 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUIGuard: Toward a General Framework for Privacy-Preserving GUI Agents
Jan 26, 2026GUI agents enable end-to-end automation through direct perception of and interaction with on-screen interfaces. However, these agents frequently access interfaces containing sensitive personal information, and screenshots are often transmitted to remote models, creating substantial privacy risks. These risks are particularly severe in GUI workflows: GUIs expose richer, more accessible private information, and privacy risks depend on interaction trajectories across sequential scenes. We propose GUIGuard, a three-stage framework for privacy-preserving GUI agents: (1) privacy recognition, (2) privacy protection, and (3) task execution under protection. We further construct GUIGuard-Bench, a cross-platform benchmark with 630 trajectories and 13,830 screenshots, annotated with region-level privacy grounding and fine-grained labels of risk level, privacy category, and task necessity. Evaluations reveal that existing agents exhibit limited privacy recognition, with state-of-the-art models achieving only 13.3% accuracy on Android and 1.4% on PC. Under privacy protection, task-planning semantics can still be maintained, with closed-source models showing stronger semantic consistency than open-source ones. Case studies on MobileWorld show that carefully designed protection strategies achieve higher task accuracy while preserving privacy. Our results highlight privacy recognition as a critical bottleneck for practical GUI agents. Project: https://futuresis.github.io/GUIGuard-page/
Mixed Chain-of-Psychotherapies for Emotional Support Chatbot
Sep 29, 2024



In the realm of mental health support chatbots, it is vital to show empathy and encourage self-exploration to provide tailored solutions. However, current approaches tend to provide general insights or solutions without fully understanding the help-seeker's situation. Therefore, we propose PsyMix, a chatbot that integrates the analyses of the seeker's state from the perspective of a psychotherapy approach (Chain-of-Psychotherapies, CoP) before generating the response, and learns to incorporate the strength of various psychotherapies by fine-tuning on a mixture of CoPs. Through comprehensive evaluation, we found that PsyMix can outperform the ChatGPT baseline, and demonstrate a comparable level of empathy in its responses to that of human counselors.
Segue: Side-information Guided Generative Unlearnable Examples for Facial Privacy Protection in Real World
Oct 24, 2023The widespread use of face recognition technology has given rise to privacy concerns, as many individuals are worried about the collection and utilization of their facial data. To address these concerns, researchers are actively exploring the concept of ``unlearnable examples", by adding imperceptible perturbation to data in the model training stage, which aims to prevent the model from learning discriminate features of the target face. However, current methods are inefficient and cannot guarantee transferability and robustness at the same time, causing impracticality in the real world. To remedy it, we propose a novel method called Segue: Side-information guided generative unlearnable examples. Specifically, we leverage a once-trained multiple-used model to generate the desired perturbation rather than the time-consuming gradient-based method. To improve transferability, we introduce side information such as true labels and pseudo labels, which are inherently consistent across different scenarios. For robustness enhancement, a distortion layer is integrated into the training pipeline. Extensive experiments demonstrate that the proposed Segue is much faster than previous methods (1000$\times$) and achieves transferable effectiveness across different datasets and model architectures. Furthermore, it can resist JPEG compression, adversarial training, and some standard data augmentations.
A flexible and accurate total variation and cascaded denoisers-based image reconstruction algorithm for hyperspectrally compressed ultrafast photography
Sep 06, 2023Hyperspectrally compressed ultrafast photography (HCUP) based on compressed sensing and the time- and spectrum-to-space mappings can simultaneously realize the temporal and spectral imaging of non-repeatable or difficult-to-repeat transient events passively in a single exposure. It possesses an incredibly high frame rate of tens of trillions of frames per second and a sequence depth of several hundred, and plays a revolutionary role in single-shot ultrafast optical imaging. However, due to the ultra-high data compression ratio induced by the extremely large sequence depth as well as the limited fidelities of traditional reconstruction algorithms over the reconstruction process, HCUP suffers from a poor image reconstruction quality and fails to capture fine structures in complex transient scenes. To overcome these restrictions, we propose a flexible image reconstruction algorithm based on the total variation (TV) and cascaded denoisers (CD) for HCUP, named the TV-CD algorithm. It applies the TV denoising model cascaded with several advanced deep learning-based denoising models in the iterative plug-and-play alternating direction method of multipliers framework, which can preserve the image smoothness while utilizing the deep denoising networks to obtain more priori, and thus solving the common sparsity representation problem in local similarity and motion compensation. Both simulation and experimental results show that the proposed TV-CD algorithm can effectively improve the image reconstruction accuracy and quality of HCUP, and further promote the practical applications of HCUP in capturing high-dimensional complex physical, chemical and biological ultrafast optical scenes.
LLM-empowered Chatbots for Psychiatrist and Patient Simulation: Application and Evaluation
May 23, 2023Empowering chatbots in the field of mental health is receiving increasing amount of attention, while there still lacks exploration in developing and evaluating chatbots in psychiatric outpatient scenarios. In this work, we focus on exploring the potential of ChatGPT in powering chatbots for psychiatrist and patient simulation. We collaborate with psychiatrists to identify objectives and iteratively develop the dialogue system to closely align with real-world scenarios. In the evaluation experiments, we recruit real psychiatrists and patients to engage in diagnostic conversations with the chatbots, collecting their ratings for assessment. Our findings demonstrate the feasibility of using ChatGPT-powered chatbots in psychiatric scenarios and explore the impact of prompt designs on chatbot behavior and user experience.
Semantic Space Grounded Weighted Decoding for Multi-Attribute Controllable Dialogue Generation
May 04, 2023Controlling chatbot utterance generation with multiple attributes such as personalities, emotions and dialogue acts is a practically useful but under-studied problem. We propose a novel controllable generation framework called DASC that possesses strong controllability with weighted decoding paradigm, while improving generation quality with the grounding in an attribute semantics space. Generation with multiple attributes is then intuitively implemented with an interpolation of multiple attribute embeddings. Experiments show that DASC can achieve state-of-the-art control accuracy in 3-aspect controllable generation tasks while also producing interesting and reasonably sensible responses, even if in an out-of-distribution robustness test. Visualization of the meaningful representations learned in the attribute semantic space also supports its effectiveness.
BLAT: Bootstrapping Language-Audio Pre-training based on AudioSet Tag-guided Synthetic Data
Mar 14, 2023



Compared with ample visual-text pre-training research, few works explore audio-text pre-training, mostly due to the lack of sufficient parallel audio-text data. Most existing methods incorporate the visual modality as a pivot for audio-text pre-training, which inevitably induces data noise. In this paper, we propose BLAT: Bootstrapping Language-Audio pre-training based on Tag-guided synthetic data. We utilize audio captioning to generate text directly from audio, without the aid of the visual modality so that potential noise from modality mismatch is eliminated. Furthermore, we propose caption generation under the guidance of AudioSet tags, leading to more accurate captions. With the above two improvements, we curate high-quality, large-scale parallel audio-text data, based on which we perform audio-text pre-training. Evaluation on a series of downstream tasks indicates that BLAT achieves SOTA zero-shot classification performance on most datasets and significant performance improvement when fine-tuned on downstream tasks, suggesting the effectiveness of our synthetic data.
Symptom Identification for Interpretable Detection of Multiple Mental Disorders
May 23, 2022



Mental disease detection (MDD) from social media has suffered from poor generalizability and interpretability, due to lack of symptom modeling. This paper introduces PsySym, the first annotated symptom identification corpus of multiple psychiatric disorders, to facilitate further research progress. PsySym is annotated according to a knowledge graph of the 38 symptom classes related to 7 mental diseases complied from established clinical manuals and scales, and a novel annotation framework for diversity and quality. Experiments show that symptom-assisted MDD enabled by PsySym can outperform strong pure-text baselines. We also exhibit the convincing MDD explanations provided by symptom predictions with case studies, and point to their further potential applications.
Psychiatric Scale Guided Risky Post Screening for Early Detection of Depression
May 19, 2022


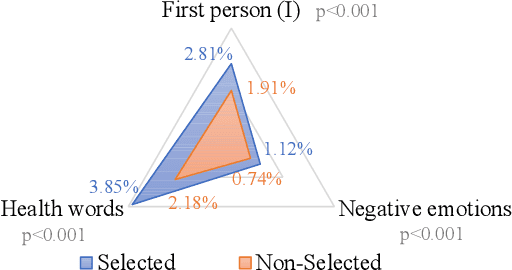
Depression is a prominent health challenge to the world, and early risk detection (ERD) of depression from online posts can be a promising technique for combating the threat. Early depression detection faces the challenge of efficiently tackling streaming data, balancing the tradeoff between timeliness, accuracy and explainability. To tackle these challenges, we propose a psychiatric scale guided risky post screening method that can capture risky posts related to the dimensions defined in clinical depression scales, and providing interpretable diagnostic basis. A Hierarchical Attentional Network equipped with BERT (HAN-BERT) is proposed to further advance explainable predictions. For ERD, we propose an online algorithm based on an evolving queue of risky posts that can significantly reduce the number of model inferences to boost efficiency. Experiments show that our method outperforms the competitive feature-based and neural models under conventional depression detection settings, and achieves simultaneous improvement in both efficacy and efficiency for ERD.
Can Audio Captions Be Evaluated with Image Caption Metrics?
Oct 10, 2021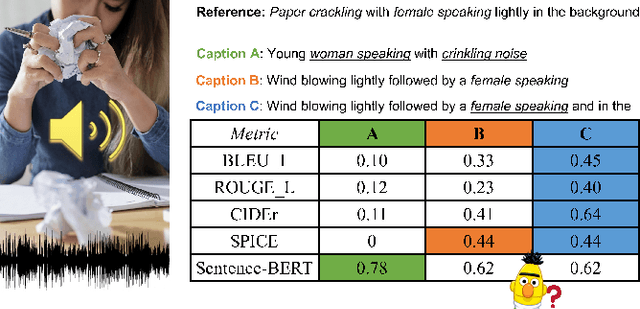

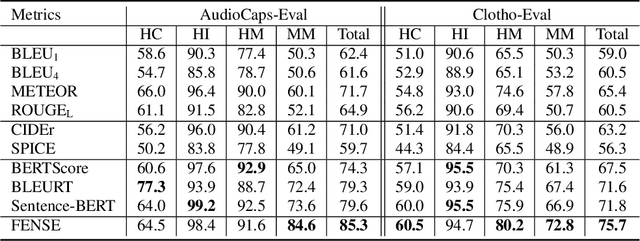
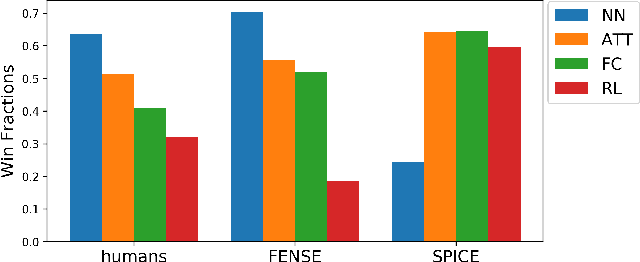
Automated audio captioning aims at generating textual descriptions for an audio clip. To evaluate the quality of generated audio captions, previous works directly adopt image captioning metrics like SPICE and CIDEr, without justifying their suitability in this new domain, which may mislead the development of advanced models. This problem is still unstudied due to the lack of human judgment datasets on caption quality. Therefore, we firstly construct two evaluation benchmarks, AudioCaps-Eval and Clotho-Eval. They are established with pairwise comparison instead of absolute rating to achieve better inter-annotator agreement. Current metrics are found in poor correlation with human annotations on these datasets. To overcome their limitations, we propose a metric named FENSE, where we combine the strength of Sentence-BERT in capturing similarity, and a novel Error Detector to penalize erroneous sentences for robustness. On the newly established benchmarks, FENSE outperforms current metrics by 14-25% accuracy. Code, data and web demo available at: https://github.com/blmoistawinde/fense