 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXRBench: An Extended Reality (XR) Machine Learning Benchmark Suite for the Metaverse
Nov 16, 2022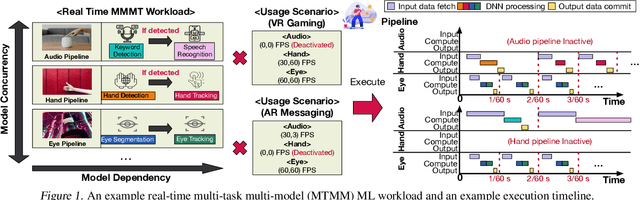
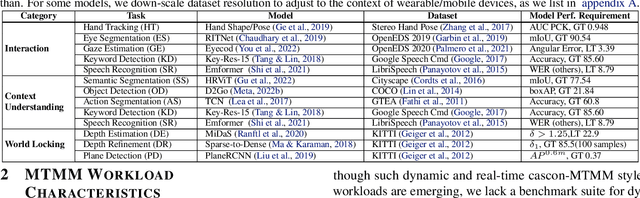

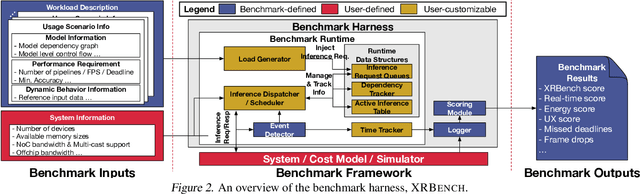
Real-time multi-model multi-task (MMMT) workloads, a new form of deep learning inference workloads, are emerging for applications areas like extended reality (XR) to support metaverse use cases. These workloads combine user interactivity with computationally complex machine learning (ML) activities. Compared to standard ML applications, these ML workloads present unique difficulties and constraints. Real-time MMMT workloads impose heterogeneity and concurrency requirements on future ML systems and devices, necessitating the development of new capabilities. This paper begins with a discussion of the various characteristics of these real-time MMMT ML workloads and presents an ontology for evaluating the performance of future ML hardware for XR systems. Next, we present XRBench, a collection of MMMT ML tasks, models, and usage scenarios that execute these models in three representative ways: cascaded, concurrent, and cascaded-concurrency for XR use cases. Finally, we emphasize the need for new metrics that capture the requirements properly. We hope that our work will stimulate research and lead to the development of a new generation of ML systems for XR use cases.
DataPerf: Benchmarks for Data-Centric AI Development
Jul 20, 2022
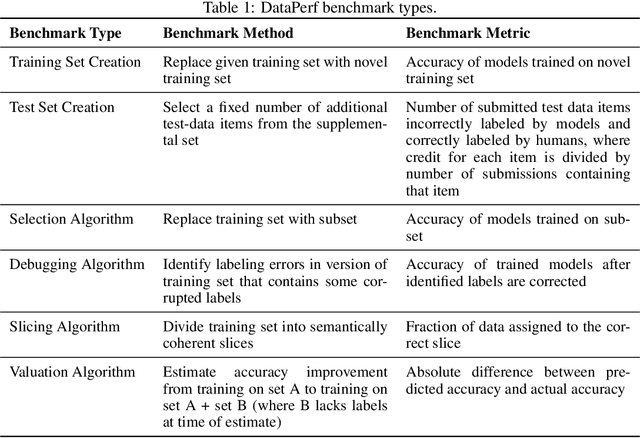
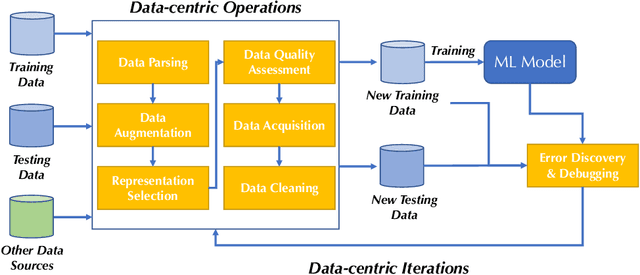
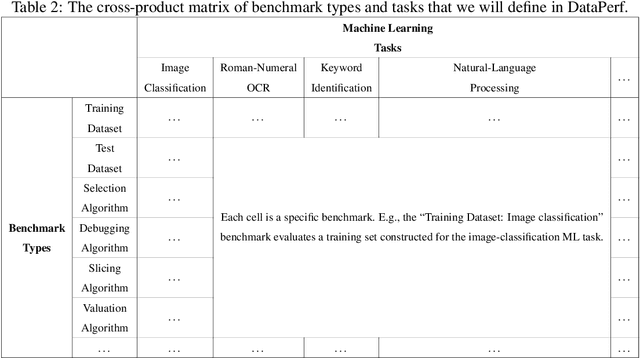
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.
FastML Science Benchmarks: Accelerating Real-Time Scientific Edge Machine Learning
Jul 16, 2022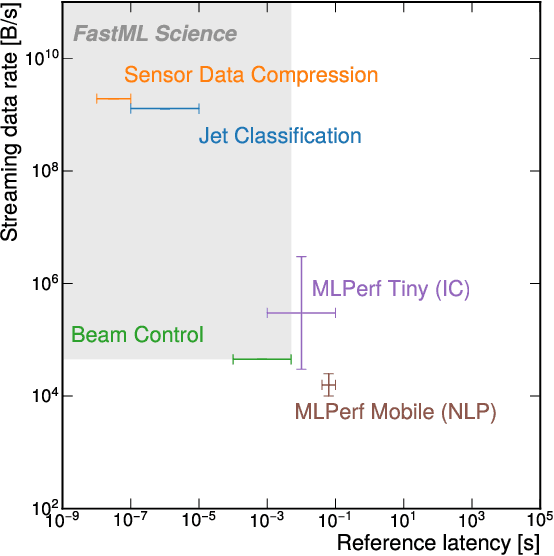
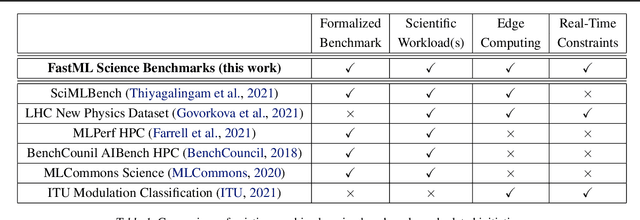
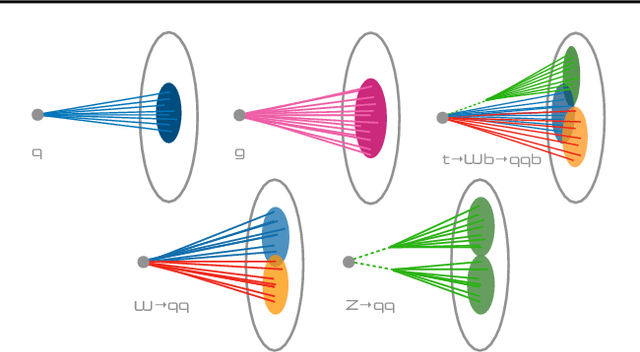

Applications of machine learning (ML) are growing by the day for many unique and challenging scientific applications. However, a crucial challenge facing these applications is their need for ultra low-latency and on-detector ML capabilities. Given the slowdown in Moore's law and Dennard scaling, coupled with the rapid advances in scientific instrumentation that is resulting in growing data rates, there is a need for ultra-fast ML at the extreme edge. Fast ML at the edge is essential for reducing and filtering scientific data in real-time to accelerate science experimentation and enable more profound insights. To accelerate real-time scientific edge ML hardware and software solutions, we need well-constrained benchmark tasks with enough specifications to be generically applicable and accessible. These benchmarks can guide the design of future edge ML hardware for scientific applications capable of meeting the nanosecond and microsecond level latency requirements. To this end, we present an initial set of scientific ML benchmarks, covering a variety of ML and embedded system techniques.
Machine Learning Sensors
Jun 07, 2022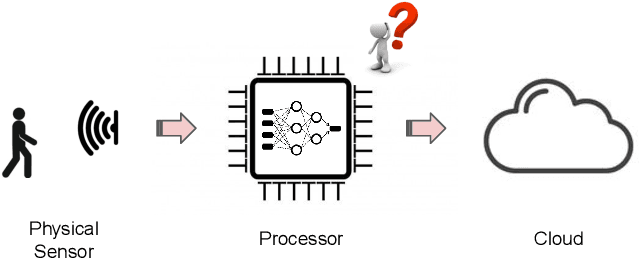
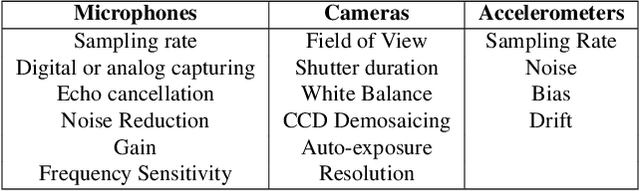
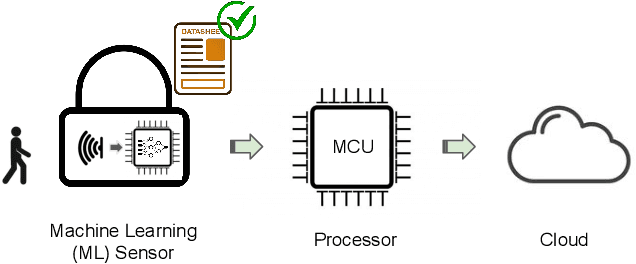
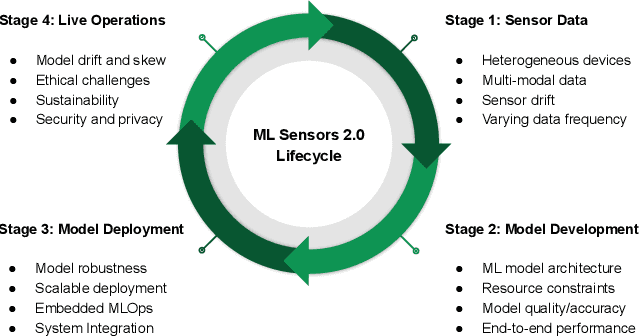
Machine learning sensors represent a paradigm shift for the future of embedded machine learning applications. Current instantiations of embedded machine learning (ML) suffer from complex integration, lack of modularity, and privacy and security concerns from data movement. This article proposes a more data-centric paradigm for embedding sensor intelligence on edge devices to combat these challenges. Our vision for "sensor 2.0" entails segregating sensor input data and ML processing from the wider system at the hardware level and providing a thin interface that mimics traditional sensors in functionality. This separation leads to a modular and easy-to-use ML sensor device. We discuss challenges presented by the standard approach of building ML processing into the software stack of the controlling microprocessor on an embedded system and how the modularity of ML sensors alleviates these problems. ML sensors increase privacy and accuracy while making it easier for system builders to integrate ML into their products as a simple component. We provide examples of prospective ML sensors and an illustrative datasheet as a demonstration and hope that this will build a dialogue to progress us towards sensor 2.0.
Robotic Computing on FPGAs: Current Progress, Research Challenges, and Opportunities
May 14, 2022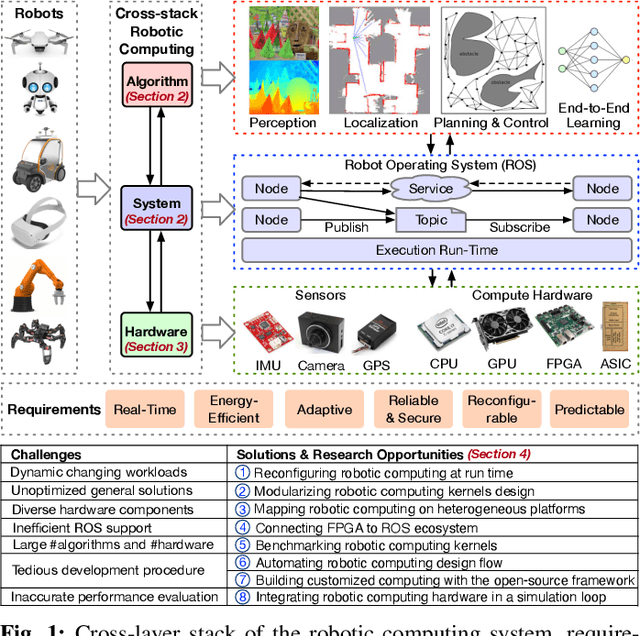
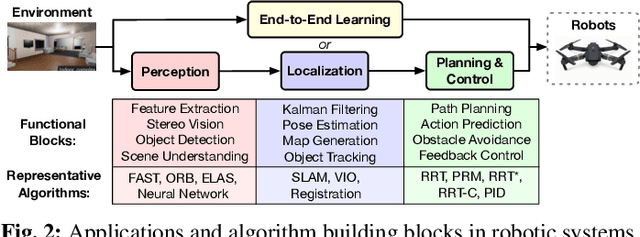
Robotic computing has reached a tipping point, with a myriad of robots (e.g., drones, self-driving cars, logistic robots) being widely applied in diverse scenarios. The continuous proliferation of robotics, however, critically depends on efficient computing substrates, driven by real-time requirements, robotic size-weight-and-power constraints, cybersecurity considerations, and dynamically changing scenarios. Within all platforms, FPGA is able to deliver both software and hardware solutions with low power, high performance, reconfigurability, reliability, and adaptivity characteristics, serving as the promising computing substrate for robotic applications. This paper highlights the current progress, design techniques, challenges, and open research challenges in the domain of robotic computing on FPGAs.
Tiny Robot Learning: Challenges and Directions for Machine Learning in Resource-Constrained Robots
May 11, 2022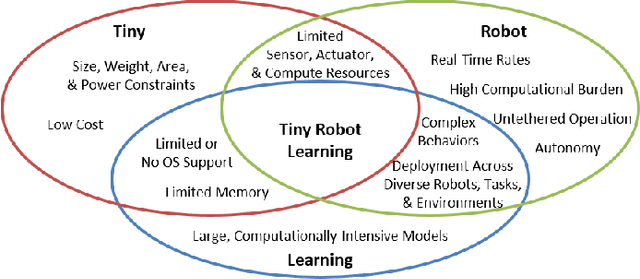
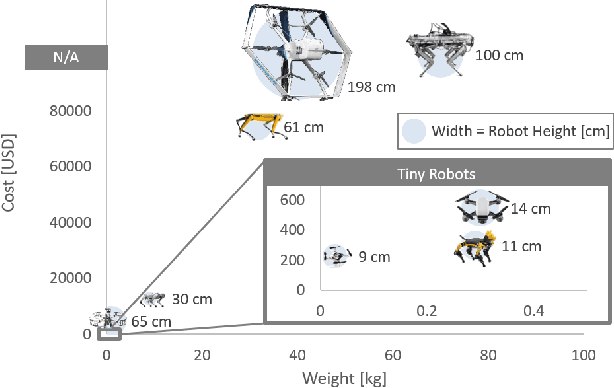
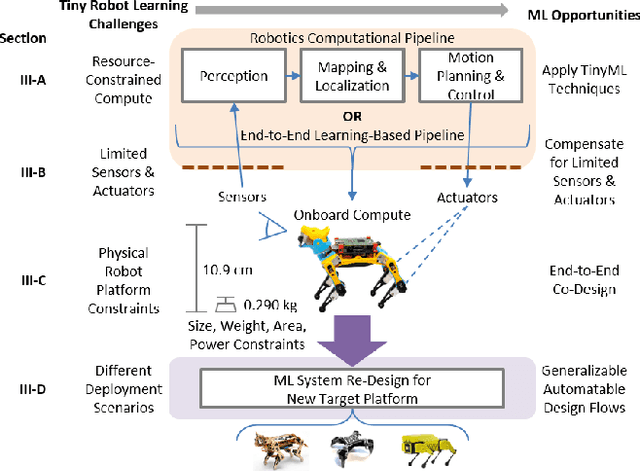
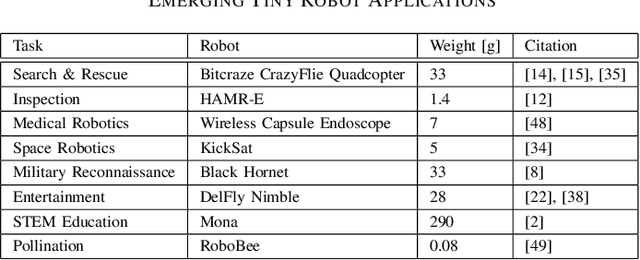
Machine learning (ML) has become a pervasive tool across computing systems. An emerging application that stress-tests the challenges of ML system design is tiny robot learning, the deployment of ML on resource-constrained low-cost autonomous robots. Tiny robot learning lies at the intersection of embedded systems, robotics, and ML, compounding the challenges of these domains. Tiny robot learning is subject to challenges from size, weight, area, and power (SWAP) constraints; sensor, actuator, and compute hardware limitations; end-to-end system tradeoffs; and a large diversity of possible deployment scenarios. Tiny robot learning requires ML models to be designed with these challenges in mind, providing a crucible that reveals the necessity of holistic ML system design and automated end-to-end design tools for agile development. This paper gives a brief survey of the tiny robot learning space, elaborates on key challenges, and proposes promising opportunities for future work in ML system design.
RobotCore: An Open Architecture for Hardware Acceleration in ROS 2
May 08, 2022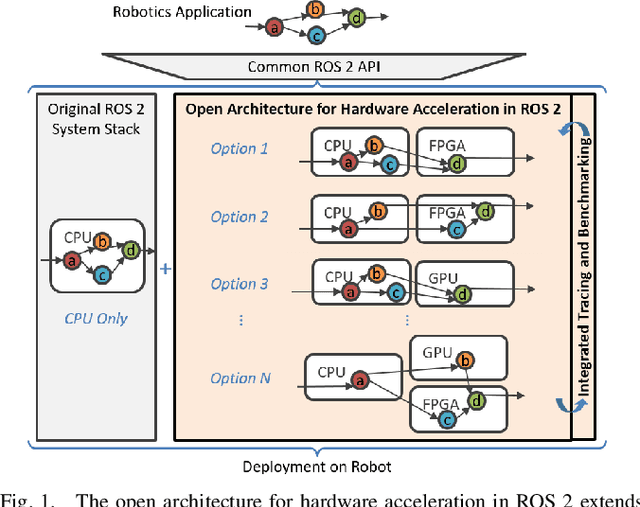
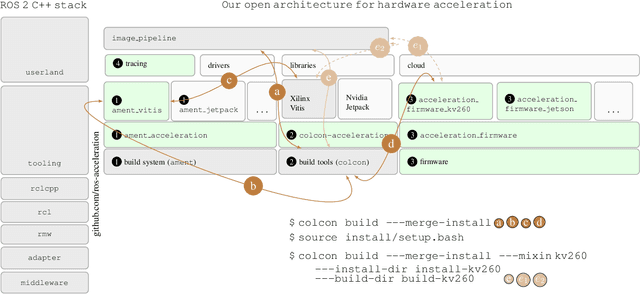
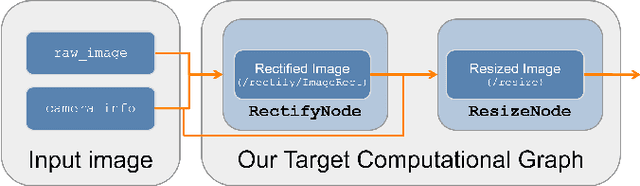
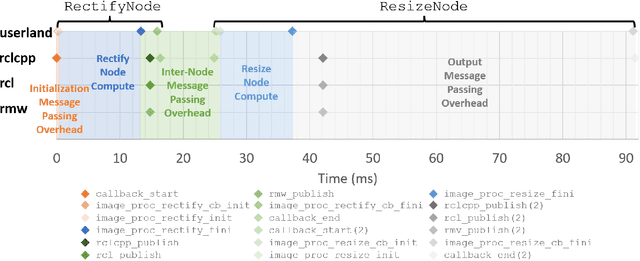
Hardware acceleration can revolutionize robotics, enabling new applications by speeding up robot response times while remaining power-efficient. However, the diversity of acceleration options makes it difficult for roboticists to easily deploy accelerated systems without expertise in each specific hardware platform. In this work, we address this challenge with RobotCore, an architecture to integrate hardware acceleration in the widely-used ROS 2 robotics software framework. This architecture is target-agnostic (supports edge, workstation, data center, or cloud targets) and accelerator-agnostic (supports both FPGAs and GPUs). It builds on top of the common ROS 2 build system and tools and is easily portable across different research and commercial solutions through a new firmware layer. We also leverage the Linux Tracing Toolkit next generation (LTTng) for low-overhead real-time tracing and benchmarking. To demonstrate the acceleration enabled by this architecture, we use it to deploy a ROS 2 perception computational graph on a CPU and FPGA. We employ our integrated tracing and benchmarking to analyze bottlenecks, uncovering insights that guide us to improve FPGA communication efficiency. In particular, we design an intra-FPGA ROS 2 node communication queue to enable faster data flows, and use it in conjunction with FPGA-accelerated nodes to achieve a 24.42% speedup over a CPU.
Zhuyi: Perception Processing Rate Estimation for Safety in Autonomous Vehicles
May 06, 2022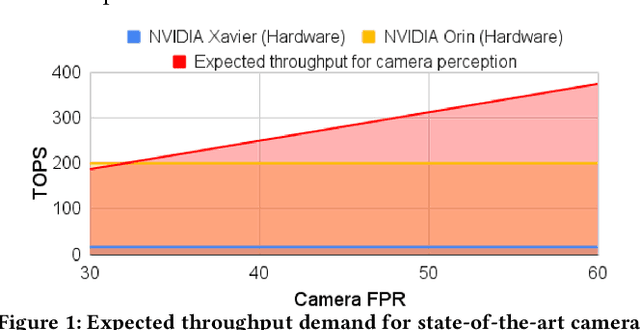

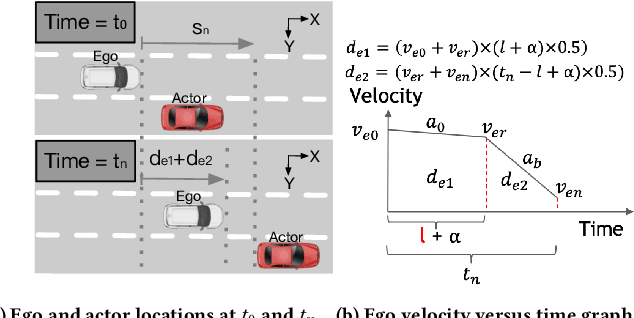
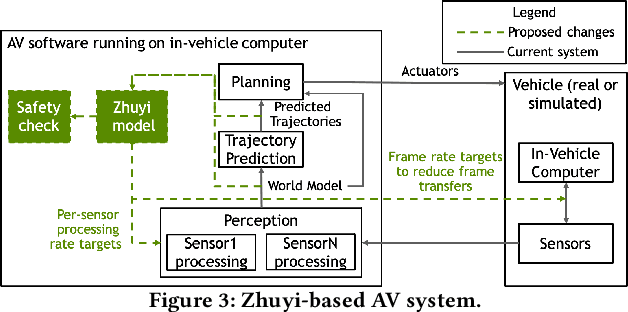
The processing requirement of autonomous vehicles (AVs) for high-accuracy perception in complex scenarios can exceed the resources offered by the in-vehicle computer, degrading safety and comfort. This paper proposes a sensor frame processing rate (FPR) estimation model, Zhuyi, that quantifies the minimum safe FPR continuously in a driving scenario. Zhuyi can be employed post-deployment as an online safety check and to prioritize work. Experiments conducted using a multi-camera state-of-the-art industry AV system show that Zhuyi's estimated FPRs are conservative, yet the system can maintain safety by processing only 36% or fewer frames compared to a default 30-FPR system in the tested scenarios.
OMU: A Probabilistic 3D Occupancy Mapping Accelerator for Real-time OctoMap at the Edge
May 06, 2022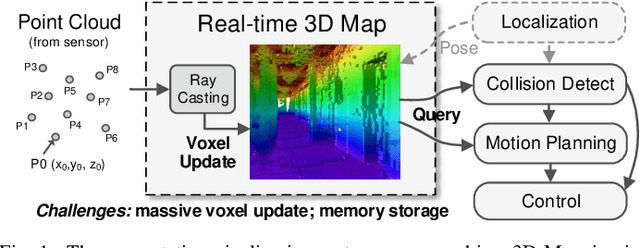
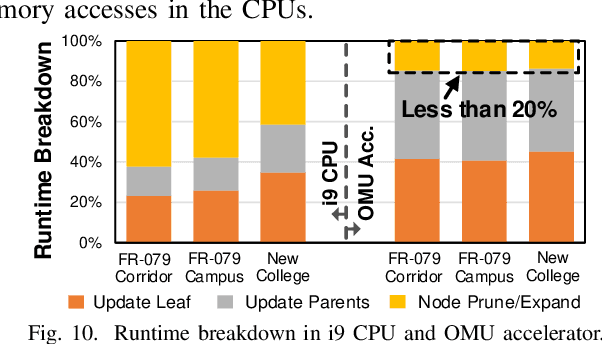
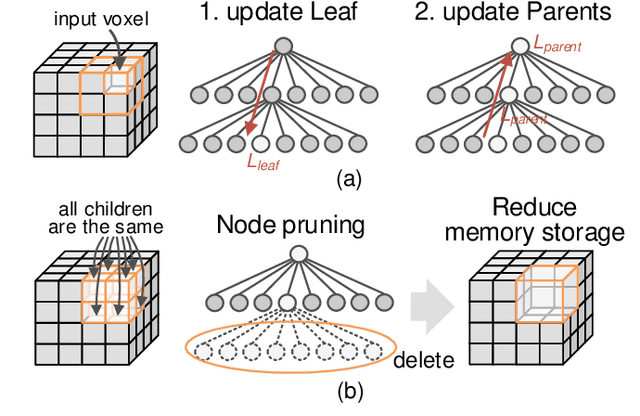
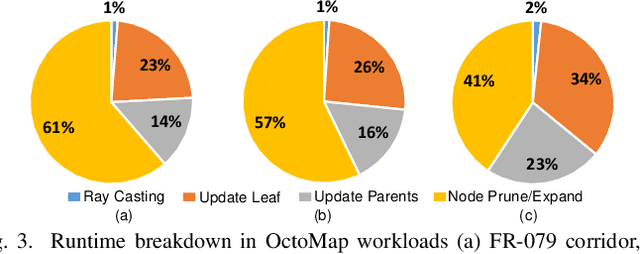
Autonomous machines (e.g., vehicles, mobile robots, drones) require sophisticated 3D mapping to perceive the dynamic environment. However, maintaining a real-time 3D map is expensive both in terms of compute and memory requirements, especially for resource-constrained edge machines. Probabilistic OctoMap is a reliable and memory-efficient 3D dense map model to represent the full environment, with dynamic voxel node pruning and expansion capacity. This paper presents the first efficient accelerator solution, i.e. OMU, to enable real-time probabilistic 3D mapping at the edge. To improve the performance, the input map voxels are updated via parallel PE units for data parallelism. Within each PE, the voxels are stored using a specially developed data structure in parallel memory banks. In addition, a pruning address manager is designed within each PE unit to reuse the pruned memory addresses. The proposed 3D mapping accelerator is implemented and evaluated using a commercial 12 nm technology. Compared to the ARM Cortex-A57 CPU in the Nvidia Jetson TX2 platform, the proposed accelerator achieves up to 62$\times$ performance and 708$\times$ energy efficiency improvement. Furthermore, the accelerator provides 63 FPS throughput, more than 2$\times$ higher than a real-time requirement, enabling real-time perception for 3D mapping.
Roofline Model for UAVs: A Bottleneck Analysis Tool for Onboard Compute Characterization of Autonomous Unmanned Aerial Vehicles
Apr 22, 2022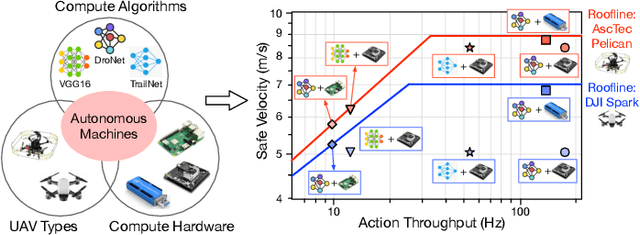
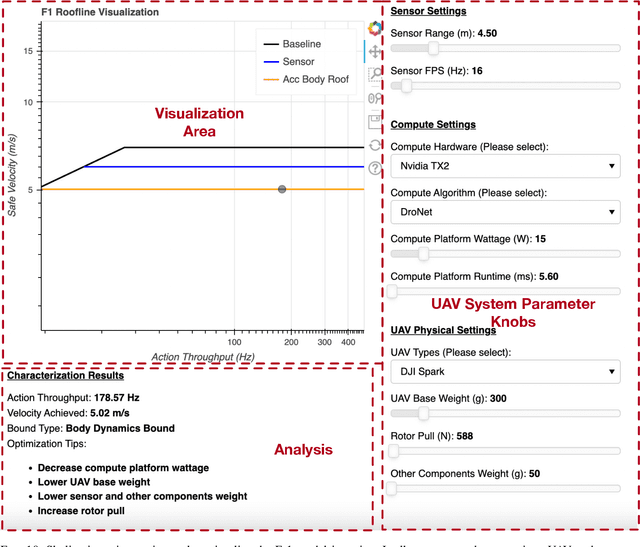
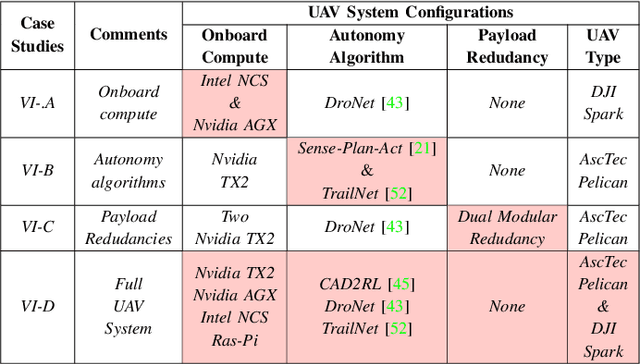
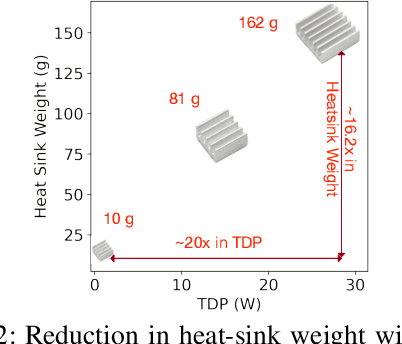
We introduce an early-phase bottleneck analysis and characterization model called the F-1 for designing computing systems that target autonomous Unmanned Aerial Vehicles (UAVs). The model provides insights by exploiting the fundamental relationships between various components in the autonomous UAV, such as sensor, compute, and body dynamics. To guarantee safe operation while maximizing the performance (e.g., velocity) of the UAV, the compute, sensor, and other mechanical properties must be carefully selected or designed. The F-1 model provides visual insights that can aid a system architect in understanding the optimal compute design or selection for autonomous UAVs. The model is experimentally validated using real UAVs, and the error is between 5.1\% to 9.5\% compared to real-world flight tests. An interactive web-based tool for the F-1 model called Skyline is available for free of cost use at: ~\url{https://bit.ly/skyline-tool}