 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Models Improve Visual Robustness in Robotic Learners
Apr 29, 2024



Visual control policies can encounter significant performance degradation when visual conditions like lighting or camera position differ from those seen during training -- often exhibiting sharp declines in capability even for minor differences. In this work, we examine robustness to a suite of these types of visual changes for RGB-D and point cloud based visual control policies. To perform these experiments on both model-free and model-based reinforcement learners, we introduce a novel Point Cloud World Model (PCWM) and point cloud based control policies. Our experiments show that policies that explicitly encode point clouds are significantly more robust than their RGB-D counterparts. Further, we find our proposed PCWM significantly outperforms prior works in terms of sample efficiency during training. Taken together, these results suggest reasoning about the 3D scene through point clouds can improve performance, reduce learning time, and increase robustness for robotic learners. Project Webpage: https://pvskand.github.io/projects/PCWM
dpVAEs: Fixing Sample Generation for Regularized VAEs
Nov 24, 2019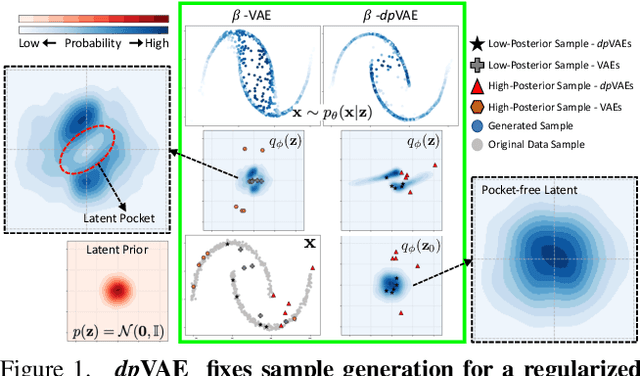
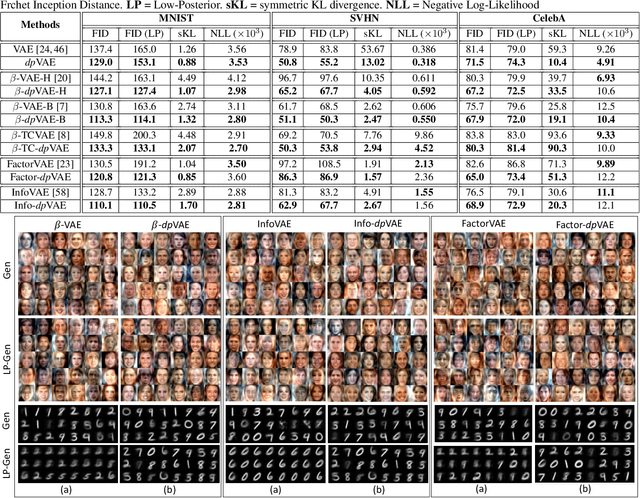
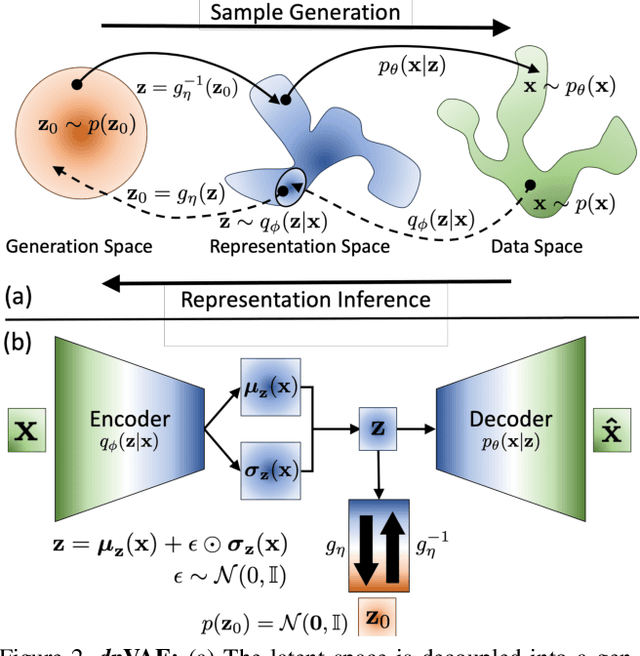
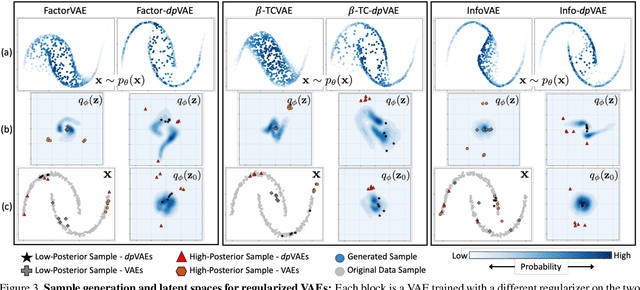
Unsupervised representation learning via generative modeling is a staple to many computer vision applications in the absence of labeled data. Variational Autoencoders (VAEs) are powerful generative models that learn representations useful for data generation. However, due to inherent challenges in the training objective, VAEs fail to learn useful representations amenable for downstream tasks. Regularization-based methods that attempt to improve the representation learning aspect of VAEs come at a price: poor sample generation. In this paper, we explore this representation-generation trade-off for regularized VAEs and introduce a new family of priors, namely decoupled priors, or dpVAEs, that decouple the representation space from the generation space. This decoupling enables the use of VAE regularizers on the representation space without impacting the distribution used for sample generation, and thereby reaping the representation learning benefits of the regularizations without sacrificing the sample generation. dpVAE leverages invertible networks to learn a bijective mapping from an arbitrarily complex representation distribution to a simple, tractable, generative distribution. Decoupled priors can be adapted to the state-of-the-art VAE regularizers without additional hyperparameter tuning. We showcase the use of dpVAEs with different regularizers. Experiments on MNIST, SVHN, and CelebA demonstrate, quantitatively and qualitatively, that dpVAE fixes sample generation for regularized VAEs.
PageNet: Page Boundary Extraction in Historical Handwritten Documents
Sep 05, 2017
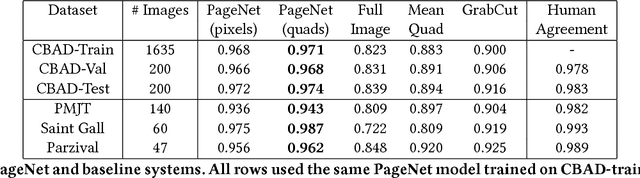

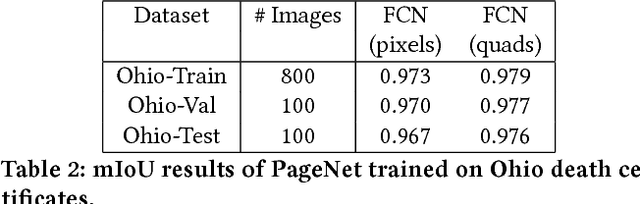
When digitizing a document into an image, it is common to include a surrounding border region to visually indicate that the entire document is present in the image. However, this border should be removed prior to automated processing. In this work, we present a deep learning based system, PageNet, which identifies the main page region in an image in order to segment content from both textual and non-textual border noise. In PageNet, a Fully Convolutional Network obtains a pixel-wise segmentation which is post-processed into the output quadrilateral region. We evaluate PageNet on 4 collections of historical handwritten documents and obtain over 94% mean intersection over union on all datasets and approach human performance on 2 of these collections. Additionally, we show that PageNet can segment documents that are overlayed on top of other documents.