 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Efficient Crack Segmentation with Task-Aligned Structural-Directional Modeling
May 29, 2026Recent crack segmentation methods often follow generic semantic segmentation designs, using stronger backbones, hybrid CNN-Transformer-Mamba encoders, and auxiliary enhancement branches. Although effective, this raises whether stronger generic feature mixing is the most suitable direction for crack segmentation. We instead formulate crack segmentation as sparse structural recovery. Cracks have limited category-level semantics but strong morphological regularities, being thin, sparse, anisotropic, locally fragmented, and easily confused with textures or shadows. Thus, the key bottleneck lies in preserving weak structural evidence, recovering directional continuity, and suppressing background coupling. We propose RIFT, a compact family of morphology-aligned crack segmentation models. Rather than compressing a complex generic architecture, RIFT is simple by design, preserving local evidence, aggregating cooperative directional continuity, and restoring crack structures through lightweight multi-scale fusion. Experiments on four public benchmarks show that RIFT achieves the best or tied-best results across the 16 main metrics against reproduced representative baselines. RIFT-B gives the strongest overall accuracy, while RIFT-T provides the best deployment efficiency with only 0.47M parameters and high inference speed. Topology-aware evaluation, ablations, transfer experiments, and visualizations further verify that task-aligned simplicity can match or surpass complex hybrid architectures when its inductive bias fits crack morphology. Code: https://github.com/xauat-liushipeng/RIFT
Tabero: Learning Gentle Manipulation with Closed-Loop Force Feedback from Vision, Touch, and Language
May 27, 2026Tactile sensing is essential for robots to achieve human-like gentle manipulation. However, existing Vision-Language-Action (VLA) models struggle to exploit tactile feedback for gentle manipulation due to scarce aligned vision-tactile-language data and the lack of effective closed-loop force feedback mechanisms. To address these challenges, we introduce Tabero, a benchmark and model suite for gentle, language-conditioned robotic manipulation that demands fine-grained contact force perception. First, the Tabero benchmark addresses the scarcity of tactile data by presenting a data-efficient pipeline that repurposes open-source robot manipulation trajectories to generate diverse vision-tactile-language tasks, and establishes a multidimensional evaluation protocol that measures task success alongside physical interaction quality. Second, we propose Tabero-VTLA, an architecture with a decoupled force-position command interface; the resulting force-position commands are executed by a fixed hybrid controller to enable real-time, force-aware manipulation. Evaluated on Tabero, our model maintains high task success while reducing average grip force by over 70\% under gentle instructions, demonstrating its ability to modulate interaction forces based on multimodal experience. Our code is publicly available at https://github.com/NathanWu7/Tabero.
LiDAR-EVS: Enhance Extrapolated View Synthesis for 3D Gaussian Splatting with Pseudo-LiDAR Supervision
Mar 16, 20263D Gaussian Splatting (3DGS) has emerged as a powerful technique for real-time LiDAR and camera synthesis in autonomous driving simulation. However, simulating LiDAR with 3DGS remains challenging for extrapolated views beyond the training trajectory, as existing methods are typically trained on single-traversal sensor scans, suffer from severe overfitting and poor generalization to novel ego-vehicle paths. To enable reliable simulation of LiDAR along unseen driving trajectories without external multi-pass data, we present LiDAR-EVS, a lightweight framework for robust extrapolated-view LiDAR simulation in autonomous driving. Designed to be plug-and-play, LiDAR-EVS readily extends to diverse LiDAR sensors and neural rendering baselines with minimal modification. Our framework comprises two key components: (1) pseudo extrapolated-view point cloud supervision with multi-frame LiDAR fusion, view transformation, occlusion curling, and intensity adjustment; (2) spatially-constrained dropout regularization that promotes robustness to diverse trajectory variations encountered in real-world driving. Extensive experiments demonstrate that LiDAR-EVS achieves SOTA performance on extrapolated-view LiDAR synthesis across three datasets, making it a promising tool for data-driven simulation, closed-loop evaluation, and synthetic data generation in autonomous driving systems.
Frequency-aware Adaptive Contrastive Learning for Sequential Recommendation
Jan 22, 2026In this paper, we revisited the role of data augmentation in contrastive learning for sequential recommendation, revealing its inherent bias against low-frequency items and sparse user behaviors. To address this limitation, we proposed FACL, a frequency-aware adaptive contrastive learning framework that introduces micro-level adaptive perturbation to protect the integrity of rare items, as well as macro-level reweighting to amplify the influence of sparse and rare-interaction sequences during training. Comprehensive experiments on five public benchmark datasets demonstrated that FACL consistently outperforms state-of-the-art data augmentation and model augmentation-based methods, achieving up to 3.8% improvement in recommendation accuracy. Moreover, fine-grained analyses confirm that FACL significantly alleviates the performance drop on low-frequency items and users, highlighting its robust intent-preserving ability and its superior applicability to real-world, long-tail recommendation scenarios.
Open Challenges and Opportunities in Federated Foundation Models Towards Biomedical Healthcare
May 10, 2024This survey explores the transformative impact of foundation models (FMs) in artificial intelligence, focusing on their integration with federated learning (FL) for advancing biomedical research. Foundation models such as ChatGPT, LLaMa, and CLIP, which are trained on vast datasets through methods including unsupervised pretraining, self-supervised learning, instructed fine-tuning, and reinforcement learning from human feedback, represent significant advancements in machine learning. These models, with their ability to generate coherent text and realistic images, are crucial for biomedical applications that require processing diverse data forms such as clinical reports, diagnostic images, and multimodal patient interactions. The incorporation of FL with these sophisticated models presents a promising strategy to harness their analytical power while safeguarding the privacy of sensitive medical data. This approach not only enhances the capabilities of FMs in medical diagnostics and personalized treatment but also addresses critical concerns about data privacy and security in healthcare. This survey reviews the current applications of FMs in federated settings, underscores the challenges, and identifies future research directions including scaling FMs, managing data diversity, and enhancing communication efficiency within FL frameworks. The objective is to encourage further research into the combined potential of FMs and FL, laying the groundwork for groundbreaking healthcare innovations.
Adaptive Transfer Learning of Multi-View Time Series Classification
Oct 14, 2019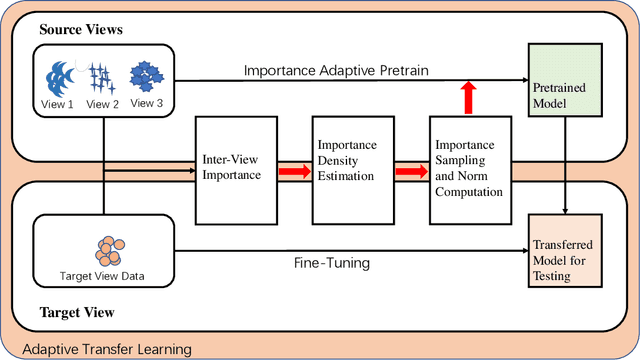


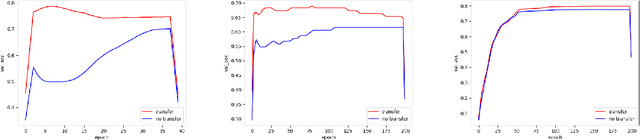
Time Series Classification (TSC) has been an important and challenging task in data mining, especially on multivariate time series and multi-view time series data sets. Meanwhile, transfer learning has been widely applied in computer vision and natural language processing applications to improve deep neural network's generalization capabilities. However, very few previous works applied transfer learning framework to time series mining problems. Particularly, the technique of measuring similarities between source domain and target domain based on dynamic representation such as density estimation with importance sampling has never been combined with transfer learning framework. In this paper, we first proposed a general adaptive transfer learning framework for multi-view time series data, which shows strong ability in storing inter-view importance value in the process of knowledge transfer. Next, we represented inter-view importance through some time series similarity measurements and approximated the posterior distribution in latent space for the importance sampling via density estimation techniques. We then computed the matrix norm of sampled importance value, which controls the degree of knowledge transfer in pre-training process. We further evaluated our work, applied it to many other time series classification tasks, and observed that our architecture maintained desirable generalization ability. Finally, we concluded that our framework could be adapted with deep learning techniques to receive significant model performance improvements.
LEARN: Learned Experts' Assessment-based Reconstruction Network for Sparse-data CT
Feb 10, 2018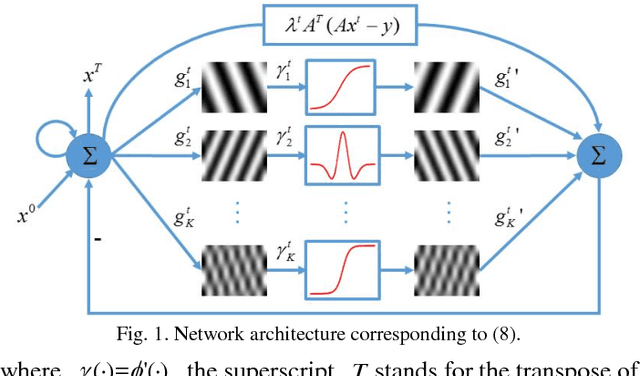
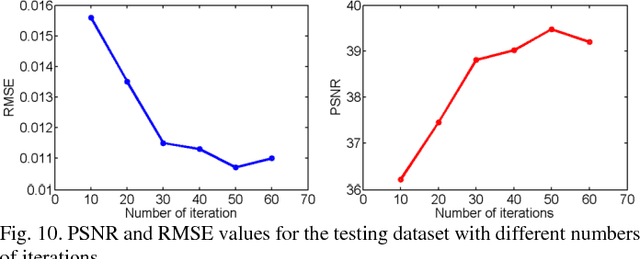
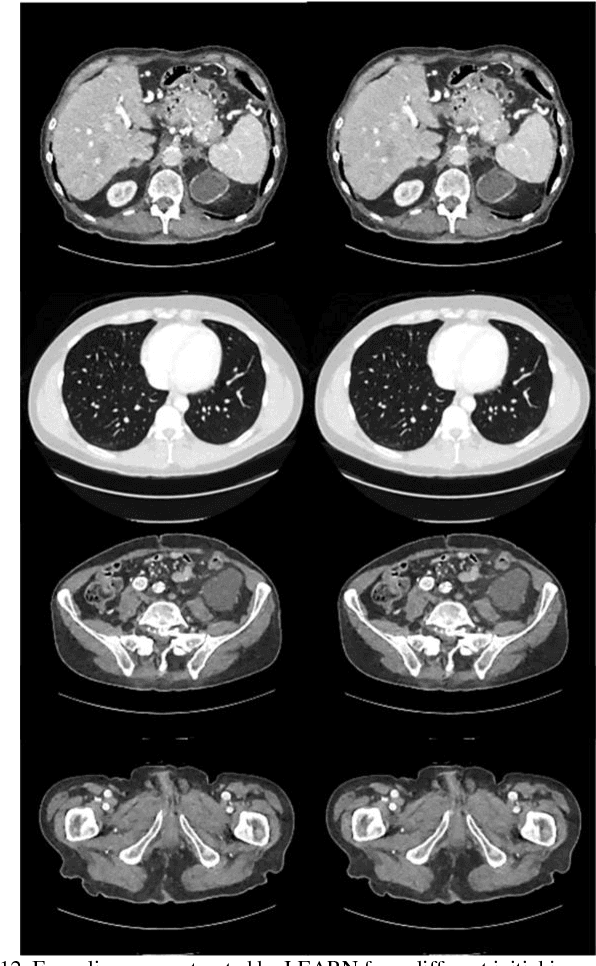
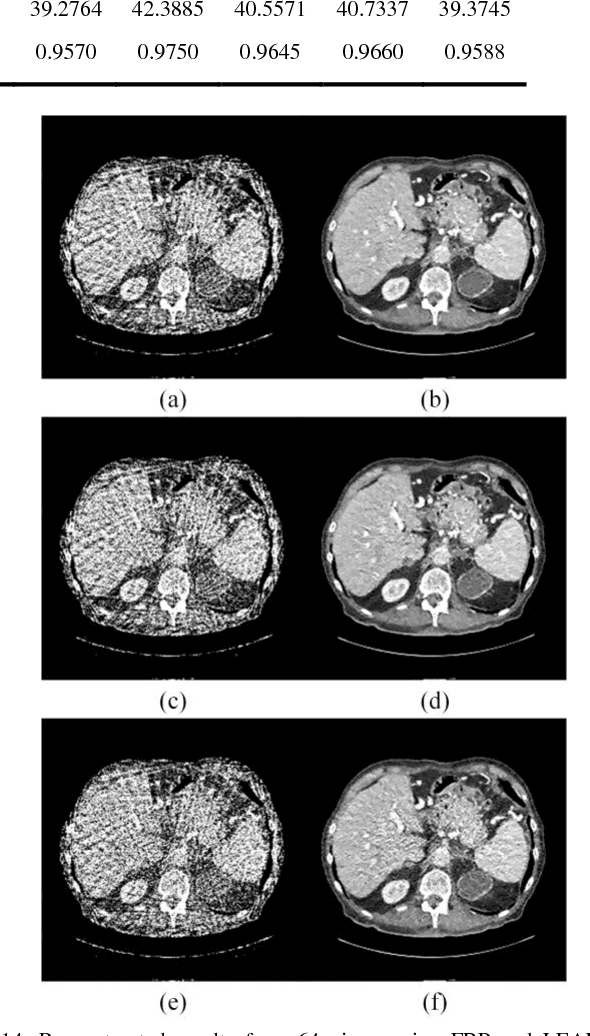
Compressive sensing (CS) has proved effective for tomographic reconstruction from sparsely collected data or under-sampled measurements, which are practically important for few-view CT, tomosynthesis, interior tomography, and so on. To perform sparse-data CT, the iterative reconstruction commonly use regularizers in the CS framework. Currently, how to choose the parameters adaptively for regularization is a major open problem. In this paper, inspired by the idea of machine learning especially deep learning, we unfold a state-of-the-art "fields of experts" based iterative reconstruction scheme up to a number of iterations for data-driven training, construct a Learned Experts' Assessment-based Reconstruction Network ("LEARN") for sparse-data CT, and demonstrate the feasibility and merits of our LEARN network. The experimental results with our proposed LEARN network produces a competitive performance with the well-known Mayo Clinic Low-Dose Challenge Dataset relative to several state-of-the-art methods, in terms of artifact reduction, feature preservation, and computational speed. This is consistent to our insight that because all the regularization terms and parameters used in the iterative reconstruction are now learned from the training data, our LEARN network utilizes application-oriented knowledge more effectively and recovers underlying images more favorably than competing algorithms. Also, the number of layers in the LEARN network is only 12, reducing the computational complexity of typical iterative algorithms by orders of magnitude.
Low-dose CT denoising with convolutional neural network
Oct 02, 2016
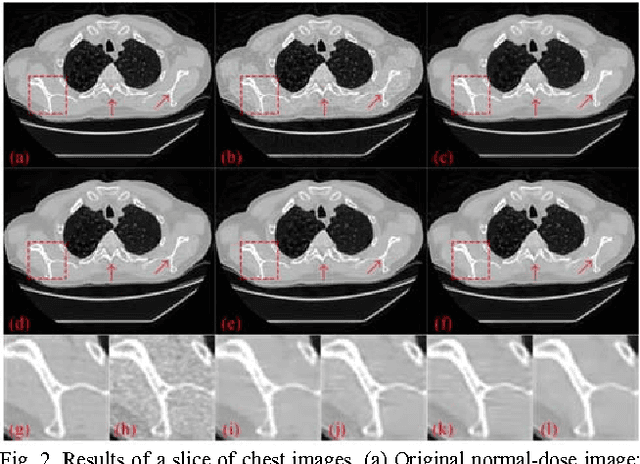
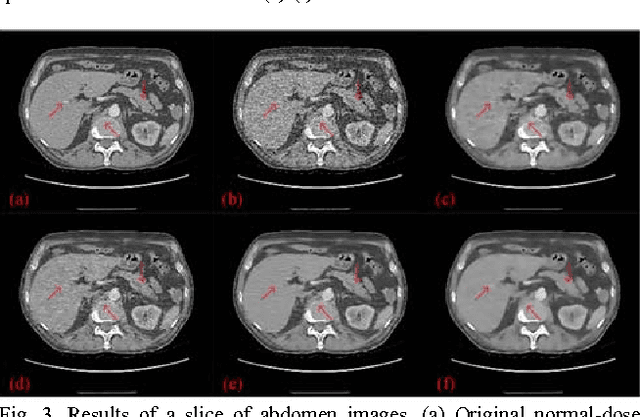
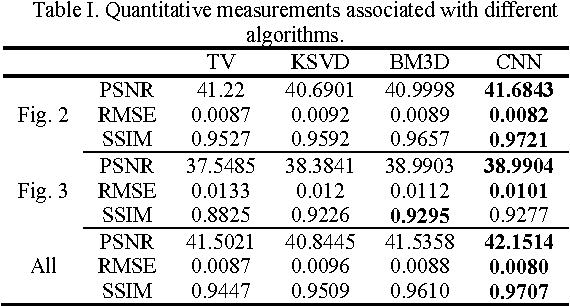
To reduce the potential radiation risk, low-dose CT has attracted much attention. However, simply lowering the radiation dose will lead to significant deterioration of the image quality. In this paper, we propose a noise reduction method for low-dose CT via deep neural network without accessing original projection data. A deep convolutional neural network is trained to transform low-dose CT images towards normal-dose CT images, patch by patch. Visual and quantitative evaluation demonstrates a competing performance of the proposed method.