 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Tempo Estimation on Solo Instrumental Performance
Apr 25, 2025Recently, automatic music transcription has made it possible to convert musical audio into accurate MIDI. However, the resulting MIDI lacks music notations such as tempo, which hinders its conversion into sheet music. In this paper, we investigate state-of-the-art tempo estimation techniques and evaluate their performance on solo instrumental music. These include temporal convolutional network (TCN) and recurrent neural network (RNN) models that are pretrained on massive of mixed vocals and instrumental music, as well as TCN models trained specifically with solo instrumental performances. Through evaluations on drum, guitar, and classical piano datasets, our TCN models with the new training scheme achieved the best performance. Our newly trained TCN model increases the Acc1 metric by 38.6% for guitar tempo estimation, compared to the pretrained TCN model with an Acc1 of 61.1%. Although our trained TCN model is twice as accurate as the pretrained TCN model in estimating classical piano tempo, its Acc1 is only 50.9%. To improve the performance of deep learning models, we investigate their combinations with various post-processing methods. These post-processing techniques effectively enhance the performance of deep learning models when they struggle to estimate the tempo of specific instruments.
Step1X-Edit: A Practical Framework for General Image Editing
Apr 24, 2025In recent years, image editing models have witnessed remarkable and rapid development. The recent unveiling of cutting-edge multimodal models such as GPT-4o and Gemini2 Flash has introduced highly promising image editing capabilities. These models demonstrate an impressive aptitude for fulfilling a vast majority of user-driven editing requirements, marking a significant advancement in the field of image manipulation. However, there is still a large gap between the open-source algorithm with these closed-source models. Thus, in this paper, we aim to release a state-of-the-art image editing model, called Step1X-Edit, which can provide comparable performance against the closed-source models like GPT-4o and Gemini2 Flash. More specifically, we adopt the Multimodal LLM to process the reference image and the user's editing instruction. A latent embedding has been extracted and integrated with a diffusion image decoder to obtain the target image. To train the model, we build a data generation pipeline to produce a high-quality dataset. For evaluation, we develop the GEdit-Bench, a novel benchmark rooted in real-world user instructions. Experimental results on GEdit-Bench demonstrate that Step1X-Edit outperforms existing open-source baselines by a substantial margin and approaches the performance of leading proprietary models, thereby making significant contributions to the field of image editing.
Large Language Models for Validating Network Protocol Parsers
Apr 18, 2025



Network protocol parsers are essential for enabling correct and secure communication between devices. Bugs in these parsers can introduce critical vulnerabilities, including memory corruption, information leakage, and denial-of-service attacks. An intuitive way to assess parser correctness is to compare the implementation with its official protocol standard. However, this comparison is challenging because protocol standards are typically written in natural language, whereas implementations are in source code. Existing methods like model checking, fuzzing, and differential testing have been used to find parsing bugs, but they either require significant manual effort or ignore the protocol standards, limiting their ability to detect semantic violations. To enable more automated validation of parser implementations against protocol standards, we propose PARVAL, a multi-agent framework built on large language models (LLMs). PARVAL leverages the capabilities of LLMs to understand both natural language and code. It transforms both protocol standards and their implementations into a unified intermediate representation, referred to as format specifications, and performs a differential comparison to uncover inconsistencies. We evaluate PARVAL on the Bidirectional Forwarding Detection (BFD) protocol. Our experiments demonstrate that PARVAL successfully identifies inconsistencies between the implementation and its RFC standard, achieving a low false positive rate of 5.6%. PARVAL uncovers seven unique bugs, including five previously unknown issues.
Perception-R1: Pioneering Perception Policy with Reinforcement Learning
Apr 10, 2025



Inspired by the success of DeepSeek-R1, we explore the potential of rule-based reinforcement learning (RL) in MLLM post-training for perception policy learning. While promising, our initial experiments reveal that incorporating a thinking process through RL does not consistently lead to performance gains across all visual perception tasks. This leads us to delve into the essential role of RL in the context of visual perception. In this work, we return to the fundamentals and explore the effects of RL on different perception tasks. We observe that the perceptual complexity is a major factor in determining the effectiveness of RL. We also observe that reward design plays a crucial role in further approching the upper limit of model perception. To leverage these findings, we propose Perception-R1, a scalable RL framework using GRPO during MLLM post-training. With a standard Qwen2.5-VL-3B-Instruct, Perception-R1 achieves +4.2% on RefCOCO+, +17.9% on PixMo-Count, +4.2% on PageOCR, and notably, 31.9% AP on COCO2017 val for the first time, establishing a strong baseline for perception policy learning.
Perception in Reflection
Apr 09, 2025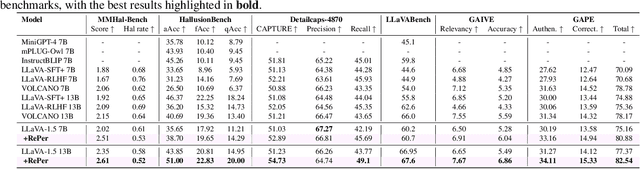


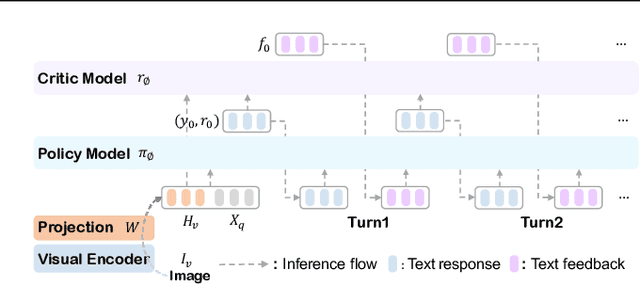
We present a perception in reflection paradigm designed to transcend the limitations of current large vision-language models (LVLMs), which are expected yet often fail to achieve perfect perception initially. Specifically, we propose Reflective Perception (RePer), a dual-model reflection mechanism that systematically alternates between policy and critic models, enables iterative refinement of visual perception. This framework is powered by Reflective Perceptual Learning (RPL), which reinforces intrinsic reflective capabilities through a methodically constructed visual reflection dataset and reflective unlikelihood training. Comprehensive experimental evaluation demonstrates RePer's quantifiable improvements in image understanding, captioning precision, and hallucination reduction. Notably, RePer achieves strong alignment between model attention patterns and human visual focus, while RPL optimizes fine-grained and free-form preference alignment. These advancements establish perception in reflection as a robust paradigm for future multimodal agents, particularly in tasks requiring complex reasoning and multi-step manipulation.
Efficient Dynamic Clustering-Based Document Compression for Retrieval-Augmented-Generation
Apr 04, 2025



Retrieval-Augmented Generation (RAG) has emerged as a widely adopted approach for knowledge integration during large language model (LLM) inference in recent years. However, current RAG implementations face challenges in effectively addressing noise, repetition and redundancy in retrieved content, primarily due to their limited ability to exploit fine-grained inter-document relationships. To address these limitations, we propose an \textbf{E}fficient \textbf{D}ynamic \textbf{C}lustering-based document \textbf{C}ompression framework (\textbf{EDC\textsuperscript{2}-RAG}) that effectively utilizes latent inter-document relationships while simultaneously removing irrelevant information and redundant content. We validate our approach, built upon GPT-3.5, on widely used knowledge-QA and hallucination-detected datasets. The results show that this method achieves consistent performance improvements across various scenarios and experimental settings, demonstrating strong robustness and applicability. Our code and datasets can be found at https://github.com/Tsinghua-dhy/EDC-2-RAG.
Ross3D: Reconstructive Visual Instruction Tuning with 3D-Awareness
Apr 02, 2025



The rapid development of Large Multimodal Models (LMMs) for 2D images and videos has spurred efforts to adapt these models for interpreting 3D scenes. However, the absence of large-scale 3D vision-language datasets has posed a significant obstacle. To address this issue, typical approaches focus on injecting 3D awareness into 2D LMMs by designing 3D input-level scene representations. This work provides a new perspective. We introduce reconstructive visual instruction tuning with 3D-awareness (Ross3D), which integrates 3D-aware visual supervision into the training procedure. Specifically, it incorporates cross-view and global-view reconstruction. The former requires reconstructing masked views by aggregating overlapping information from other views. The latter aims to aggregate information from all available views to recover Bird's-Eye-View images, contributing to a comprehensive overview of the entire scene. Empirically, Ross3D achieves state-of-the-art performance across various 3D scene understanding benchmarks. More importantly, our semi-supervised experiments demonstrate significant potential in leveraging large amounts of unlabeled 3D vision-only data.
$μ$KE: Matryoshka Unstructured Knowledge Editing of Large Language Models
Apr 01, 2025



Large language models (LLMs) have emerged as powerful knowledge bases yet are limited by static training data, leading to issues such as hallucinations and safety risks. Editing a model's internal knowledge through the locate-and-edit paradigm has proven a cost-effective alternative to retraining, though current unstructured approaches, especially window-based autoregressive methods, often disrupt the causal dependency between early memory updates and later output tokens. In this work, we first theoretically analyze these limitations and then introduce Matryoshka Unstructured Knowledge Editing ($\mu$KE), a novel memory update mechanism that preserves such dependencies via a Matryoshka-style objective and adaptive loss coefficients. Empirical evaluations on two models across four benchmarks demonstrate that $\mu$KE improves edit efficacy by up to 12.33% over state-of-the-art methods, and remain robust when applied to diverse formatted edits, underscoring its potential for effective unstructured knowledge editing in LLMs.
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Mar 31, 2025



We introduce Open-Reasoner-Zero, the first open source implementation of large-scale reasoning-oriented RL training focusing on scalability, simplicity and accessibility. Through extensive experiments, we demonstrate that a minimalist approach, vanilla PPO with GAE ($\lambda=1$, $\gamma=1$) and straightforward rule-based rewards, without any KL regularization, is sufficient to scale up both response length and benchmark performance, similar to the phenomenon observed in DeepSeek-R1-Zero. Using the same base model as DeepSeek-R1-Zero-Qwen-32B, our implementation achieves superior performance on AIME2024, MATH500, and the GPQA Diamond benchmark while demonstrating remarkable efficiency -- requiring only a tenth of the training steps, compared to DeepSeek-R1-Zero pipeline. In the spirit of open source, we release our source code, parameter settings, training data, and model weights across various sizes.
M-DocSum: Do LVLMs Genuinely Comprehend Interleaved Image-Text in Document Summarization?
Mar 27, 2025



We investigate a critical yet under-explored question in Large Vision-Language Models (LVLMs): Do LVLMs genuinely comprehend interleaved image-text in the document? Existing document understanding benchmarks often assess LVLMs using question-answer formats, which are information-sparse and difficult to guarantee the coverage of long-range dependencies. To address this issue, we introduce a novel and challenging Multimodal Document Summarization Benchmark (M-DocSum-Bench), which comprises 500 high-quality arXiv papers, along with interleaved multimodal summaries aligned with human preferences. M-DocSum-Bench is a reference-based generation task and necessitates the generation of interleaved image-text summaries using provided reference images, thereby simultaneously evaluating capabilities in understanding, reasoning, localization, and summarization within complex multimodal document scenarios. To facilitate this benchmark, we develop an automated framework to construct summaries and propose a fine-grained evaluation method called M-DocEval. Moreover, we further develop a robust summarization baseline, i.e., M-DocSum-7B, by progressive two-stage training with diverse instruction and preference data. The extensive results on our M-DocSum-Bench reveal that the leading LVLMs struggle to maintain coherence and accurately integrate information within long and interleaved contexts, often exhibiting confusion between similar images and a lack of robustness. Notably, M-DocSum-7B achieves state-of-the-art performance compared to larger and closed-source models (including GPT-4o, Gemini Pro, Claude-3.5-Sonnet and Qwen2.5-VL-72B, etc.), demonstrating the potential of LVLMs for improved interleaved image-text understanding. The code, data, and models are available at https://github.com/stepfun-ai/M-DocSum-Bench.