 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMPO:Scale-wise Autoregression with Motion PrOmpt for generative world models
Sep 19, 2025World models allow agents to simulate the consequences of actions in imagined environments for planning, control, and long-horizon decision-making. However, existing autoregressive world models struggle with visually coherent predictions due to disrupted spatial structure, inefficient decoding, and inadequate motion modeling. In response, we propose \textbf{S}cale-wise \textbf{A}utoregression with \textbf{M}otion \textbf{P}r\textbf{O}mpt (\textbf{SAMPO}), a hybrid framework that combines visual autoregressive modeling for intra-frame generation with causal modeling for next-frame generation. Specifically, SAMPO integrates temporal causal decoding with bidirectional spatial attention, which preserves spatial locality and supports parallel decoding within each scale. This design significantly enhances both temporal consistency and rollout efficiency. To further improve dynamic scene understanding, we devise an asymmetric multi-scale tokenizer that preserves spatial details in observed frames and extracts compact dynamic representations for future frames, optimizing both memory usage and model performance. Additionally, we introduce a trajectory-aware motion prompt module that injects spatiotemporal cues about object and robot trajectories, focusing attention on dynamic regions and improving temporal consistency and physical realism. Extensive experiments show that SAMPO achieves competitive performance in action-conditioned video prediction and model-based control, improving generation quality with 4.4$\times$ faster inference. We also evaluate SAMPO's zero-shot generalization and scaling behavior, demonstrating its ability to generalize to unseen tasks and benefit from larger model sizes.
STCOcc: Sparse Spatial-Temporal Cascade Renovation for 3D Occupancy and Scene Flow Prediction
Apr 28, 2025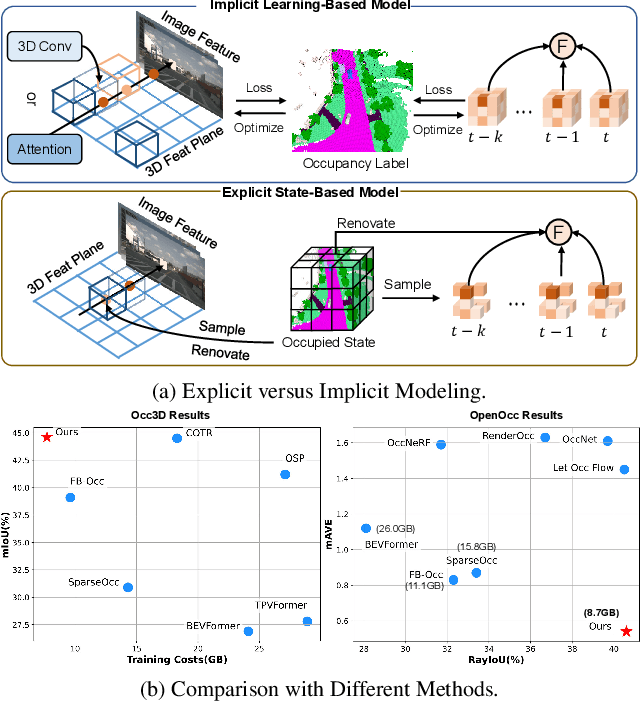
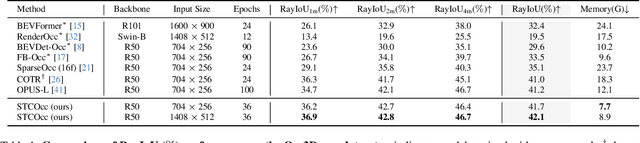
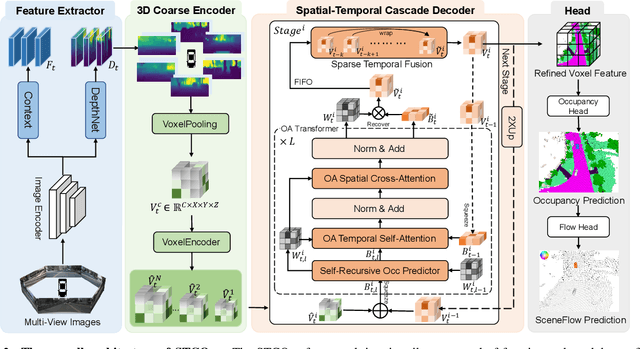
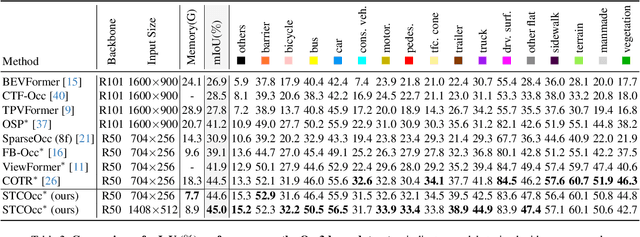
3D occupancy and scene flow offer a detailed and dynamic representation of 3D scene. Recognizing the sparsity and complexity of 3D space, previous vision-centric methods have employed implicit learning-based approaches to model spatial and temporal information. However, these approaches struggle to capture local details and diminish the model's spatial discriminative ability. To address these challenges, we propose a novel explicit state-based modeling method designed to leverage the occupied state to renovate the 3D features. Specifically, we propose a sparse occlusion-aware attention mechanism, integrated with a cascade refinement strategy, which accurately renovates 3D features with the guidance of occupied state information. Additionally, we introduce a novel method for modeling long-term dynamic interactions, which reduces computational costs and preserves spatial information. Compared to the previous state-of-the-art methods, our efficient explicit renovation strategy not only delivers superior performance in terms of RayIoU and mAVE for occupancy and scene flow prediction but also markedly reduces GPU memory usage during training, bringing it down to 8.7GB. Our code is available on https://github.com/lzzzzzm/STCOcc