 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Training Quantization for Vision Transformer
Jun 27, 2021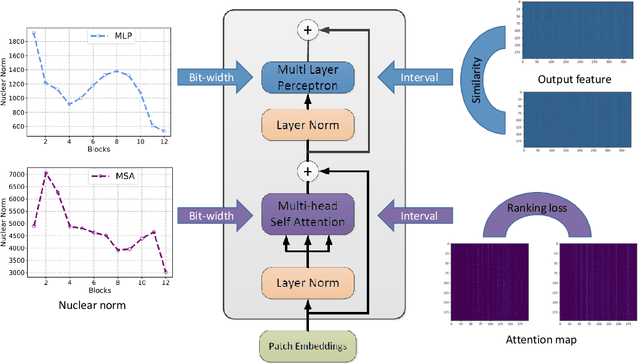

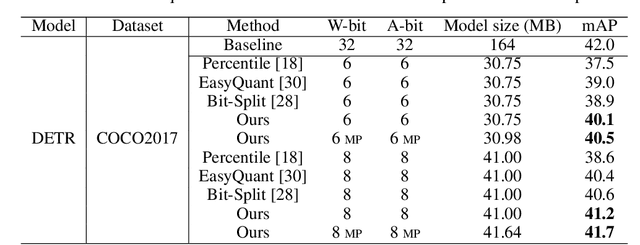

Recently, transformer has achieved remarkable performance on a variety of computer vision applications. Compared with mainstream convolutional neural networks, vision transformers are often of sophisticated architectures for extracting powerful feature representations, which are more difficult to be developed on mobile devices. In this paper, we present an effective post-training quantization algorithm for reducing the memory storage and computational costs of vision transformers. Basically, the quantization task can be regarded as finding the optimal low-bit quantization intervals for weights and inputs, respectively. To preserve the functionality of the attention mechanism, we introduce a ranking loss into the conventional quantization objective that aims to keep the relative order of the self-attention results after quantization. Moreover, we thoroughly analyze the relationship between quantization loss of different layers and the feature diversity, and explore a mixed-precision quantization scheme by exploiting the nuclear norm of each attention map and output feature. The effectiveness of the proposed method is verified on several benchmark models and datasets, which outperforms the state-of-the-art post-training quantization algorithms. For instance, we can obtain an 81.29\% top-1 accuracy using DeiT-B model on ImageNet dataset with about 8-bit quantization.
Rate Distortion Characteristic Modeling for Neural Image Compression
Jun 24, 2021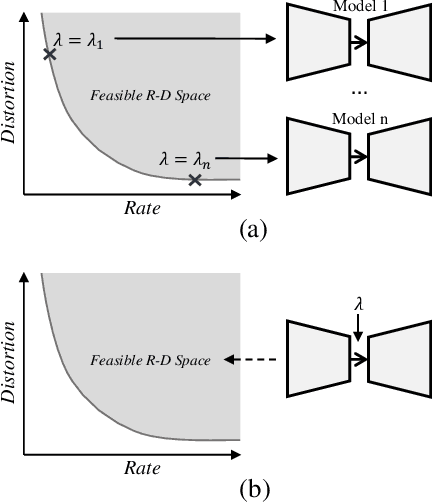

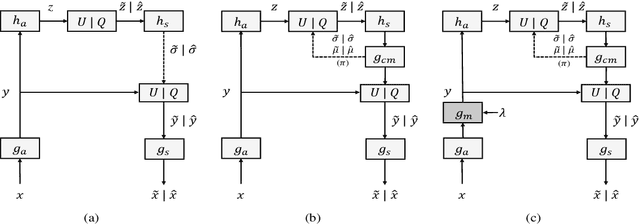
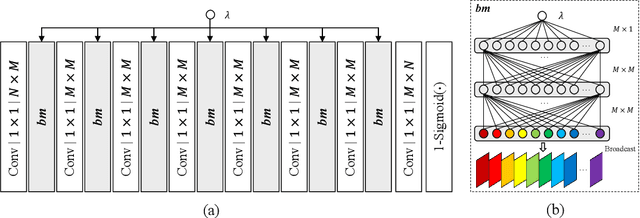
End-to-end optimization capability offers neural image compression (NIC) superior lossy compression performance. However, distinct models are required to be trained to reach different points in the rate-distortion (R-D) space. In this paper, we consider the problem of R-D characteristic analysis and modeling for NIC. We make efforts to formulate the essential mathematical functions to describe the R-D behavior of NIC using deep network and statistical modeling. Thus continuous bit-rate points could be elegantly realized by leveraging such model via a single trained network. In this regard, we propose a plugin-in module to learn the relationship between the target bit-rate and the binary representation for the latent variable of auto-encoder. Furthermore, we model the rate and distortion characteristic of NIC as a function of the coding parameter $\lambda$ respectively. Our experiments show our proposed method is easy to adopt and obtains competitive coding performance with fixed-rate coding approaches, which would benefit the practical deployment of NIC. In addition, the proposed model could be applied to NIC rate control with limited bit-rate error using a single network.
Progressive Stage-wise Learning for Unsupervised Feature Representation Enhancement
Jun 11, 2021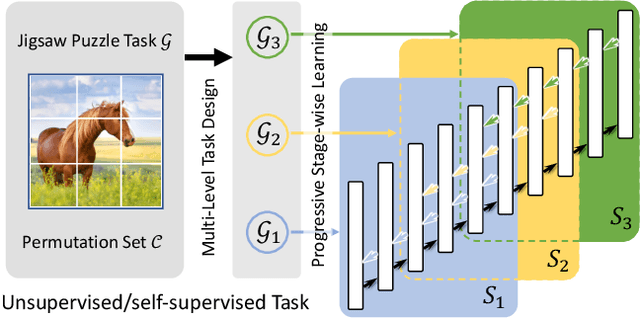

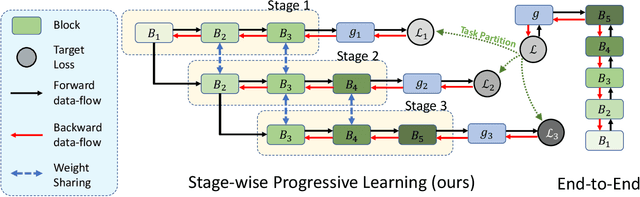
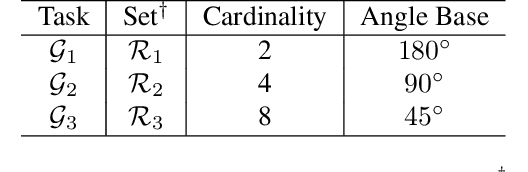
Unsupervised learning methods have recently shown their competitiveness against supervised training. Typically, these methods use a single objective to train the entire network. But one distinct advantage of unsupervised over supervised learning is that the former possesses more variety and freedom in designing the objective. In this work, we explore new dimensions of unsupervised learning by proposing the Progressive Stage-wise Learning (PSL) framework. For a given unsupervised task, we design multilevel tasks and define different learning stages for the deep network. Early learning stages are forced to focus on lowlevel tasks while late stages are guided to extract deeper information through harder tasks. We discover that by progressive stage-wise learning, unsupervised feature representation can be effectively enhanced. Our extensive experiments show that PSL consistently improves results for the leading unsupervised learning methods.
Recent Standard Development Activities on Video Coding for Machines
May 26, 2021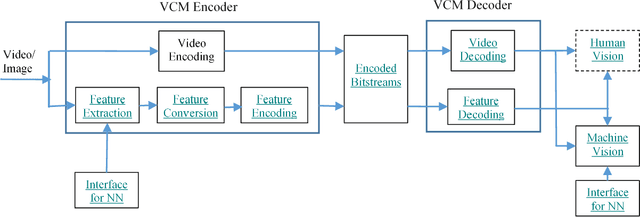
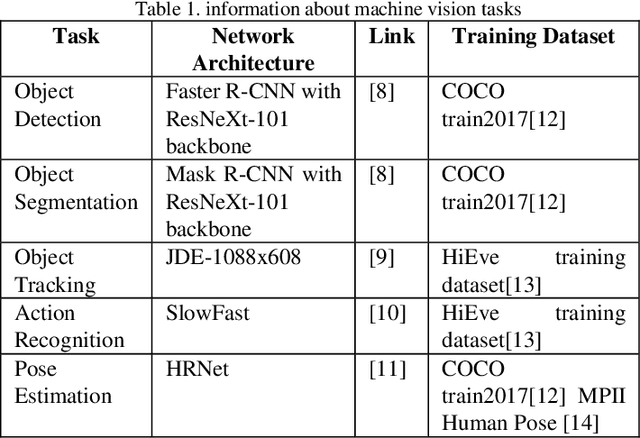

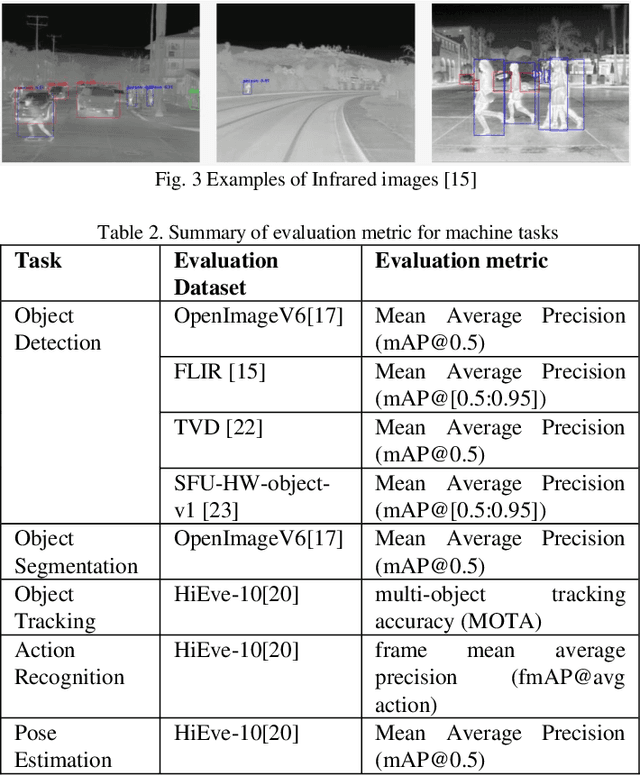
In recent years, video data has dominated internet traffic and becomes one of the major data formats. With the emerging 5G and internet of things (IoT) technologies, more and more videos are generated by edge devices, sent across networks, and consumed by machines. The volume of video consumed by machine is exceeding the volume of video consumed by humans. Machine vision tasks include object detection, segmentation, tracking, and other machine-based applications, which are quite different from those for human consumption. On the other hand, due to large volumes of video data, it is essential to compress video before transmission. Thus, efficient video coding for machines (VCM) has become an important topic in academia and industry. In July 2019, the international standardization organization, i.e., MPEG, created an Ad-Hoc group named VCM to study the requirements for potential standardization work. In this paper, we will address the recent development activities in the MPEG VCM group. Specifically, we will first provide an overview of the MPEG VCM group including use cases, requirements, processing pipelines, plan for potential VCM standards, followed by the evaluation framework including machine-vision tasks, dataset, evaluation metrics, and anchor generation. We then introduce technology solutions proposed so far and discuss the recent responses to the Call for Evidence issued by MPEG VCM group.
Sub-sampled Cross-component Prediction for Emerging Video Coding Standards
Dec 30, 2020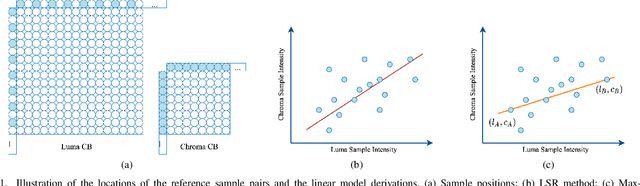
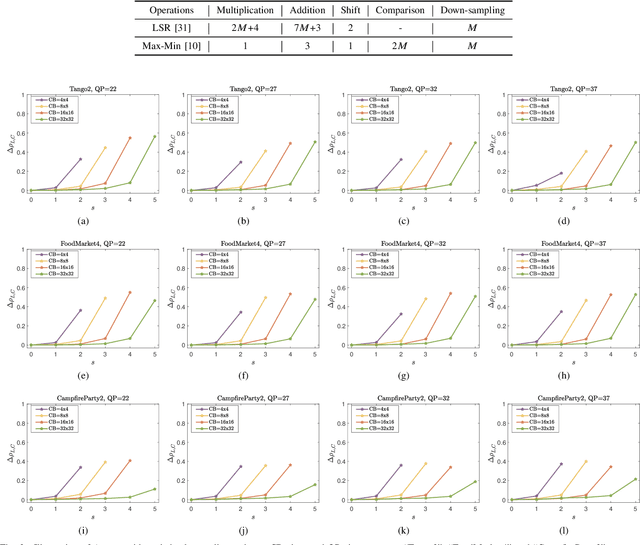
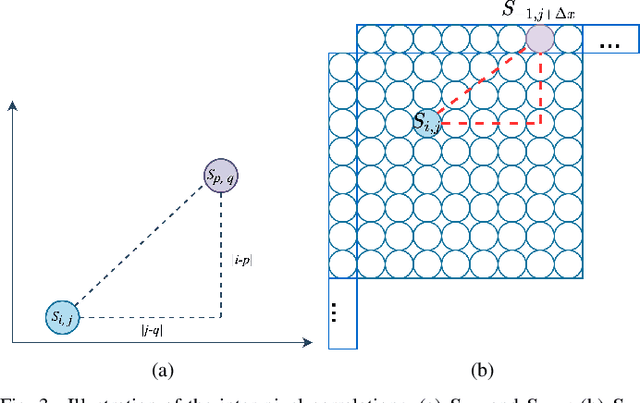

Cross-component linear model (CCLM) prediction has been repeatedly proven to be effective in reducing the inter-channel redundancies in video compression. Essentially speaking, the linear model is identically trained by employing accessible luma and chroma reference samples at both encoder and decoder, elevating the level of operational complexity due to the least square regression or max-min based model parameter derivation. In this paper, we investigate the capability of the linear model in the context of sub-sampled based cross-component correlation mining, as a means of significantly releasing the operation burden and facilitating the hardware and software design for both encoder and decoder. In particular, the sub-sampling ratios and positions are elaborately designed by exploiting the spatial correlation and the inter-channel correlation. Extensive experiments verify that the proposed method is characterized by its simplicity in operation and robustness in terms of rate-distortion performance, leading to the adoption by Versatile Video Coding (VVC) standard and the third generation of Audio Video Coding Standard (AVS3).
Intrinsic Temporal Regularization for High-resolution Human Video Synthesis
Dec 11, 2020
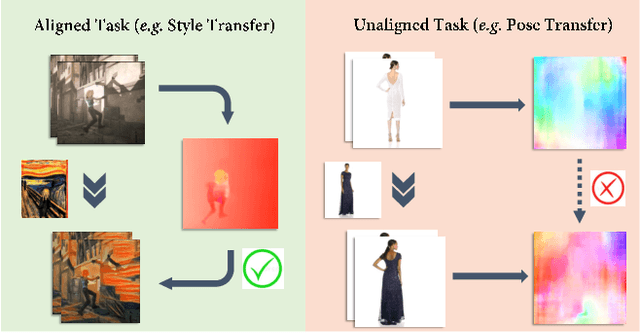


Temporal consistency is crucial for extending image processing pipelines to the video domain, which is often enforced with flow-based warping error over adjacent frames. Yet for human video synthesis, such scheme is less reliable due to the misalignment between source and target video as well as the difficulty in accurate flow estimation. In this paper, we propose an effective intrinsic temporal regularization scheme to mitigate these issues, where an intrinsic confidence map is estimated via the frame generator to regulate motion estimation via temporal loss modulation. This creates a shortcut for back-propagating temporal loss gradients directly to the front-end motion estimator, thus improving training stability and temporal coherence in output videos. We apply our intrinsic temporal regulation to single-image generator, leading to a powerful "INTERnet" capable of generating $512\times512$ resolution human action videos with temporal-coherent, realistic visual details. Extensive experiments demonstrate the superiority of proposed INTERnet over several competitive baselines.
Pre-Trained Image Processing Transformer
Dec 03, 2020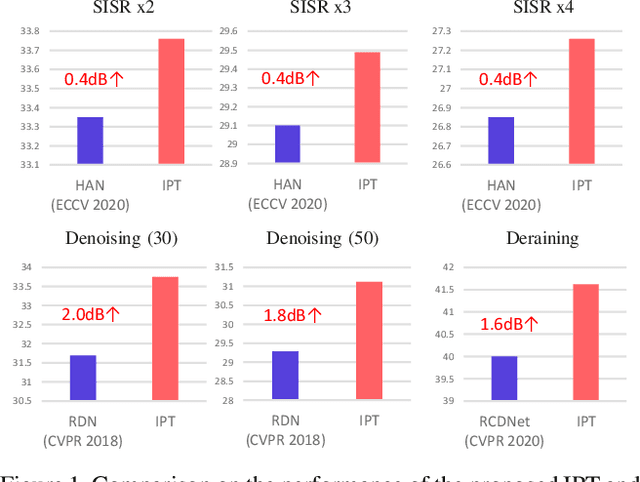

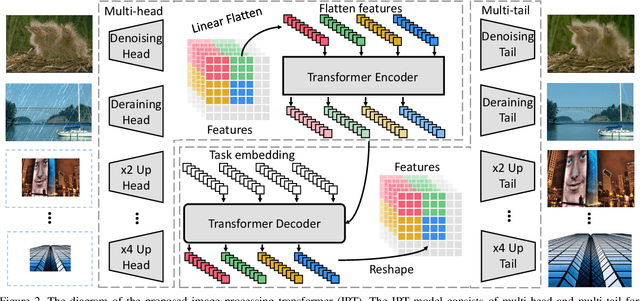
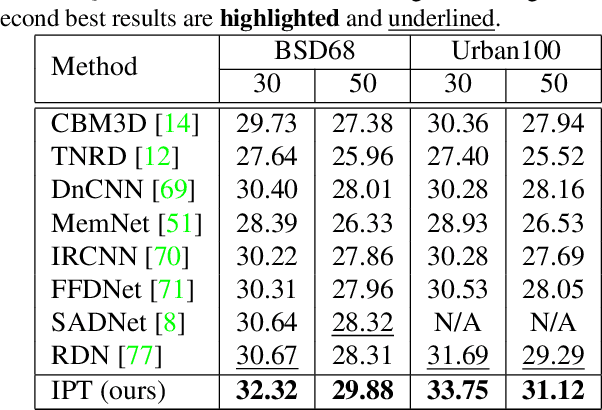
As the computing power of modern hardware is increasing strongly, pre-trained deep learning models (e.g., BERT, GPT-3) learned on large-scale datasets have shown their effectiveness over conventional methods. The big progress is mainly contributed to the representation ability of transformer and its variant architectures. In this paper, we study the low-level computer vision task (e.g., denoising, super-resolution and deraining) and develop a new pre-trained model, namely, image processing transformer (IPT). To maximally excavate the capability of transformer, we present to utilize the well-known ImageNet benchmark for generating a large amount of corrupted image pairs. The IPT model is trained on these images with multi-heads and multi-tails. In addition, the contrastive learning is introduced for well adapting to different image processing tasks. The pre-trained model can therefore efficiently employed on desired task after fine-tuning. With only one pre-trained model, IPT outperforms the current state-of-the-art methods on various low-level benchmarks.
Deinterlacing Network for Early Interlaced Videos
Nov 27, 2020

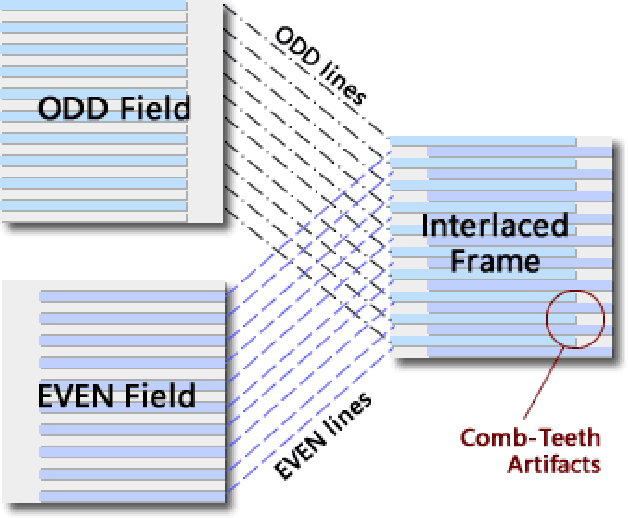
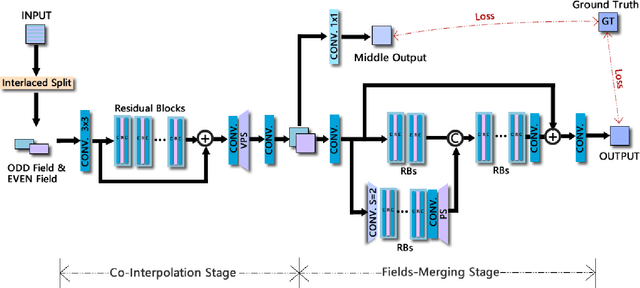
With the rapid development of image restoration techniques, high-definition reconstruction of early videos has achieved impressive results. However, there are few studies about the interlacing artifacts that often appear in early videos and significantly affect visual perception. Traditional deinterlacing approaches are mainly focused on early interlacing scanning systems and thus cannot handle the complex and complicated artifacts in real-world early interlaced videos. Hence, this paper proposes a specific deinterlacing network (DIN), which is motivated by the traditional deinterlacing strategy. The proposed DIN consists of two stages, i.e., a cooperative vertical interpolation stage for split fields, and a merging stage that is applied to perceive movements and remove ghost artifacts. Experimental results demonstrate that the proposed method can effectively remove complex artifacts in early interlaced videos.
Implicit Subspace Prior Learning for Dual-Blind Face Restoration
Oct 12, 2020
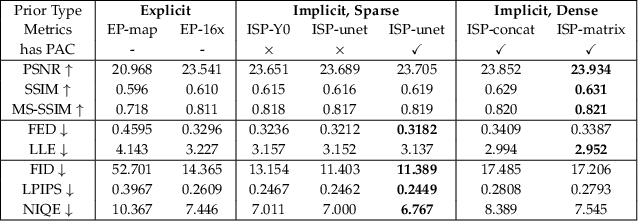


Face restoration is an inherently ill-posed problem, where additional prior constraints are typically considered crucial for mitigating such pathology. However, real-world image prior are often hard to simulate with precise mathematical models, which inevitably limits the performance and generalization ability of existing prior-regularized restoration methods. In this paper, we study the problem of face restoration under a more practical ``dual blind'' setting, i.e., without prior assumptions or hand-crafted regularization terms on the degradation profile or image contents. To this end, a novel implicit subspace prior learning (ISPL) framework is proposed as a generic solution to dual-blind face restoration, with two key elements: 1) an implicit formulation to circumvent the ill-defined restoration mapping and 2) a subspace prior decomposition and fusion mechanism to dynamically handle inputs at varying degradation levels with consistent high-quality restoration results. Experimental results demonstrate significant perception-distortion improvement of ISPL against existing state-of-the-art methods for a variety of restoration subtasks, including a 3.69db PSNR and 45.8% FID gain against ESRGAN, the 2018 NTIRE SR challenge winner. Overall, we prove that it is possible to capture and utilize prior knowledge without explicitly formulating it, which will help inspire new research paradigms towards low-level vision tasks.
Progressive Multi-Scale Residual Network for Single Image Super-Resolution
Jul 19, 2020

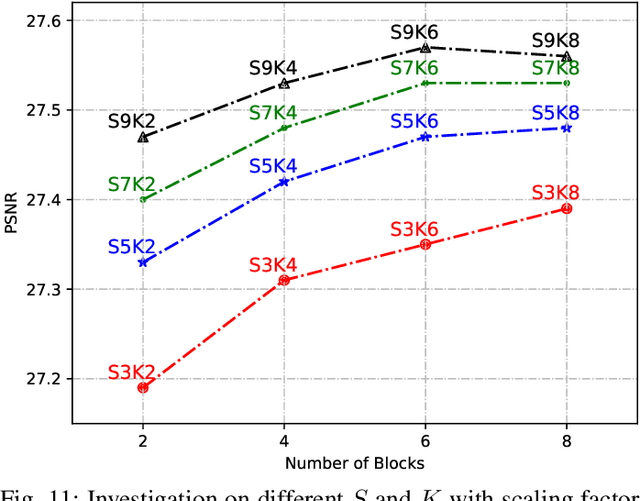
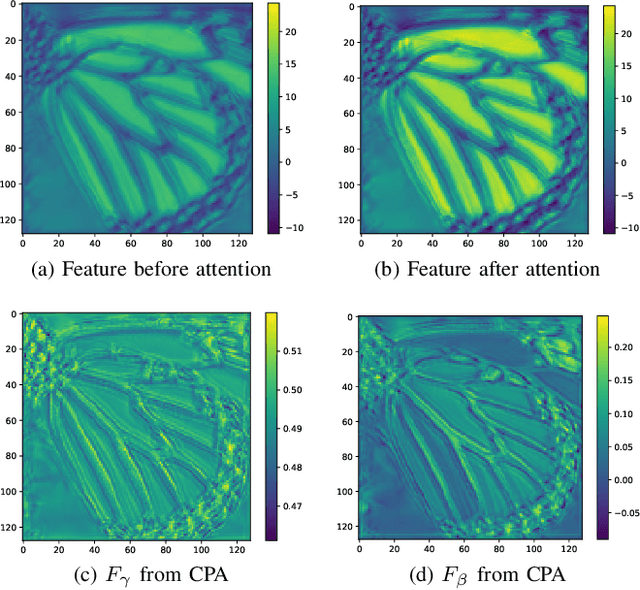
Super-resolution is a classical issue in image restoration field. In recent years, deep learning methods have achieved significant success in super-resolution topic, which concentrate on different elaborate network designs to exploit the image features more effectively. However, most of the networks focus on increasing the depth or width for superior capacities with a large number of parameters, which cause a high computation complexity cost and seldom focus on the inherent correlation of different features. This paper proposes a progressive multi-scale residual network (PMRN) for single image super-resolution problem by sequentially exploiting features with restricted parameters. Specifically, we design a progressive multi-scale residual block (PMRB) to progressively explore the multi-scale features with different layer combinations, aiming to consider the correlations of different scales. The combinations for feature exploitation are defined in a recursive fashion for introducing the non-linearity and better feature representation with limited parameters. Furthermore, we investigate a joint channel-wise and pixel-wise attention mechanism for comprehensive correlation exploration, termed as CPA, which is utilized in PMRB by considering both scale and bias factors for features in parallel. Experimental results show that proposed PMRN recovers structural textures more effectively with superior PSNR/SSIM results than other lightweight works. The extension model PMRN+ with self-ensemble achieves competitive or better results than large networks with much fewer parameters and lower computation complexity.