 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAMP: Cross-Modal Adaptive Message Passing for Text-Image Retrieval
Sep 12, 2019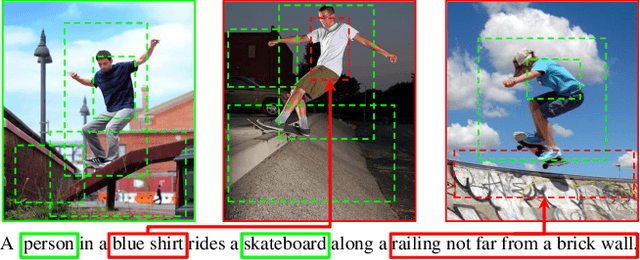
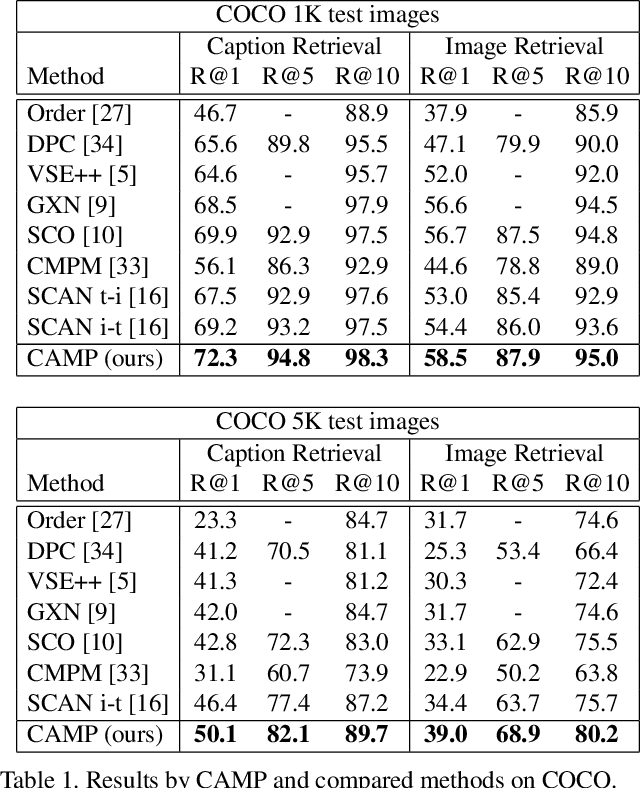
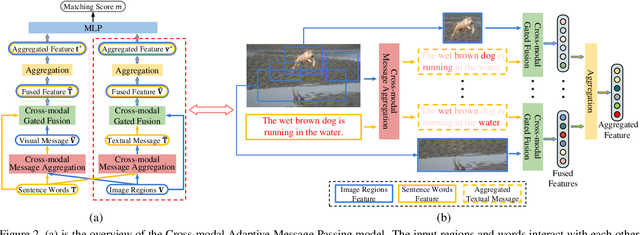
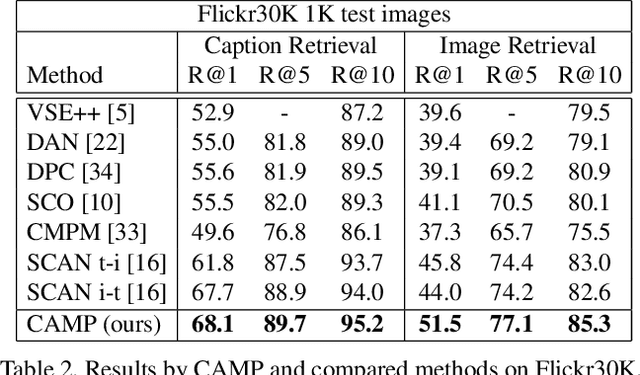
Text-image cross-modal retrieval is a challenging task in the field of language and vision. Most previous approaches independently embed images and sentences into a joint embedding space and compare their similarities. However, previous approaches rarely explore the interactions between images and sentences before calculating similarities in the joint space. Intuitively, when matching between images and sentences, human beings would alternatively attend to regions in images and words in sentences, and select the most salient information considering the interaction between both modalities. In this paper, we propose Cross-modal Adaptive Message Passing (CAMP), which adaptively controls the information flow for message passing across modalities. Our approach not only takes comprehensive and fine-grained cross-modal interactions into account, but also properly handles negative pairs and irrelevant information with an adaptive gating scheme. Moreover, instead of conventional joint embedding approaches for text-image matching, we infer the matching score based on the fused features, and propose a hardest negative binary cross-entropy loss for training. Results on COCO and Flickr30k significantly surpass state-of-the-art methods, demonstrating the effectiveness of our approach.
Deep Self-Learning From Noisy Labels
Aug 20, 2019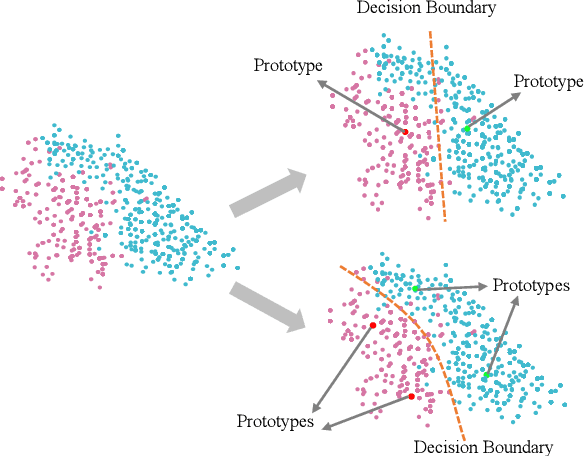
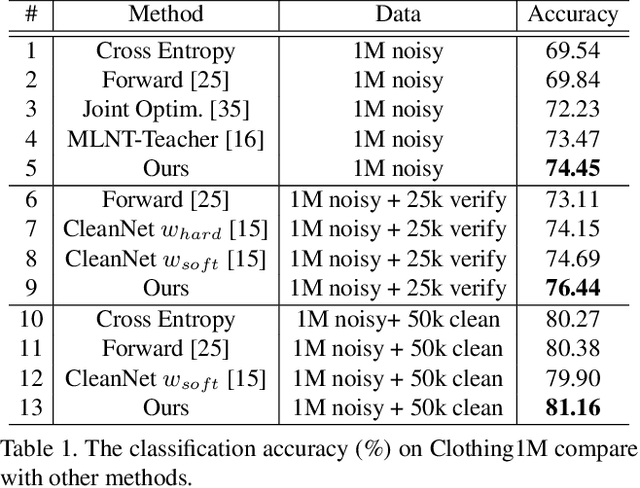
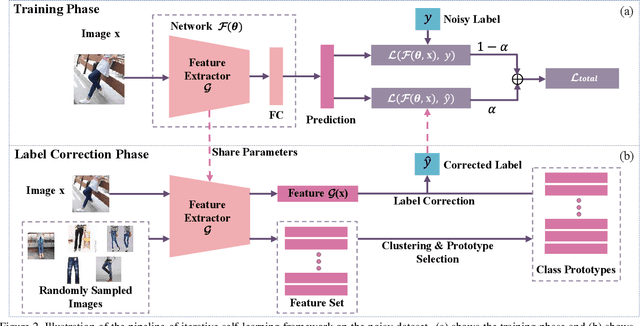
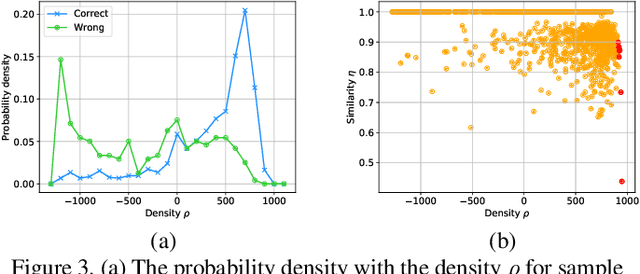
ConvNets achieve good results when training from clean data, but learning from noisy labels significantly degrades performances and remains challenging. Unlike previous works constrained by many conditions, making them infeasible to real noisy cases, this work presents a novel deep self-learning framework to train a robust network on the real noisy datasets without extra supervision. The proposed approach has several appealing benefits. (1) Different from most existing work, it does not rely on any assumption on the distribution of the noisy labels, making it robust to real noises. (2) It does not need extra clean supervision or accessorial network to help training. (3) A self-learning framework is proposed to train the network in an iterative end-to-end manner, which is effective and efficient. Extensive experiments in challenging benchmarks such as Clothing1M and Food101-N show that our approach outperforms its counterparts in all empirical settings.
Differentiable Learning-to-Group Channels via Groupable Convolutional Neural Networks
Aug 19, 2019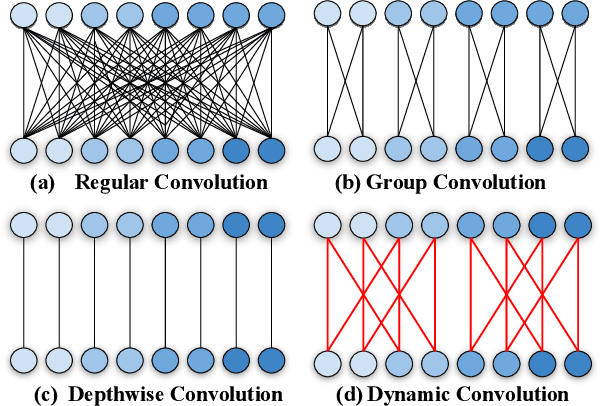
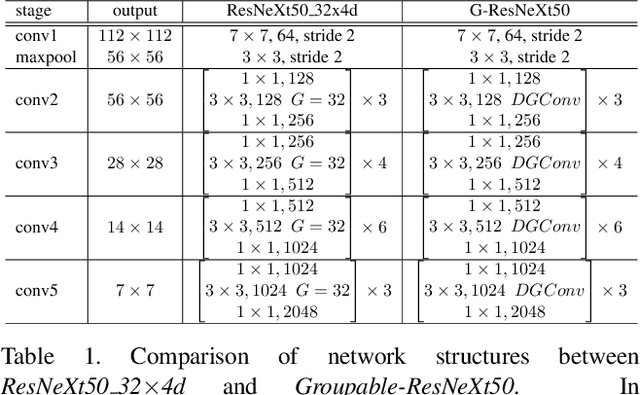
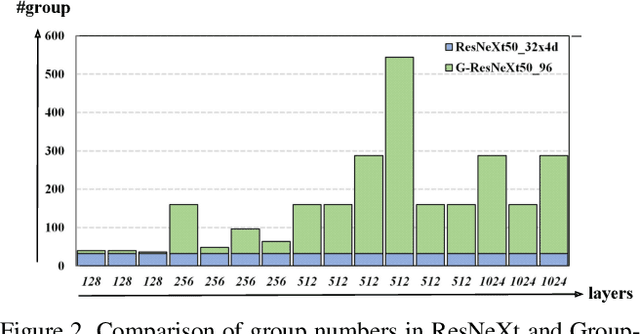
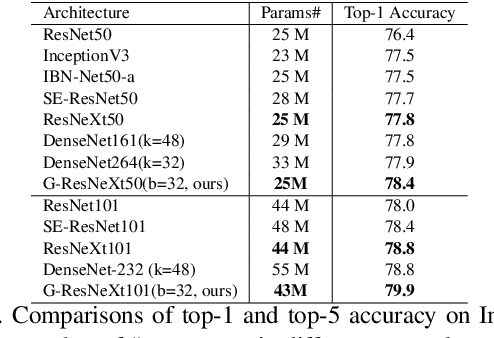
Group convolution, which divides the channels of ConvNets into groups, has achieved impressive improvement over the regular convolution operation. However, existing models, eg. ResNeXt, still suffers from the sub-optimal performance due to manually defining the number of groups as a constant over all of the layers. Toward addressing this issue, we present Groupable ConvNet (GroupNet) built by using a novel dynamic grouping convolution (DGConv) operation, which is able to learn the number of groups in an end-to-end manner. The proposed approach has several appealing benefits. (1) DGConv provides a unified convolution representation and covers many existing convolution operations such as regular dense convolution, group convolution, and depthwise convolution. (2) DGConv is a differentiable and flexible operation which learns to perform various convolutions from training data. (3) GroupNet trained with DGConv learns different number of groups for different convolution layers. Extensive experiments demonstrate that GroupNet outperforms its counterparts such as ResNet and ResNeXt in terms of accuracy and computational complexity. We also present introspection and reproducibility study, for the first time, showing the learning dynamics of training group numbers.
Once a MAN: Towards Multi-Target Attack via Learning Multi-Target Adversarial Network Once
Aug 14, 2019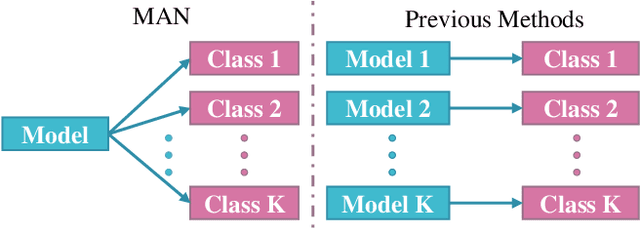
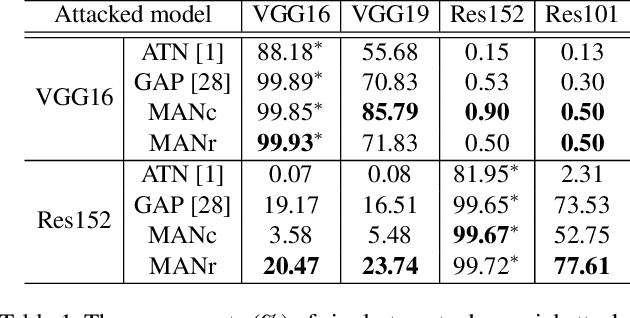
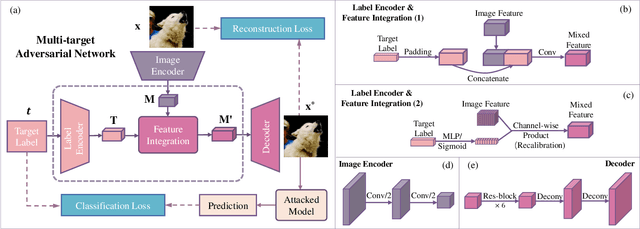
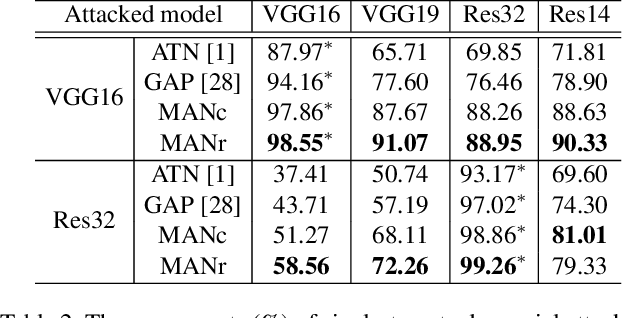
Modern deep neural networks are often vulnerable to adversarial samples. Based on the first optimization-based attacking method, many following methods are proposed to improve the attacking performance and speed. Recently, generation-based methods have received much attention since they directly use feed-forward networks to generate the adversarial samples, which avoid the time-consuming iterative attacking procedure in optimization-based and gradient-based methods. However, current generation-based methods are only able to attack one specific target (category) within one model, thus making them not applicable to real classification systems that often have hundreds/thousands of categories. In this paper, we propose the first Multi-target Adversarial Network (MAN), which can generate multi-target adversarial samples with a single model. By incorporating the specified category information into the intermediate features, it can attack any category of the target classification model during runtime. Experiments show that the proposed MAN can produce stronger attack results and also have better transferability than previous state-of-the-art methods in both multi-target attack task and single-target attack task. We further use the adversarial samples generated by our MAN to improve the robustness of the classification model. It can also achieve better classification accuracy than other methods when attacked by various methods.
Interpolated Convolutional Networks for 3D Point Cloud Understanding
Aug 13, 2019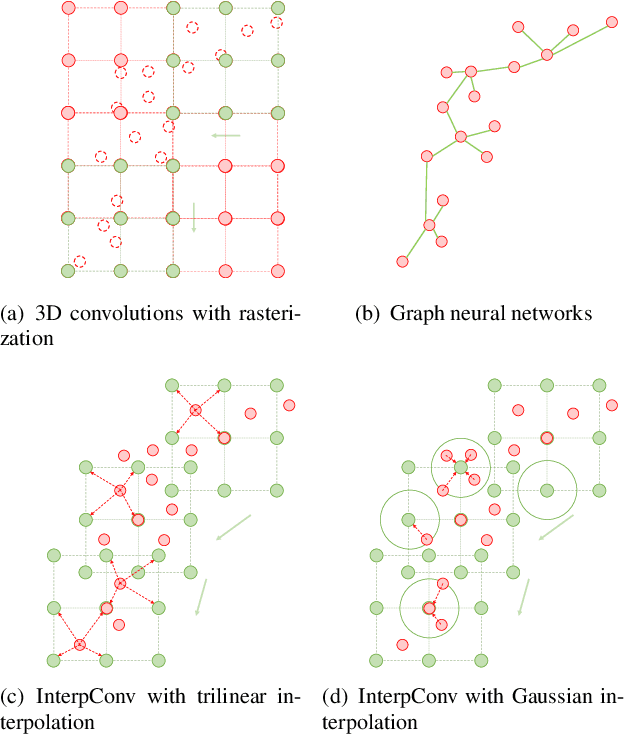
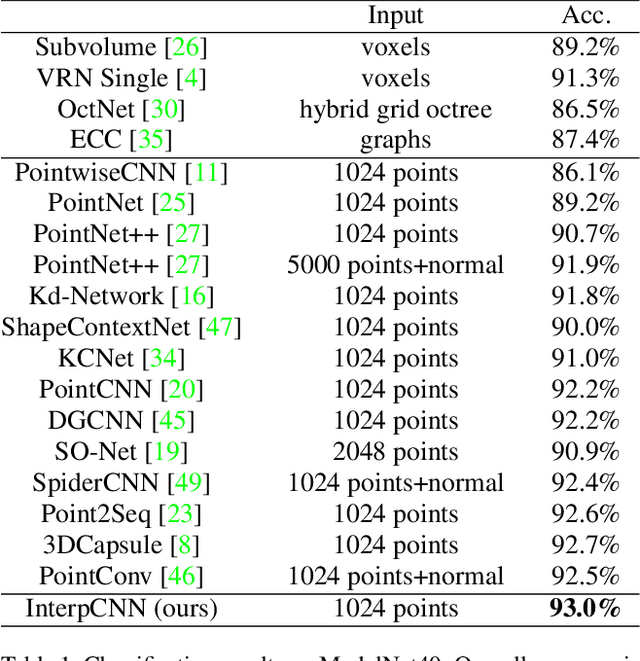
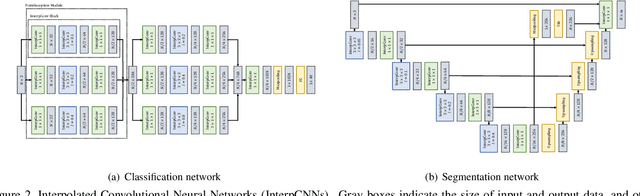
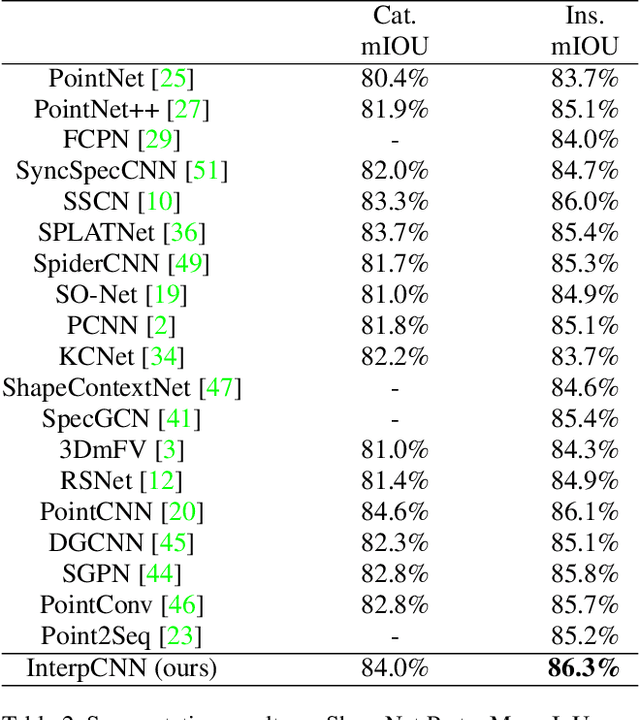
Point cloud is an important type of 3D representation. However, directly applying convolutions on point clouds is challenging due to the sparse, irregular and unordered data structure. In this paper, we propose a novel Interpolated Convolution operation, InterpConv, to tackle the point cloud feature learning and understanding problem. The key idea is to utilize a set of discrete kernel weights and interpolate point features to neighboring kernel-weight coordinates by an interpolation function for convolution. A normalization term is introduced to handle neighborhoods of different sparsity levels. Our InterpConv is shown to be permutation and sparsity invariant, and can directly handle irregular inputs. We further design Interpolated Convolutional Neural Networks (InterpCNNs) based on InterpConv layers to handle point cloud recognition tasks including shape classification, object part segmentation and indoor scene semantic parsing. Experiments show that the networks can capture both fine-grained local structures and global shape context information effectively. The proposed approach achieves state-of-the-art performance on public benchmarks including ModelNet40, ShapeNet Parts and S3DIS.
Multi-modality Latent Interaction Network for Visual Question Answering
Aug 10, 2019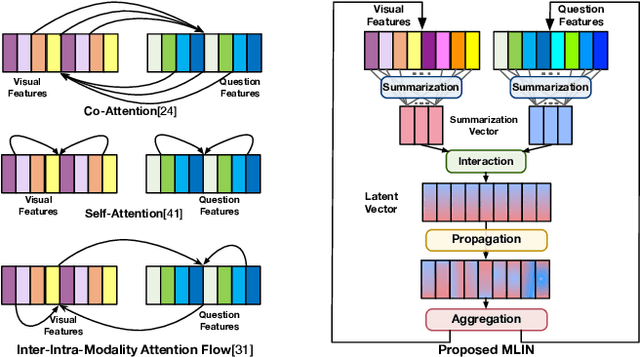
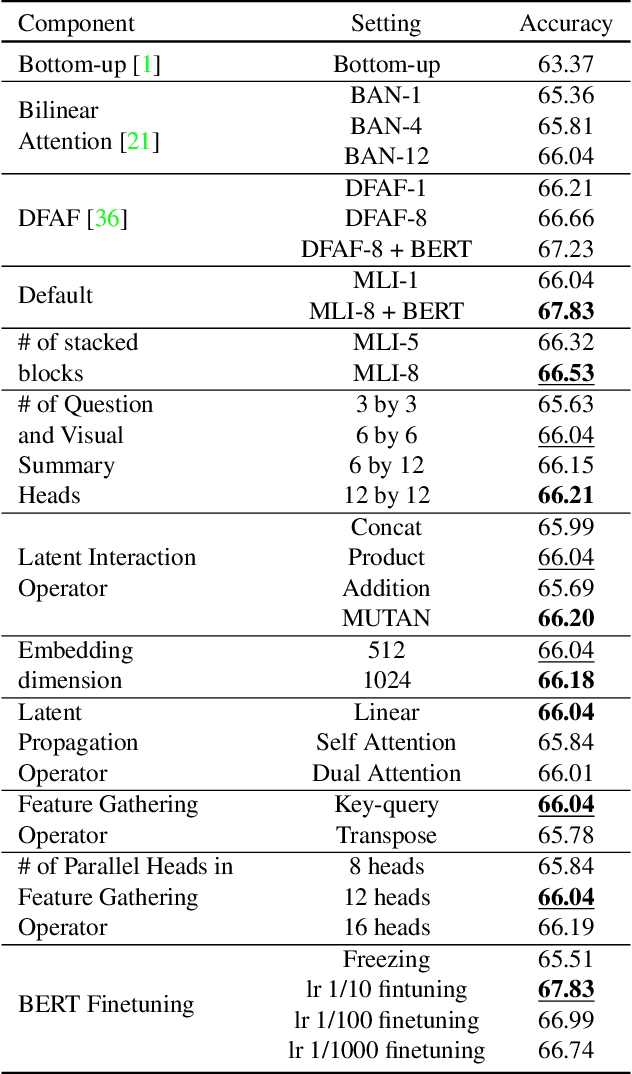
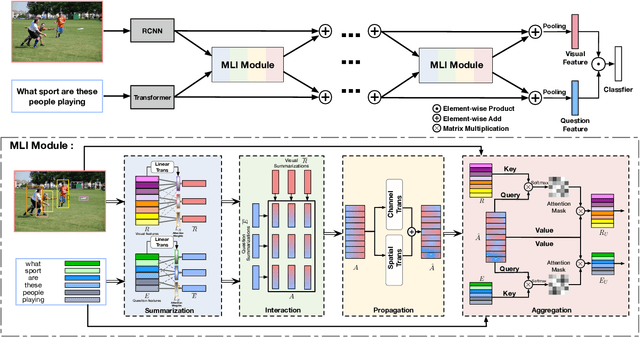
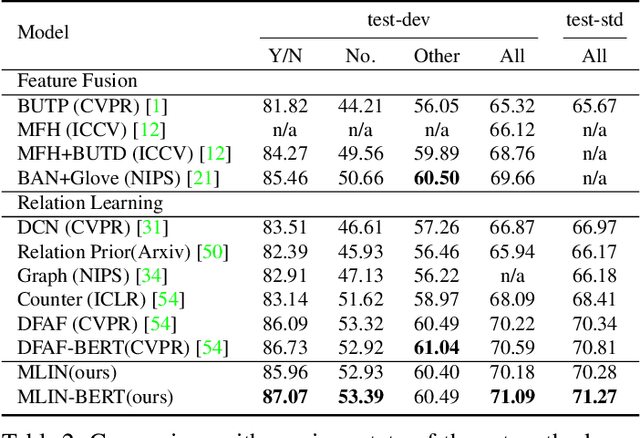
Exploiting relationships between visual regions and question words have achieved great success in learning multi-modality features for Visual Question Answering (VQA). However, we argue that existing methods mostly model relations between individual visual regions and words, which are not enough to correctly answer the question. From humans' perspective, answering a visual question requires understanding the summarizations of visual and language information. In this paper, we proposed the Multi-modality Latent Interaction module (MLI) to tackle this problem. The proposed module learns the cross-modality relationships between latent visual and language summarizations, which summarize visual regions and question into a small number of latent representations to avoid modeling uninformative individual region-word relations. The cross-modality information between the latent summarizations are propagated to fuse valuable information from both modalities and are used to update the visual and word features. Such MLI modules can be stacked for several stages to model complex and latent relations between the two modalities and achieves highly competitive performance on public VQA benchmarks, VQA v2.0 and TDIUC . In addition, we show that the performance of our methods could be significantly improved by combining with pre-trained language model BERT.
Part-A^2 Net: 3D Part-Aware and Aggregation Neural Network for Object Detection from Point Cloud
Jul 08, 2019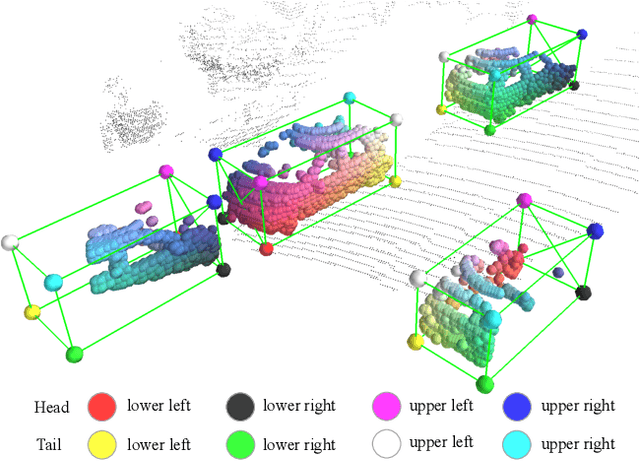
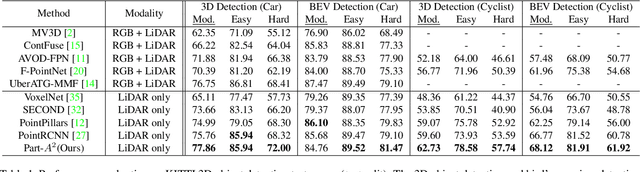
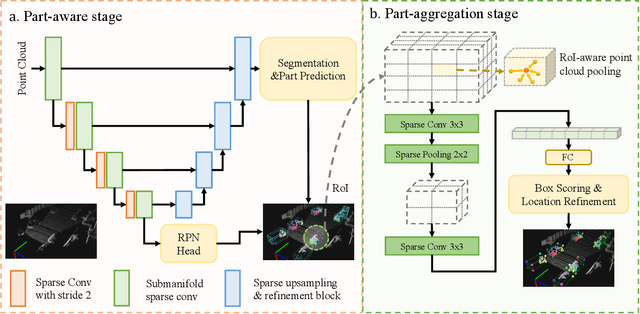
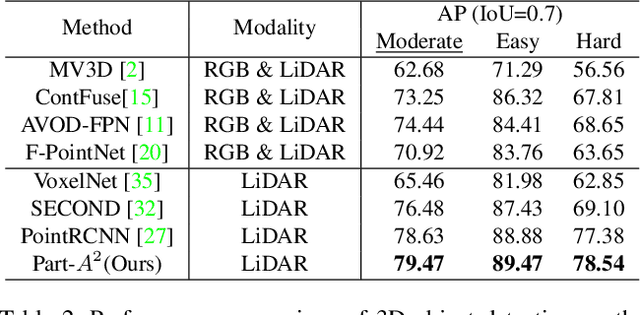
In this paper, we propose the part-aware and aggregation neural network (Part-A^2 net) for 3D object detection from point cloud. The whole framework consists of the part-aware stage and the part-aggregation stage. Firstly, the part-aware stage learns to simultaneously predict coarse 3D proposals and accurate intra-object part locations with the free-of-charge supervisions derived from 3D ground-truth boxes. The predicted intra-object part locations within the same proposals are grouped by our new-designed RoI-aware point cloud pooling module, which results in an effective representation to encode the features of 3D proposals. Then the part-aggregation stage learns to re-score the box and refine the box location based on the pooled part locations. We present extensive experiments on the KITTI 3D object detection dataset, which demonstrate that both the predicted intra-object part locations and the proposed RoI-aware point cloud pooling scheme benefit 3D object detection and our Part-A^2 net outperforms state-of-the-art methods by utilizing only point cloud data.
Finding Task-Relevant Features for Few-Shot Learning by Category Traversal
May 27, 2019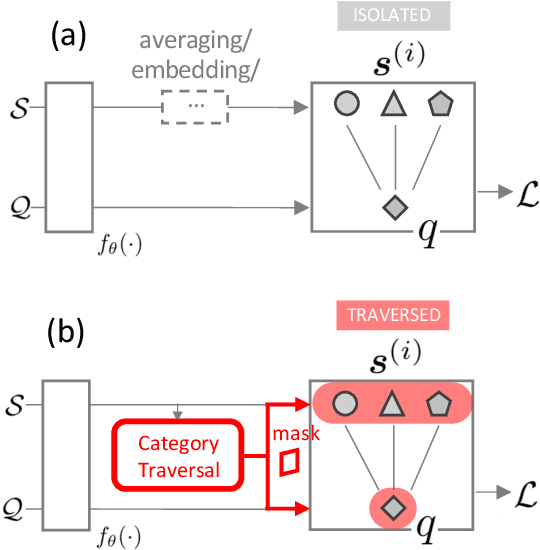
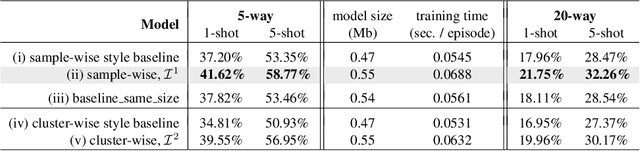
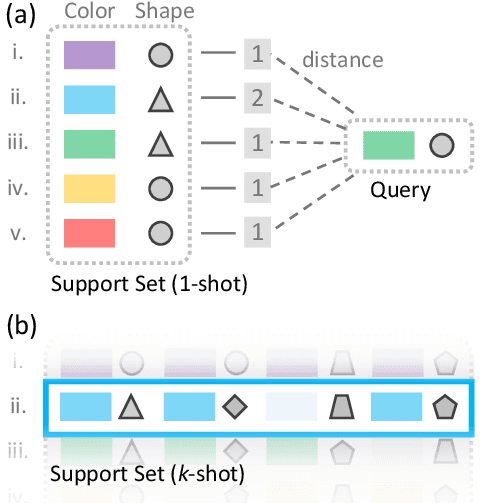
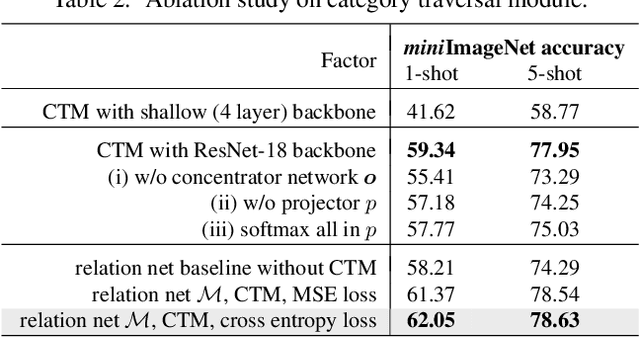
Few-shot learning is an important area of research. Conceptually, humans are readily able to understand new concepts given just a few examples, while in more pragmatic terms, limited-example training situations are common in practice. Recent effective approaches to few-shot learning employ a metric-learning framework to learn a feature similarity comparison between a query (test) example, and the few support (training) examples. However, these approaches treat each support class independently from one another, never looking at the entire task as a whole. Because of this, they are constrained to use a single set of features for all possible test-time tasks, which hinders the ability to distinguish the most relevant dimensions for the task at hand. In this work, we introduce a Category Traversal Module that can be inserted as a plug-and-play module into most metric-learning based few-shot learners. This component traverses across the entire support set at once, identifying task-relevant features based on both intra-class commonality and inter-class uniqueness in the feature space. Incorporating our module improves performance considerably (5%-10% relative) over baseline systems on both mini-ImageNet and tieredImageNet benchmarks, with overall performance competitive with recent state-of-the-art systems.
P2SGrad: Refined Gradients for Optimizing Deep Face Models
May 07, 2019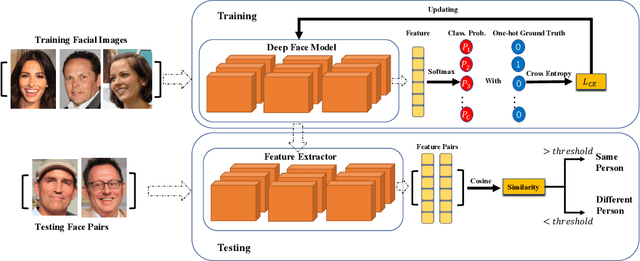
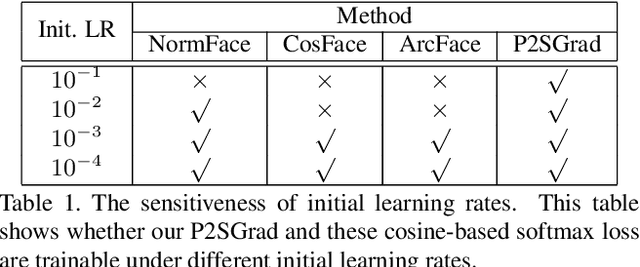
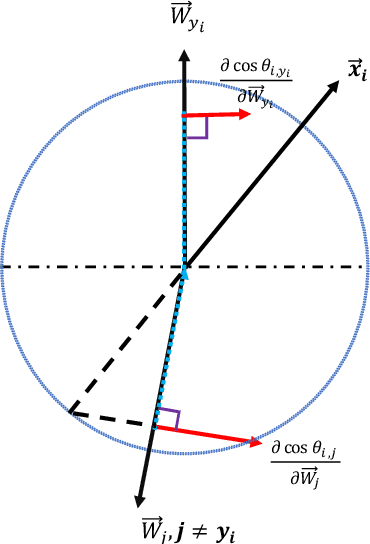
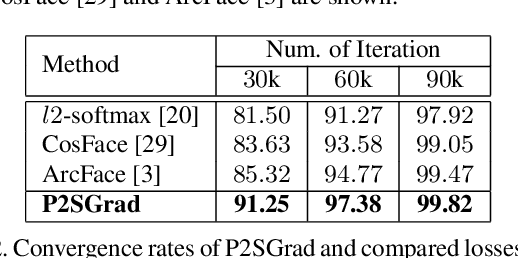
Cosine-based softmax losses significantly improve the performance of deep face recognition networks. However, these losses always include sensitive hyper-parameters which can make training process unstable, and it is very tricky to set suitable hyper parameters for a specific dataset. This paper addresses this challenge by directly designing the gradients for adaptively training deep neural networks. We first investigate and unify previous cosine softmax losses by analyzing their gradients. This unified view inspires us to propose a novel gradient called P2SGrad (Probability-to-Similarity Gradient), which leverages a cosine similarity instead of classification probability to directly update the testing metrics for updating neural network parameters. P2SGrad is adaptive and hyper-parameter free, which makes the training process more efficient and faster. We evaluate our P2SGrad on three face recognition benchmarks, LFW, MegaFace, and IJB-C. The results show that P2SGrad is stable in training, robust to noise, and achieves state-of-the-art performance on all the three benchmarks.
AdaCos: Adaptively Scaling Cosine Logits for Effectively Learning Deep Face Representations
May 07, 2019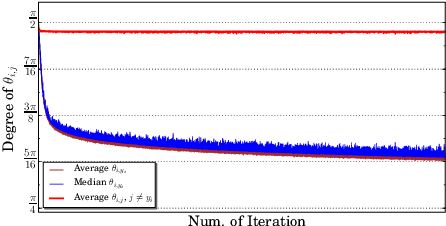
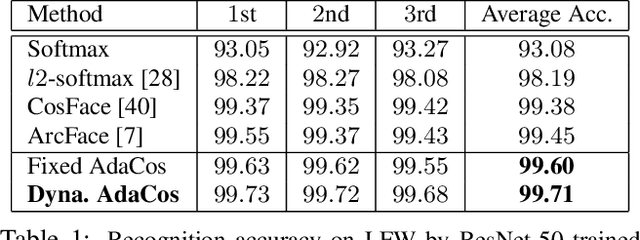

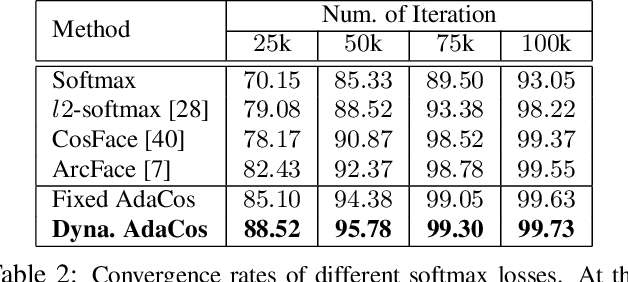
The cosine-based softmax losses and their variants achieve great success in deep learning based face recognition. However, hyperparameter settings in these losses have significant influences on the optimization path as well as the final recognition performance. Manually tuning those hyperparameters heavily relies on user experience and requires many training tricks. In this paper, we investigate in depth the effects of two important hyperparameters of cosine-based softmax losses, the scale parameter and angular margin parameter, by analyzing how they modulate the predicted classification probability. Based on these analysis, we propose a novel cosine-based softmax loss, AdaCos, which is hyperparameter-free and leverages an adaptive scale parameter to automatically strengthen the training supervisions during the training process. We apply the proposed AdaCos loss to large-scale face verification and identification datasets, including LFW, MegaFace, and IJB-C 1:1 Verification. Our results show that training deep neural networks with the AdaCos loss is stable and able to achieve high face recognition accuracy. Our method outperforms state-of-the-art softmax losses on all the three datasets.