 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWithAnyone: Towards Controllable and ID Consistent Image Generation
Oct 16, 2025Identity-consistent generation has become an important focus in text-to-image research, with recent models achieving notable success in producing images aligned with a reference identity. Yet, the scarcity of large-scale paired datasets containing multiple images of the same individual forces most approaches to adopt reconstruction-based training. This reliance often leads to a failure mode we term copy-paste, where the model directly replicates the reference face rather than preserving identity across natural variations in pose, expression, or lighting. Such over-similarity undermines controllability and limits the expressive power of generation. To address these limitations, we (1) construct a large-scale paired dataset MultiID-2M, tailored for multi-person scenarios, providing diverse references for each identity; (2) introduce a benchmark that quantifies both copy-paste artifacts and the trade-off between identity fidelity and variation; and (3) propose a novel training paradigm with a contrastive identity loss that leverages paired data to balance fidelity with diversity. These contributions culminate in WithAnyone, a diffusion-based model that effectively mitigates copy-paste while preserving high identity similarity. Extensive qualitative and quantitative experiments demonstrate that WithAnyone significantly reduces copy-paste artifacts, improves controllability over pose and expression, and maintains strong perceptual quality. User studies further validate that our method achieves high identity fidelity while enabling expressive controllable generation.
SC-Captioner: Improving Image Captioning with Self-Correction by Reinforcement Learning
Aug 08, 2025We propose SC-Captioner, a reinforcement learning framework that enables the self-correcting capability of image caption models. Our crucial technique lies in the design of the reward function to incentivize accurate caption corrections. Specifically, the predicted and reference captions are decomposed into object, attribute, and relation sets using scene-graph parsing algorithms. We calculate the set difference between sets of initial and self-corrected captions to identify added and removed elements. These elements are matched against the reference sets to calculate correctness bonuses for accurate refinements and mistake punishments for wrong additions and removals, thereby forming the final reward. For image caption quality assessment, we propose a set of metrics refined from CAPTURE that alleviate its incomplete precision evaluation and inefficient relation matching problems. Furthermore, we collect a fine-grained annotated image caption dataset, RefinedCaps, consisting of 6.5K diverse images from COCO dataset. Experiments show that applying SC-Captioner on large visual-language models can generate better image captions across various scenarios, significantly outperforming the direct preference optimization training strategy.
OneIG-Bench: Omni-dimensional Nuanced Evaluation for Image Generation
Jun 09, 2025Text-to-image (T2I) models have garnered significant attention for generating high-quality images aligned with text prompts. However, rapid T2I model advancements reveal limitations in early benchmarks, lacking comprehensive evaluations, for example, the evaluation on reasoning, text rendering and style. Notably, recent state-of-the-art models, with their rich knowledge modeling capabilities, show promising results on the image generation problems requiring strong reasoning ability, yet existing evaluation systems have not adequately addressed this frontier. To systematically address these gaps, we introduce OneIG-Bench, a meticulously designed comprehensive benchmark framework for fine-grained evaluation of T2I models across multiple dimensions, including prompt-image alignment, text rendering precision, reasoning-generated content, stylization, and diversity. By structuring the evaluation, this benchmark enables in-depth analysis of model performance, helping researchers and practitioners pinpoint strengths and bottlenecks in the full pipeline of image generation. Specifically, OneIG-Bench enables flexible evaluation by allowing users to focus on a particular evaluation subset. Instead of generating images for the entire set of prompts, users can generate images only for the prompts associated with the selected dimension and complete the corresponding evaluation accordingly. Our codebase and dataset are now publicly available to facilitate reproducible evaluation studies and cross-model comparisons within the T2I research community.
DreamDance: Animating Character Art via Inpainting Stable Gaussian Worlds
May 30, 2025



This paper presents DreamDance, a novel character art animation framework capable of producing stable, consistent character and scene motion conditioned on precise camera trajectories. To achieve this, we re-formulate the animation task as two inpainting-based steps: Camera-aware Scene Inpainting and Pose-aware Video Inpainting. The first step leverages a pre-trained image inpainting model to generate multi-view scene images from the reference art and optimizes a stable large-scale Gaussian field, which enables coarse background video rendering with camera trajectories. However, the rendered video is rough and only conveys scene motion. To resolve this, the second step trains a pose-aware video inpainting model that injects the dynamic character into the scene video while enhancing background quality. Specifically, this model is a DiT-based video generation model with a gating strategy that adaptively integrates the character's appearance and pose information into the base background video. Through extensive experiments, we demonstrate the effectiveness and generalizability of DreamDance, producing high-quality and consistent character animations with remarkable camera dynamics.
ViStoryBench: Comprehensive Benchmark Suite for Story Visualization
May 30, 2025Story visualization, which aims to generate a sequence of visually coherent images aligning with a given narrative and reference images, has seen significant progress with recent advancements in generative models. To further enhance the performance of story visualization frameworks in real-world scenarios, we introduce a comprehensive evaluation benchmark, ViStoryBench. We collect a diverse dataset encompassing various story types and artistic styles, ensuring models are evaluated across multiple dimensions such as different plots (e.g., comedy, horror) and visual aesthetics (e.g., anime, 3D renderings). ViStoryBench is carefully curated to balance narrative structures and visual elements, featuring stories with single and multiple protagonists to test models' ability to maintain character consistency. Additionally, it includes complex plots and intricate world-building to challenge models in generating accurate visuals. To ensure comprehensive comparisons, our benchmark incorporates a wide range of evaluation metrics assessing critical aspects. This structured and multifaceted framework enables researchers to thoroughly identify both the strengths and weaknesses of different models, fostering targeted improvements.
KRIS-Bench: Benchmarking Next-Level Intelligent Image Editing Models
May 22, 2025Recent advances in multi-modal generative models have enabled significant progress in instruction-based image editing. However, while these models produce visually plausible outputs, their capacity for knowledge-based reasoning editing tasks remains under-explored. In this paper, we introduce KRIS-Bench (Knowledge-based Reasoning in Image-editing Systems Benchmark), a diagnostic benchmark designed to assess models through a cognitively informed lens. Drawing from educational theory, KRIS-Bench categorizes editing tasks across three foundational knowledge types: Factual, Conceptual, and Procedural. Based on this taxonomy, we design 22 representative tasks spanning 7 reasoning dimensions and release 1,267 high-quality annotated editing instances. To support fine-grained evaluation, we propose a comprehensive protocol that incorporates a novel Knowledge Plausibility metric, enhanced by knowledge hints and calibrated through human studies. Empirical results on 10 state-of-the-art models reveal significant gaps in reasoning performance, highlighting the need for knowledge-centric benchmarks to advance the development of intelligent image editing systems.
Step1X-Edit: A Practical Framework for General Image Editing
Apr 24, 2025In recent years, image editing models have witnessed remarkable and rapid development. The recent unveiling of cutting-edge multimodal models such as GPT-4o and Gemini2 Flash has introduced highly promising image editing capabilities. These models demonstrate an impressive aptitude for fulfilling a vast majority of user-driven editing requirements, marking a significant advancement in the field of image manipulation. However, there is still a large gap between the open-source algorithm with these closed-source models. Thus, in this paper, we aim to release a state-of-the-art image editing model, called Step1X-Edit, which can provide comparable performance against the closed-source models like GPT-4o and Gemini2 Flash. More specifically, we adopt the Multimodal LLM to process the reference image and the user's editing instruction. A latent embedding has been extracted and integrated with a diffusion image decoder to obtain the target image. To train the model, we build a data generation pipeline to produce a high-quality dataset. For evaluation, we develop the GEdit-Bench, a novel benchmark rooted in real-world user instructions. Experimental results on GEdit-Bench demonstrate that Step1X-Edit outperforms existing open-source baselines by a substantial margin and approaches the performance of leading proprietary models, thereby making significant contributions to the field of image editing.
StyleMe3D: Stylization with Disentangled Priors by Multiple Encoders on 3D Gaussians
Apr 21, 20253D Gaussian Splatting (3DGS) excels in photorealistic scene reconstruction but struggles with stylized scenarios (e.g., cartoons, games) due to fragmented textures, semantic misalignment, and limited adaptability to abstract aesthetics. We propose StyleMe3D, a holistic framework for 3D GS style transfer that integrates multi-modal style conditioning, multi-level semantic alignment, and perceptual quality enhancement. Our key insights include: (1) optimizing only RGB attributes preserves geometric integrity during stylization; (2) disentangling low-, medium-, and high-level semantics is critical for coherent style transfer; (3) scalability across isolated objects and complex scenes is essential for practical deployment. StyleMe3D introduces four novel components: Dynamic Style Score Distillation (DSSD), leveraging Stable Diffusion's latent space for semantic alignment; Contrastive Style Descriptor (CSD) for localized, content-aware texture transfer; Simultaneously Optimized Scale (SOS) to decouple style details and structural coherence; and 3D Gaussian Quality Assessment (3DG-QA), a differentiable aesthetic prior trained on human-rated data to suppress artifacts and enhance visual harmony. Evaluated on NeRF synthetic dataset (objects) and tandt db (scenes) datasets, StyleMe3D outperforms state-of-the-art methods in preserving geometric details (e.g., carvings on sculptures) and ensuring stylistic consistency across scenes (e.g., coherent lighting in landscapes), while maintaining real-time rendering. This work bridges photorealistic 3D GS and artistic stylization, unlocking applications in gaming, virtual worlds, and digital art.
OmniSVG: A Unified Scalable Vector Graphics Generation Model
Apr 08, 2025
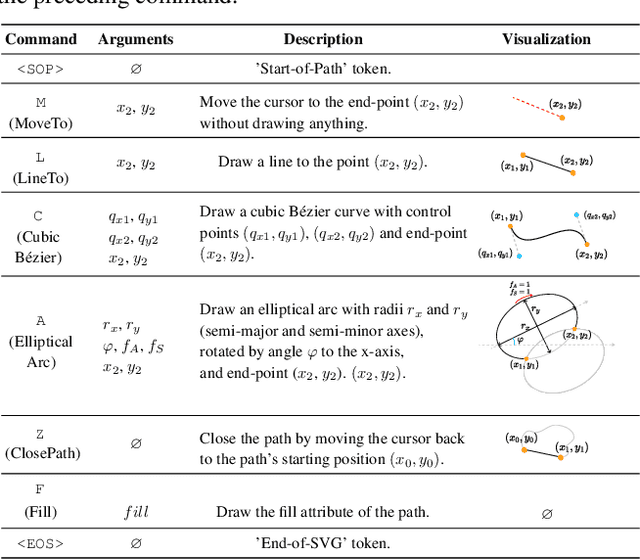


Scalable Vector Graphics (SVG) is an important image format widely adopted in graphic design because of their resolution independence and editability. The study of generating high-quality SVG has continuously drawn attention from both designers and researchers in the AIGC community. However, existing methods either produces unstructured outputs with huge computational cost or is limited to generating monochrome icons of over-simplified structures. To produce high-quality and complex SVG, we propose OmniSVG, a unified framework that leverages pre-trained Vision-Language Models (VLMs) for end-to-end multimodal SVG generation. By parameterizing SVG commands and coordinates into discrete tokens, OmniSVG decouples structural logic from low-level geometry for efficient training while maintaining the expressiveness of complex SVG structure. To further advance the development of SVG synthesis, we introduce MMSVG-2M, a multimodal dataset with two million richly annotated SVG assets, along with a standardized evaluation protocol for conditional SVG generation tasks. Extensive experiments show that OmniSVG outperforms existing methods and demonstrates its potential for integration into professional SVG design workflows.
FAVOR-Bench: A Comprehensive Benchmark for Fine-Grained Video Motion Understanding
Mar 19, 2025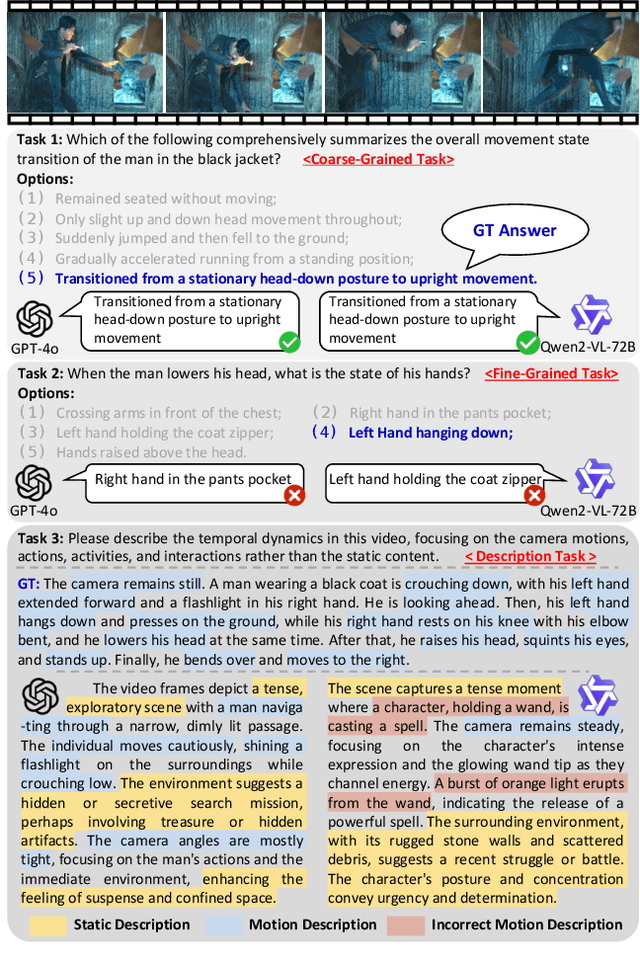

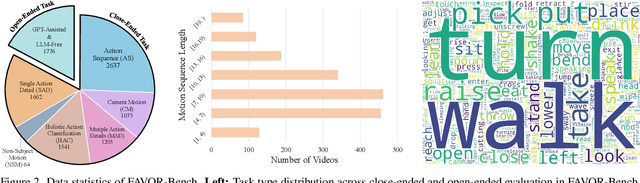
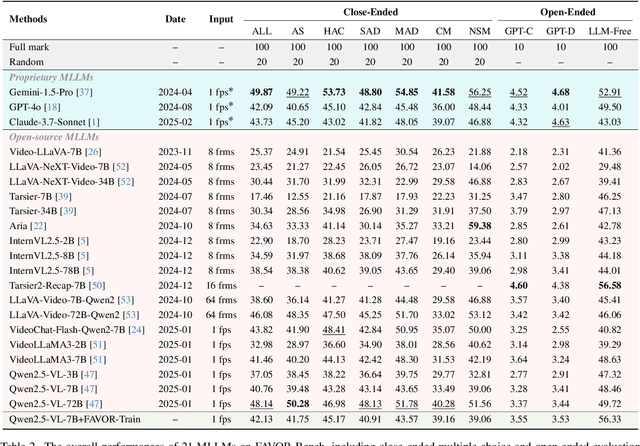
Multimodal Large Language Models (MLLMs) have shown remarkable capabilities in video content understanding but still struggle with fine-grained motion comprehension. To comprehensively assess the motion understanding ability of existing MLLMs, we introduce FAVOR-Bench, comprising 1,776 videos with structured manual annotations of various motions. Our benchmark includes both close-ended and open-ended tasks. For close-ended evaluation, we carefully design 8,184 multiple-choice question-answer pairs spanning six distinct sub-tasks. For open-ended evaluation, we develop both a novel cost-efficient LLM-free and a GPT-assisted caption assessment method, where the former can enhance benchmarking interpretability and reproducibility. Comprehensive experiments with 21 state-of-the-art MLLMs reveal significant limitations in their ability to comprehend and describe detailed temporal dynamics in video motions. To alleviate this limitation, we further build FAVOR-Train, a dataset consisting of 17,152 videos with fine-grained motion annotations. The results of finetuning Qwen2.5-VL on FAVOR-Train yield consistent improvements on motion-related tasks of TVBench, MotionBench and our FAVOR-Bench. Comprehensive assessment results demonstrate that the proposed FAVOR-Bench and FAVOR-Train provide valuable tools to the community for developing more powerful video understanding models. Project page: \href{https://favor-bench.github.io/}{https://favor-bench.github.io/}.