 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoSense: Evaluating Identification and Application of Geometric Principles in Multimodal Reasoning
Apr 17, 2025



Geometry problem-solving (GPS), a challenging task requiring both visual comprehension and symbolic reasoning, effectively measures the reasoning capabilities of multimodal large language models (MLLMs). Humans exhibit strong reasoning ability in this task through accurate identification and adaptive application of geometric principles within visual contexts. However, existing benchmarks fail to jointly assess both dimensions of the human-like geometric reasoning mechanism in MLLMs, remaining a critical gap in assessing their ability to tackle GPS. To this end, we introduce GeoSense, the first comprehensive bilingual benchmark designed to systematically evaluate the geometric reasoning abilities of MLLMs through the lens of geometric principles. GeoSense features a five-level hierarchical framework of geometric principles spanning plane and solid geometry, an intricately annotated dataset of 1,789 problems, and an innovative evaluation strategy. Through extensive experiments on GeoSense with various open-source and closed-source MLLMs, we observe that Gemini-2.0-pro-flash performs best, achieving an overall score of $65.3$. Our in-depth analysis reveals that the identification and application of geometric principles remain a bottleneck for leading MLLMs, jointly hindering their reasoning abilities. These findings underscore GeoSense's potential to guide future advancements in MLLMs' geometric reasoning capabilities, paving the way for more robust and human-like reasoning in artificial intelligence.
FairACE: Achieving Degree Fairness in Graph Neural Networks via Contrastive and Adversarial Group-Balanced Training
Apr 15, 2025Fairness has been a significant challenge in graph neural networks (GNNs) since degree biases often result in un-equal prediction performance among nodes with varying degrees. Existing GNN models focus on prediction accuracy, frequently overlooking fairness across different degree groups. To addressthis issue, we propose a novel GNN framework, namely Fairness- Aware Asymmetric Contrastive Ensemble (FairACE), which inte-grates asymmetric contrastive learning with adversarial training to improve degree fairness. FairACE captures one-hop local neighborhood information and two-hop monophily similarity to create fairer node representations and employs a degree fairness regulator to balance performance between high-degree and low-degree nodes. During model training, a novel group-balanced fairness loss is proposed to minimize classification disparities across degree groups. In addition, we also propose a novel fairness metric, the Accuracy Distribution Gap (ADG), which can quantitatively assess and ensure equitable performance across different degree-based node groups. Experimental results on both synthetic and real-world datasets demonstrate that FairACE significantly improves degree fairness metrics while maintaining competitive accuracy in comparison to the state-of-the-art GNN models.
Explicit Uncertainty Modeling for Video Watch Time Prediction
Apr 10, 2025In video recommendation, a critical component that determines the system's recommendation accuracy is the watch-time prediction module, since how long a user watches a video directly reflects personalized preferences. One of the key challenges of this problem is the user's stochastic watch-time behavior. To improve the prediction accuracy for such an uncertain behavior, existing approaches show that one can either reduce the noise through duration bias modeling or formulate a distribution modeling task to capture the uncertainty. However, the uncontrolled uncertainty is not always equally distributed across users and videos, inducing a balancing paradox between the model accuracy and the ability to capture out-of-distribution samples. In practice, we find that the uncertainty of the watch-time prediction model also provides key information about user behavior, which, in turn, could benefit the prediction task itself. Following this notion, we derive an explicit uncertainty modeling strategy for the prediction model and propose an adversarial optimization framework that can better exploit the user watch-time behavior. This framework has been deployed online on an industrial video sharing platform that serves hundreds of millions of daily active users, which obtains a significant increase in users' video watch time by 0.31% through the online A/B test. Furthermore, extended offline experiments on two public datasets verify the effectiveness of the proposed framework across various watch-time prediction backbones.
MRD-RAG: Enhancing Medical Diagnosis with Multi-Round Retrieval-Augmented Generation
Apr 10, 2025In recent years, accurately and quickly deploying medical large language models (LLMs) has become a significant trend. Among these, retrieval-augmented generation (RAG) has garnered significant attention due to its features of rapid deployment and privacy protection. However, existing medical RAG frameworks still have shortcomings. Most existing medical RAG frameworks are designed for single-round question answering tasks and are not suitable for multi-round diagnostic dialogue. On the other hand, existing medical multi-round RAG frameworks do not consider the interconnections between potential diseases to inquire precisely like a doctor. To address these issues, we propose a Multi-Round Diagnostic RAG (MRD-RAG) framework that mimics the doctor's diagnostic process. This RAG framework can analyze diagnosis information of potential diseases and accurately conduct multi-round diagnosis like a doctor. To evaluate the effectiveness of our proposed frameworks, we conduct experiments on two modern medical datasets and two traditional Chinese medicine datasets, with evaluations by GPT and human doctors on different methods. The results indicate that our RAG framework can significantly enhance the diagnostic performance of LLMs, highlighting the potential of our approach in medical diagnosis. The code and data can be found in our project website https://github.com/YixiangCh/MRD-RAG/tree/master.
RS-RAG: Bridging Remote Sensing Imagery and Comprehensive Knowledge with a Multi-Modal Dataset and Retrieval-Augmented Generation Model
Apr 07, 2025



Recent progress in VLMs has demonstrated impressive capabilities across a variety of tasks in the natural image domain. Motivated by these advancements, the remote sensing community has begun to adopt VLMs for remote sensing vision-language tasks, including scene understanding, image captioning, and visual question answering. However, existing remote sensing VLMs typically rely on closed-set scene understanding and focus on generic scene descriptions, yet lack the ability to incorporate external knowledge. This limitation hinders their capacity for semantic reasoning over complex or context-dependent queries that involve domain-specific or world knowledge. To address these challenges, we first introduced a multimodal Remote Sensing World Knowledge (RSWK) dataset, which comprises high-resolution satellite imagery and detailed textual descriptions for 14,141 well-known landmarks from 175 countries, integrating both remote sensing domain knowledge and broader world knowledge. Building upon this dataset, we proposed a novel Remote Sensing Retrieval-Augmented Generation (RS-RAG) framework, which consists of two key components. The Multi-Modal Knowledge Vector Database Construction module encodes remote sensing imagery and associated textual knowledge into a unified vector space. The Knowledge Retrieval and Response Generation module retrieves and re-ranks relevant knowledge based on image and/or text queries, and incorporates the retrieved content into a knowledge-augmented prompt to guide the VLM in producing contextually grounded responses. We validated the effectiveness of our approach on three representative vision-language tasks, including image captioning, image classification, and visual question answering, where RS-RAG significantly outperformed state-of-the-art baselines.
Towards deployment-centric multimodal AI beyond vision and language
Apr 04, 2025Multimodal artificial intelligence (AI) integrates diverse types of data via machine learning to improve understanding, prediction, and decision-making across disciplines such as healthcare, science, and engineering. However, most multimodal AI advances focus on models for vision and language data, while their deployability remains a key challenge. We advocate a deployment-centric workflow that incorporates deployment constraints early to reduce the likelihood of undeployable solutions, complementing data-centric and model-centric approaches. We also emphasise deeper integration across multiple levels of multimodality and multidisciplinary collaboration to significantly broaden the research scope beyond vision and language. To facilitate this approach, we identify common multimodal-AI-specific challenges shared across disciplines and examine three real-world use cases: pandemic response, self-driving car design, and climate change adaptation, drawing expertise from healthcare, social science, engineering, science, sustainability, and finance. By fostering multidisciplinary dialogue and open research practices, our community can accelerate deployment-centric development for broad societal impact.
AI-Newton: A Concept-Driven Physical Law Discovery System without Prior Physical Knowledge
Apr 02, 2025Current limitations in human scientific discovery necessitate a new research paradigm. While advances in artificial intelligence (AI) offer a highly promising solution, enabling AI to emulate human-like scientific discovery remains an open challenge. To address this, we propose AI-Newton, a concept-driven discovery system capable of autonomously deriving physical laws from raw data -- without supervision or prior physical knowledge. The system integrates a knowledge base and knowledge representation centered on physical concepts, along with an autonomous discovery workflow. As a proof of concept, we apply AI-Newton to a large set of Newtonian mechanics problems. Given experimental data with noise, the system successfully rediscovers fundamental laws, including Newton's second law, energy conservation and law of gravitation, using autonomously defined concepts. This achievement marks a significant step toward AI-driven autonomous scientific discovery.
Fourier Feature Attribution: A New Efficiency Attribution Method
Apr 02, 2025


The study of neural networks from the perspective of Fourier features has garnered significant attention. While existing analytical research suggests that neural networks tend to learn low-frequency features, a clear attribution method for identifying the specific learned Fourier features has remained elusive. To bridge this gap, we propose a novel Fourier feature attribution method grounded in signal decomposition theory. Additionally, we analyze the differences between game-theoretic attribution metrics for Fourier and spatial domain features, demonstrating that game-theoretic evaluation metrics are better suited for Fourier-based feature attribution. Our experiments show that Fourier feature attribution exhibits superior feature selection capabilities compared to spatial domain attribution methods. For instance, in the case of Vision Transformers (ViTs) on the ImageNet dataset, only $8\%$ of the Fourier features are required to maintain the original predictions for $80\%$ of the samples. Furthermore, we compare the specificity of features identified by our method against traditional spatial domain attribution methods. Results reveal that Fourier features exhibit greater intra-class concentration and inter-class distinctiveness, indicating their potential for more efficient classification and explainable AI algorithms.
MedReason: Eliciting Factual Medical Reasoning Steps in LLMs via Knowledge Graphs
Apr 01, 2025

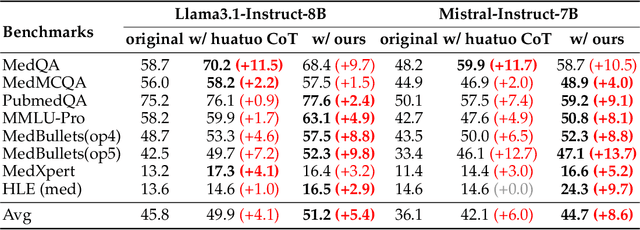
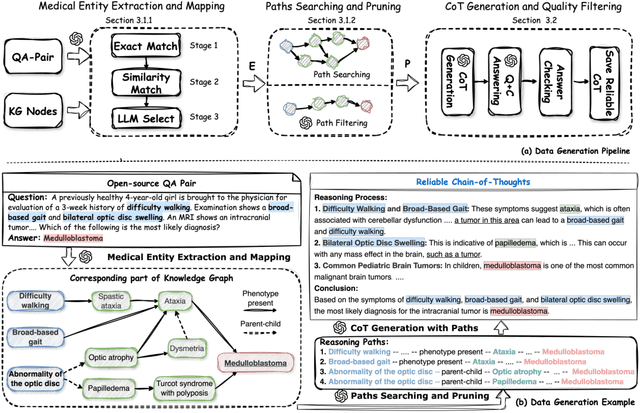
Medical tasks such as diagnosis and treatment planning require precise and complex reasoning, particularly in life-critical domains. Unlike mathematical reasoning, medical reasoning demands meticulous, verifiable thought processes to ensure reliability and accuracy. However, there is a notable lack of datasets that provide transparent, step-by-step reasoning to validate and enhance the medical reasoning ability of AI models. To bridge this gap, we introduce MedReason, a large-scale high-quality medical reasoning dataset designed to enable faithful and explainable medical problem-solving in large language models (LLMs). We utilize a structured medical knowledge graph (KG) to convert clinical QA pairs into logical chains of reasoning, or ``thinking paths'', which trace connections from question elements to answers via relevant KG entities. Each path is validated for consistency with clinical logic and evidence-based medicine. Our pipeline generates detailed reasoning for various medical questions from 7 medical datasets, resulting in a dataset of 32,682 question-answer pairs, each with detailed, step-by-step explanations. Experiments demonstrate that fine-tuning with our dataset consistently boosts medical problem-solving capabilities, achieving significant gains of up to 7.7% for DeepSeek-Ditill-8B. Our top-performing model, MedReason-8B, outperforms the Huatuo-o1-8B, a state-of-the-art medical reasoning model, by up to 4.2% on the clinical benchmark MedBullets. We also engage medical professionals from diverse specialties to assess our dataset's quality, ensuring MedReason offers accurate and coherent medical reasoning. Our data, models, and code will be publicly available.
Science Autonomy using Machine Learning for Astrobiology
Apr 01, 2025In recent decades, artificial intelligence (AI) including machine learning (ML) have become vital for space missions enabling rapid data processing, advanced pattern recognition, and enhanced insight extraction. These tools are especially valuable in astrobiology applications, where models must distinguish biotic patterns from complex abiotic backgrounds. Advancing the integration of autonomy through AI and ML into space missions is a complex challenge, and we believe that by focusing on key areas, we can make significant progress and offer practical recommendations for tackling these obstacles.