 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Mitigating the High Computational Cost in Path Data Diffusion
Feb 02, 2025Advancements in mobility services, navigation systems, and smart transportation technologies have made it possible to collect large amounts of path data. Modeling the distribution of this path data, known as the Path Generation (PG) problem, is crucial for understanding urban mobility patterns and developing intelligent transportation systems. Recent studies have explored using diffusion models to address the PG problem due to their ability to capture multimodal distributions and support conditional generation. A recent work devises a diffusion process explicitly in graph space and achieves state-of-the-art performance. However, this method suffers a high computation cost in terms of both time and memory, which prohibits its application. In this paper, we analyze this method both theoretically and experimentally and find that the main culprit of its high computation cost is its explicit design of the diffusion process in graph space. To improve efficiency, we devise a Latent-space Path Diffusion (LPD) model, which operates in latent space instead of graph space. Our LPD significantly reduces both time and memory costs by up to 82.8% and 83.1%, respectively. Despite these reductions, our approach does not suffer from performance degradation. It outperforms the state-of-the-art method in most scenarios by 24.5%~34.0%.
Prioritize Denoising Steps on Diffusion Model Preference Alignment via Explicit Denoised Distribution Estimation
Nov 22, 2024



Diffusion models have shown remarkable success in text-to-image generation, making alignment methods for these models increasingly important. A key challenge is the sparsity of preference labels, which are typically available only at the terminal of denoising trajectories. This raises the issue of how to assign credit across denoising steps based on these sparse labels. In this paper, we propose Denoised Distribution Estimation (DDE), a novel method for credit assignment. Unlike previous approaches that rely on auxiliary models or hand-crafted schemes, DDE derives its strategy more explicitly. The proposed DDE directly estimates the terminal denoised distribution from the perspective of each step. It is equipped with two estimation strategies and capable of representing the entire denoising trajectory with a single model inference. Theoretically and empirically, we show that DDE prioritizes optimizing the middle part of the denoising trajectory, resulting in a novel and effective credit assignment scheme. Extensive experiments demonstrate that our approach achieves superior performance, both quantitatively and qualitatively.
DreamCouple: Exploring High Quality Text-to-3D Generation Via Rectified Flow
Aug 09, 2024The Score Distillation Sampling (SDS), which exploits pretrained text-to-image model diffusion models as priors to 3D model training, has achieved significant success. Currently, the flow-based diffusion model has become a new trend for generations. Yet, adapting SDS to flow-based diffusion models in 3D generation remains unexplored. Our work is aimed to bridge this gap. In this paper, we adapt SDS to rectified flow and re-examine the over-smoothing issue under this novel framework. The issue can be explained that the model learns an average of multiple ODE trajectories. Then we propose DreamCouple, which instead of randomly sampling noise, uses a rectified flow model to find the coupled noise. Its Unique Couple Matching (UCM) loss guides the model to learn different trajectories and thus solves the over-smoothing issue. We apply our method to both NeRF and 3D Gaussian splatting and achieve state-of-the-art performances. We also identify some other interesting open questions such as initialization issues for NeRF and faster training convergence. Our code will be released soon.
Adaptive Task Planning for Large-Scale Robotized Warehouses
Apr 24, 2022
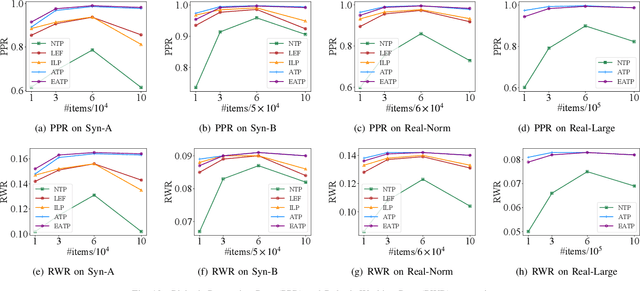
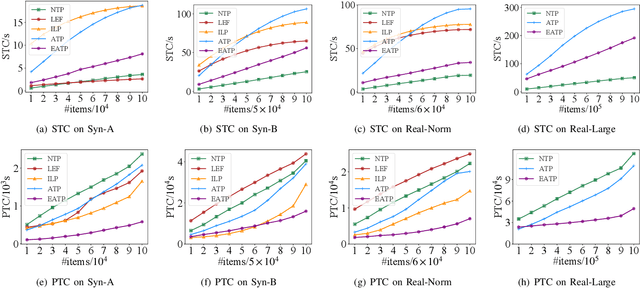
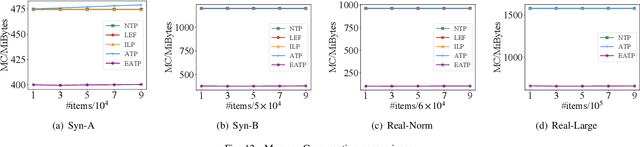
Robotized warehouses are deployed to automatically distribute millions of items brought by the massive logistic orders from e-commerce. A key to automated item distribution is to plan paths for robots, also known as task planning, where each task is to deliver racks with items to pickers for processing and then return the rack back. Prior solutions are unfit for large-scale robotized warehouses due to the inflexibility to time-varying item arrivals and the low efficiency for high throughput. In this paper, we propose a new task planning problem called TPRW, which aims to minimize the end-to-end makespan that incorporates the entire item distribution pipeline, known as a fulfilment cycle. Direct extensions from state-of-the-art path finding methods are ineffective to solve the TPRW problem because they fail to adapt to the bottleneck variations of fulfillment cycles. In response, we propose Efficient Adaptive Task Planning, a framework for large-scale robotized warehouses with time-varying item arrivals. It adaptively selects racks to fulfill at each timestamp via reinforcement learning, accounting for the time-varying bottleneck of the fulfillment cycles. Then it finds paths for robots to transport the selected racks. The framework adopts a series of efficient optimizations on both time and memory to handle large-scale item throughput. Evaluations on both synthesized and real data show an improvement of $37.1\%$ in effectiveness and $75.5\%$ in efficiency over the state-of-the-arts.
Value Function is All You Need: A Unified Learning Framework for Ride Hailing Platforms
Jun 04, 2021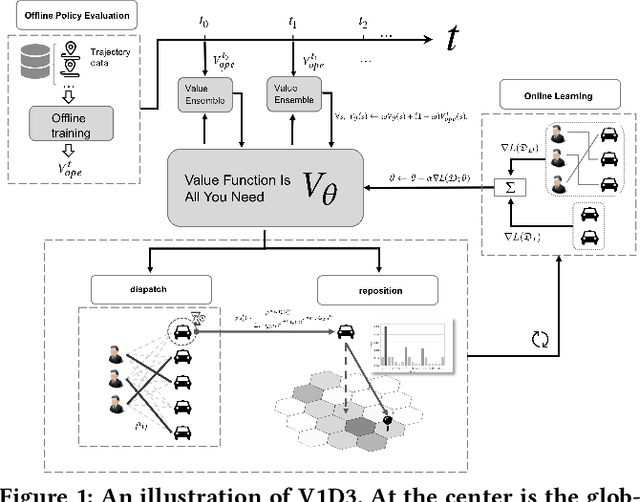
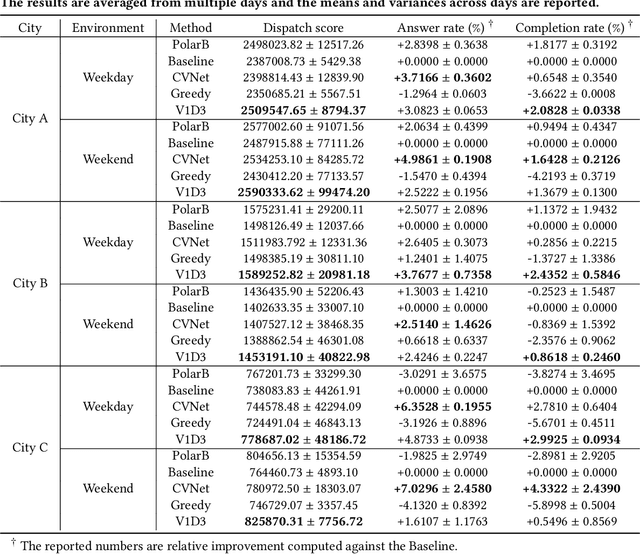
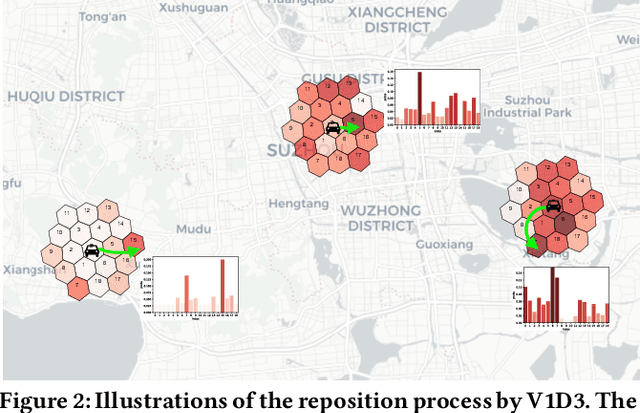
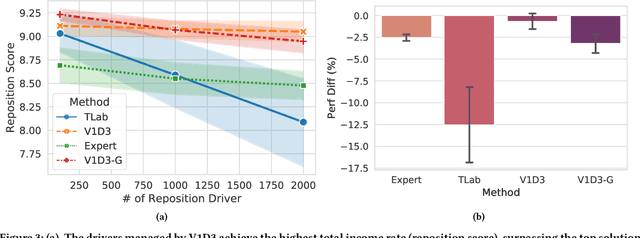
Large ride-hailing platforms, such as DiDi, Uber and Lyft, connect tens of thousands of vehicles in a city to millions of ride demands throughout the day, providing great promises for improving transportation efficiency through the tasks of order dispatching and vehicle repositioning. Existing studies, however, usually consider the two tasks in simplified settings that hardly address the complex interactions between the two, the real-time fluctuations between supply and demand, and the necessary coordinations due to the large-scale nature of the problem. In this paper we propose a unified value-based dynamic learning framework (V1D3) for tackling both tasks. At the center of the framework is a globally shared value function that is updated continuously using online experiences generated from real-time platform transactions. To improve the sample-efficiency and the robustness, we further propose a novel periodic ensemble method combining the fast online learning with a large-scale offline training scheme that leverages the abundant historical driver trajectory data. This allows the proposed framework to adapt quickly to the highly dynamic environment, to generalize robustly to recurrent patterns and to drive implicit coordinations among the population of managed vehicles. Extensive experiments based on real-world datasets show considerably improvements over other recently proposed methods on both tasks. Particularly, V1D3 outperforms the first prize winners of both dispatching and repositioning tracks in the KDD Cup 2020 RL competition, achieving state-of-the-art results on improving both total driver income and user experience related metrics.