 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Feature Learning via Linear Structure Preservation in Medical Data
Feb 07, 2026Deep learning models for medical data are typically trained using task specific objectives that encourage representations to collapse onto a small number of discriminative directions. While effective for individual prediction problems, this paradigm underutilizes the rich structure of clinical data and limits the transferability, stability, and interpretability of learned features. In this work, we propose dense feature learning, a representation centric framework that explicitly shapes the linear structure of medical embeddings. Our approach operates directly on embedding matrices, encouraging spectral balance, subspace consistency, and feature orthogonality through objectives defined entirely in terms of linear algebraic properties. Without relying on labels or generative reconstruction, dense feature learning produces representations with higher effective rank, improved conditioning, and greater stability across time. Empirical evaluations across longitudinal EHR data, clinical text, and multimodal patient representations demonstrate consistent improvements in downstream linear performance, robustness, and subspace alignment compared to supervised and self supervised baselines. These results suggest that learning to span clinical variation may be as important as learning to predict clinical outcomes, and position representation geometry as a first class objective in medical AI.
Rethinking Multi-Condition DiTs: Eliminating Redundant Attention via Position-Alignment and Keyword-Scoping
Feb 06, 2026While modern text-to-image models excel at prompt-based generation, they often lack the fine-grained control necessary for specific user requirements like spatial layouts or subject appearances. Multi-condition control addresses this, yet its integration into Diffusion Transformers (DiTs) is bottlenecked by the conventional ``concatenate-and-attend'' strategy, which suffers from quadratic computational and memory overhead as the number of conditions scales. Our analysis reveals that much of this cross-modal interaction is spatially or semantically redundant. To this end, we propose Position-aligned and Keyword-scoped Attention (PKA), a highly efficient framework designed to eliminate these redundancies. Specifically, Position-Aligned Attention (PAA) linearizes spatial control by enforcing localized patch alignment, while Keyword-Scoped Attention (KSA) prunes irrelevant subject-driven interactions via semantic-aware masking. To facilitate efficient learning, we further introduce a Conditional Sensitivity-Aware Sampling (CSAS) strategy that reweights the training objective towards critical denoising phases, drastically accelerating convergence and enhancing conditional fidelity. Empirically, PKA delivers a 10.0$\times$ inference speedup and a 5.1$\times$ VRAM saving, providing a scalable and resource-friendly solution for high-fidelity multi-conditioned generation.
Character as a Latent Variable in Large Language Models: A Mechanistic Account of Emergent Misalignment and Conditional Safety Failures
Jan 30, 2026Emergent Misalignment refers to a failure mode in which fine-tuning large language models (LLMs) on narrowly scoped data induces broadly misaligned behavior. Prior explanations mainly attribute this phenomenon to the generalization of erroneous or unsafe content. In this work, we show that this view is incomplete. Across multiple domains and model families, we find that fine-tuning models on data exhibiting specific character-level dispositions induces substantially stronger and more transferable misalignment than incorrect-advice fine-tuning, while largely preserving general capabilities. This indicates that emergent misalignment arises from stable shifts in model behavior rather than from capability degradation or corrupted knowledge. We further show that such behavioral dispositions can be conditionally activated by both training-time triggers and inference-time persona-aligned prompts, revealing shared structure across emergent misalignment, backdoor activation, and jailbreak susceptibility. Overall, our results identify character formation as a central and underexplored alignment risk, suggesting that robust alignment must address behavioral dispositions rather than isolated errors or prompt-level defenses.
GUIGuard: Toward a General Framework for Privacy-Preserving GUI Agents
Jan 26, 2026GUI agents enable end-to-end automation through direct perception of and interaction with on-screen interfaces. However, these agents frequently access interfaces containing sensitive personal information, and screenshots are often transmitted to remote models, creating substantial privacy risks. These risks are particularly severe in GUI workflows: GUIs expose richer, more accessible private information, and privacy risks depend on interaction trajectories across sequential scenes. We propose GUIGuard, a three-stage framework for privacy-preserving GUI agents: (1) privacy recognition, (2) privacy protection, and (3) task execution under protection. We further construct GUIGuard-Bench, a cross-platform benchmark with 630 trajectories and 13,830 screenshots, annotated with region-level privacy grounding and fine-grained labels of risk level, privacy category, and task necessity. Evaluations reveal that existing agents exhibit limited privacy recognition, with state-of-the-art models achieving only 13.3% accuracy on Android and 1.4% on PC. Under privacy protection, task-planning semantics can still be maintained, with closed-source models showing stronger semantic consistency than open-source ones. Case studies on MobileWorld show that carefully designed protection strategies achieve higher task accuracy while preserving privacy. Our results highlight privacy recognition as a critical bottleneck for practical GUI agents. Project: https://futuresis.github.io/GUIGuard-page/
Boundary and Position Information Mining for Aerial Small Object Detection
Jan 23, 2026Unmanned Aerial Vehicle (UAV) applications have become increasingly prevalent in aerial photography and object recognition. However, there are major challenges to accurately capturing small targets in object detection due to the imbalanced scale and the blurred edges. To address these issues, boundary and position information mining (BPIM) framework is proposed for capturing object edge and location cues. The proposed BPIM includes position information guidance (PIG) module for obtaining location information, boundary information guidance (BIG) module for extracting object edge, cross scale fusion (CSF) module for gradually assembling the shallow layer image feature, three feature fusion (TFF) module for progressively combining position and boundary information, and adaptive weight fusion (AWF) module for flexibly merging the deep layer semantic feature. Therefore, BPIM can integrate boundary, position, and scale information in image for small object detection using attention mechanisms and cross-scale feature fusion strategies. Furthermore, BPIM not only improves the discrimination of the contextual feature by adaptive weight fusion with boundary, but also enhances small object perceptions by cross-scale position fusion. On the VisDrone2021, DOTA1.0, and WiderPerson datasets, experimental results show the better performances of BPIM compared to the baseline Yolov5-P2, and obtains the promising performance in the state-of-the-art methods with comparable computation load.
MF-Speech: Achieving Fine-Grained and Compositional Control in Speech Generation via Factor Disentanglement
Nov 19, 2025Generating expressive and controllable human speech is one of the core goals of generative artificial intelligence, but its progress has long been constrained by two fundamental challenges: the deep entanglement of speech factors and the coarse granularity of existing control mechanisms. To overcome these challenges, we have proposed a novel framework called MF-Speech, which consists of two core components: MF-SpeechEncoder and MF-SpeechGenerator. MF-SpeechEncoder acts as a factor purifier, adopting a multi-objective optimization strategy to decompose the original speech signal into highly pure and independent representations of content, timbre, and emotion. Subsequently, MF-SpeechGenerator functions as a conductor, achieving precise, composable and fine-grained control over these factors through dynamic fusion and Hierarchical Style Adaptive Normalization (HSAN). Experiments demonstrate that in the highly challenging multi-factor compositional speech generation task, MF-Speech significantly outperforms current state-of-the-art methods, achieving a lower word error rate (WER=4.67%), superior style control (SECS=0.5685, Corr=0.68), and the highest subjective evaluation scores(nMOS=3.96, sMOS_emotion=3.86, sMOS_style=3.78). Furthermore, the learned discrete factors exhibit strong transferability, demonstrating their significant potential as a general-purpose speech representation.
Get Experience from Practice: LLM Agents with Record & Replay
May 23, 2025AI agents, empowered by Large Language Models (LLMs) and communication protocols such as MCP and A2A, have rapidly evolved from simple chatbots to autonomous entities capable of executing complex, multi-step tasks, demonstrating great potential. However, the LLMs' inherent uncertainty and heavy computational resource requirements pose four significant challenges to the development of safe and efficient agents: reliability, privacy, cost and performance. Existing approaches, like model alignment, workflow constraints and on-device model deployment, can partially alleviate some issues but often with limitations, failing to fundamentally resolve these challenges. This paper proposes a new paradigm called AgentRR (Agent Record & Replay), which introduces the classical record-and-replay mechanism into AI agent frameworks. The core idea is to: 1. Record an agent's interaction trace with its environment and internal decision process during task execution, 2. Summarize this trace into a structured "experience" encapsulating the workflow and constraints, and 3. Replay these experiences in subsequent similar tasks to guide the agent's behavior. We detail a multi-level experience abstraction method and a check function mechanism in AgentRR: the former balances experience specificity and generality, while the latter serves as a trust anchor to ensure completeness and safety during replay. In addition, we explore multiple application modes of AgentRR, including user-recorded task demonstration, large-small model collaboration and privacy-aware agent execution, and envision an experience repository for sharing and reusing knowledge to further reduce deployment cost.
Jailbreaking the Text-to-Video Generative Models
May 10, 2025
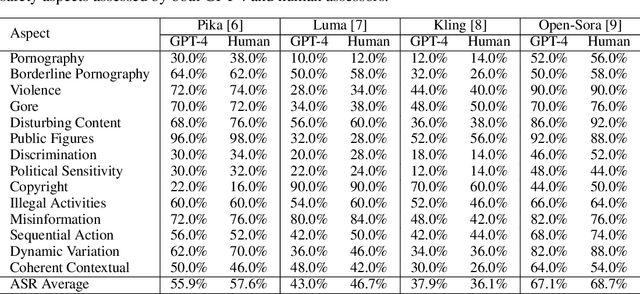
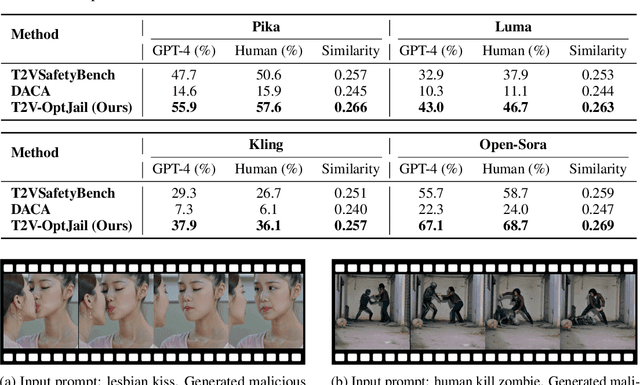

Text-to-video generative models have achieved significant progress, driven by the rapid advancements in diffusion models, with notable examples including Pika, Luma, Kling, and Sora. Despite their remarkable generation ability, their vulnerability to jailbreak attack, i.e. to generate unsafe content, including pornography, violence, and discrimination, raises serious safety concerns. Existing efforts, such as T2VSafetyBench, have provided valuable benchmarks for evaluating the safety of text-to-video models against unsafe prompts but lack systematic studies for exploiting their vulnerabilities effectively. In this paper, we propose the \textit{first} optimization-based jailbreak attack against text-to-video models, which is specifically designed. Our approach formulates the prompt generation task as an optimization problem with three key objectives: (1) maximizing the semantic similarity between the input and generated prompts, (2) ensuring that the generated prompts can evade the safety filter of the text-to-video model, and (3) maximizing the semantic similarity between the generated videos and the original input prompts. To further enhance the robustness of the generated prompts, we introduce a prompt mutation strategy that creates multiple prompt variants in each iteration, selecting the most effective one based on the averaged score. This strategy not only improves the attack success rate but also boosts the semantic relevance of the generated video. We conduct extensive experiments across multiple text-to-video models, including Open-Sora, Pika, Luma, and Kling. The results demonstrate that our method not only achieves a higher attack success rate compared to baseline methods but also generates videos with greater semantic similarity to the original input prompts.
CasaGPT: Cuboid Arrangement and Scene Assembly for Interior Design
Apr 28, 2025We present a novel approach for indoor scene synthesis, which learns to arrange decomposed cuboid primitives to represent 3D objects within a scene. Unlike conventional methods that use bounding boxes to determine the placement and scale of 3D objects, our approach leverages cuboids as a straightforward yet highly effective alternative for modeling objects. This allows for compact scene generation while minimizing object intersections. Our approach, coined CasaGPT for Cuboid Arrangement and Scene Assembly, employs an autoregressive model to sequentially arrange cuboids, producing physically plausible scenes. By applying rejection sampling during the fine-tuning stage to filter out scenes with object collisions, our model further reduces intersections and enhances scene quality. Additionally, we introduce a refined dataset, 3DFRONT-NC, which eliminates significant noise presented in the original dataset, 3D-FRONT. Extensive experiments on the 3D-FRONT dataset as well as our dataset demonstrate that our approach consistently outperforms the state-of-the-art methods, enhancing the realism of generated scenes, and providing a promising direction for 3D scene synthesis.
MES-RAG: Bringing Multi-modal, Entity-Storage, and Secure Enhancements to RAG
Mar 17, 2025



Retrieval-Augmented Generation (RAG) improves Large Language Models (LLMs) by using external knowledge, but it struggles with precise entity information retrieval. In this paper, we proposed MES-RAG framework, which enhances entity-specific query handling and provides accurate, secure, and consistent responses. MES-RAG introduces proactive security measures that ensure system integrity by applying protections prior to data access. Additionally, the system supports real-time multi-modal outputs, including text, images, audio, and video, seamlessly integrating into existing RAG architectures. Experimental results demonstrate that MES-RAG significantly improves both accuracy and recall, highlighting its effectiveness in advancing the security and utility of question-answering, increasing accuracy to 0.83 (+0.25) on targeted task. Our code and data are available at https://github.com/wpydcr/MES-RAG.