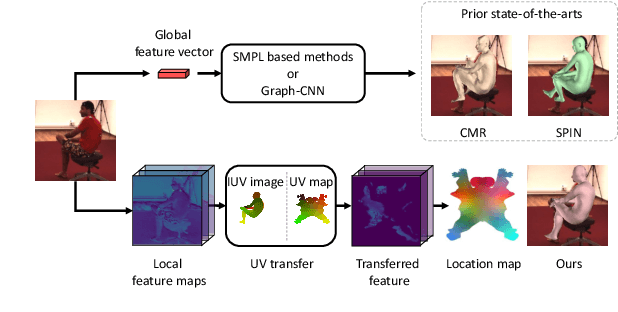
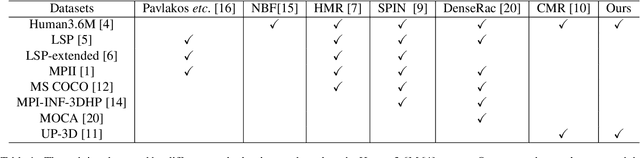

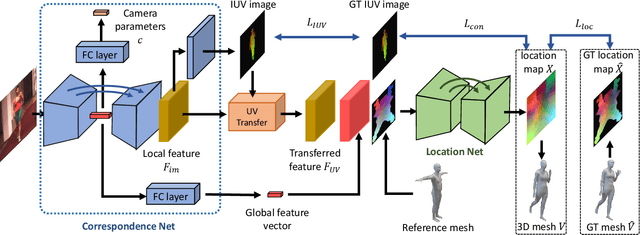
Estimating 3D mesh of the human body from a single 2D image is an important task with many applications such as augmented reality and Human-Robot interaction. However, prior works reconstructed 3D mesh from global image feature extracted by using convolutional neural network (CNN), where the dense correspondences between the mesh surface and the image pixels are missing, leading to suboptimal solution. This paper proposes a model-free 3D human mesh estimation framework, named DecoMR, which explicitly establishes the dense correspondence between the mesh and the local image features in the UV space (i.e. a 2D space used for texture mapping of 3D mesh). DecoMR first predicts pixel-to-surface dense correspondence map (i.e., IUV image), with which we transfer local features from the image space to the UV space. Then the transferred local image features are processed in the UV space to regress a location map, which is well aligned with transferred features. Finally we reconstruct 3D human mesh from the regressed location map with a predefined mapping function. We also observe that the existing discontinuous UV map are unfriendly to the learning of network. Therefore, we propose a novel UV map that maintains most of the neighboring relations on the original mesh surface. Experiments demonstrate that our proposed local feature alignment and continuous UV map outperforms existing 3D mesh based methods on multiple public benchmarks. Code will be made available at https://github.com/zengwang430521/DecoMR
StereoGAN: Bridging Synthetic-to-Real Domain Gap by Joint Optimization of Domain Translation and Stereo Matching
May 05, 2020
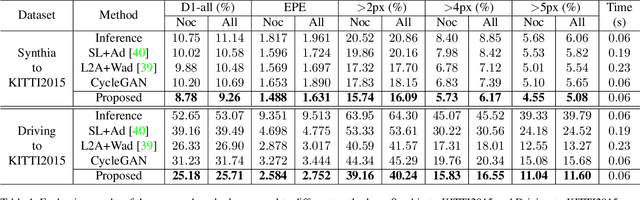

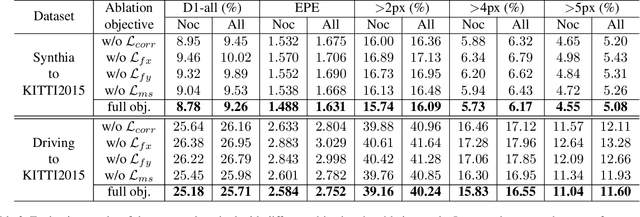
Large-scale synthetic datasets are beneficial to stereo matching but usually introduce known domain bias. Although unsupervised image-to-image translation networks represented by CycleGAN show great potential in dealing with domain gap, it is non-trivial to generalize this method to stereo matching due to the problem of pixel distortion and stereo mismatch after translation. In this paper, we propose an end-to-end training framework with domain translation and stereo matching networks to tackle this challenge. First, joint optimization between domain translation and stereo matching networks in our end-to-end framework makes the former facilitate the latter one to the maximum extent. Second, this framework introduces two novel losses, i.e., bidirectional multi-scale feature re-projection loss and correlation consistency loss, to help translate all synthetic stereo images into realistic ones as well as maintain epipolar constraints. The effective combination of above two contributions leads to impressive stereo-consistent translation and disparity estimation accuracy. In addition, a mode seeking regularization term is added to endow the synthetic-to-real translation results with higher fine-grained diversity. Extensive experiments demonstrate the effectiveness of the proposed framework on bridging the synthetic-to-real domain gap on stereo matching.
Cascaded Refinement Network for Point Cloud Completion
Apr 07, 2020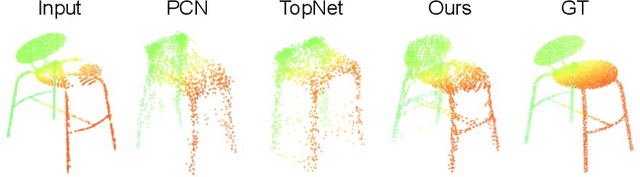
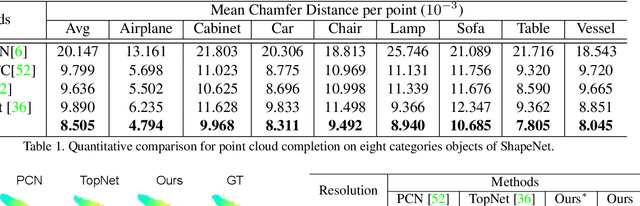
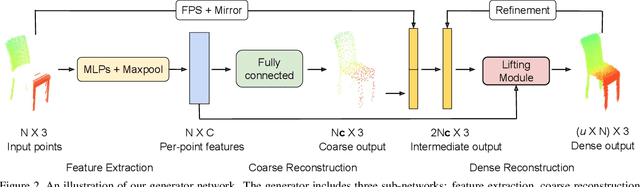
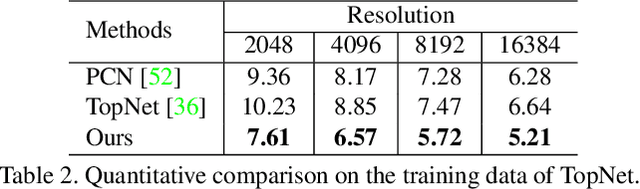
Point clouds are often sparse and incomplete. Existing shape completion methods are incapable of generating details of objects or learning the complex point distributions. To this end, we propose a cascaded refinement network together with a coarse-to-fine strategy to synthesize the detailed object shapes. Considering the local details of partial input with the global shape information together, we can preserve the existing details in the incomplete point set and generate the missing parts with high fidelity. We also design a patch discriminator that guarantees every local area has the same pattern with the ground truth to learn the complicated point distribution. Quantitative and qualitative experiments on different datasets show that our method achieves superior results compared to existing state-of-the-art approaches on the 3D point cloud completion task. Our source code is available at https://github.com/xiaogangw/cascaded-point-completion.git.
Rotate-and-Render: Unsupervised Photorealistic Face Rotation from Single-View Images
Mar 18, 2020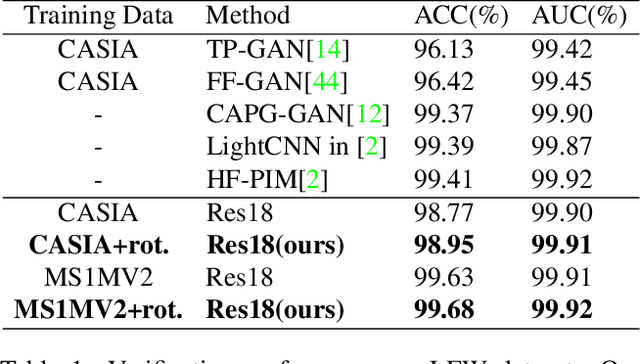
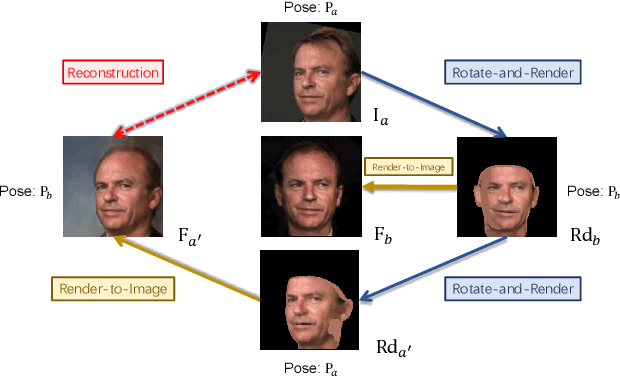

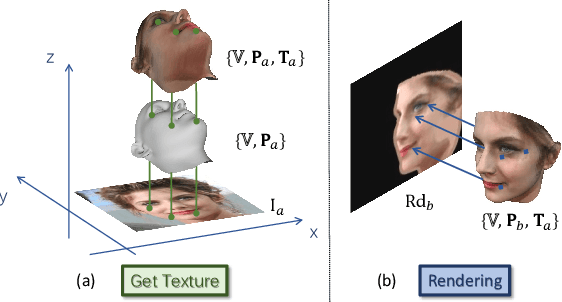
Though face rotation has achieved rapid progress in recent years, the lack of high-quality paired training data remains a great hurdle for existing methods. The current generative models heavily rely on datasets with multi-view images of the same person. Thus, their generated results are restricted by the scale and domain of the data source. To overcome these challenges, we propose a novel unsupervised framework that can synthesize photo-realistic rotated faces using only single-view image collections in the wild. Our key insight is that rotating faces in the 3D space back and forth, and re-rendering them to the 2D plane can serve as a strong self-supervision. We leverage the recent advances in 3D face modeling and high-resolution GAN to constitute our building blocks. Since the 3D rotation-and-render on faces can be applied to arbitrary angles without losing details, our approach is extremely suitable for in-the-wild scenarios (i.e. no paired data are available), where existing methods fall short. Extensive experiments demonstrate that our approach has superior synthesis quality as well as identity preservation over the state-of-the-art methods, across a wide range of poses and domains. Furthermore, we validate that our rotate-and-render framework naturally can act as an effective data augmentation engine for boosting modern face recognition systems even on strong baseline models.
1st Place Solutions for OpenImage2019 -- Object Detection and Instance Segmentation
Mar 17, 2020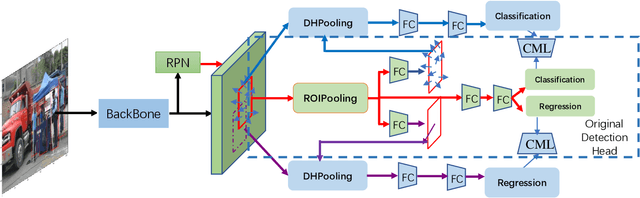


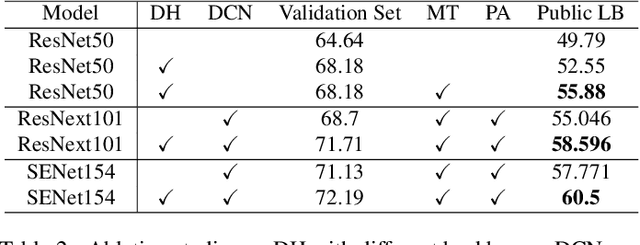
This article introduces the solutions of the two champion teams, `MMfruit' for the detection track and `MMfruitSeg' for the segmentation track, in OpenImage Challenge 2019. It is commonly known that for an object detector, the shared feature at the end of the backbone is not appropriate for both classification and regression, which greatly limits the performance of both single stage detector and Faster RCNN \cite{ren2015faster} based detector. In this competition, we observe that even with a shared feature, different locations in one object has completely inconsistent performances for the two tasks. \textit{E.g. the features of salient locations are usually good for classification, while those around the object edge are good for regression.} Inspired by this, we propose the Decoupling Head (DH) to disentangle the object classification and regression via the self-learned optimal feature extraction, which leads to a great improvement. Furthermore, we adjust the soft-NMS algorithm to adj-NMS to obtain stable performance improvement. Finally, a well-designed ensemble strategy via voting the bounding box location and confidence is proposed. We will also introduce several training/inferencing strategies and a bag of tricks that give minor improvement. Given those masses of details, we train and aggregate 28 global models with various backbones, heads and 3+2 expert models, and achieves the 1st place on the OpenImage 2019 Object Detection Challenge on the both public and private leadboards. Given such good instance bounding box, we further design a simple instance-level semantic segmentation pipeline and achieve the 1st place on the segmentation challenge.