 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Pedestrian Detection
Apr 26, 2021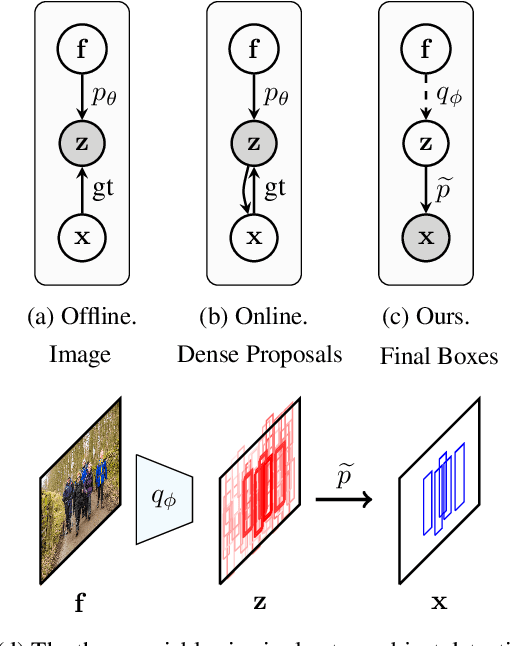
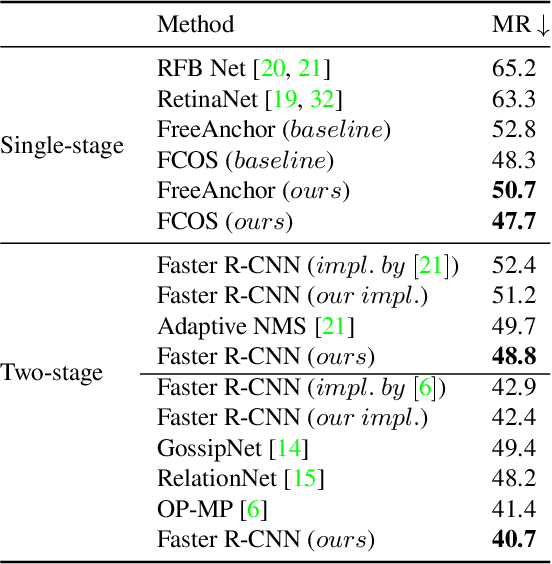
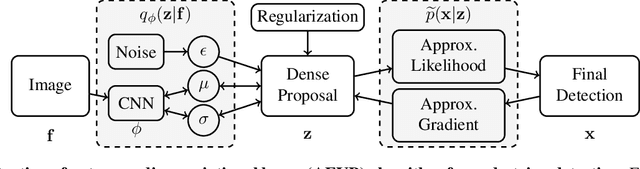
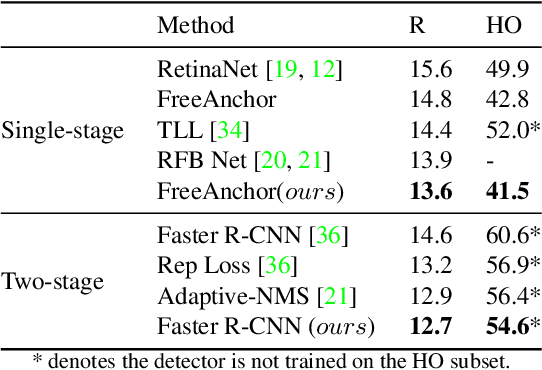
Pedestrian detection in a crowd is a challenging task due to a high number of mutually-occluding human instances, which brings ambiguity and optimization difficulties to the current IoU-based ground truth assignment procedure in classical object detection methods. In this paper, we develop a unique perspective of pedestrian detection as a variational inference problem. We formulate a novel and efficient algorithm for pedestrian detection by modeling the dense proposals as a latent variable while proposing a customized Auto Encoding Variational Bayes (AEVB) algorithm. Through the optimization of our proposed algorithm, a classical detector can be fashioned into a variational pedestrian detector. Experiments conducted on CrowdHuman and CityPersons datasets show that the proposed algorithm serves as an efficient solution to handle the dense pedestrian detection problem for the case of single-stage detectors. Our method can also be flexibly applied to two-stage detectors, achieving notable performance enhancement.
Delving into the Cyclic Mechanism in Semi-supervised Video Object Segmentation
Oct 23, 2020
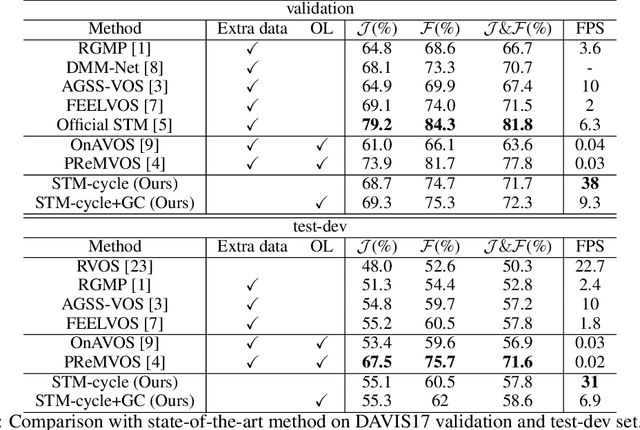
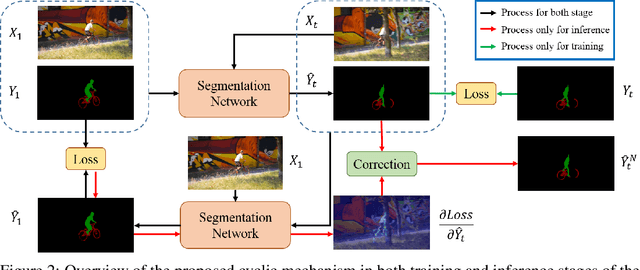
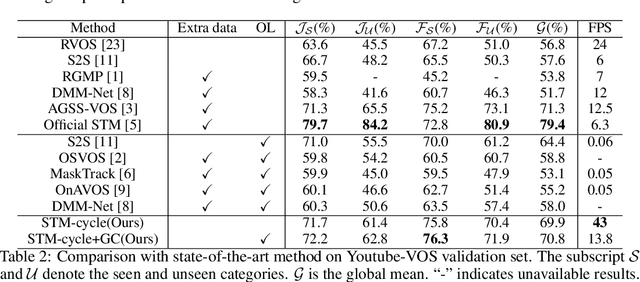
In this paper, we address several inadequacies of current video object segmentation pipelines. Firstly, a cyclic mechanism is incorporated to the standard semi-supervised process to produce more robust representations. By relying on the accurate reference mask in the starting frame, we show that the error propagation problem can be mitigated. Next, we introduce a simple gradient correction module, which extends the offline pipeline to an online method while maintaining the efficiency of the former. Finally we develop cycle effective receptive field (cycle-ERF) based on gradient correction to provide a new perspective into analyzing object-specific regions of interests. We conduct comprehensive experiments on challenging benchmarks of DAVIS17 and Youtube-VOS, demonstrating that the cyclic mechanism is beneficial to segmentation quality.
Discriminative Sounding Objects Localization via Self-supervised Audiovisual Matching
Oct 12, 2020
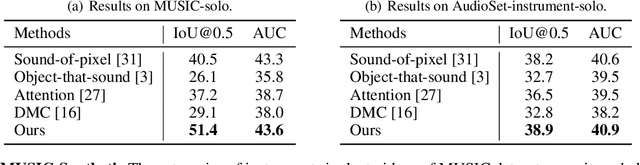
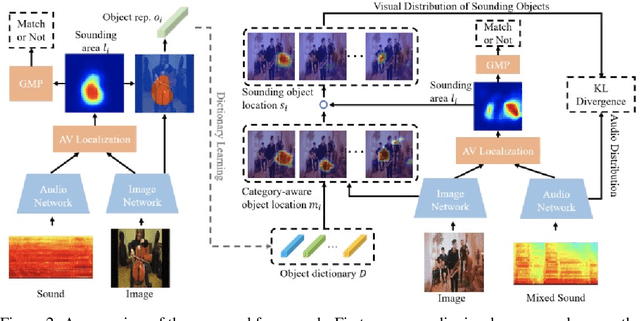
Discriminatively localizing sounding objects in cocktail-party, i.e., mixed sound scenes, is commonplace for humans, but still challenging for machines. In this paper, we propose a two-stage learning framework to perform self-supervised class-aware sounding object localization. First, we propose to learn robust object representations by aggregating the candidate sound localization results in the single source scenes. Then, class-aware object localization maps are generated in the cocktail-party scenarios by referring the pre-learned object knowledge, and the sounding objects are accordingly selected by matching audio and visual object category distributions, where the audiovisual consistency is viewed as the self-supervised signal. Experimental results in both realistic and synthesized cocktail-party videos demonstrate that our model is superior in filtering out silent objects and pointing out the location of sounding objects of different classes. Code is available at https://github.com/DTaoo/Discriminative-Sounding-Objects-Localization.
Finding Action Tubes with a Sparse-to-Dense Framework
Aug 30, 2020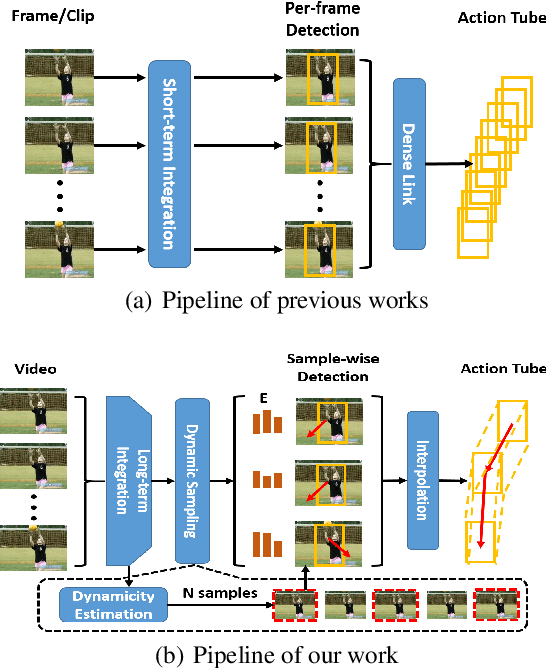

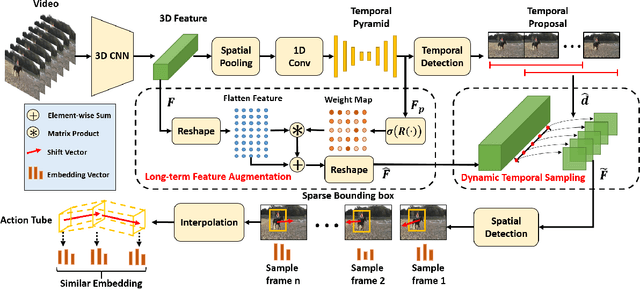
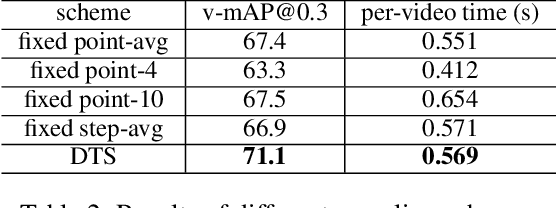
The task of spatial-temporal action detection has attracted increasing attention among researchers. Existing dominant methods solve this problem by relying on short-term information and dense serial-wise detection on each individual frames or clips. Despite their effectiveness, these methods showed inadequate use of long-term information and are prone to inefficiency. In this paper, we propose for the first time, an efficient framework that generates action tube proposals from video streams with a single forward pass in a sparse-to-dense manner. There are two key characteristics in this framework: (1) Both long-term and short-term sampled information are explicitly utilized in our spatiotemporal network, (2) A new dynamic feature sampling module (DTS) is designed to effectively approximate the tube output while keeping the system tractable. We evaluate the efficacy of our model on the UCF101-24, JHMDB-21 and UCFSports benchmark datasets, achieving promising results that are competitive to state-of-the-art methods. The proposed sparse-to-dense strategy rendered our framework about 7.6 times more efficient than the nearest competitor.
CFAD: Coarse-to-Fine Action Detector for Spatiotemporal Action Localization
Aug 19, 2020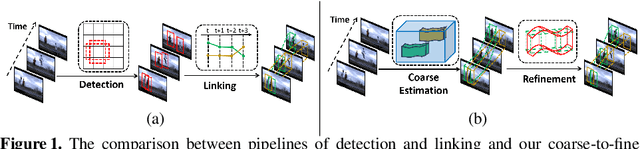
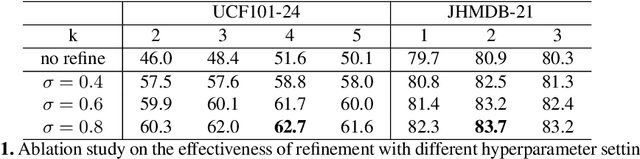
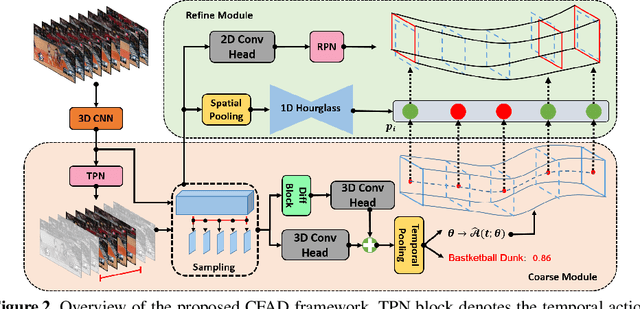
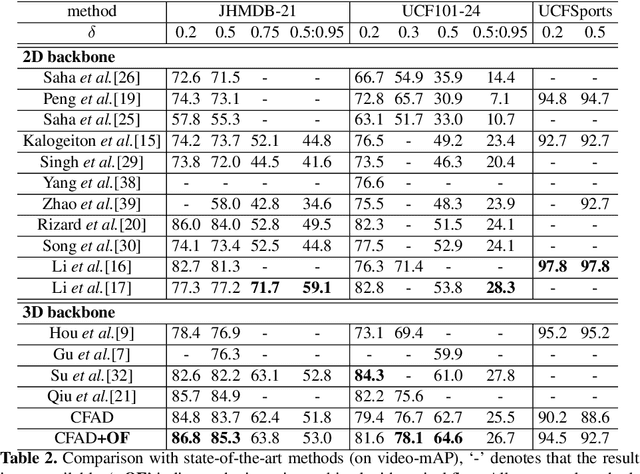
Most current pipelines for spatio-temporal action localization connect frame-wise or clip-wise detection results to generate action proposals, where only local information is exploited and the efficiency is hindered by dense per-frame localization. In this paper, we propose Coarse-to-Fine Action Detector (CFAD),an original end-to-end trainable framework for efficient spatio-temporal action localization. The CFAD introduces a new paradigm that first estimates coarse spatio-temporal action tubes from video streams, and then refines the tubes' location based on key timestamps. This concept is implemented by two key components, the Coarse and Refine Modules in our framework. The parameterized modeling of long temporal information in the Coarse Module helps obtain accurate initial tube estimation, while the Refine Module selectively adjusts the tube location under the guidance of key timestamps. Against other methods, theproposed CFAD achieves competitive results on action detection benchmarks of UCF101-24, UCFSports and JHMDB-21 with inference speed that is 3.3x faster than the nearest competitors.
AP-Loss for Accurate One-Stage Object Detection
Aug 17, 2020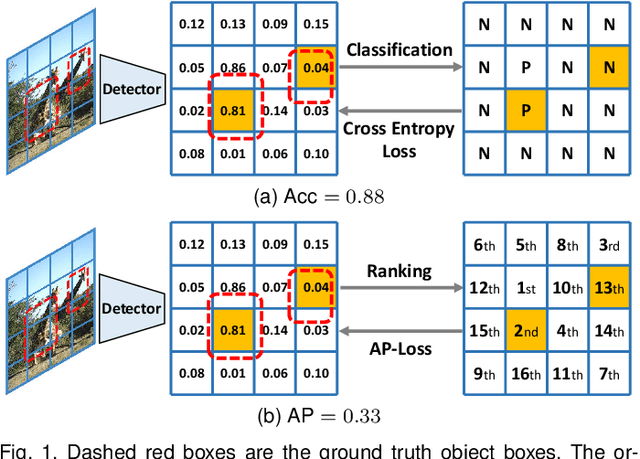

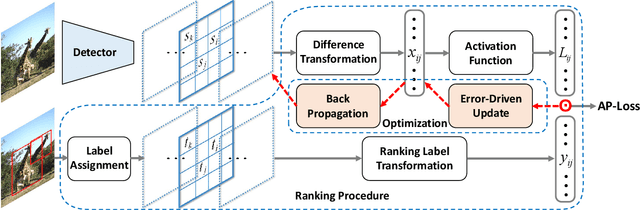

One-stage object detectors are trained by optimizing classification-loss and localization-loss simultaneously, with the former suffering much from extreme foreground-background class imbalance issue due to the large number of anchors. This paper alleviates this issue by proposing a novel framework to replace the classification task in one-stage detectors with a ranking task, and adopting the Average-Precision loss (AP-loss) for the ranking problem. Due to its non-differentiability and non-convexity, the AP-loss cannot be optimized directly. For this purpose, we develop a novel optimization algorithm, which seamlessly combines the error-driven update scheme in perceptron learning and backpropagation algorithm in deep networks. We provide in-depth analyses on the good convergence property and computational complexity of the proposed algorithm, both theoretically and empirically. Experimental results demonstrate notable improvement in addressing the imbalance issue in object detection over existing AP-based optimization algorithms. An improved state-of-the-art performance is achieved in one-stage detectors based on AP-loss over detectors using classification-losses on various standard benchmarks. The proposed framework is also highly versatile in accommodating different network architectures. Code is available at https://github.com/cccorn/AP-loss .
PIoU Loss: Towards Accurate Oriented Object Detection in Complex Environments
Jul 19, 2020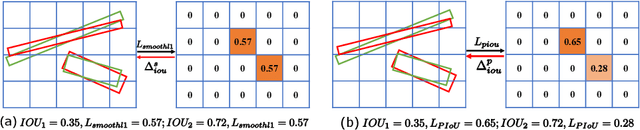
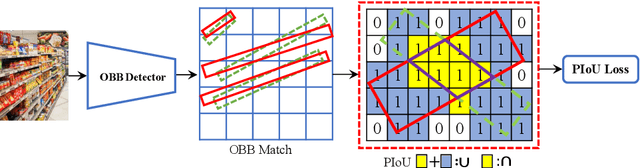
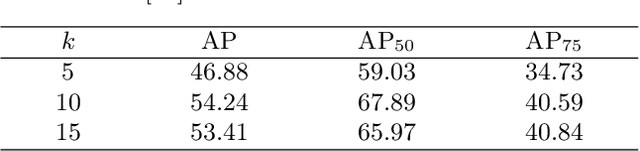
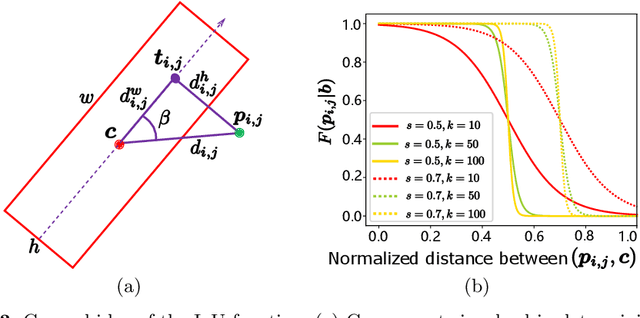
Object detection using an oriented bounding box (OBB) can better target rotated objects by reducing the overlap with background areas. Existing OBB approaches are mostly built on horizontal bounding box detectors by introducing an additional angle dimension optimized by a distance loss. However, as the distance loss only minimizes the angle error of the OBB and that it loosely correlates to the IoU, it is insensitive to objects with high aspect ratios. Therefore, a novel loss, Pixels-IoU (PIoU) Loss, is formulated to exploit both the angle and IoU for accurate OBB regression. The PIoU loss is derived from IoU metric with a pixel-wise form, which is simple and suitable for both horizontal and oriented bounding box. To demonstrate its effectiveness, we evaluate the PIoU loss on both anchor-based and anchor-free frameworks. The experimental results show that PIoU loss can dramatically improve the performance of OBB detectors, particularly on objects with high aspect ratios and complex backgrounds. Besides, previous evaluation datasets did not include scenarios where the objects have high aspect ratios, hence a new dataset, Retail50K, is introduced to encourage the community to adapt OBB detectors for more complex environments.
Multiple Sound Sources Localization from Coarse to Fine
Jul 14, 2020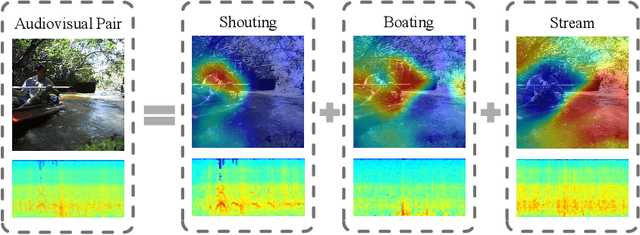
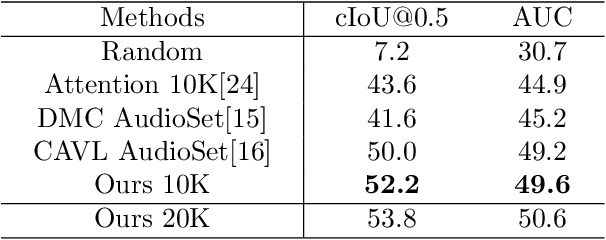


How to visually localize multiple sound sources in unconstrained videos is a formidable problem, especially when lack of the pairwise sound-object annotations. To solve this problem, we develop a two-stage audiovisual learning framework that disentangles audio and visual representations of different categories from complex scenes, then performs cross-modal feature alignment in a coarse-to-fine manner. Our model achieves state-of-the-art results on public dataset of localization, as well as considerable performance on multi-source sound localization in complex scenes. We then employ the localization results for sound separation and obtain comparable performance to existing methods. These outcomes demonstrate our model's ability in effectively aligning sounds with specific visual sources. Code is available at https://github.com/shvdiwnkozbw/Multi-Source-Sound-Localization
Human in Events: A Large-Scale Benchmark for Human-centric Video Analysis in Complex Events
May 19, 2020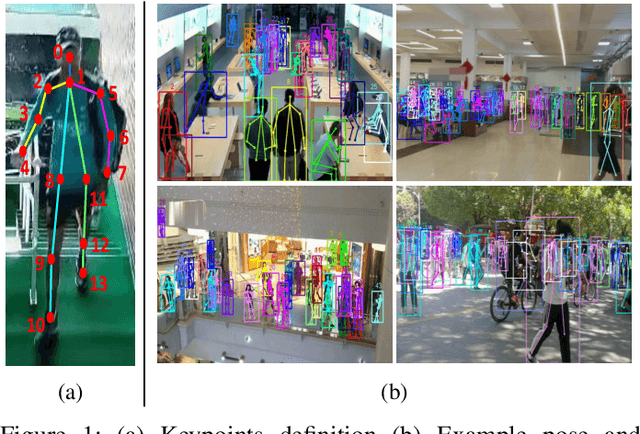
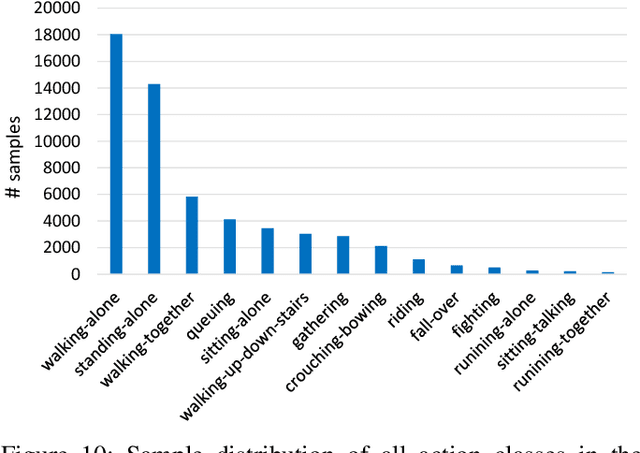
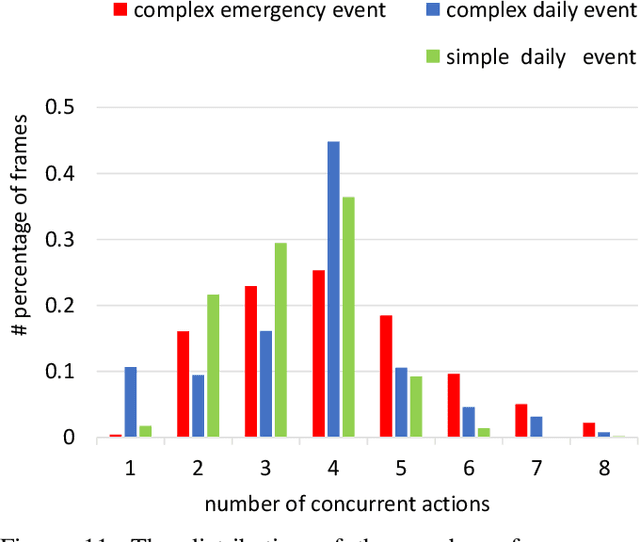
Along with the development of the modern smart city, human-centric video analysis is encountering the challenge of diverse and complex events in real scenes. A complex event relates to dense crowds, anomalous individual, or collective behavior. However, limited by the scale of available surveillance video datasets, few existing human analysis approaches report their performances on such complex events. To this end, we present a new large-scale dataset, named Human-in-Events or HiEve (human-centric video analysis in complex events), for understanding human motions, poses, and actions in a variety of realistic events, especially crowd & complex events. It contains a record number of poses (>1M), the largest number of action labels (>56k) for complex events, and one of the largest number of trajectories lasting for long terms (with average trajectory length >480). Besides, an online evaluation server is built for researchers to evaluate their approaches. Furthermore, we conduct extensive experiments on recent video analysis approaches, demonstrating that the HiEve is a challenging dataset for human-centric video analysis. We expect that the dataset will advance the development of cutting-edge techniques in human-centric analysis and the understanding of complex events. The dataset is available at http://humaninevents.org
TRP: Trained Rank Pruning for Efficient Deep Neural Networks
Apr 30, 2020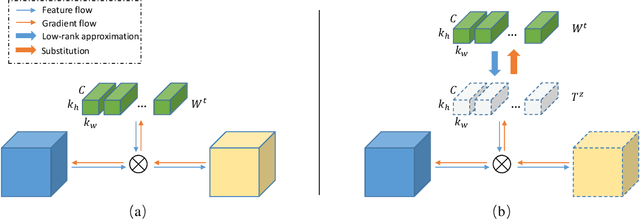
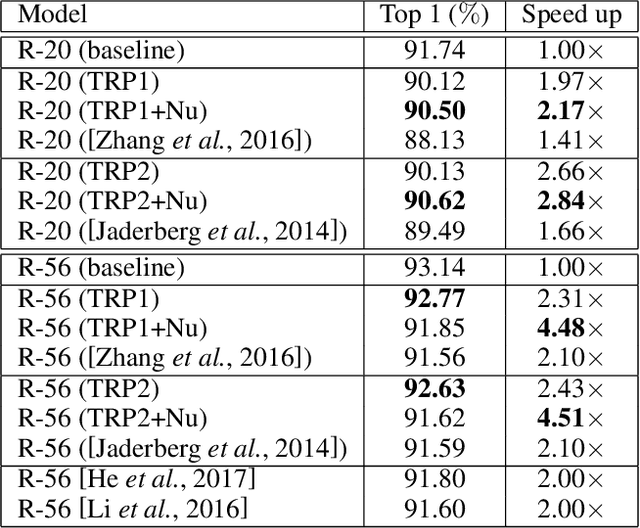
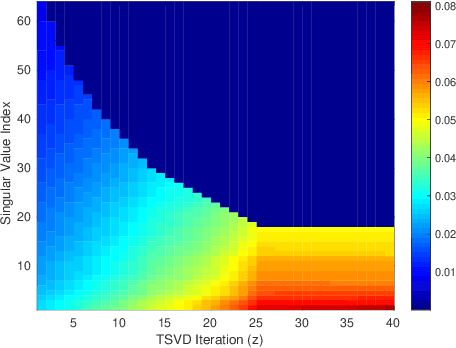
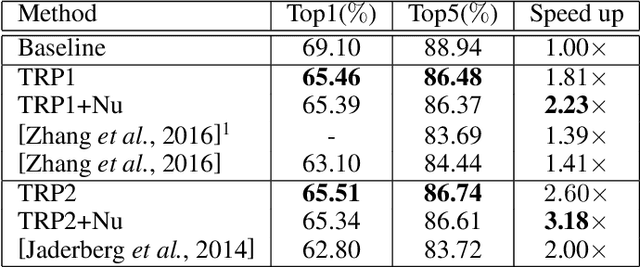
To enable DNNs on edge devices like mobile phones, low-rank approximation has been widely adopted because of its solid theoretical rationale and efficient implementations. Several previous works attempted to directly approximate a pretrained model by low-rank decomposition; however, small approximation errors in parameters can ripple over a large prediction loss. As a result, performance usually drops significantly and a sophisticated effort on fine-tuning is required to recover accuracy. Apparently, it is not optimal to separate low-rank approximation from training. Unlike previous works, this paper integrates low rank approximation and regularization into the training process. We propose Trained Rank Pruning (TRP), which alternates between low rank approximation and training. TRP maintains the capacity of the original network while imposing low-rank constraints during training. A nuclear regularization optimized by stochastic sub-gradient descent is utilized to further promote low rank in TRP. The TRP trained network inherently has a low-rank structure, and is approximated with negligible performance loss, thus eliminating the fine-tuning process after low rank decomposition. The proposed method is comprehensively evaluated on CIFAR-10 and ImageNet, outperforming previous compression methods using low rank approximation.