 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Transfer via Semantic Skill Imitation
Dec 14, 2022



We propose an approach for semantic imitation, which uses demonstrations from a source domain, e.g. human videos, to accelerate reinforcement learning (RL) in a different target domain, e.g. a robotic manipulator in a simulated kitchen. Instead of imitating low-level actions like joint velocities, our approach imitates the sequence of demonstrated semantic skills like "opening the microwave" or "turning on the stove". This allows us to transfer demonstrations across environments (e.g. real-world to simulated kitchen) and agent embodiments (e.g. bimanual human demonstration to robotic arm). We evaluate on three challenging cross-domain learning problems and match the performance of demonstration-accelerated RL approaches that require in-domain demonstrations. In a simulated kitchen environment, our approach learns long-horizon robot manipulation tasks, using less than 3 minutes of human video demonstrations from a real-world kitchen. This enables scaling robot learning via the reuse of demonstrations, e.g. collected as human videos, for learning in any number of target domains.
* Project website: https://kpertsch.github.io/star
CACTI: A Framework for Scalable Multi-Task Multi-Scene Visual Imitation Learning
Dec 12, 2022Developing robots that are capable of many skills and generalization to unseen scenarios requires progress on two fronts: efficient collection of large and diverse datasets, and training of high-capacity policies on the collected data. While large datasets have propelled progress in other fields like computer vision and natural language processing, collecting data of comparable scale is particularly challenging for physical systems like robotics. In this work, we propose a framework to bridge this gap and better scale up robot learning, under the lens of multi-task, multi-scene robot manipulation in kitchen environments. Our framework, named CACTI, has four stages that separately handle data collection, data augmentation, visual representation learning, and imitation policy training. In the CACTI framework, we highlight the benefit of adapting state-of-the-art models for image generation as part of the augmentation stage, and the significant improvement of training efficiency by using pretrained out-of-domain visual representations at the compression stage. Experimentally, we demonstrate that 1) on a real robot setup, CACTI enables efficient training of a single policy capable of 10 manipulation tasks involving kitchen objects, and robust to varying layouts of distractor objects; 2) in a simulated kitchen environment, CACTI trains a single policy on 18 semantic tasks across up to 50 layout variations per task. The simulation task benchmark and augmented datasets in both real and simulated environments will be released to facilitate future research.
MoDem: Accelerating Visual Model-Based Reinforcement Learning with Demonstrations
Dec 12, 2022



Poor sample efficiency continues to be the primary challenge for deployment of deep Reinforcement Learning (RL) algorithms for real-world applications, and in particular for visuo-motor control. Model-based RL has the potential to be highly sample efficient by concurrently learning a world model and using synthetic rollouts for planning and policy improvement. However, in practice, sample-efficient learning with model-based RL is bottlenecked by the exploration challenge. In this work, we find that leveraging just a handful of demonstrations can dramatically improve the sample-efficiency of model-based RL. Simply appending demonstrations to the interaction dataset, however, does not suffice. We identify key ingredients for leveraging demonstrations in model learning -- policy pretraining, targeted exploration, and oversampling of demonstration data -- which forms the three phases of our model-based RL framework. We empirically study three complex visuo-motor control domains and find that our method is 150%-250% more successful in completing sparse reward tasks compared to prior approaches in the low data regime (100K interaction steps, 5 demonstrations). Code and videos are available at: https://nicklashansen.github.io/modemrl
Visual Dexterity: In-hand Dexterous Manipulation from Depth
Nov 21, 2022In-hand object reorientation is necessary for performing many dexterous manipulation tasks, such as tool use in unstructured environments that remain beyond the reach of current robots. Prior works built reorientation systems that assume one or many of the following specific circumstances: reorienting only specific objects with simple shapes, limited range of reorientation, slow or quasistatic manipulation, the need for specialized and costly sensor suites, simulation-only results, and other constraints which make the system infeasible for real-world deployment. We overcome these limitations and present a general object reorientation controller that is trained using reinforcement learning in simulation and evaluated in the real world. Our system uses readings from a single commodity depth camera to dynamically reorient complex objects by any amount in real time. The controller generalizes to novel objects not used during training. It is successful in the most challenging test: the ability to reorient objects in the air held by a downward-facing hand that must counteract gravity during reorientation. The results demonstrate that the policy transfer from simulation to the real world can be accomplished even for dynamic and contact-rich tasks. Lastly, our hardware only uses open-source components that cost less than five thousand dollars. Such construction makes it possible to replicate the work and democratize future research in dexterous manipulation. Videos are available at: https://taochenshh.github.io/projects/visual-dexterity.
CoNMix for Source-free Single and Multi-target Domain Adaptation
Nov 07, 2022This work introduces the novel task of Source-free Multi-target Domain Adaptation and proposes adaptation framework comprising of \textbf{Co}nsistency with \textbf{N}uclear-Norm Maximization and \textbf{Mix}Up knowledge distillation (\textit{CoNMix}) as a solution to this problem. The main motive of this work is to solve for Single and Multi target Domain Adaptation (SMTDA) for the source-free paradigm, which enforces a constraint where the labeled source data is not available during target adaptation due to various privacy-related restrictions on data sharing. The source-free approach leverages target pseudo labels, which can be noisy, to improve the target adaptation. We introduce consistency between label preserving augmentations and utilize pseudo label refinement methods to reduce noisy pseudo labels. Further, we propose novel MixUp Knowledge Distillation (MKD) for better generalization on multiple target domains using various source-free STDA models. We also show that the Vision Transformer (VT) backbone gives better feature representation with improved domain transferability and class discriminability. Our proposed framework achieves the state-of-the-art (SOTA) results in various paradigms of source-free STDA and MTDA settings on popular domain adaptation datasets like Office-Home, Office-Caltech, and DomainNet. Project Page: https://sites.google.com/view/conmix-vcl
All the Feels: A dexterous hand with large area sensing
Oct 27, 2022



High cost and lack of reliability has precluded the widespread adoption of dexterous hands in robotics. Furthermore, the lack of a viable tactile sensor capable of sensing over the entire area of the hand impedes the rich, low-level feedback that would improve learning of dexterous manipulation skills. This paper introduces an inexpensive, modular, robust, and scalable platform - the DManus- aimed at resolving these challenges while satisfying the large-scale data collection capabilities demanded by deep robot learning paradigms. Studies on human manipulation point to the criticality of low-level tactile feedback in performing everyday dexterous tasks. The DManus comes with ReSkin sensing on the entire surface of the palm as well as the fingertips. We demonstrate effectiveness of the fully integrated system in a tactile aware task - bin picking and sorting. Code, documentation, design files, detailed assembly instructions, trained models, task videos, and all supplementary materials required to recreate the setup can be found on http://roboticsbenchmarks.org/platforms/dmanus
Real World Offline Reinforcement Learning with Realistic Data Source
Oct 12, 2022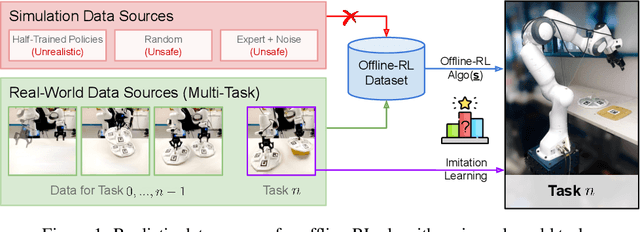

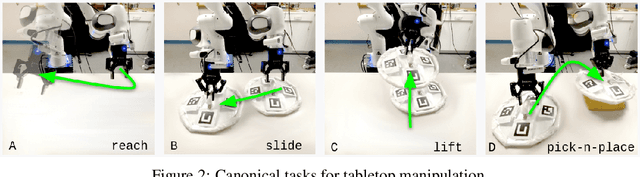
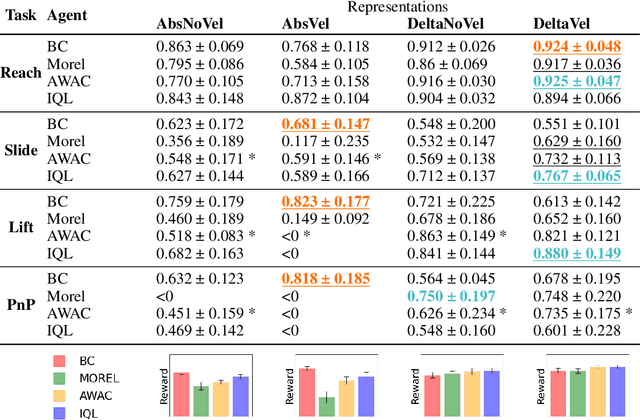
Offline reinforcement learning (ORL) holds great promise for robot learning due to its ability to learn from arbitrary pre-generated experience. However, current ORL benchmarks are almost entirely in simulation and utilize contrived datasets like replay buffers of online RL agents or sub-optimal trajectories, and thus hold limited relevance for real-world robotics. In this work (Real-ORL), we posit that data collected from safe operations of closely related tasks are more practical data sources for real-world robot learning. Under these settings, we perform an extensive (6500+ trajectories collected over 800+ robot hours and 270+ human labor hour) empirical study evaluating generalization and transfer capabilities of representative ORL methods on four real-world tabletop manipulation tasks. Our study finds that ORL and imitation learning prefer different action spaces, and that ORL algorithms can generalize from leveraging offline heterogeneous data sources and outperform imitation learning. We release our dataset and implementations at URL: https://sites.google.com/view/real-orl
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Sep 30, 2022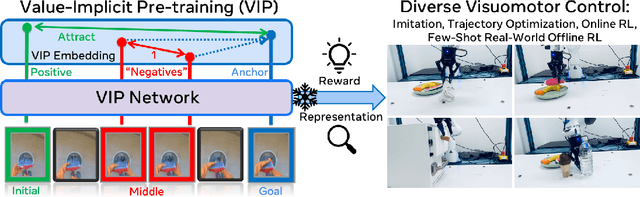

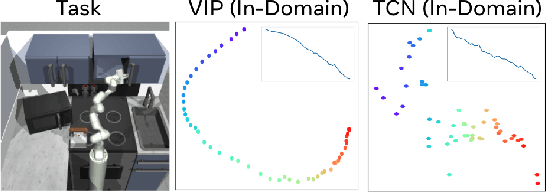
Reward and representation learning are two long-standing challenges for learning an expanding set of robot manipulation skills from sensory observations. Given the inherent cost and scarcity of in-domain, task-specific robot data, learning from large, diverse, offline human videos has emerged as a promising path towards acquiring a generally useful visual representation for control; however, how these human videos can be used for general-purpose reward learning remains an open question. We introduce $\textbf{V}$alue-$\textbf{I}$mplicit $\textbf{P}$re-training (VIP), a self-supervised pre-trained visual representation capable of generating dense and smooth reward functions for unseen robotic tasks. VIP casts representation learning from human videos as an offline goal-conditioned reinforcement learning problem and derives a self-supervised dual goal-conditioned value-function objective that does not depend on actions, enabling pre-training on unlabeled human videos. Theoretically, VIP can be understood as a novel implicit time contrastive objective that generates a temporally smooth embedding, enabling the value function to be implicitly defined via the embedding distance, which can then be used to construct the reward for any goal-image specified downstream task. Trained on large-scale Ego4D human videos and without any fine-tuning on in-domain, task-specific data, VIP's frozen representation can provide dense visual reward for an extensive set of simulated and $\textbf{real-robot}$ tasks, enabling diverse reward-based visual control methods and significantly outperforming all prior pre-trained representations. Notably, VIP can enable simple, $\textbf{few-shot}$ offline RL on a suite of real-world robot tasks with as few as 20 trajectories.
Learning Dexterous Manipulation from Exemplar Object Trajectories and Pre-Grasps
Sep 22, 2022
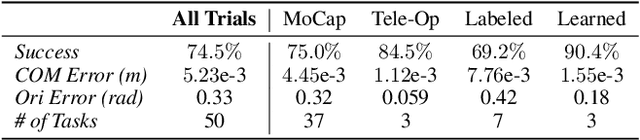
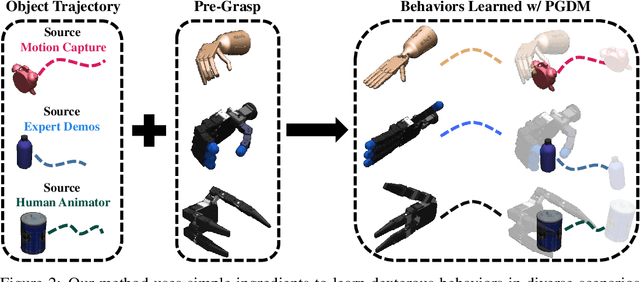

Learning diverse dexterous manipulation behaviors with assorted objects remains an open grand challenge. While policy learning methods offer a powerful avenue to attack this problem, they require extensive per-task engineering and algorithmic tuning. This paper seeks to escape these constraints, by developing a Pre-Grasp informed Dexterous Manipulation (PGDM) framework that generates diverse dexterous manipulation behaviors, without any task-specific reasoning or hyper-parameter tuning. At the core of PGDM is a well known robotics construct, pre-grasps (i.e. the hand-pose preparing for object interaction). This simple primitive is enough to induce efficient exploration strategies for acquiring complex dexterous manipulation behaviors. To exhaustively verify these claims, we introduce TCDM, a benchmark of 50 diverse manipulation tasks defined over multiple objects and dexterous manipulators. Tasks for TCDM are defined automatically using exemplar object trajectories from various sources (animators, human behaviors, etc.), without any per-task engineering and/or supervision. Our experiments validate that PGDM's exploration strategy, induced by a surprisingly simple ingredient (single pre-grasp pose), matches the performance of prior methods, which require expensive per-task feature/reward engineering, expert supervision, and hyper-parameter tuning. For animated visualizations, trained policies, and project code, please refer to: https://pregrasps.github.io/
MyoSuite -- A contact-rich simulation suite for musculoskeletal motor control
May 26, 2022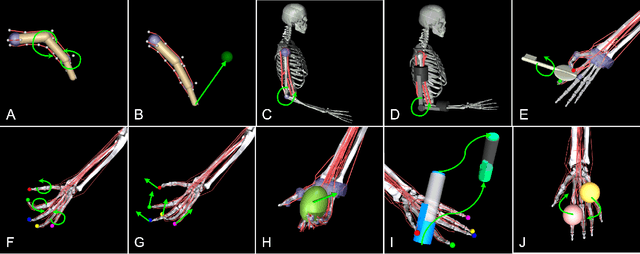
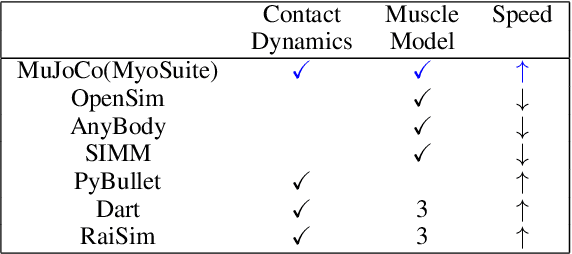
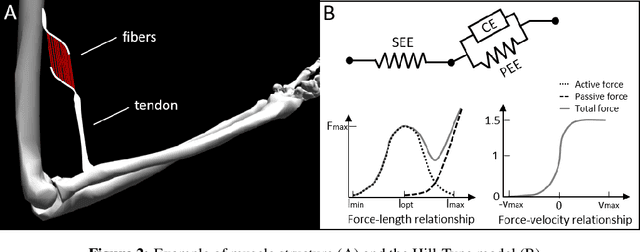
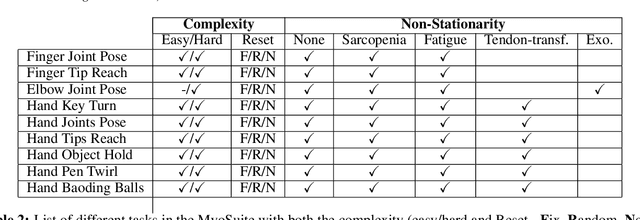
Embodied agents in continuous control domains have had limited exposure to tasks allowing to explore musculoskeletal properties that enable agile and nimble behaviors in biological beings. The sophistication behind neuro-musculoskeletal control can pose new challenges for the motor learning community. At the same time, agents solving complex neural control problems allow impact in fields such as neuro-rehabilitation, as well as collaborative-robotics. Human biomechanics underlies complex multi-joint-multi-actuator musculoskeletal systems. The sensory-motor system relies on a range of sensory-contact rich and proprioceptive inputs that define and condition muscle actuation required to exhibit intelligent behaviors in the physical world. Current frameworks for musculoskeletal control do not support physiological sophistication of the musculoskeletal systems along with physical world interaction capabilities. In addition, they are neither embedded in complex and skillful motor tasks nor are computationally effective and scalable to study large-scale learning paradigms. Here, we present MyoSuite -- a suite of physiologically accurate biomechanical models of elbow, wrist, and hand, with physical contact capabilities, which allow learning of complex and skillful contact-rich real-world tasks. We provide diverse motor-control challenges: from simple postural control to skilled hand-object interactions such as turning a key, twirling a pen, rotating two balls in one hand, etc. By supporting physiological alterations in musculoskeletal geometry (tendon transfer), assistive devices (exoskeleton assistance), and muscle contraction dynamics (muscle fatigue, sarcopenia), we present real-life tasks with temporal changes, thereby exposing realistic non-stationary conditions in our tasks which most continuous control benchmarks lack.