 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Support Few-Shot Semantic Segmentation
Jul 23, 2022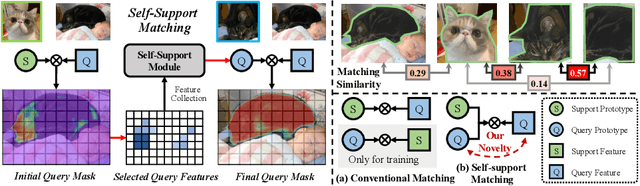

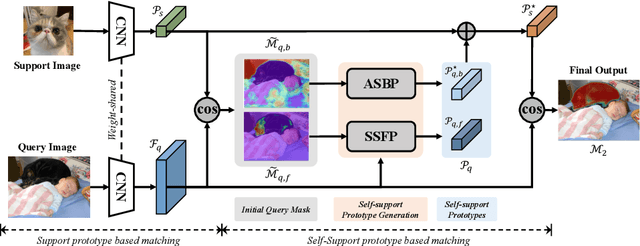
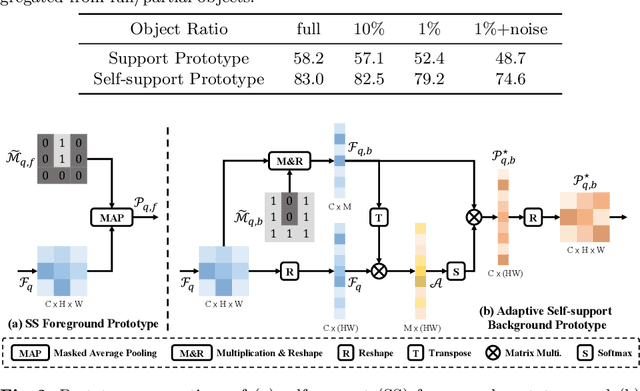
Existing few-shot segmentation methods have achieved great progress based on the support-query matching framework. But they still heavily suffer from the limited coverage of intra-class variations from the few-shot supports provided. Motivated by the simple Gestalt principle that pixels belonging to the same object are more similar than those to different objects of same class, we propose a novel self-support matching strategy to alleviate this problem, which uses query prototypes to match query features, where the query prototypes are collected from high-confidence query predictions. This strategy can effectively capture the consistent underlying characteristics of the query objects, and thus fittingly match query features. We also propose an adaptive self-support background prototype generation module and self-support loss to further facilitate the self-support matching procedure. Our self-support network substantially improves the prototype quality, benefits more improvement from stronger backbones and more supports, and achieves SOTA on multiple datasets. Codes are at \url{https://github.com/fanq15/SSP}.
Multi-Faceted Distillation of Base-Novel Commonality for Few-shot Object Detection
Jul 22, 2022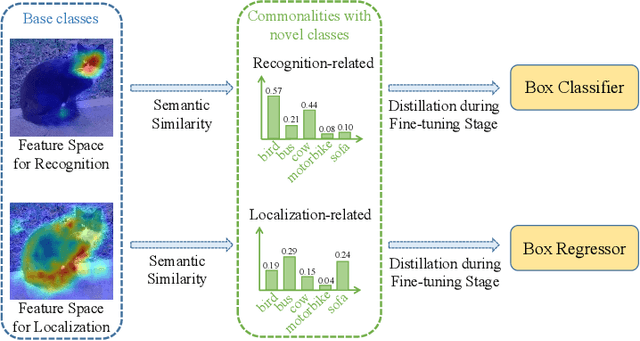
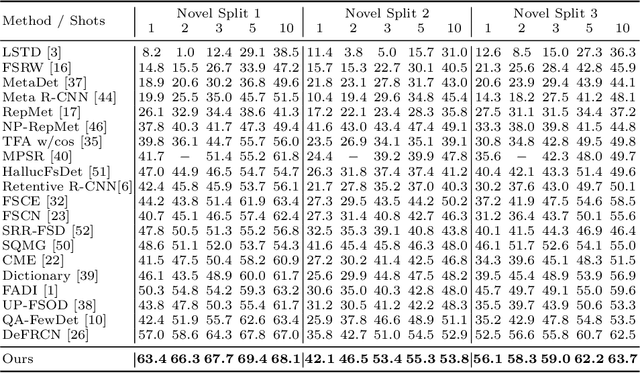
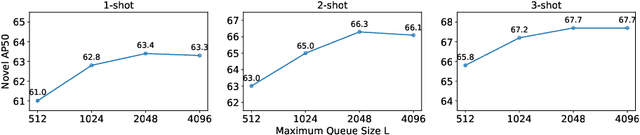
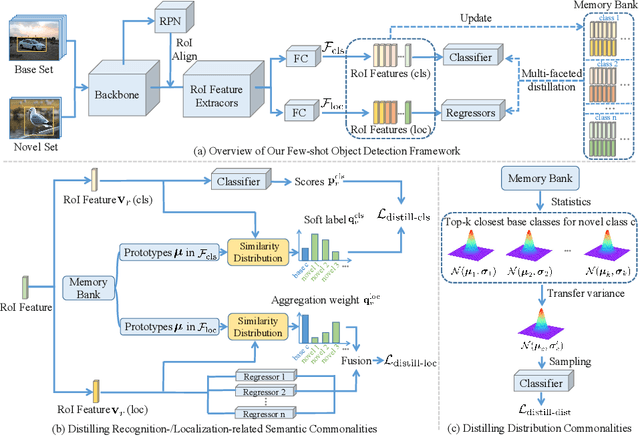
Most of existing methods for few-shot object detection follow the fine-tuning paradigm, which potentially assumes that the class-agnostic generalizable knowledge can be learned and transferred implicitly from base classes with abundant samples to novel classes with limited samples via such a two-stage training strategy. However, it is not necessarily true since the object detector can hardly distinguish between class-agnostic knowledge and class-specific knowledge automatically without explicit modeling. In this work we propose to learn three types of class-agnostic commonalities between base and novel classes explicitly: recognition-related semantic commonalities, localization-related semantic commonalities and distribution commonalities. We design a unified distillation framework based on a memory bank, which is able to perform distillation of all three types of commonalities jointly and efficiently. Extensive experiments demonstrate that our method can be readily integrated into most of existing fine-tuning based methods and consistently improve the performance by a large margin.
Learning Sequence Representations by Non-local Recurrent Neural Memory
Jul 20, 2022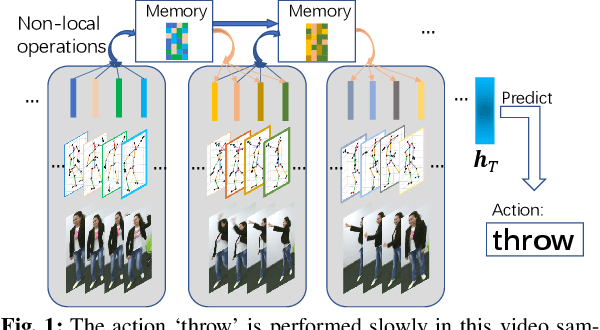
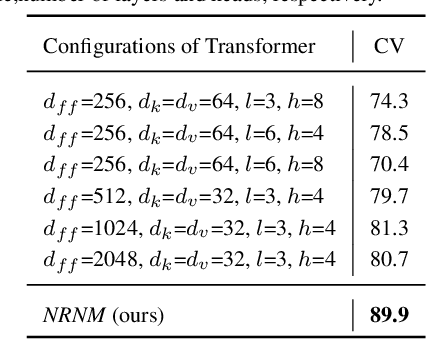
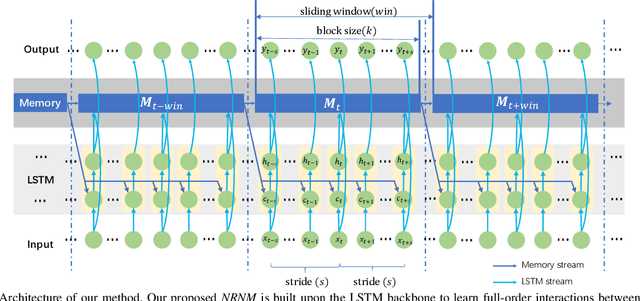
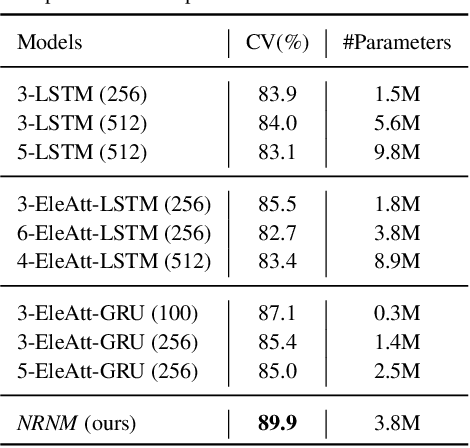
The key challenge of sequence representation learning is to capture the long-range temporal dependencies. Typical methods for supervised sequence representation learning are built upon recurrent neural networks to capture temporal dependencies. One potential limitation of these methods is that they only model one-order information interactions explicitly between adjacent time steps in a sequence, hence the high-order interactions between nonadjacent time steps are not fully exploited. It greatly limits the capability of modeling the long-range temporal dependencies since the temporal features learned by one-order interactions cannot be maintained for a long term due to temporal information dilution and gradient vanishing. To tackle this limitation, we propose the Non-local Recurrent Neural Memory (NRNM) for supervised sequence representation learning, which performs non-local operations \MR{by means of self-attention mechanism} to learn full-order interactions within a sliding temporal memory block and models global interactions between memory blocks in a gated recurrent manner. Consequently, our model is able to capture long-range dependencies. Besides, the latent high-level features contained in high-order interactions can be distilled by our model. We validate the effectiveness and generalization of our NRNM on three types of sequence applications across different modalities, including sequence classification, step-wise sequential prediction and sequence similarity learning. Our model compares favorably against other state-of-the-art methods specifically designed for each of these sequence applications.
Decoupling Recognition from Detection: Single Shot Self-Reliant Scene Text Spotter
Jul 18, 2022

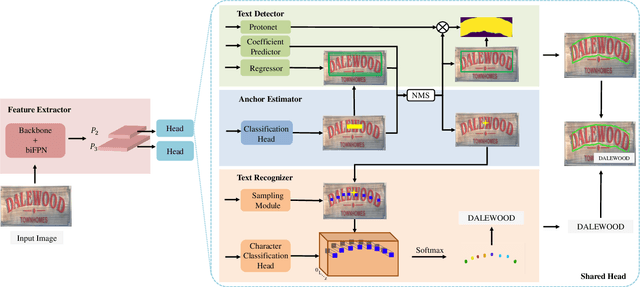

Typical text spotters follow the two-stage spotting strategy: detect the precise boundary for a text instance first and then perform text recognition within the located text region. While such strategy has achieved substantial progress, there are two underlying limitations. 1) The performance of text recognition depends heavily on the precision of text detection, resulting in the potential error propagation from detection to recognition. 2) The RoI cropping which bridges the detection and recognition brings noise from background and leads to information loss when pooling or interpolating from feature maps. In this work we propose the single shot Self-Reliant Scene Text Spotter (SRSTS), which circumvents these limitations by decoupling recognition from detection. Specifically, we conduct text detection and recognition in parallel and bridge them by the shared positive anchor point. Consequently, our method is able to recognize the text instances correctly even though the precise text boundaries are challenging to detect. Additionally, our method reduces the annotation cost for text detection substantially. Extensive experiments on regular-shaped benchmark and arbitrary-shaped benchmark demonstrate that our SRSTS compares favorably to previous state-of-the-art spotters in terms of both accuracy and efficiency.
Global-Local Stepwise Generative Network for Ultra High-Resolution Image Restoration
Jul 16, 2022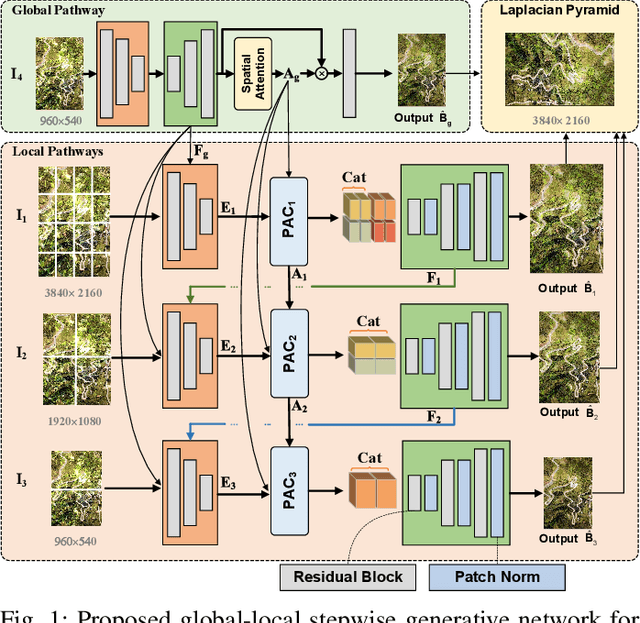



While the research on image background restoration from regular size of degraded images has achieved remarkable progress, restoring ultra high-resolution (e.g., 4K) images remains an extremely challenging task due to the explosion of computational complexity and memory usage, as well as the deficiency of annotated data. In this paper we present a novel model for ultra high-resolution image restoration, referred to as the Global-Local Stepwise Generative Network (GLSGN), which employs a stepwise restoring strategy involving four restoring pathways: three local pathways and one global pathway. The local pathways focus on conducting image restoration in a fine-grained manner over local but high-resolution image patches, while the global pathway performs image restoration coarsely on the scale-down but intact image to provide cues for the local pathways in a global view including semantics and noise patterns. To smooth the mutual collaboration between these four pathways, our GLSGN is designed to ensure the inter-pathway consistency in four aspects in terms of low-level content, perceptual attention, restoring intensity and high-level semantics, respectively. As another major contribution of this work, we also introduce the first ultra high-resolution dataset to date for both reflection removal and rain streak removal, comprising 4,670 real-world and synthetic images. Extensive experiments across three typical tasks for image background restoration, including image reflection removal, image rain streak removal and image dehazing, show that our GLSGN consistently outperforms state-of-the-art methods.
Global Tracking via Ensemble of Local Trackers
Mar 30, 2022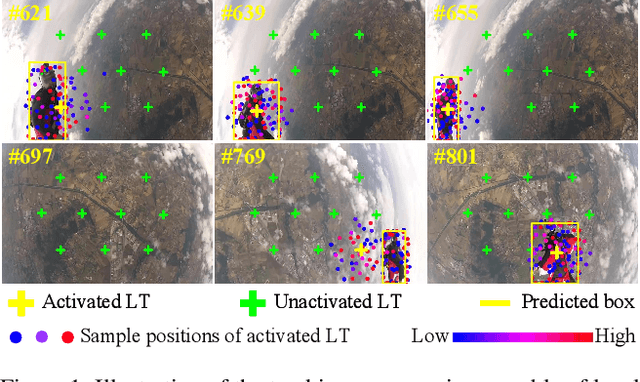
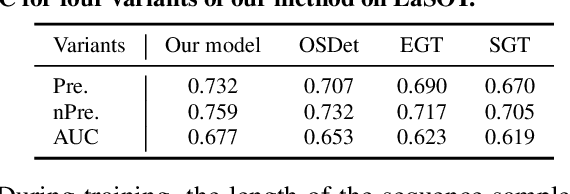
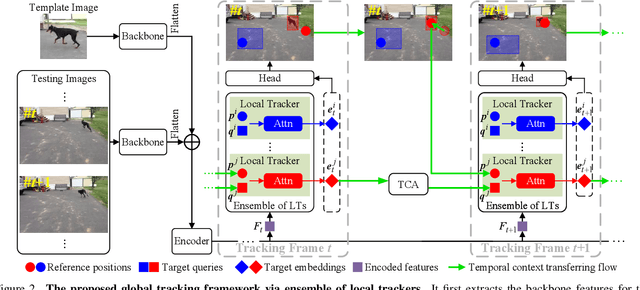
The crux of long-term tracking lies in the difficulty of tracking the target with discontinuous moving caused by out-of-view or occlusion. Existing long-term tracking methods follow two typical strategies. The first strategy employs a local tracker to perform smooth tracking and uses another re-detector to detect the target when the target is lost. While it can exploit the temporal context like historical appearances and locations of the target, a potential limitation of such strategy is that the local tracker tends to misidentify a nearby distractor as the target instead of activating the re-detector when the real target is out of view. The other long-term tracking strategy tracks the target in the entire image globally instead of local tracking based on the previous tracking results. Unfortunately, such global tracking strategy cannot leverage the temporal context effectively. In this work, we combine the advantages of both strategies: tracking the target in a global view while exploiting the temporal context. Specifically, we perform global tracking via ensemble of local trackers spreading the full image. The smooth moving of the target can be handled steadily by one local tracker. When the local tracker accidentally loses the target due to suddenly discontinuous moving, another local tracker close to the target is then activated and can readily take over the tracking to locate the target. While the activated local tracker performs tracking locally by leveraging the temporal context, the ensemble of local trackers renders our model the global view for tracking. Extensive experiments on six datasets demonstrate that our method performs favorably against state-of-the-art algorithms.
Exploring Category-correlated Feature for Few-shot Image Classification
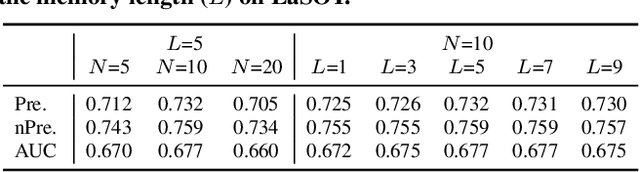
Dec 14, 2021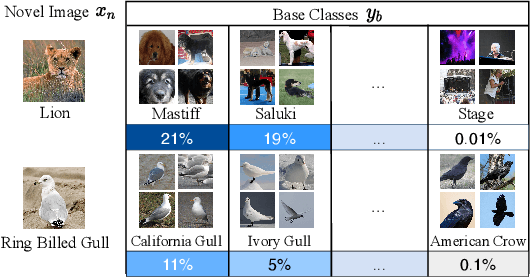
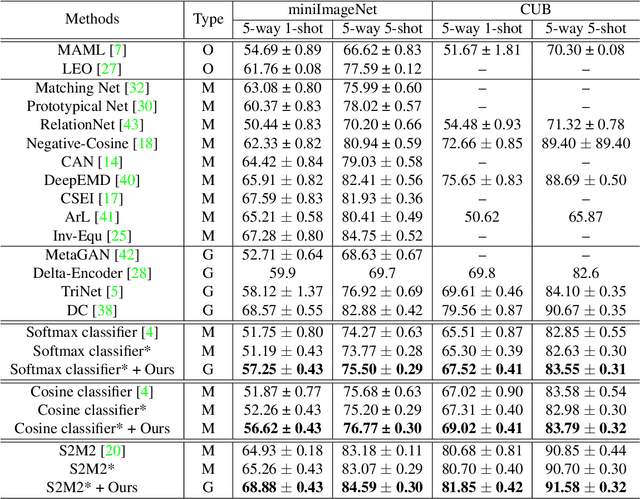

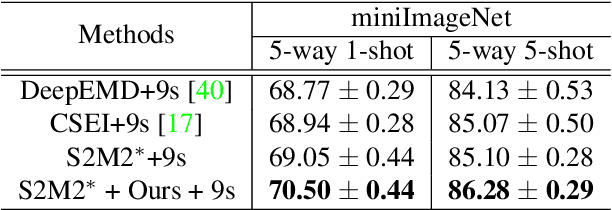
Few-shot classification aims to adapt classifiers to novel classes with a few training samples. However, the insufficiency of training data may cause a biased estimation of feature distribution in a certain class. To alleviate this problem, we present a simple yet effective feature rectification method by exploring the category correlation between novel and base classes as the prior knowledge. We explicitly capture such correlation by mapping features into a latent vector with dimension matching the number of base classes, treating it as the logarithm probability of the feature over base classes. Based on this latent vector, the rectified feature is directly constructed by a decoder, which we expect maintaining category-related information while removing other stochastic factors, and consequently being closer to its class centroid. Furthermore, by changing the temperature value in softmax, we can re-balance the feature rectification and reconstruction for better performance. Our method is generic, flexible and agnostic to any feature extractor and classifier, readily to be embedded into existing FSL approaches. Experiments verify that our method is capable of rectifying biased features, especially when the feature is far from the class centroid. The proposed approach consistently obtains considerable performance gains on three widely used benchmarks, evaluated with different backbones and classifiers. The code will be made public.
An Informative Tracking Benchmark
Dec 13, 2021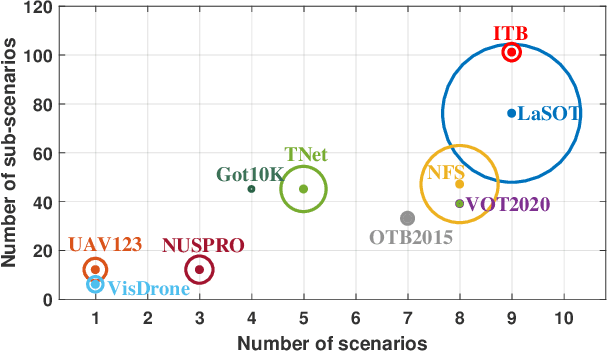
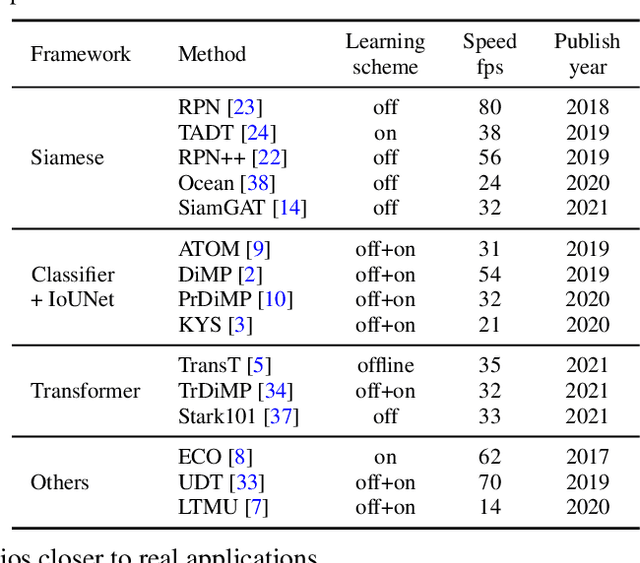
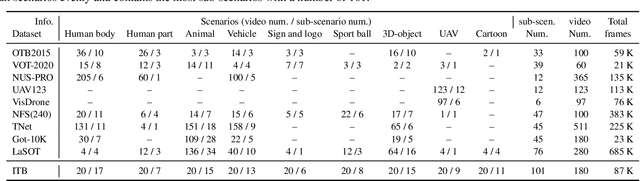
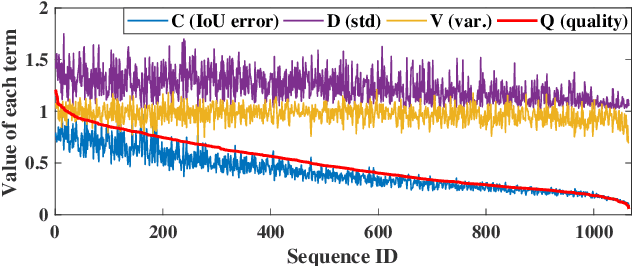
Along with the rapid progress of visual tracking, existing benchmarks become less informative due to redundancy of samples and weak discrimination between current trackers, making evaluations on all datasets extremely time-consuming. Thus, a small and informative benchmark, which covers all typical challenging scenarios to facilitate assessing the tracker performance, is of great interest. In this work, we develop a principled way to construct a small and informative tracking benchmark (ITB) with 7% out of 1.2 M frames of existing and newly collected datasets, which enables efficient evaluation while ensuring effectiveness. Specifically, we first design a quality assessment mechanism to select the most informative sequences from existing benchmarks taking into account 1) challenging level, 2) discriminative strength, 3) and density of appearance variations. Furthermore, we collect additional sequences to ensure the diversity and balance of tracking scenarios, leading to a total of 20 sequences for each scenario. By analyzing the results of 15 state-of-the-art trackers re-trained on the same data, we determine the effective methods for robust tracking under each scenario and demonstrate new challenges for future research direction in this field.
U2-Former: A Nested U-shaped Transformer for Image Restoration
Dec 08, 2021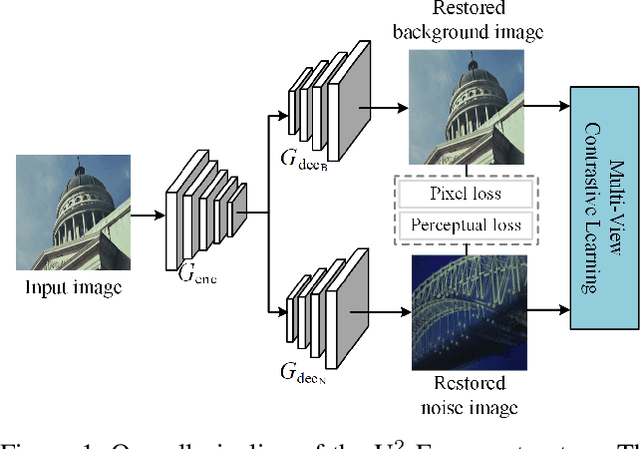
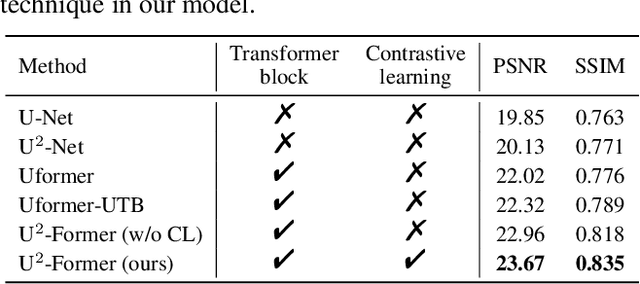
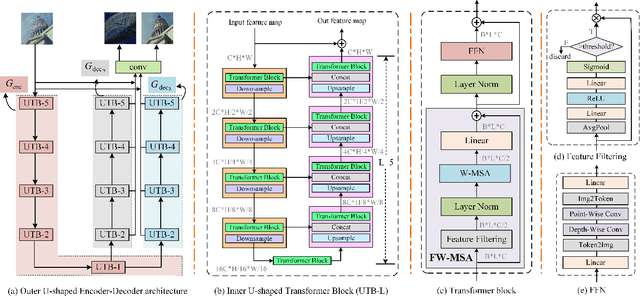
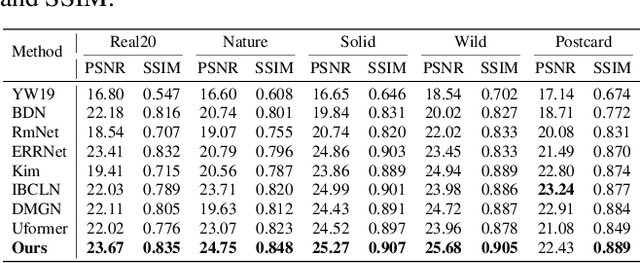
While Transformer has achieved remarkable performance in various high-level vision tasks, it is still challenging to exploit the full potential of Transformer in image restoration. The crux lies in the limited depth of applying Transformer in the typical encoder-decoder framework for image restoration, resulting from heavy self-attention computation load and inefficient communications across different depth (scales) of layers. In this paper, we present a deep and effective Transformer-based network for image restoration, termed as U2-Former, which is able to employ Transformer as the core operation to perform image restoration in a deep encoding and decoding space. Specifically, it leverages the nested U-shaped structure to facilitate the interactions across different layers with different scales of feature maps. Furthermore, we optimize the computational efficiency for the basic Transformer block by introducing a feature-filtering mechanism to compress the token representation. Apart from the typical supervision ways for image restoration, our U2-Former also performs contrastive learning in multiple aspects to further decouple the noise component from the background image. Extensive experiments on various image restoration tasks, including reflection removal, rain streak removal and dehazing respectively, demonstrate the effectiveness of the proposed U2-Former.
Pedestrian Detection by Exemplar-Guided Contrastive Learning
Nov 30, 2021
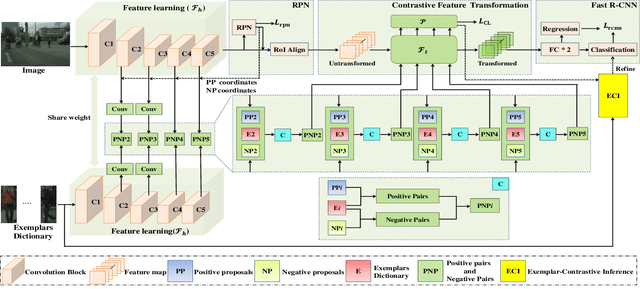
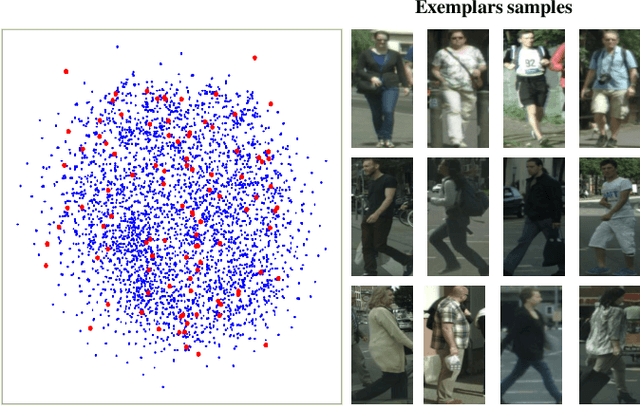
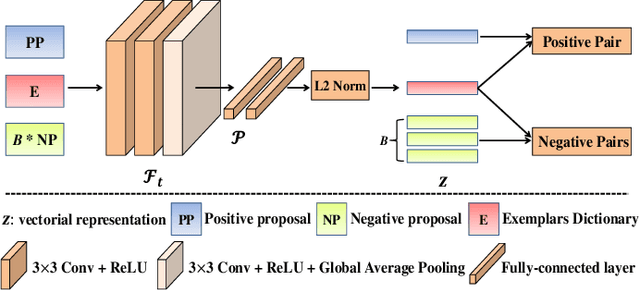
Typical methods for pedestrian detection focus on either tackling mutual occlusions between crowded pedestrians, or dealing with the various scales of pedestrians. Detecting pedestrians with substantial appearance diversities such as different pedestrian silhouettes, different viewpoints or different dressing, remains a crucial challenge. Instead of learning each of these diverse pedestrian appearance features individually as most existing methods do, we propose to perform contrastive learning to guide the feature learning in such a way that the semantic distance between pedestrians with different appearances in the learned feature space is minimized to eliminate the appearance diversities, whilst the distance between pedestrians and background is maximized. To facilitate the efficiency and effectiveness of contrastive learning, we construct an exemplar dictionary with representative pedestrian appearances as prior knowledge to construct effective contrastive training pairs and thus guide contrastive learning. Besides, the constructed exemplar dictionary is further leveraged to evaluate the quality of pedestrian proposals during inference by measuring the semantic distance between the proposal and the exemplar dictionary. Extensive experiments on both daytime and nighttime pedestrian detection validate the effectiveness of the proposed method.