 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Regression-Free Neural Networks for Diverse Compute Platforms
Sep 27, 2022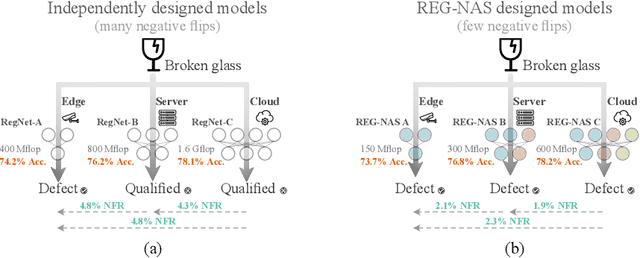
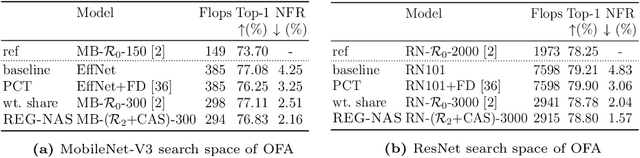
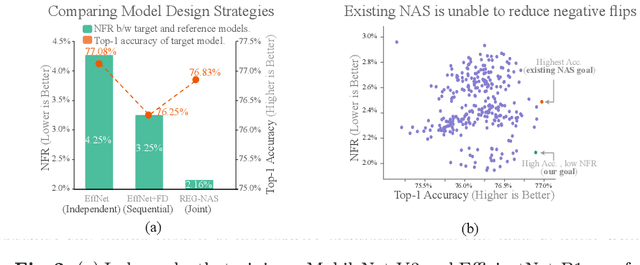
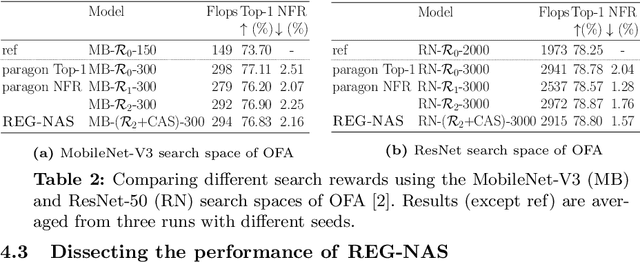
With the shift towards on-device deep learning, ensuring a consistent behavior of an AI service across diverse compute platforms becomes tremendously important. Our work tackles the emergent problem of reducing predictive inconsistencies arising as negative flips: test samples that are correctly predicted by a less accurate model, but incorrectly by a more accurate one. We introduce REGression constrained Neural Architecture Search (REG-NAS) to design a family of highly accurate models that engender fewer negative flips. REG-NAS consists of two components: (1) A novel architecture constraint that enables a larger model to contain all the weights of the smaller one thus maximizing weight sharing. This idea stems from our observation that larger weight sharing among networks leads to similar sample-wise predictions and results in fewer negative flips; (2) A novel search reward that incorporates both Top-1 accuracy and negative flips in the architecture search metric. We demonstrate that \regnas can successfully find desirable architectures with few negative flips in three popular architecture search spaces. Compared to the existing state-of-the-art approach, REG-NAS enables 33-48% relative reduction of negative flips.
Data-driven Attention and Data-independent DCT based Global Context Modeling for Text-independent Speaker Recognition
Aug 04, 2022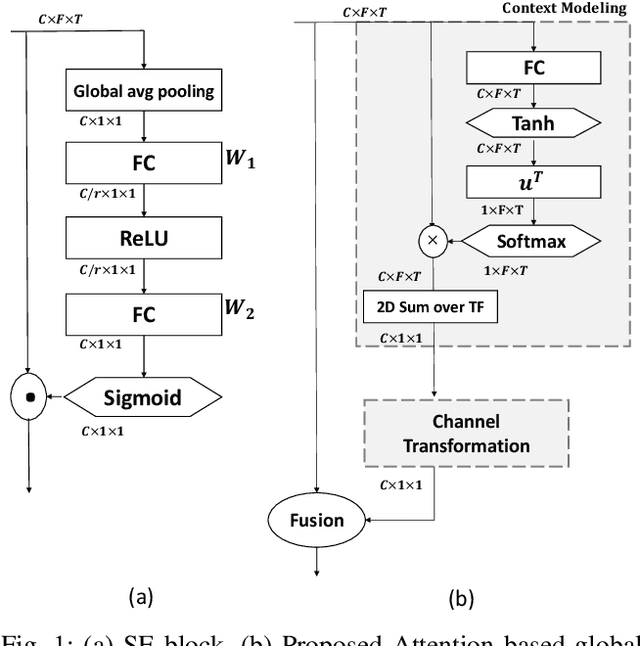
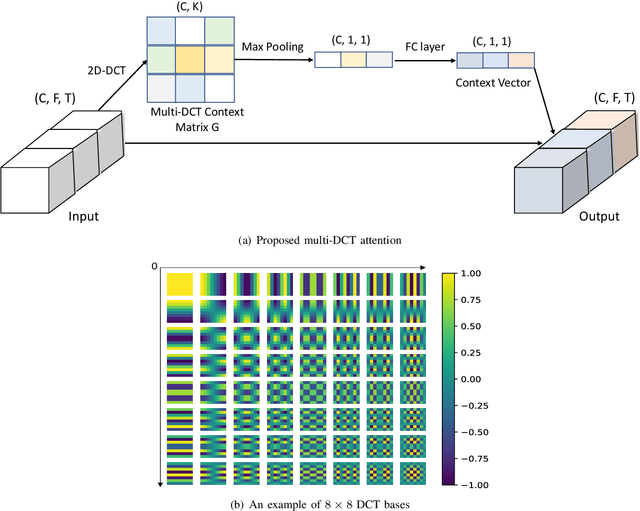
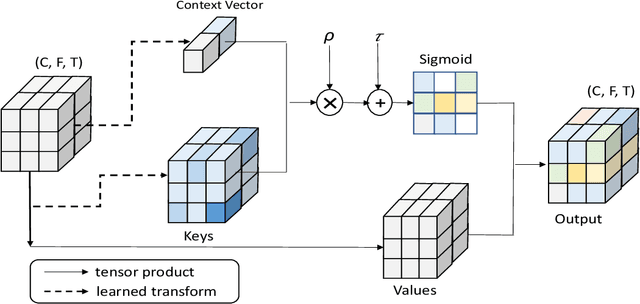
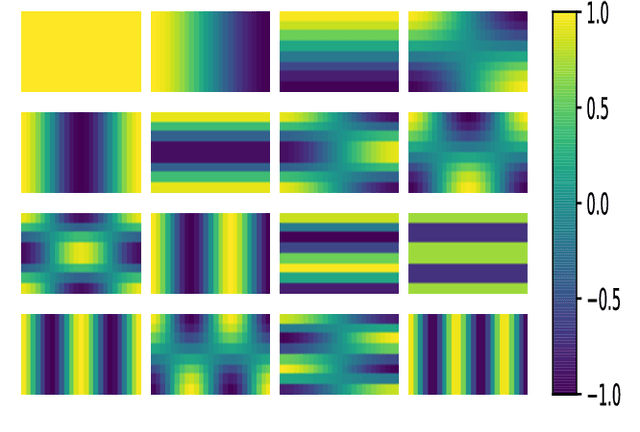
Learning an effective speaker representation is crucial for achieving reliable performance in speaker verification tasks. Speech signals are high-dimensional, long, and variable-length sequences that entail a complex hierarchical structure. Signals may contain diverse information at each time-frequency (TF) location. For example, it may be more beneficial to focus on high-energy parts for phoneme classes such as fricatives. The standard convolutional layer that operates on neighboring local regions cannot capture the complex TF global context information. In this study, a general global time-frequency context modeling framework is proposed to leverage the context information specifically for speaker representation modeling. First, a data-driven attention-based context model is introduced to capture the long-range and non-local relationship across different time-frequency locations. Second, a data-independent 2D-DCT based context model is proposed to improve model interpretability. A multi-DCT attention mechanism is presented to improve modeling power with alternate DCT base forms. Finally, the global context information is used to recalibrate salient time-frequency locations by computing the similarity between the global context and local features. The proposed lightweight blocks can be easily incorporated into a speaker model with little additional computational costs and effectively improves the speaker verification performance compared to the standard ResNet model and Squeeze\&Excitation block by a large margin. Detailed ablation studies are also performed to analyze various factors that may impact performance of the proposed individual modules. Results from experiments show that the proposed global context modeling framework can efficiently improve the learned speaker representations by achieving channel-wise and time-frequency feature recalibration.
ELODI: Ensemble Logit Difference Inhibition for Positive-Congruent Training
May 13, 2022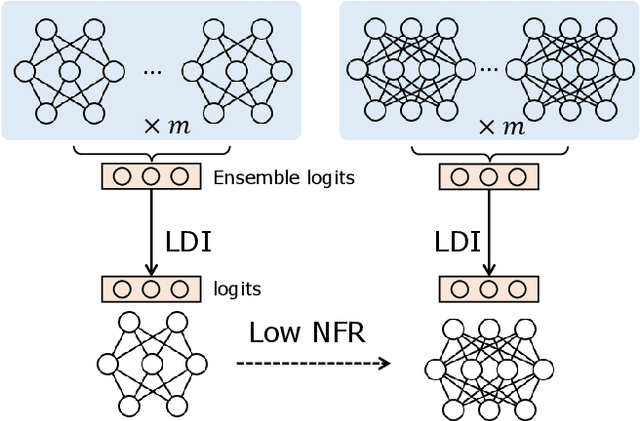
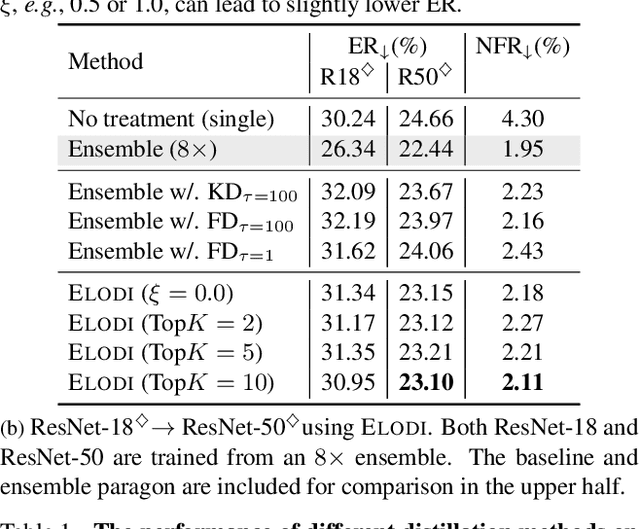
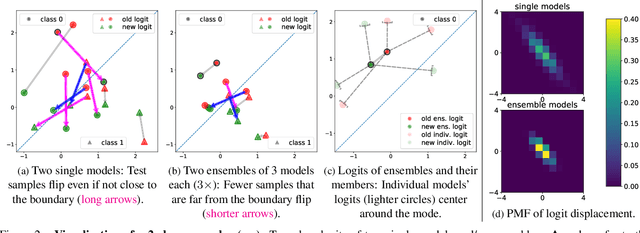
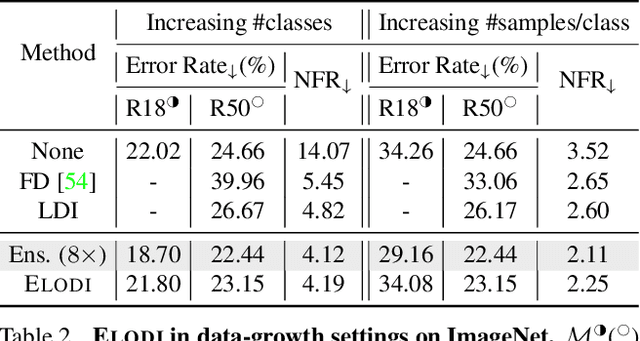
Negative flips are errors introduced in a classification system when a legacy model is replaced with a new one. Existing methods to reduce the negative flip rate (NFR) either do so at the expense of overall accuracy using model distillation, or use ensembles, which multiply inference cost prohibitively. We present a method to train a classification system that achieves paragon performance in both error rate and NFR, at the inference cost of a single model. Our method introduces a generalized distillation objective, Logit Difference Inhibition (LDI), that penalizes changes in the logits between the new and old model, without forcing them to coincide as in ordinary distillation. LDI affords the model flexibility to reduce error rate along with NFR. The method uses a homogeneous ensemble as the reference model for LDI, hence the name Ensemble LDI, or ELODI. The reference model can then be substituted with a single model at inference time. The method leverages the observation that negative flips are typically not close to the decision boundary, but often exhibit large deviations in the distance among their logits, which are reduced by ELODI.
MeMOT: Multi-Object Tracking with Memory
Mar 31, 2022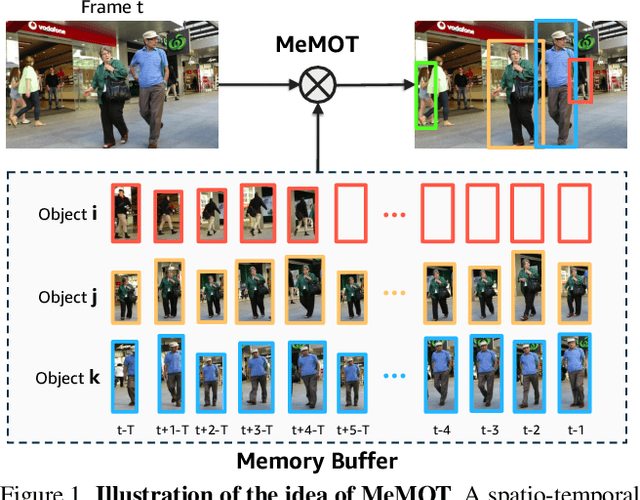
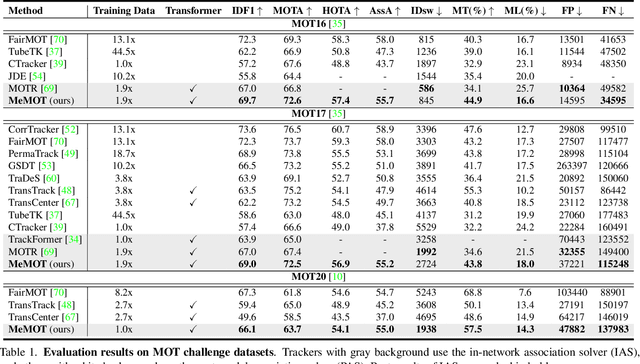
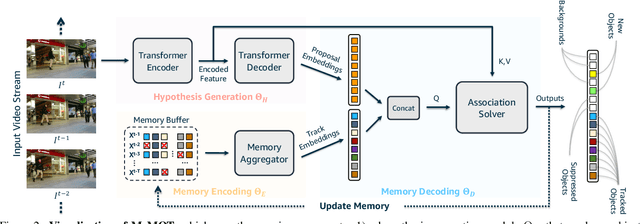
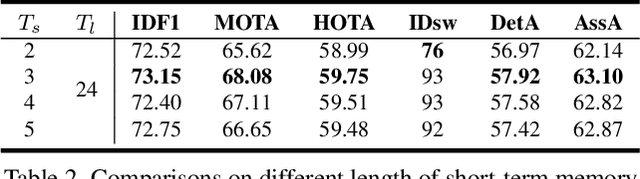
We propose an online tracking algorithm that performs the object detection and data association under a common framework, capable of linking objects after a long time span. This is realized by preserving a large spatio-temporal memory to store the identity embeddings of the tracked objects, and by adaptively referencing and aggregating useful information from the memory as needed. Our model, called MeMOT, consists of three main modules that are all Transformer-based: 1) Hypothesis Generation that produce object proposals in the current video frame; 2) Memory Encoding that extracts the core information from the memory for each tracked object; and 3) Memory Decoding that solves the object detection and data association tasks simultaneously for multi-object tracking. When evaluated on widely adopted MOT benchmark datasets, MeMOT observes very competitive performance.
Stochastic Backpropagation: A Memory Efficient Strategy for Training Video Models
Mar 31, 2022
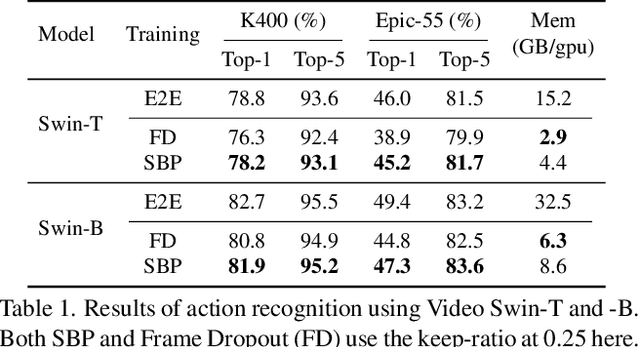
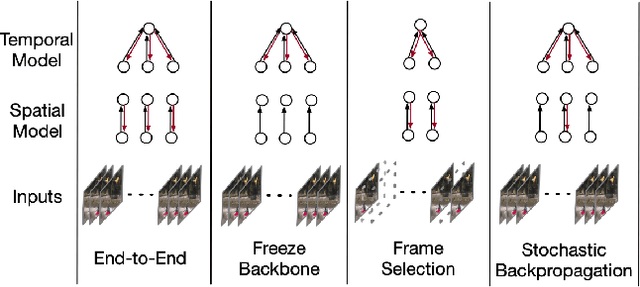
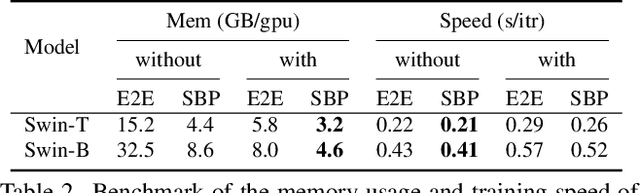
We propose a memory efficient method, named Stochastic Backpropagation (SBP), for training deep neural networks on videos. It is based on the finding that gradients from incomplete execution for backpropagation can still effectively train the models with minimal accuracy loss, which attributes to the high redundancy of video. SBP keeps all forward paths but randomly and independently removes the backward paths for each network layer in each training step. It reduces the GPU memory cost by eliminating the need to cache activation values corresponding to the dropped backward paths, whose amount can be controlled by an adjustable keep-ratio. Experiments show that SBP can be applied to a wide range of models for video tasks, leading to up to 80.0% GPU memory saving and 10% training speedup with less than 1% accuracy drop on action recognition and temporal action detection.
An Automatic Detection Method Of Cerebral Aneurysms In Time-Of-Flight Magnetic Resonance Angiography Images Based On Attention 3D U-Net
Oct 26, 2021

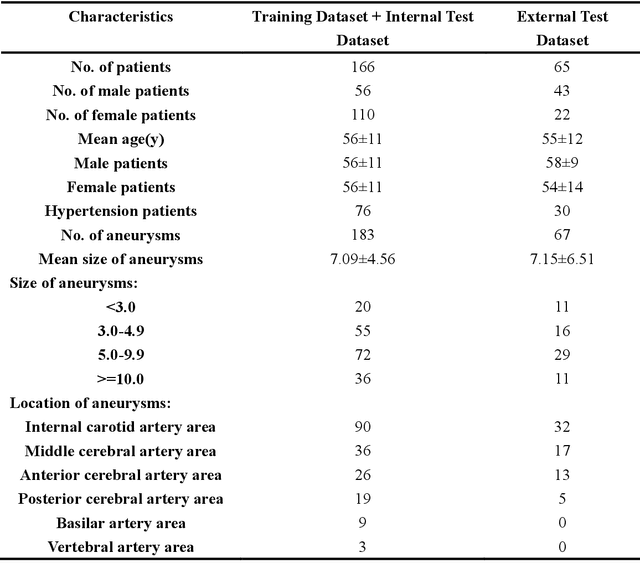
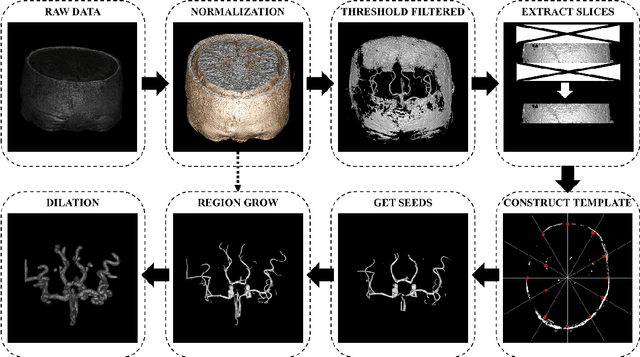
Background:Subarachnoid hemorrhage caused by ruptured cerebral aneurysm often leads to fatal consequences.However,if the aneurysm can be found and treated during asymptomatic periods,the probability of rupture can be greatly reduced.At present,time-of-flight magnetic resonance angiography is one of the most commonly used non-invasive screening techniques for cerebral aneurysm,and the application of deep learning technology in aneurysm detection can effectively improve the screening effect of aneurysm.Existing studies have found that three-dimensional features play an important role in aneurysm detection,but they require a large amount of training data and have problems such as a high false positive rate. Methods:This paper proposed a novel method for aneurysm detection.First,a fully automatic cerebral artery segmentation algorithm without training data was used to extract the volume of interest,and then the 3D U-Net was improved by the 3D SENet module to establish an aneurysm detection model.Eventually a set of fully automated,end-to-end aneurysm detection methods have been formed. Results:A total of 231 magnetic resonance angiography image data were used in this study,among which 132 were training sets,34 were internal test sets and 65 were external test sets.The presented method obtained 97.89% sensitivity in the five-fold cross-validation and obtained 91.0% sensitivity with 2.48 false positives/case in the detection of the external test sets. Conclusions:Compared with the results of our previous studies and other studies,the method in this paper achieves a very competitive sensitivity with less training data and maintains a low false positive rate.As the only method currently using 3D U-Net for aneurysm detection,it proves the feasibility and superior performance of this network in aneurysm detection,and also explores the potential of the channel attention mechanism in this task.
Self-supervised Contrastive Attributed Graph Clustering
Oct 15, 2021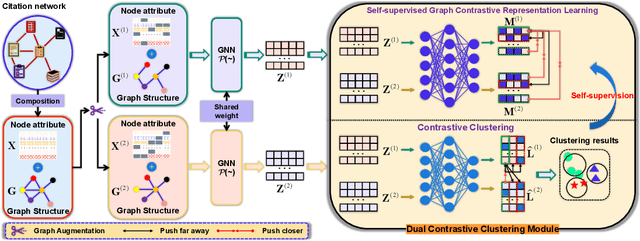

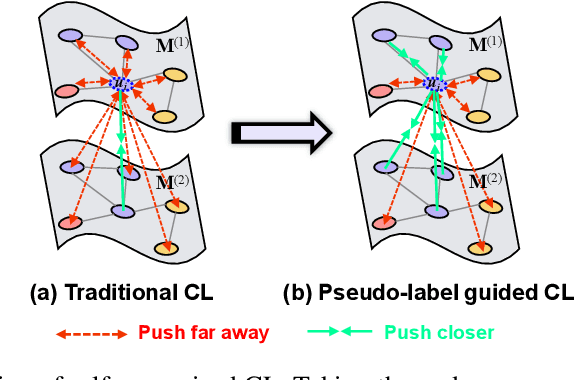
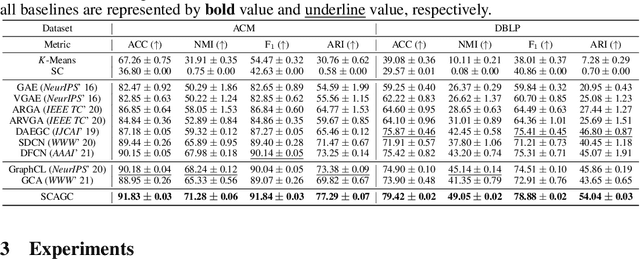
Attributed graph clustering, which learns node representation from node attribute and topological graph for clustering, is a fundamental but challenging task for graph analysis. Recently, methods based on graph contrastive learning (GCL) have obtained impressive clustering performance on this task. Yet, we observe that existing GCL-based methods 1) fail to benefit from imprecise clustering labels; 2) require a post-processing operation to get clustering labels; 3) cannot solve out-of-sample (OOS) problem. To address these issues, we propose a novel attributed graph clustering network, namely Self-supervised Contrastive Attributed Graph Clustering (SCAGC). In SCAGC, by leveraging inaccurate clustering labels, a self-supervised contrastive loss, which aims to maximize the similarities of intra-cluster nodes while minimizing the similarities of inter-cluster nodes, are designed for node representation learning. Meanwhile, a clustering module is built to directly output clustering labels by contrasting the representation of different clusters. Thus, for the OOS nodes, SCAGC can directly calculate their clustering labels. Extensive experimental results on four benchmark datasets have shown that SCAGC consistently outperforms 11 competitive clustering methods.
Turn-to-Diarize: Online Speaker Diarization Constrained by Transformer Transducer Speaker Turn Detection
Oct 05, 2021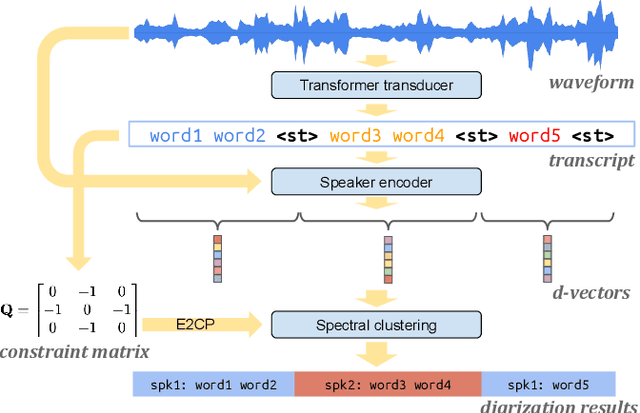

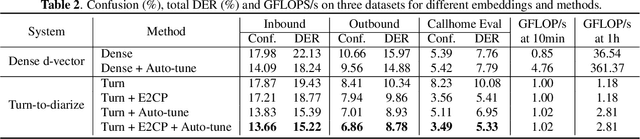
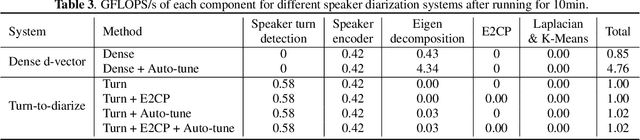
In this paper, we present a novel speaker diarization system for streaming on-device applications. In this system, we use a transformer transducer to detect the speaker turns, represent each speaker turn by a speaker embedding, then cluster these embeddings with constraints from the detected speaker turns. Compared with conventional clustering-based diarization systems, our system largely reduces the computational cost of clustering due to the sparsity of speaker turns. Unlike other supervised speaker diarization systems which require annotations of time-stamped speaker labels for training, our system only requires including speaker turn tokens during the transcribing process, which largely reduces the human efforts involved in data collection.
Scenario Aware Speech Recognition: Advancements for Apollo Fearless Steps & CHiME-4 Corpora
Sep 23, 2021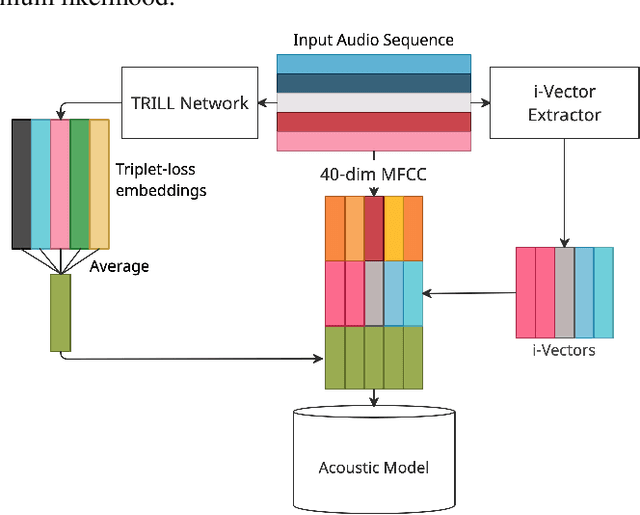
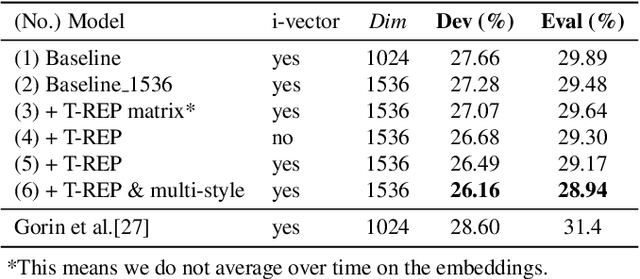
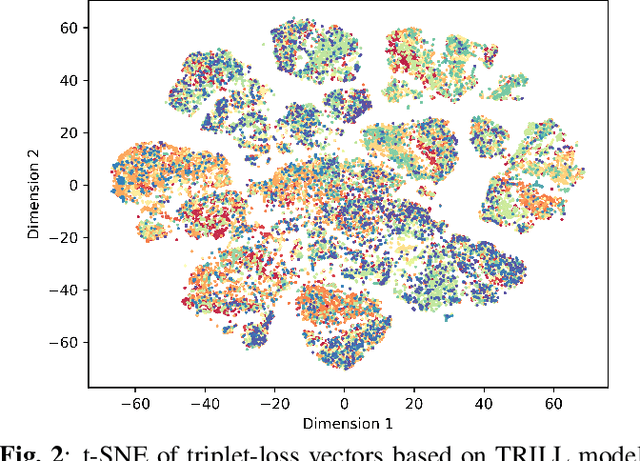

In this study, we propose to investigate triplet loss for the purpose of an alternative feature representation for ASR. We consider a general non-semantic speech representation, which is trained with a self-supervised criteria based on triplet loss called TRILL, for acoustic modeling to represent the acoustic characteristics of each audio. This strategy is then applied to the CHiME-4 corpus and CRSS-UTDallas Fearless Steps Corpus, with emphasis on the 100-hour challenge corpus which consists of 5 selected NASA Apollo-11 channels. An analysis of the extracted embeddings provides the foundation needed to characterize training utterances into distinct groups based on acoustic distinguishing properties. Moreover, we also demonstrate that triplet-loss based embedding performs better than i-Vector in acoustic modeling, confirming that the triplet loss is more effective than a speaker feature. With additional techniques such as pronunciation and silence probability modeling, plus multi-style training, we achieve a +5.42% and +3.18% relative WER improvement for the development and evaluation sets of the Fearless Steps Corpus. To explore generalization, we further test the same technique on the 1 channel track of CHiME-4 and observe a +11.90% relative WER improvement for real test data.
Effective and Efficient Graph Learning for Multi-view Clustering
Aug 15, 2021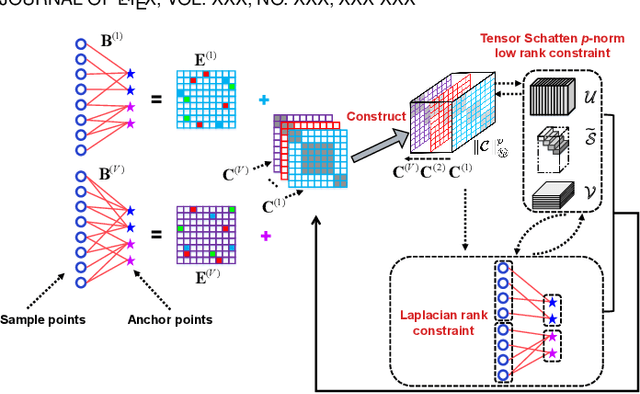
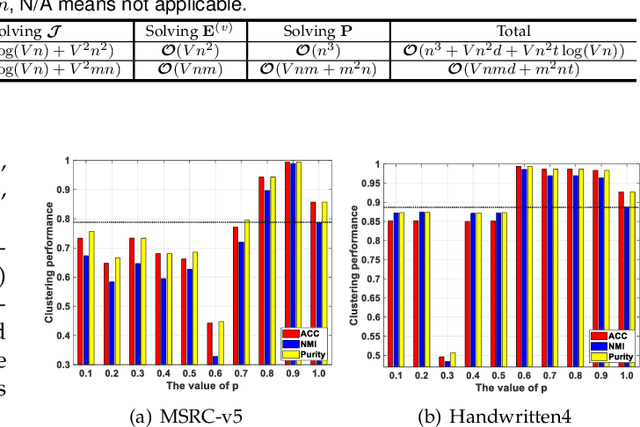
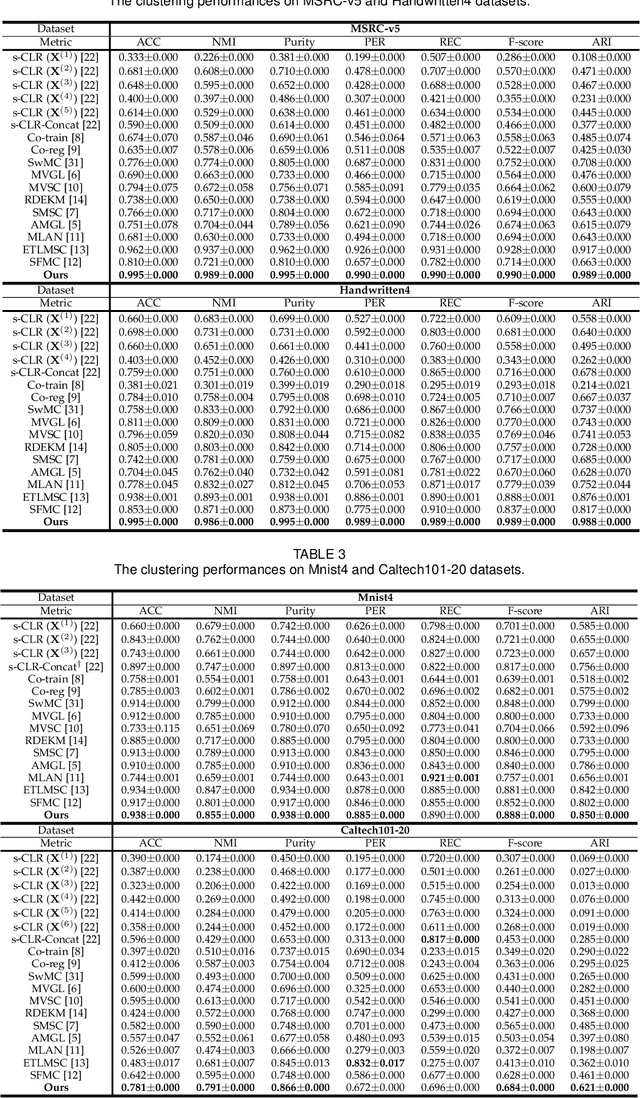
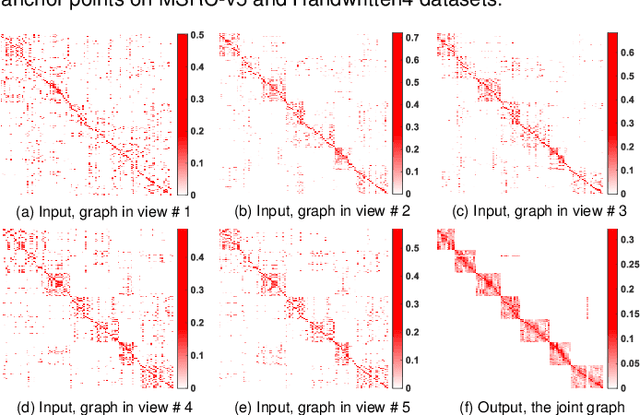
Despite the impressive clustering performance and efficiency in characterizing both the relationship between data and cluster structure, existing graph-based multi-view clustering methods still have the following drawbacks. They suffer from the expensive time burden due to both the construction of graphs and eigen-decomposition of Laplacian matrix, and fail to explore the cluster structure of large-scale data. Moreover, they require a post-processing to get the final clustering, resulting in suboptimal performance. Furthermore, rank of the learned view-consensus graph cannot approximate the target rank. In this paper, drawing the inspiration from the bipartite graph, we propose an effective and efficient graph learning model for multi-view clustering. Specifically, our method exploits the view-similar between graphs of different views by the minimization of tensor Schatten p-norm, which well characterizes both the spatial structure and complementary information embedded in graphs of different views. We learn view-consensus graph with adaptively weighted strategy and connectivity constraint such that the connected components indicates clusters directly. Our proposed algorithm is time-economical and obtains the stable results and scales well with the data size. Extensive experimental results indicate that our method is superior to state-of-the-art methods.