 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Domain-Adaptive Self-Supervised Learning for Clinical Voice-Based Disease Classification
Jan 29, 2026The human voice is a promising non-invasive digital biomarker, yet deep learning for voice-based health analysis is hindered by data scarcity and domain mismatch, where models pre-trained on general audio fail to capture the subtle pathological features characteristic of clinical voice data. To address these challenges, we investigate domain-adaptive self-supervised learning (SSL) with Masked Autoencoders (MAE) and demonstrate that standard configurations are suboptimal for health-related audio. Using the Bridge2AI-Voice dataset, a multi-institutional collection of pathological voices, we systematically examine three performance-critical factors: reconstruction loss (Mean Absolute Error vs. Mean Squared Error), normalization (patch-wise vs. global), and masking (random vs. content-aware). Our optimized design, which combines Mean Absolute Error (MA-Error) loss, patch-wise normalization, and content-aware masking, achieves a Macro F1 of $0.688 \pm 0.009$ (over 10 fine-tuning runs), outperforming a strong out-of-domain SSL baseline pre-trained on large-scale general audio, which has a Macro F1 of $0.663 \pm 0.011$. The results show that MA-Error loss improves robustness and content-aware masking boosts performance by emphasizing information-rich regions. These findings highlight the importance of component-level optimization in data-constrained medical applications that rely on audio data.
East: Efficient and Accurate Secure Transformer Framework for Inference
Aug 19, 2023



Transformer has been successfully used in practical applications, such as ChatGPT, due to its powerful advantages. However, users' input is leaked to the model provider during the service. With people's attention to privacy, privacy-preserving Transformer inference is on the demand of such services. Secure protocols for non-linear functions are crucial in privacy-preserving Transformer inference, which are not well studied. Thus, designing practical secure protocols for non-linear functions is hard but significant to model performance. In this work, we propose a framework \emph{East} to enable efficient and accurate secure Transformer inference. Firstly, we propose a new oblivious piecewise polynomial evaluation algorithm and apply it to the activation functions, which reduces the runtime and communication of GELU by over 1.5$\times$ and 2.5$\times$, compared to prior arts. Secondly, the secure protocols for softmax and layer normalization are carefully designed to faithfully maintain the desired functionality. Thirdly, several optimizations are conducted in detail to enhance the overall efficiency. We applied \emph{East} to BERT and the results show that the inference accuracy remains consistent with the plaintext inference without fine-tuning. Compared to Iron, we achieve about 1.8$\times$ lower communication within 1.2$\times$ lower runtime.
ERNIE 3.0 Tiny: Frustratingly Simple Method to Improve Task-Agnostic Distillation Generalization
Jan 09, 2023



Task-agnostic knowledge distillation attempts to address the problem of deploying large pretrained language model in resource-constrained scenarios by compressing a large pretrained model called teacher into a smaller one called student such that the student can be directly finetuned on downstream tasks and retains comparable performance. However, we empirically find that there is a generalization gap between the student and the teacher in existing methods. In this work, we show that we can leverage multi-task learning in task-agnostic distillation to advance the generalization of the resulted student. In particular, we propose Multi-task Infused Task-agnostic Knowledge Distillation (MITKD). We first enhance the teacher by multi-task training it on multiple downstream tasks and then perform distillation to produce the student. Experimental results demonstrate that our method yields a student with much better generalization, significantly outperforms existing baselines, and establishes a new state-of-the-art result on in-domain, out-domain, and low-resource datasets in the setting of task-agnostic distillation. Moreover, our method even exceeds an 8x larger BERT$_{\text{Base}}$ on SQuAD and four GLUE tasks. In addition, by combining ERNIE 3.0, our method achieves state-of-the-art results on 10 Chinese datasets.
Learning Weakly-Supervised Contrastive Representations
Feb 18, 2022



We argue that a form of the valuable information provided by the auxiliary information is its implied data clustering information. For instance, considering hashtags as auxiliary information, we can hypothesize that an Instagram image will be semantically more similar with the same hashtags. With this intuition, we present a two-stage weakly-supervised contrastive learning approach. The first stage is to cluster data according to its auxiliary information. The second stage is to learn similar representations within the same cluster and dissimilar representations for data from different clusters. Our empirical experiments suggest the following three contributions. First, compared to conventional self-supervised representations, the auxiliary-information-infused representations bring the performance closer to the supervised representations, which use direct downstream labels as supervision signals. Second, our approach performs the best in most cases, when comparing our approach with other baseline representation learning methods that also leverage auxiliary data information. Third, we show that our approach also works well with unsupervised constructed clusters (e.g., no auxiliary information), resulting in a strong unsupervised representation learning approach.
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Dec 23, 2021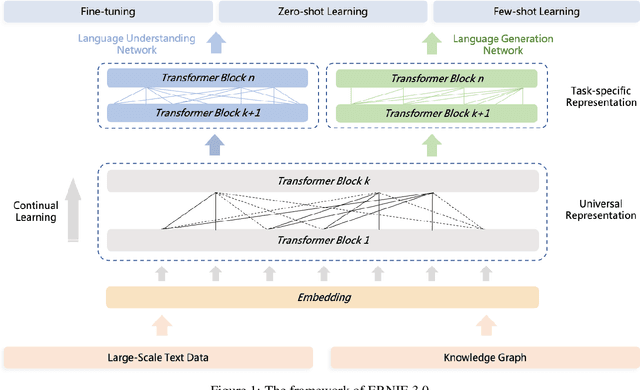
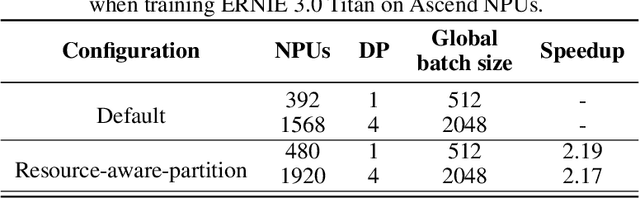
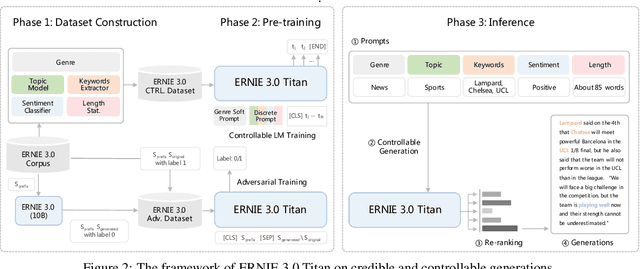
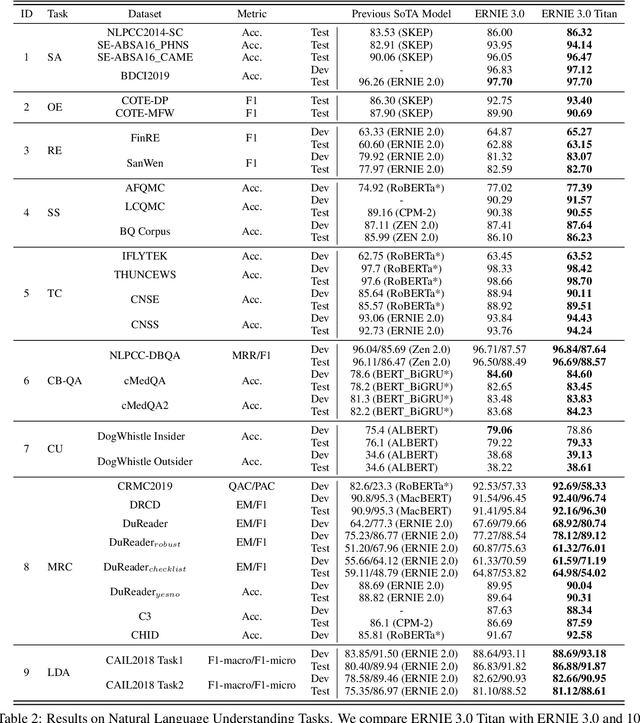
Pre-trained language models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. GPT-3 has shown that scaling up pre-trained language models can further exploit their enormous potential. A unified framework named ERNIE 3.0 was recently proposed for pre-training large-scale knowledge enhanced models and trained a model with 10 billion parameters. ERNIE 3.0 outperformed the state-of-the-art models on various NLP tasks. In order to explore the performance of scaling up ERNIE 3.0, we train a hundred-billion-parameter model called ERNIE 3.0 Titan with up to 260 billion parameters on the PaddlePaddle platform. Furthermore, we design a self-supervised adversarial loss and a controllable language modeling loss to make ERNIE 3.0 Titan generate credible and controllable texts. To reduce the computation overhead and carbon emission, we propose an online distillation framework for ERNIE 3.0 Titan, where the teacher model will teach students and train itself simultaneously. ERNIE 3.0 Titan is the largest Chinese dense pre-trained model so far. Empirical results show that the ERNIE 3.0 Titan outperforms the state-of-the-art models on 68 NLP datasets.
ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Jul 05, 2021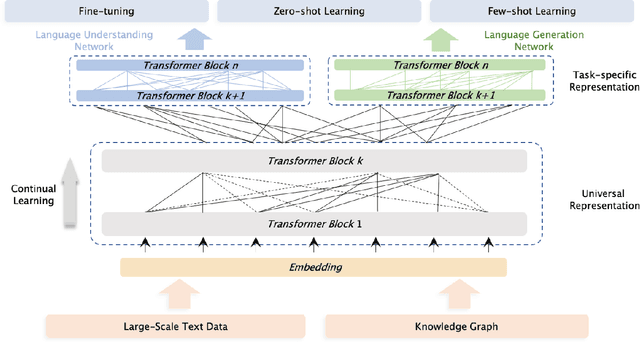

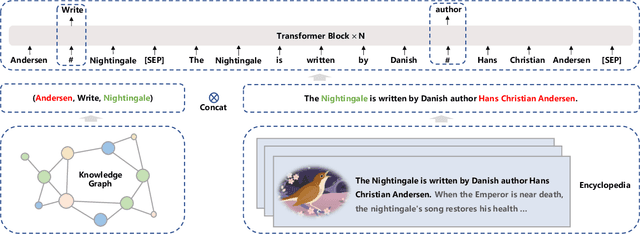
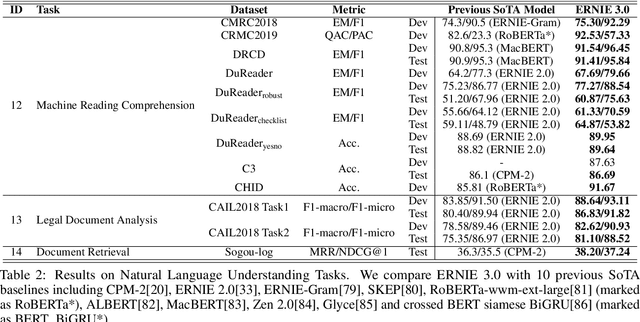
Pre-trained models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. Recent works such as T5 and GPT-3 have shown that scaling up pre-trained language models can improve their generalization abilities. Particularly, the GPT-3 model with 175 billion parameters shows its strong task-agnostic zero-shot/few-shot learning capabilities. Despite their success, these large-scale models are trained on plain texts without introducing knowledge such as linguistic knowledge and world knowledge. In addition, most large-scale models are trained in an auto-regressive way. As a result, this kind of traditional fine-tuning approach demonstrates relatively weak performance when solving downstream language understanding tasks. In order to solve the above problems, we propose a unified framework named ERNIE 3.0 for pre-training large-scale knowledge enhanced models. It fuses auto-regressive network and auto-encoding network, so that the trained model can be easily tailored for both natural language understanding and generation tasks with zero-shot learning, few-shot learning or fine-tuning. We trained the model with 10 billion parameters on a 4TB corpus consisting of plain texts and a large-scale knowledge graph. Empirical results show that the model outperforms the state-of-the-art models on 54 Chinese NLP tasks, and its English version achieves the first place on the SuperGLUE benchmark (July 3, 2021), surpassing the human performance by +0.8% (90.6% vs. 89.8%).
Integrating Auxiliary Information in Self-supervised Learning
Jun 05, 2021



This paper presents to integrate the auxiliary information (e.g., additional attributes for data such as the hashtags for Instagram images) in the self-supervised learning process. We first observe that the auxiliary information may bring us useful information about data structures: for instance, the Instagram images with the same hashtags can be semantically similar. Hence, to leverage the structural information from the auxiliary information, we present to construct data clusters according to the auxiliary information. Then, we introduce the Clustering InfoNCE (Cl-InfoNCE) objective that learns similar representations for augmented variants of data from the same cluster and dissimilar representations for data from different clusters. Our approach contributes as follows: 1) Comparing to conventional self-supervised representations, the auxiliary-information-infused self-supervised representations bring the performance closer to the supervised representations; 2) The presented Cl-InfoNCE can also work with unsupervised constructed clusters (e.g., k-means clusters) and outperform strong clustering-based self-supervised learning approaches, such as the Prototypical Contrastive Learning (PCL) method; 3) We show that Cl-InfoNCE may be a better approach to leverage the data clustering information, by comparing it to the baseline approach - learning to predict the clustering assignments with cross-entropy loss. For analysis, we connect the goodness of the learned representations with the statistical relationships: i) the mutual information between the labels and the clusters and ii) the conditional entropy of the clusters given the labels.
ERNIE-Tiny : A Progressive Distillation Framework for Pretrained Transformer Compression
Jun 04, 2021
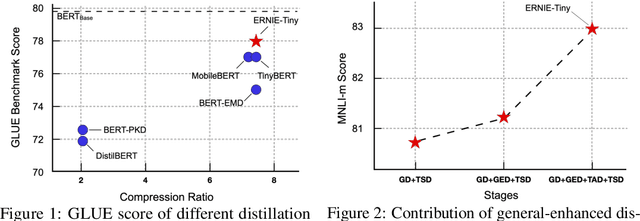
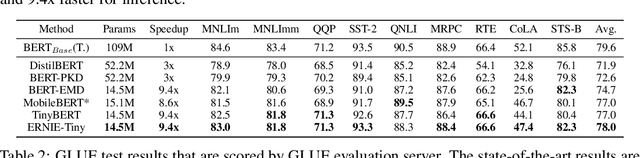
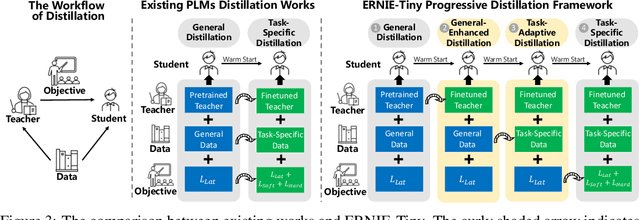
Pretrained language models (PLMs) such as BERT adopt a training paradigm which first pretrain the model in general data and then finetune the model on task-specific data, and have recently achieved great success. However, PLMs are notorious for their enormous parameters and hard to be deployed on real-life applications. Knowledge distillation has been prevailing to address this problem by transferring knowledge from a large teacher to a much smaller student over a set of data. We argue that the selection of thee three key components, namely teacher, training data, and learning objective, is crucial to the effectiveness of distillation. We, therefore, propose a four-stage progressive distillation framework ERNIE-Tiny to compress PLM, which varies the three components gradually from general level to task-specific level. Specifically, the first stage, General Distillation, performs distillation with guidance from pretrained teacher, gerenal data and latent distillation loss. Then, General-Enhanced Distillation changes teacher model from pretrained teacher to finetuned teacher. After that, Task-Adaptive Distillation shifts training data from general data to task-specific data. In the end, Task-Specific Distillation, adds two additional losses, namely Soft-Label and Hard-Label loss onto the last stage. Empirical results demonstrate the effectiveness of our framework and generalization gain brought by ERNIE-Tiny.In particular, experiments show that a 4-layer ERNIE-Tiny maintains over 98.0%performance of its 12-layer teacher BERT base on GLUE benchmark, surpassing state-of-the-art (SOTA) by 1.0% GLUE score with the same amount of parameters. Moreover, ERNIE-Tiny achieves a new compression SOTA on five Chinese NLP tasks, outperforming BERT base by 0.4% accuracy with 7.5x fewer parameters and9.4x faster inference speed.