 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSetPO: Set-Level Policy Optimization for Diversity-Preserving LLM Reasoning
Feb 01, 2026Reinforcement learning with verifiable rewards has shown notable effectiveness in enhancing large language models (LLMs) reasoning performance, especially in mathematics tasks. However, such improvements often come with reduced outcome diversity, where the model concentrates probability mass on a narrow set of solutions. Motivated by diminishing-returns principles, we introduce a set level diversity objective defined over sampled trajectories using kernelized similarity. Our approach derives a leave-one-out marginal contribution for each sampled trajectory and integrates this objective as a plug-in advantage shaping term for policy optimization. We further investigate the contribution of a single trajectory to language model diversity within a distribution perturbation framework. This analysis theoretically confirms a monotonicity property, proving that rarer trajectories yield consistently higher marginal contributions to the global diversity. Extensive experiments across a range of model scales demonstrate the effectiveness of our proposed algorithm, consistently outperforming strong baselines in both Pass@1 and Pass@K across various benchmarks.
StoryState: Agent-Based State Control for Consistent and Editable Storybooks
Feb 01, 2026Large multimodal models have enabled one-click storybook generation, where users provide a short description and receive a multi-page illustrated story. However, the underlying story state, such as characters, world settings, and page-level objects, remains implicit, making edits coarse-grained and often breaking visual consistency. We present StoryState, an agent-based orchestration layer that introduces an explicit and editable story state on top of training-free text-to-image generation. StoryState represents each story as a structured object composed of a character sheet, global settings, and per-page scene constraints, and employs a small set of LLM agents to maintain this state and derive 1Prompt1Story-style prompts for generation and editing. Operating purely through prompts, StoryState is model-agnostic and compatible with diverse generation backends. System-level experiments on multi-page editing tasks show that StoryState enables localized page edits, improves cross-page consistency, and reduces unintended changes, interaction turns, and editing time compared to 1Prompt1Story, while approaching the one-shot consistency of Gemini Storybook. Code is available at https://github.com/YuZhenyuLindy/StoryState
ReDiStory: Region-Disentangled Diffusion for Consistent Visual Story Generation
Feb 01, 2026Generating coherent visual stories requires maintaining subject identity across multiple images while preserving frame-specific semantics. Recent training-free methods concatenate identity and frame prompts into a unified representation, but this often introduces inter-frame semantic interference that weakens identity preservation in complex stories. We propose ReDiStory, a training-free framework that improves multi-frame story generation via inference-time prompt embedding reorganization. ReDiStory explicitly decomposes text embeddings into identity-related and frame-specific components, then decorrelates frame embeddings by suppressing shared directions across frames. This reduces cross-frame interference without modifying diffusion parameters or requiring additional supervision. Under identical diffusion backbones and inference settings, ReDiStory improves identity consistency while maintaining prompt fidelity. Experiments on the ConsiStory+ benchmark show consistent gains over 1Prompt1Story on multiple identity consistency metrics. Code is available at: https://github.com/YuZhenyuLindy/ReDiStory
Calibratable Disambiguation Loss for Multi-Instance Partial-Label Learning
Dec 19, 2025Multi-instance partial-label learning (MIPL) is a weakly supervised framework that extends the principles of multi-instance learning (MIL) and partial-label learning (PLL) to address the challenges of inexact supervision in both instance and label spaces. However, existing MIPL approaches often suffer from poor calibration, undermining classifier reliability. In this work, we propose a plug-and-play calibratable disambiguation loss (CDL) that simultaneously improves classification accuracy and calibration performance. The loss has two instantiations: the first one calibrates predictions based on probabilities from the candidate label set, while the second one integrates probabilities from both candidate and non-candidate label sets. The proposed CDL can be seamlessly incorporated into existing MIPL and PLL frameworks. We provide a theoretical analysis that establishes the lower bound and regularization properties of CDL, demonstrating its superiority over conventional disambiguation losses. Experimental results on benchmark and real-world datasets confirm that our CDL significantly enhances both classification and calibration performance.
Non-Linear Trajectory Modeling for Multi-Step Gradient Inversion Attacks in Federated Learning
Sep 26, 2025Federated Learning (FL) preserves privacy by keeping raw data local, yet Gradient Inversion Attacks (GIAs) pose significant threats. In FedAVG multi-step scenarios, attackers observe only aggregated gradients, making data reconstruction challenging. Existing surrogate model methods like SME assume linear parameter trajectories, but we demonstrate this severely underestimates SGD's nonlinear complexity, fundamentally limiting attack effectiveness. We propose Non-Linear Surrogate Model Extension (NL-SME), the first method to introduce nonlinear parametric trajectory modeling for GIAs. Our approach replaces linear interpolation with learnable quadratic B\'ezier curves that capture SGD's curved characteristics through control points, combined with regularization and dvec scaling mechanisms for enhanced expressiveness. Extensive experiments on CIFAR-100 and FEMNIST datasets show NL-SME significantly outperforms baselines across all metrics, achieving order-of-magnitude improvements in cosine similarity loss while maintaining computational efficiency.This work exposes heightened privacy vulnerabilities in FL's multi-step update paradigm and offers novel perspectives for developing robust defense strategies.
SAMPO:Scale-wise Autoregression with Motion PrOmpt for generative world models
Sep 19, 2025World models allow agents to simulate the consequences of actions in imagined environments for planning, control, and long-horizon decision-making. However, existing autoregressive world models struggle with visually coherent predictions due to disrupted spatial structure, inefficient decoding, and inadequate motion modeling. In response, we propose \textbf{S}cale-wise \textbf{A}utoregression with \textbf{M}otion \textbf{P}r\textbf{O}mpt (\textbf{SAMPO}), a hybrid framework that combines visual autoregressive modeling for intra-frame generation with causal modeling for next-frame generation. Specifically, SAMPO integrates temporal causal decoding with bidirectional spatial attention, which preserves spatial locality and supports parallel decoding within each scale. This design significantly enhances both temporal consistency and rollout efficiency. To further improve dynamic scene understanding, we devise an asymmetric multi-scale tokenizer that preserves spatial details in observed frames and extracts compact dynamic representations for future frames, optimizing both memory usage and model performance. Additionally, we introduce a trajectory-aware motion prompt module that injects spatiotemporal cues about object and robot trajectories, focusing attention on dynamic regions and improving temporal consistency and physical realism. Extensive experiments show that SAMPO achieves competitive performance in action-conditioned video prediction and model-based control, improving generation quality with 4.4$\times$ faster inference. We also evaluate SAMPO's zero-shot generalization and scaling behavior, demonstrating its ability to generalize to unseen tasks and benefit from larger model sizes.
From Orthomosaics to Raw UAV Imagery: Enhancing Palm Detection and Crown-Center Localization
Sep 15, 2025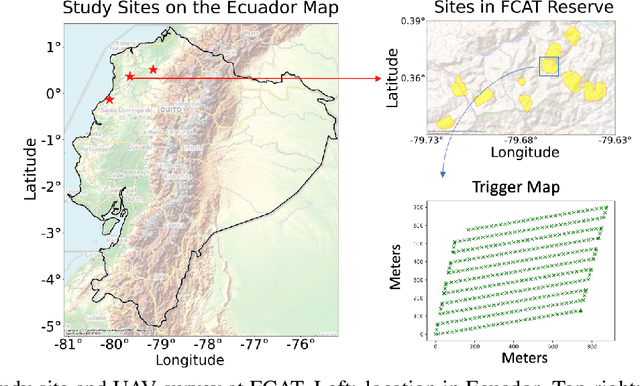
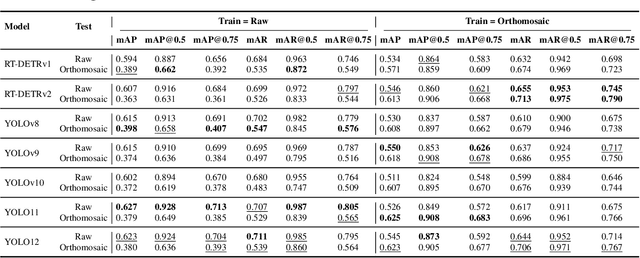
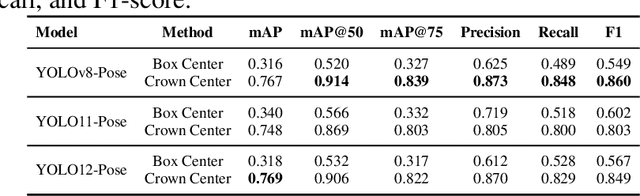

Accurate mapping of individual trees is essential for ecological monitoring and forest management. Orthomosaic imagery from unmanned aerial vehicles (UAVs) is widely used, but stitching artifacts and heavy preprocessing limit its suitability for field deployment. This study explores the use of raw UAV imagery for palm detection and crown-center localization in tropical forests. Two research questions are addressed: (1) how detection performance varies across orthomosaic and raw imagery, including within-domain and cross-domain transfer, and (2) to what extent crown-center annotations improve localization accuracy beyond bounding-box centroids. Using state-of-the-art detectors and keypoint models, we show that raw imagery yields superior performance in deployment-relevant scenarios, while orthomosaics retain value for robust cross-domain generalization. Incorporating crown-center annotations in training further improves localization and provides precise tree positions for downstream ecological analyses. These findings offer practical guidance for UAV-based biodiversity and conservation monitoring.
Learning Primitive Embodied World Models: Towards Scalable Robotic Learning
Aug 28, 2025



While video-generation-based embodied world models have gained increasing attention, their reliance on large-scale embodied interaction data remains a key bottleneck. The scarcity, difficulty of collection, and high dimensionality of embodied data fundamentally limit the alignment granularity between language and actions and exacerbate the challenge of long-horizon video generation--hindering generative models from achieving a "GPT moment" in the embodied domain. There is a naive observation: the diversity of embodied data far exceeds the relatively small space of possible primitive motions. Based on this insight, we propose a novel paradigm for world modeling--Primitive Embodied World Models (PEWM). By restricting video generation to fixed short horizons, our approach 1) enables fine-grained alignment between linguistic concepts and visual representations of robotic actions, 2) reduces learning complexity, 3) improves data efficiency in embodied data collection, and 4) decreases inference latency. By equipping with a modular Vision-Language Model (VLM) planner and a Start-Goal heatmap Guidance mechanism (SGG), PEWM further enables flexible closed-loop control and supports compositional generalization of primitive-level policies over extended, complex tasks. Our framework leverages the spatiotemporal vision priors in video models and the semantic awareness of VLMs to bridge the gap between fine-grained physical interaction and high-level reasoning, paving the way toward scalable, interpretable, and general-purpose embodied intelligence.
Measuring Informativeness Gap of (Mis)Calibrated Predictors
Jul 16, 2025In many applications, decision-makers must choose between multiple predictive models that may all be miscalibrated. Which model (i.e., predictor) is more "useful" in downstream decision tasks? To answer this, our first contribution introduces the notion of the informativeness gap between any two predictors, defined as the maximum normalized payoff advantage one predictor offers over the other across all decision-making tasks. Our framework strictly generalizes several existing notions: it subsumes U-Calibration [KLST-23] and Calibration Decision Loss [HW-24], which compare a miscalibrated predictor to its calibrated counterpart, and it recovers Blackwell informativeness [Bla-51, Bla-53] as a special case when both predictors are perfectly calibrated. Our second contribution is a dual characterization of the informativeness gap, which gives rise to a natural informativeness measure that can be viewed as a relaxed variant of the earth mover's distance (EMD) between two prediction distributions. We show that this measure satisfies natural desiderata: it is complete and sound, and it can be estimated sample-efficiently in the prediction-only access setting. Along the way, we also obtain novel combinatorial structural results when applying this measure to perfectly calibrated predictors.
Tuning the Right Foundation Models is What you Need for Partial Label Learning
Jun 05, 2025Partial label learning (PLL) seeks to train generalizable classifiers from datasets with inexact supervision, a common challenge in real-world applications. Existing studies have developed numerous approaches to progressively refine and recover ground-truth labels by training convolutional neural networks. However, limited attention has been given to foundation models that offer transferrable representations. In this work, we empirically conduct comprehensive evaluations of 11 foundation models across 13 PLL approaches on 8 benchmark datasets under 3 PLL scenarios. We further propose PartialCLIP, an efficient fine-tuning framework for foundation models in PLL. Our findings reveal that current PLL approaches tend to 1) achieve significant performance gains when using foundation models, 2) exhibit remarkably similar performance to each other, 3) maintain stable performance across varying ambiguity levels, while 4) are susceptible to foundation model selection and adaptation strategies. Additionally, we demonstrate the efficacy of text-embedding classifier initialization and effective candidate label filtering using zero-shot CLIP. Our experimental results and analysis underscore the limitations of current PLL approaches and provide valuable insights for developing more generalizable PLL models. The source code can be found at https://github.com/SEU-hk/PartialCLIP.