 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining in Style: Training a GAN to explain a classifier in StyleSpace
Apr 27, 2021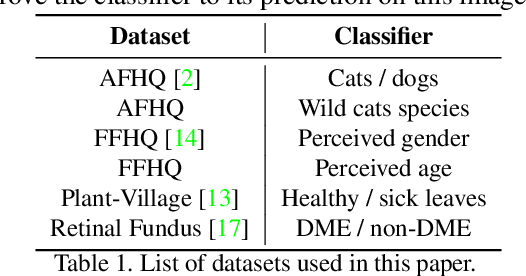
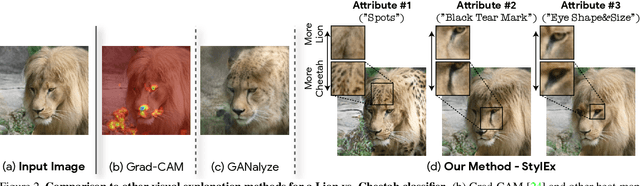
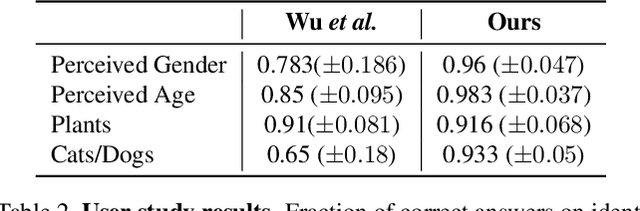
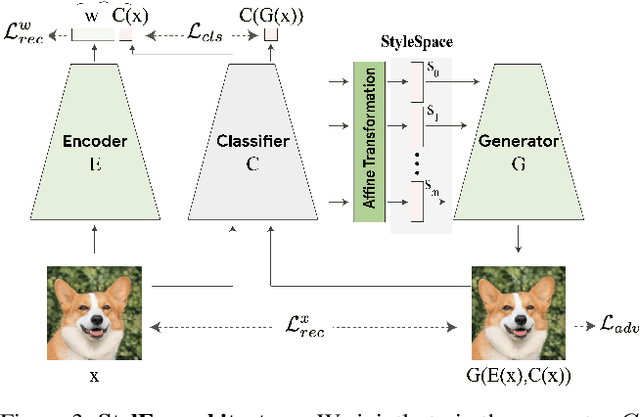
Image classification models can depend on multiple different semantic attributes of the image. An explanation of the decision of the classifier needs to both discover and visualize these properties. Here we present StylEx, a method for doing this, by training a generative model to specifically explain multiple attributes that underlie classifier decisions. A natural source for such attributes is the StyleSpace of StyleGAN, which is known to generate semantically meaningful dimensions in the image. However, because standard GAN training is not dependent on the classifier, it may not represent these attributes which are important for the classifier decision, and the dimensions of StyleSpace may represent irrelevant attributes. To overcome this, we propose a training procedure for a StyleGAN, which incorporates the classifier model, in order to learn a classifier-specific StyleSpace. Explanatory attributes are then selected from this space. These can be used to visualize the effect of changing multiple attributes per image, thus providing image-specific explanations. We apply StylEx to multiple domains, including animals, leaves, faces and retinal images. For these, we show how an image can be modified in different ways to change its classifier output. Our results show that the method finds attributes that align well with semantic ones, generate meaningful image-specific explanations, and are human-interpretable as measured in user-studies.
Model-Agnostic Explainability for Visual Search
Feb 28, 2021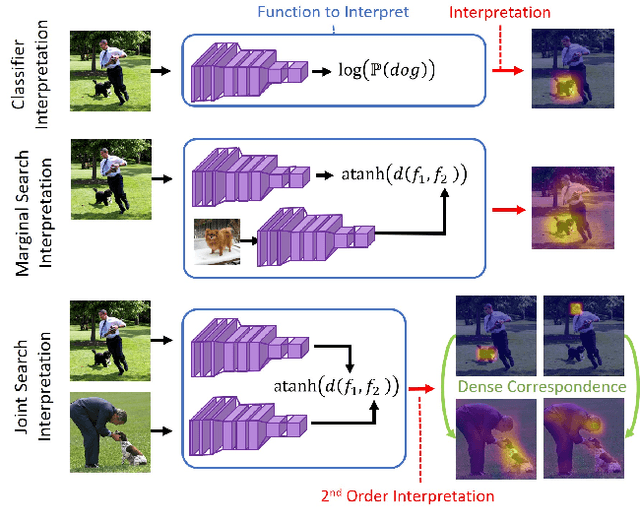
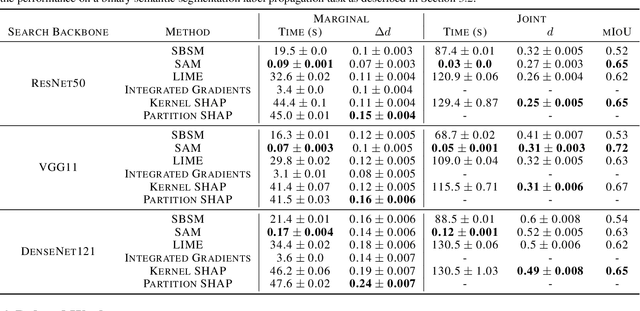


What makes two images similar? We propose new approaches to generate model-agnostic explanations for image similarity, search, and retrieval. In particular, we extend Class Activation Maps (CAMs), Additive Shapley Explanations (SHAP), and Locally Interpretable Model-Agnostic Explanations (LIME) to the domain of image retrieval and search. These approaches enable black and grey-box model introspection and can help diagnose errors and understand the rationale behind a model's similarity judgments. Furthermore, we extend these approaches to extract a full pairwise correspondence between the query and retrieved image pixels, an approach we call "joint interpretations". Formally, we show joint search interpretations arise from projecting Harsanyi dividends, and that this approach generalizes Shapley Values and The Shapley-Taylor indices. We introduce a fast kernel-based method for estimating Shapley-Taylor indices and empirically show that these game-theoretic measures yield more consistent explanations for image similarity architectures.
Multi-Plane Program Induction with 3D Box Priors
Nov 22, 2020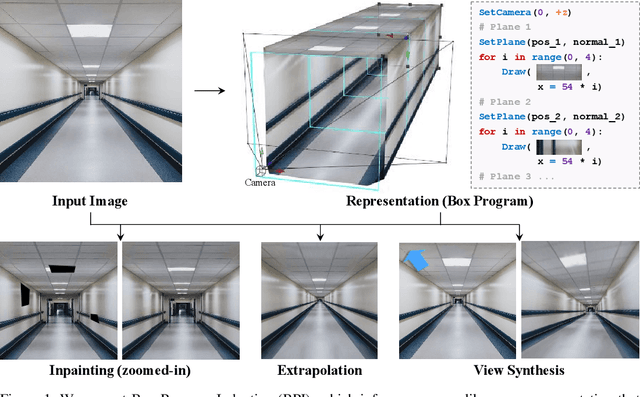


We consider two important aspects in understanding and editing images: modeling regular, program-like texture or patterns in 2D planes, and 3D posing of these planes in the scene. Unlike prior work on image-based program synthesis, which assumes the image contains a single visible 2D plane, we present Box Program Induction (BPI), which infers a program-like scene representation that simultaneously models repeated structure on multiple 2D planes, the 3D position and orientation of the planes, and camera parameters, all from a single image. Our model assumes a box prior, i.e., that the image captures either an inner view or an outer view of a box in 3D. It uses neural networks to infer visual cues such as vanishing points, wireframe lines to guide a search-based algorithm to find the program that best explains the image. Such a holistic, structured scene representation enables 3D-aware interactive image editing operations such as inpainting missing pixels, changing camera parameters, and extrapolate the image contents.
Large-Scale Intelligent Microservices
Sep 17, 2020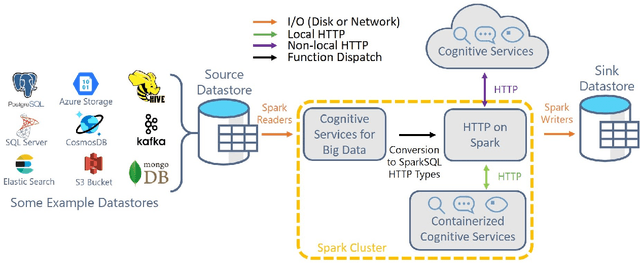
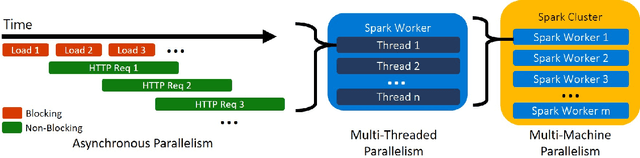
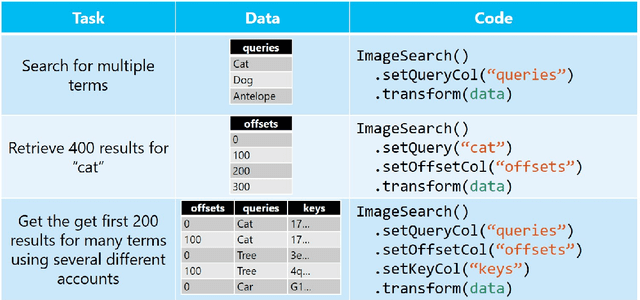
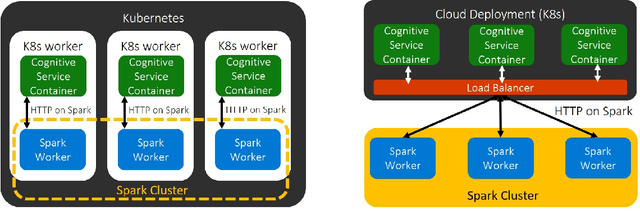
Deploying Machine Learning (ML) algorithms within databases is a challenge due to the varied computational footprints of modern ML algorithms and the myriad of database technologies each with their own restrictive syntax. We introduce an Apache Spark-based micro-service orchestration framework that extends database operations to include web service primitives. Our system can orchestrate web services across hundreds of machines and takes full advantage of cluster, thread, and asynchronous parallelism. Using this framework, we provide large scale clients for intelligent services such as speech, vision, search, anomaly detection, and text analysis. This allows users to integrate ready-to-use intelligence into any datastore with an Apache Spark connector. To eliminate the majority of overhead from network communication, we also introduce a low-latency containerized version of our architecture. Finally, we demonstrate that the services we investigate are competitive on a variety of benchmarks, and present two applications of this framework to create intelligent search engines, and real time auto race analytics systems.
Layered Neural Rendering for Retiming People in Video
Sep 16, 2020
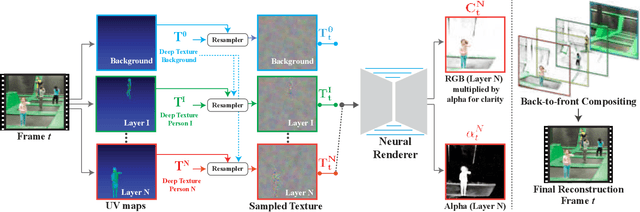

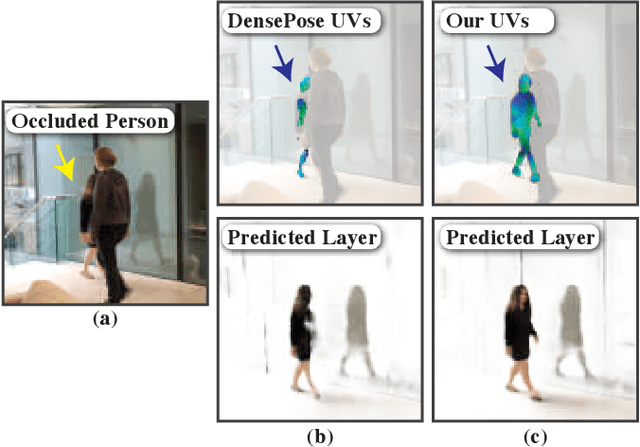
We present a method for retiming people in an ordinary, natural video---manipulating and editing the time in which different motions of individuals in the video occur. We can temporally align different motions, change the speed of certain actions (speeding up/slowing down, or entirely "freezing" people), or "erase" selected people from the video altogether. We achieve these effects computationally via a dedicated learning-based layered video representation, where each frame in the video is decomposed into separate RGBA layers, representing the appearance of different people in the video. A key property of our model is that it not only disentangles the direct motions of each person in the input video, but also correlates each person automatically with the scene changes they generate---e.g., shadows, reflections, and motion of loose clothing. The layers can be individually retimed and recombined into a new video, allowing us to achieve realistic, high-quality renderings of retiming effects for real-world videos depicting complex actions and involving multiple individuals, including dancing, trampoline jumping, or group running.
Neural Light Transport for Relighting and View Synthesis
Aug 20, 2020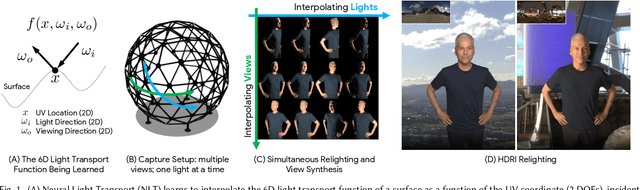

The light transport (LT) of a scene describes how it appears under different lighting and viewing directions, and complete knowledge of a scene's LT enables the synthesis of novel views under arbitrary lighting. In this paper, we focus on image-based LT acquisition, primarily for human bodies within a light stage setup. We propose a semi-parametric approach to learn a neural representation of LT that is embedded in the space of a texture atlas of known geometric properties, and model all non-diffuse and global LT as residuals added to a physically-accurate diffuse base rendering. In particular, we show how to fuse previously seen observations of illuminants and views to synthesize a new image of the same scene under a desired lighting condition from a chosen viewpoint. This strategy allows the network to learn complex material effects (such as subsurface scattering) and global illumination, while guaranteeing the physical correctness of the diffuse LT (such as hard shadows). With this learned LT, one can relight the scene photorealistically with a directional light or an HDRI map, synthesize novel views with view-dependent effects, or do both simultaneously, all in a unified framework using a set of sparse, previously seen observations. Qualitative and quantitative experiments demonstrate that our neural LT (NLT) outperforms state-of-the-art solutions for relighting and view synthesis, without separate treatment for both problems that prior work requires.
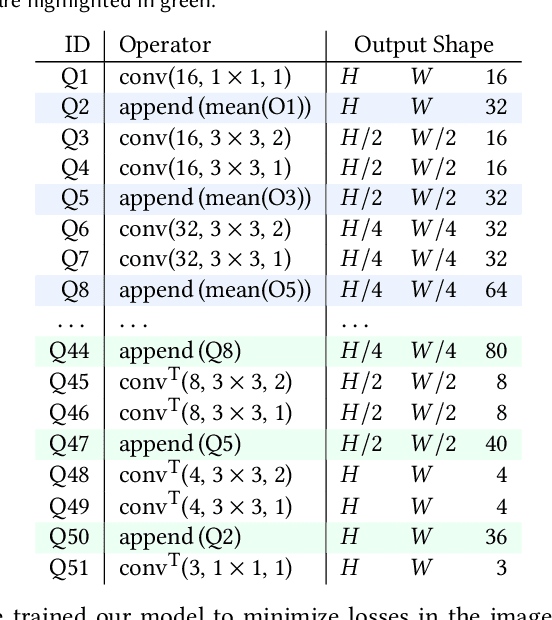
Neural Descent for Visual 3D Human Pose and Shape
Aug 16, 2020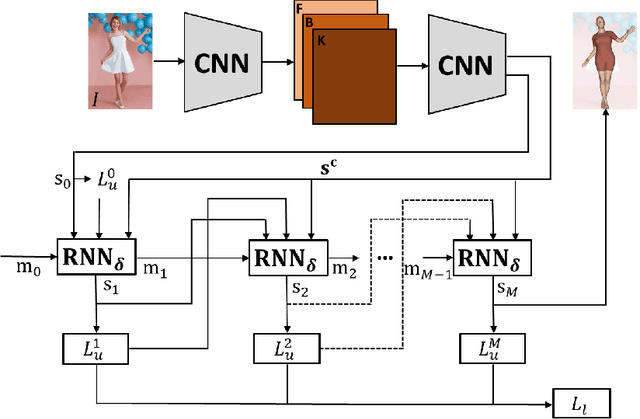
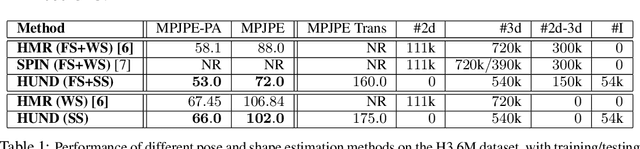

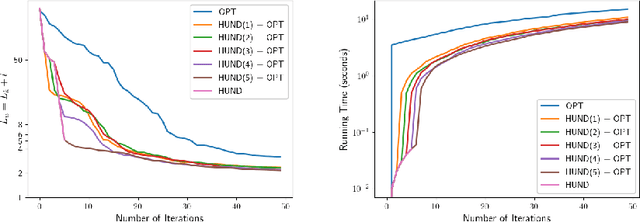
We present deep neural network methodology to reconstruct the 3d pose and shape of people, given an input RGB image. We rely on a recently introduced, expressivefull body statistical 3d human model, GHUM, trained end-to-end, and learn to reconstruct its pose and shape state in a self-supervised regime. Central to our methodology, is a learning to learn and optimize approach, referred to as HUmanNeural Descent (HUND), which avoids both second-order differentiation when training the model parameters,and expensive state gradient descent in order to accurately minimize a semantic differentiable rendering loss at test time. Instead, we rely on novel recurrent stages to update the pose and shape parameters such that not only losses are minimized effectively, but the process is meta-regularized in order to ensure end-progress. HUND's symmetry between training and testing makes it the first 3d human sensing architecture to natively support different operating regimes including self-supervised ones. In diverse tests, we show that HUND achieves very competitive results in datasets like H3.6M and 3DPW, aswell as good quality 3d reconstructions for complex imagery collected in-the-wild.
Conditional Image Retrieval
Jul 14, 2020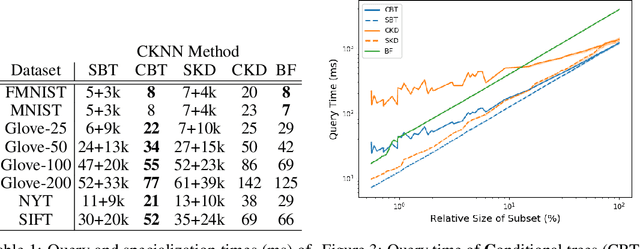
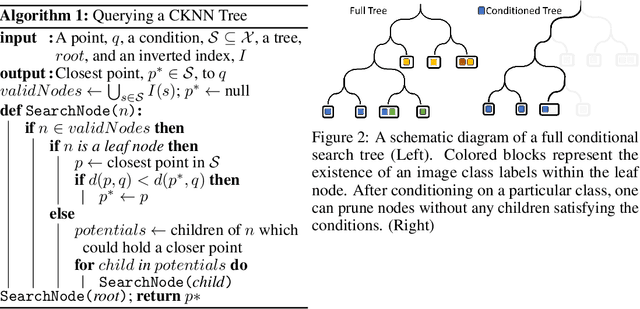
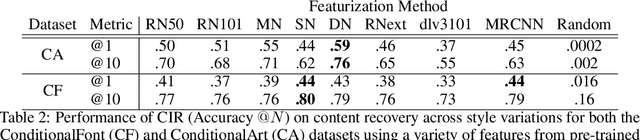
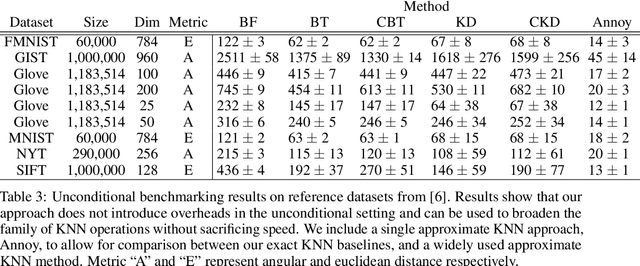
This work introduces Conditional Image Retrieval (CIR) systems: IR methods that can efficiently specialize to specific subsets of images on the fly. These systems broaden the class of queries IR systems support, and eliminate the need for expensive re-fitting to specific subsets of data. Specifically, we adapt tree-based K-Nearest Neighbor (KNN) data-structures to the conditional setting by introducing additional inverted-index data-structures. This speeds conditional queries and does not slow queries without conditioning. We present two new datasets for evaluating the performance of CIR systems and evaluate a variety of design choices. As a motivating application, we present an algorithm that can explore shared semantic content between works of art of vastly different media and cultural origin. Finally, we demonstrate that CIR data-structures can identify Generative Adversarial Network (GAN) ``blind spots'': areas where GANs fail to properly model the true data distribution.
It Is Likely That Your Loss Should be a Likelihood
Jul 12, 2020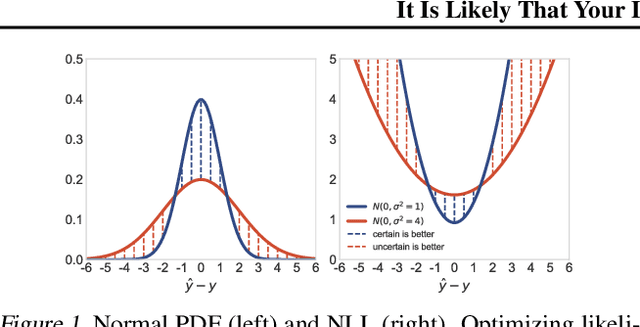
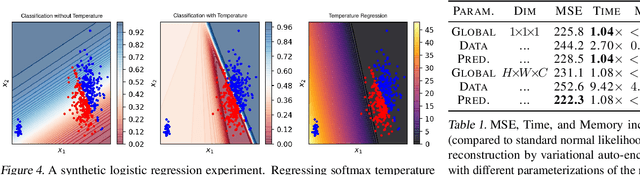

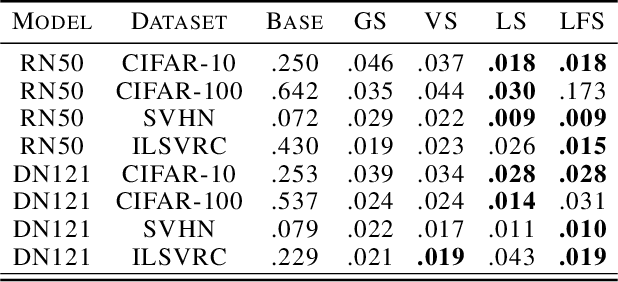
We recall that certain common losses are simplified likelihoods and instead argue for optimizing full likelihoods that include their parameters, such as the variance of the normal distribution and the temperature of the softmax distribution. Joint optimization of likelihood and model parameters can adaptively tune the scales and shapes of losses and the weights of regularizers. We survey and systematically evaluate how to parameterize and apply likelihood parameters for robust modeling and re-calibration. Additionally, we propose adaptively tuning $L_2$ and $L_1$ weights by fitting the scale parameters of normal and Laplace priors and introduce more flexible element-wise regularizers.
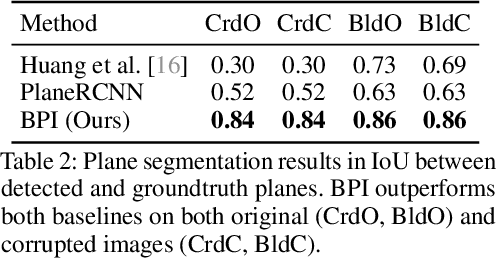
Perspective Plane Program Induction from a Single Image
Jun 25, 2020
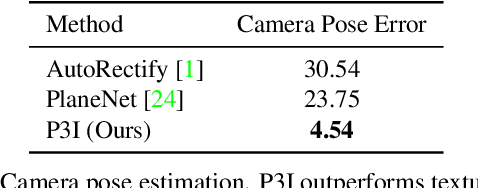

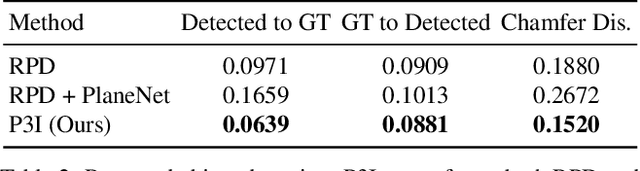
We study the inverse graphics problem of inferring a holistic representation for natural images. Given an input image, our goal is to induce a neuro-symbolic, program-like representation that jointly models camera poses, object locations, and global scene structures. Such high-level, holistic scene representations further facilitate low-level image manipulation tasks such as inpainting. We formulate this problem as jointly finding the camera pose and scene structure that best describe the input image. The benefits of such joint inference are two-fold: scene regularity serves as a new cue for perspective correction, and in turn, correct perspective correction leads to a simplified scene structure, similar to how the correct shape leads to the most regular texture in shape from texture. Our proposed framework, Perspective Plane Program Induction (P3I), combines search-based and gradient-based algorithms to efficiently solve the problem. P3I outperforms a set of baselines on a collection of Internet images, across tasks including camera pose estimation, global structure inference, and down-stream image manipulation tasks.