 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVNN: A Measure-Valued Neural Network for Learning McKean-Vlasov Dynamics from Particle Data
Apr 01, 2026Collective behaviors that emerge from interactions are fundamental to numerous biological systems. To learn such interacting forces from observations, we introduce a measure-valued neural network that infers measure-dependent interaction (drift) terms directly from particle-trajectory observations. The proposed architecture generalizes standard neural networks to operate on probability measures by learning cylindrical features, using an embedding network that produces scalable distribution-to-vector representations. On the theory side, we establish well-posedness of the resulting dynamics and prove propagation-of-chaos for the associated interacting-particle system. We further show universal approximation and quantitative approximation rates under a low-dimensional measure-dependence assumption. Numerical experiments on first and second order systems, including deterministic and stochastic Motsch-Tadmor dynamics, two-dimensional attraction-repulsion aggregation, Cucker-Smale dynamics, and a hierarchical multi-group system, demonstrate accurate prediction and strong out-of-distribution generalization.
ChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
Mar 28, 2026Understanding charts requires models to jointly reason over geometric visual patterns, structured numerical data, and natural language -- a capability where current vision-language models (VLMs) remain limited. We introduce ChartNet, a high-quality, million-scale multimodal dataset designed to advance chart interpretation and reasoning. ChartNet leverages a novel code-guided synthesis pipeline to generate 1.5 million diverse chart samples spanning 24 chart types and 6 plotting libraries. Each sample consists of five aligned components: plotting code, rendered chart image, data table, natural language summary, and question-answering with reasoning, providing fine-grained cross-modal alignment. To capture the full spectrum of chart comprehension, ChartNet additionally includes specialized subsets encompassing human annotated data, real-world data, safety, and grounding. Moreover, a rigorous quality-filtering pipeline ensures visual fidelity, semantic accuracy, and diversity across chart representations. Fine-tuning on ChartNet consistently improves results across benchmarks, demonstrating its utility as large-scale supervision for multimodal models. As the largest open-source dataset of its kind, ChartNet aims to support the development of foundation models with robust and generalizable capabilities for data visualization understanding. The dataset is publicly available at https://huggingface.co/datasets/ibm-granite/ChartNet
Regularized Random Fourier Features and Finite Element Reconstruction for Operator Learning in Sobolev Space
Dec 19, 2025Operator learning is a data-driven approximation of mappings between infinite-dimensional function spaces, such as the solution operators of partial differential equations. Kernel-based operator learning can offer accurate, theoretically justified approximations that require less training than standard methods. However, they can become computationally prohibitive for large training sets and can be sensitive to noise. We propose a regularized random Fourier feature (RRFF) approach, coupled with a finite element reconstruction map (RRFF-FEM), for learning operators from noisy data. The method uses random features drawn from multivariate Student's $t$ distributions, together with frequency-weighted Tikhonov regularization that suppresses high-frequency noise. We establish high-probability bounds on the extreme singular values of the associated random feature matrix and show that when the number of features $N$ scales like $m \log m$ with the number of training samples $m$, the system is well-conditioned, which yields estimation and generalization guarantees. Detailed numerical experiments on benchmark PDE problems, including advection, Burgers', Darcy flow, Helmholtz, Navier-Stokes, and structural mechanics, demonstrate that RRFF and RRFF-FEM are robust to noise and achieve improved performance with reduced training time compared to the unregularized random feature model, while maintaining competitive accuracy relative to kernel and neural operator tests.
MF-Speech: Achieving Fine-Grained and Compositional Control in Speech Generation via Factor Disentanglement
Nov 19, 2025Generating expressive and controllable human speech is one of the core goals of generative artificial intelligence, but its progress has long been constrained by two fundamental challenges: the deep entanglement of speech factors and the coarse granularity of existing control mechanisms. To overcome these challenges, we have proposed a novel framework called MF-Speech, which consists of two core components: MF-SpeechEncoder and MF-SpeechGenerator. MF-SpeechEncoder acts as a factor purifier, adopting a multi-objective optimization strategy to decompose the original speech signal into highly pure and independent representations of content, timbre, and emotion. Subsequently, MF-SpeechGenerator functions as a conductor, achieving precise, composable and fine-grained control over these factors through dynamic fusion and Hierarchical Style Adaptive Normalization (HSAN). Experiments demonstrate that in the highly challenging multi-factor compositional speech generation task, MF-Speech significantly outperforms current state-of-the-art methods, achieving a lower word error rate (WER=4.67%), superior style control (SECS=0.5685, Corr=0.68), and the highest subjective evaluation scores(nMOS=3.96, sMOS_emotion=3.86, sMOS_style=3.78). Furthermore, the learned discrete factors exhibit strong transferability, demonstrating their significant potential as a general-purpose speech representation.
An Adaptive Differential Privacy Method Based on Federated Learning
Aug 13, 2024

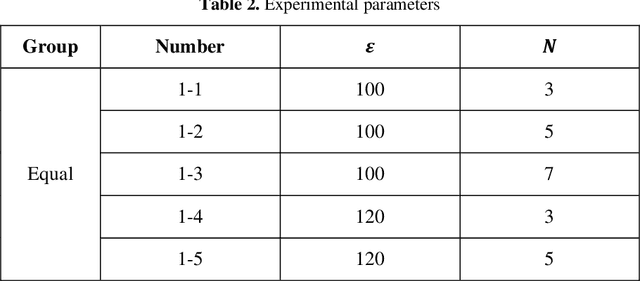

Differential privacy is one of the methods to solve the problem of privacy protection in federated learning. Setting the same privacy budget for each round will result in reduced accuracy in training. The existing methods of the adjustment of privacy budget consider fewer influencing factors and tend to ignore the boundaries, resulting in unreasonable privacy budgets. Therefore, we proposed an adaptive differential privacy method based on federated learning. The method sets the adjustment coefficient and scoring function according to accuracy, loss, training rounds, and the number of datasets and clients. And the privacy budget is adjusted based on them. Then the local model update is processed according to the scaling factor and the noise. Fi-nally, the server aggregates the noised local model update and distributes the noised global model. The range of parameters and the privacy of the method are analyzed. Through the experimental evaluation, it can reduce the privacy budget by about 16%, while the accuracy remains roughly the same.