 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Zero- and Few-Shot Learning via Aligned Variational Autoencoders
Dec 17, 2018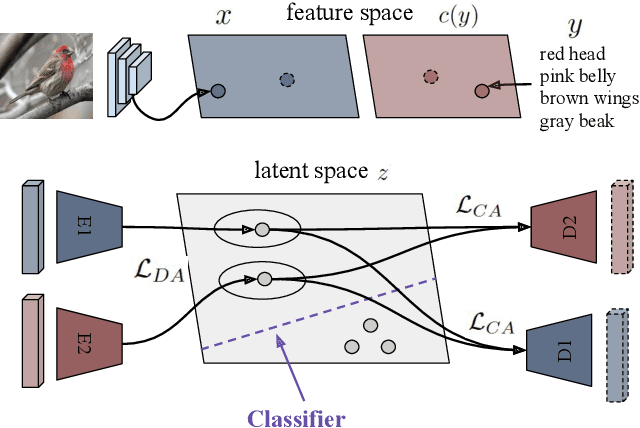

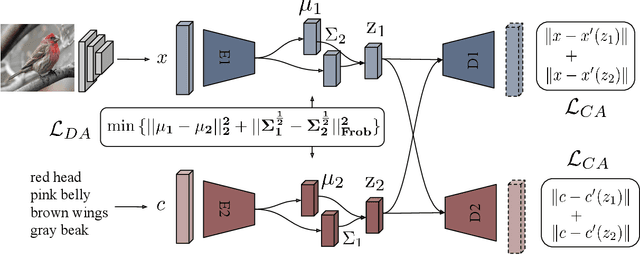
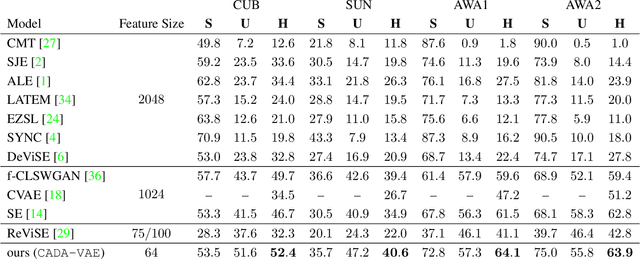
Many approaches in generalized zero-shot learning rely on cross-modal mapping between the image feature space and the class embedding space. As labeled images are rare, one direction is to augment the dataset by generating either images or image features. However, the former misses fine-grained details and the latter requires learning a mapping associated with class embeddings. In this work, we take feature generation one step further and propose a model where a shared latent space of image features and class embeddings is learned by modality-specific aligned variational autoencoders. This leaves us with the required discriminative information about the image and classes in the latent features, on which we train a softmax classifier. The key to our approach is that we align the distributions learned from images and from side-information to construct latent features that contain the essential multi-modal information associated with unseen classes. We evaluate our learned latent features on several benchmark datasets, i.e. CUB, SUN, AWA1 and AWA2, and establish a new state-of-the-art on generalized zero-shot as well as on few-shot learning. Moreover, our results on ImageNet with various zero-shot splits show that our latent features generalize well in large-scale settings.
Adversarial Inference for Multi-Sentence Video Description
Dec 13, 2018
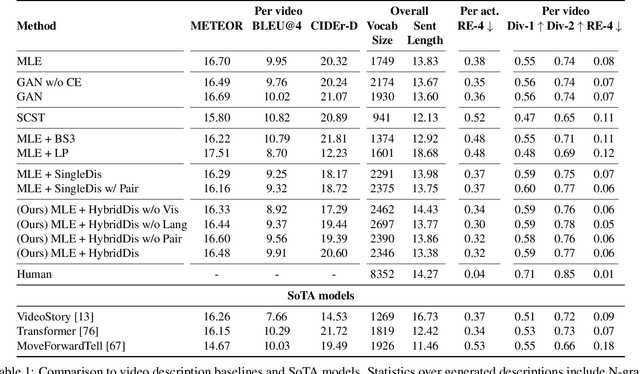
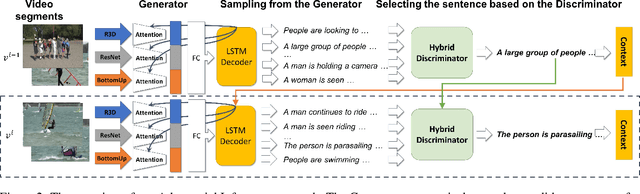
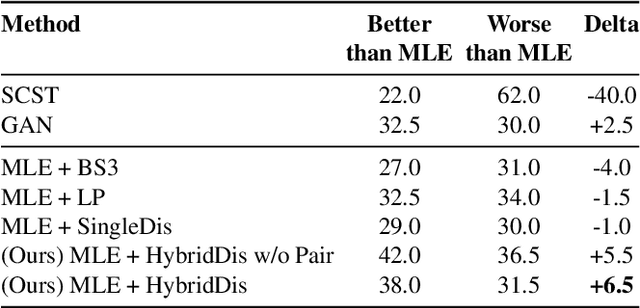
While significant progress has been made in the image captioning task, video description is still comparatively in its infancy, due to the complex nature of video data. Generating multi-sentence descriptions for long videos is even more challenging. Among the main issues are the fluency and coherence of the generated descriptions, and their relevance to the video. Recently, reinforcement and adversarial learning based methods have been explored to improve the image captioning models; however, both types of methods suffer from a number of issues, e.g. poor readability and high redundancy for RL and stability issues for GANs. In this work, we instead propose to apply adversarial techniques during inference, designing a discriminator which encourages better multi-sentence video description. In addition, we find that a multi-discriminator "hybrid" design, where each discriminator targets one aspect of a description, leads to the best results. Specifically, we decouple the discriminator to evaluate on three criteria: 1) visual relevance to the video, 2) language diversity and fluency, and 3) coherence across sentences. Our approach results in more accurate, diverse and coherent multi-sentence video descriptions, as shown by automatic as well as human evaluation on the popular ActivityNet Captions dataset.
Few-shot Object Detection via Feature Reweighting
Dec 05, 2018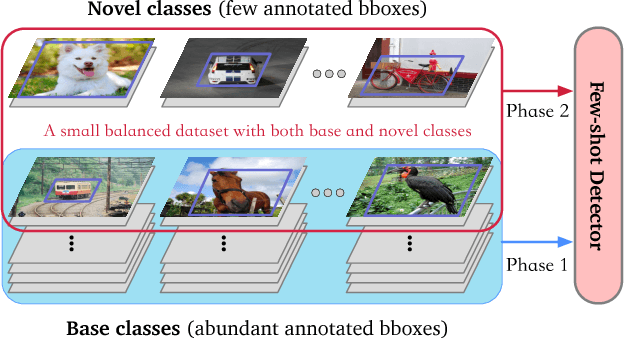
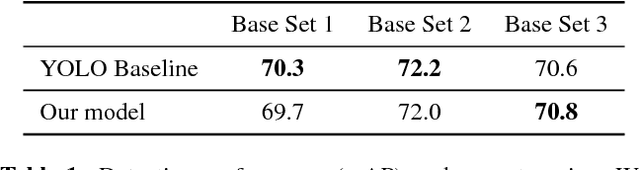
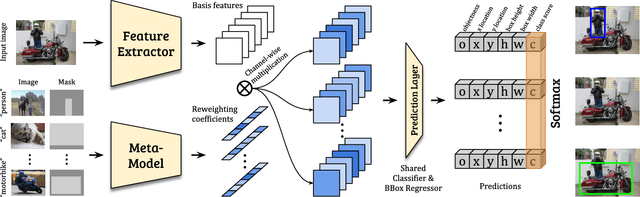
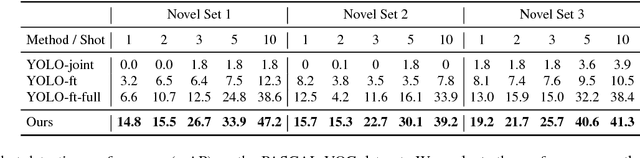
This work aims to solve the challenging few-shot object detection problem where only a few annotated examples are available for each object category to train a detection model. Such an ability of learning to detect an object from just a few examples is common for human vision systems, but remains absent for computer vision systems. Though few-shot meta learning offers a promising solution technique, previous works mostly target the task of image classification and are not directly applicable for the much more complicated object detection task. In this work, we propose a novel meta-learning based model with carefully designed architecture, which consists of a meta-model and a base detection model. The base detection model is trained on several base classes with sufficient samples to offer basis features. The meta-model is trained to reweight importance of features from the base detection model over the input image and adapt these features to assist novel object detection from a few examples. The meta-model is light-weight, end-to-end trainable and able to entail the base model with detection ability for novel objects fast. Through experiments we demonstrated our model can outperform baselines by a large margin for few-shot object detection, on multiple datasets and settings. Our model also exhibits fast adaptation speed to novel few-shot classes.
Classifying Collisions with Spatio-Temporal Action Graph Networks
Dec 04, 2018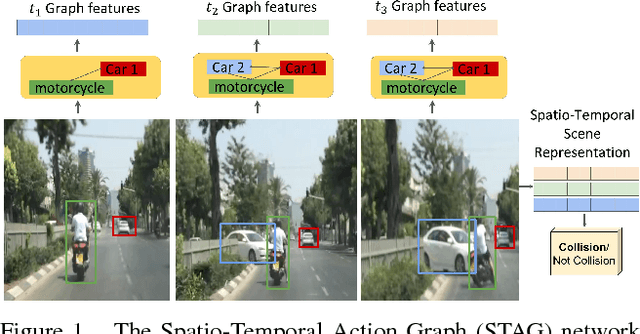
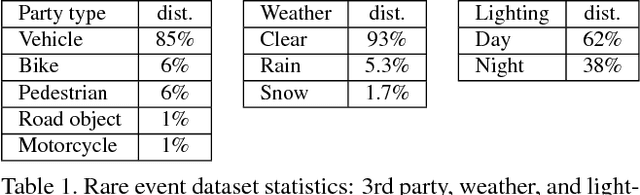
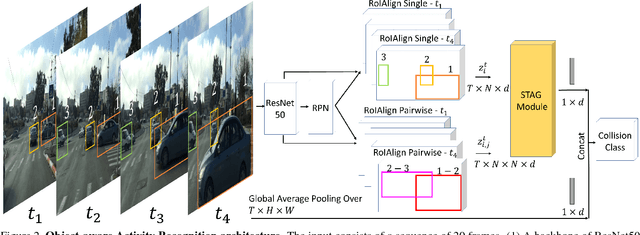
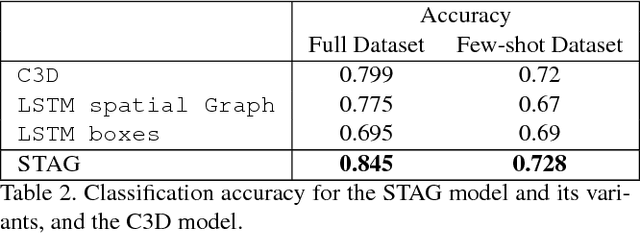
Events defined by the interaction of objects in a scene often are of critical importance, yet such events are typically rare and available labeled examples insufficient to train a conventional deep model that performs well across expected object appearances. Most deep learning activity recognition models focus on global context aggregation and do not explicitly consider object interactions inside the video, potentially overlooking important cues relevant to interpreting activity in the scene. In this paper, we show that a new model for explicit representation of object interactions significantly improves deep video activity classification for driving collision detection. We propose a Spatio-Temporal Action Graph (STAG) network, which incorporates spatial and temporal relations of objects. The network is automatically learned from data, with a latent graph structure inferred for the task. As a benchmark to evaluate performance on collision detection tasks, we introduce a novel data set based on data obtained from real life driving collisions and near-collisions. This data set reflects the challenging task of detecting and classifying accidents in a richly varying but yet highly constrained setting, that is very relevant to the evaluation of autonomous driving and alerting systems. Our experiments confirm that our STAG model offers significantly improved results for collision activity classification.
SPLAT: Semantic Pixel-Level Adaptation Transforms for Detection
Dec 03, 2018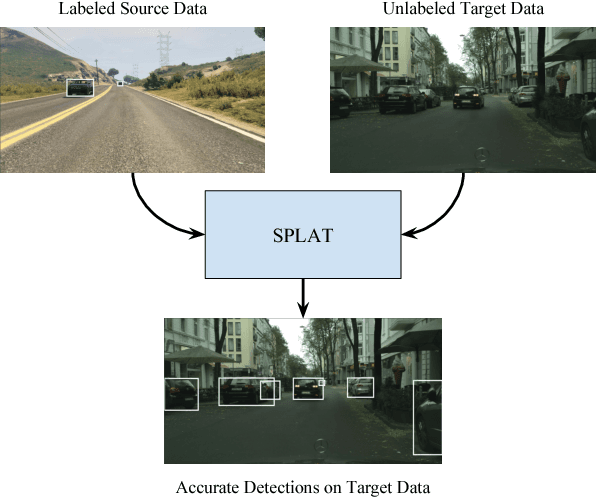
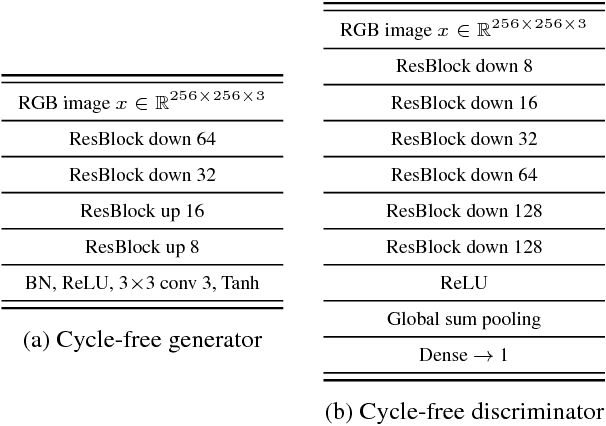
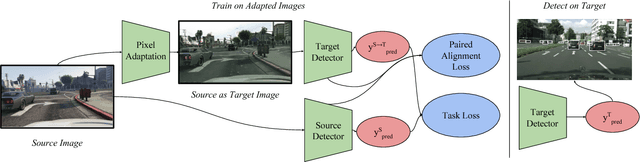
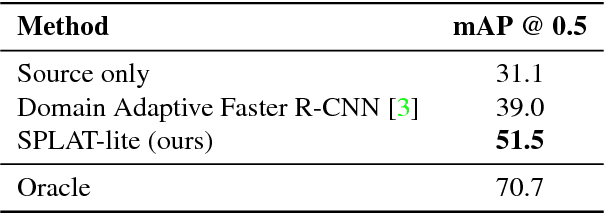
Domain adaptation of visual detectors is a critical challenge, yet existing methods have overlooked pixel appearance transformations, focusing instead on bootstrapping and/or domain confusion losses. We propose a Semantic Pixel-Level Adaptation Transform (SPLAT) approach to detector adaptation that efficiently generates cross-domain image pairs. Our model uses aligned-pair and/or pseudo-label losses to adapt an object detector to the target domain, and can learn transformations with or without densely labeled data in the source (e.g. semantic segmentation annotations). Without dense labels, as is the case when only detection labels are available in the source, transformations are learned using CycleGAN alignment. Otherwise, when dense labels are available we introduce a more efficient cycle-free method, which exploits pixel-level semantic labels to condition the training of the transformation network. The end task is then trained using detection box labels from the source, potentially including labels inferred on unlabeled source data. We show both that pixel-level transforms outperform prior approaches to detector domain adaptation, and that our cycle-free method outperforms prior models for unconstrained cycle-based learning of generic transformations while running 3.8 times faster. Our combined model improves on prior detection baselines by 12.5 mAP adapting from Sim 10K to Cityscapes, recovering over 50% of the missing performance between the unadapted baseline and the labeled-target upper bound.
Disentangling Propagation and Generation for Video Prediction
Dec 02, 2018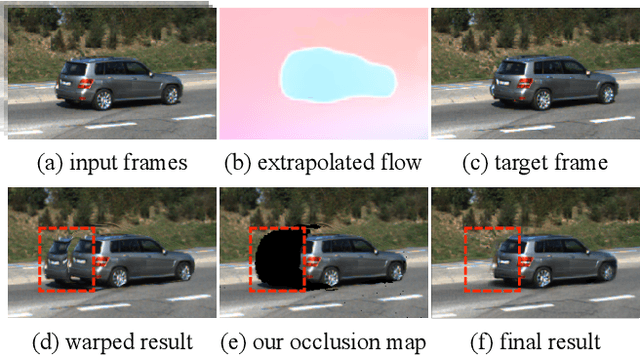
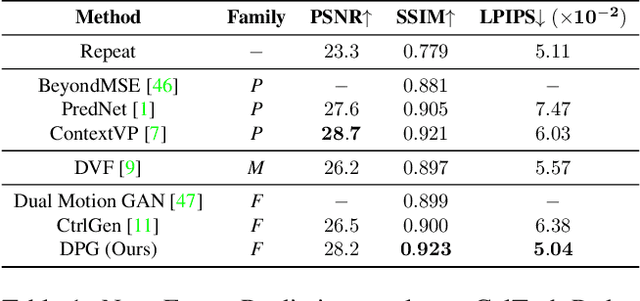
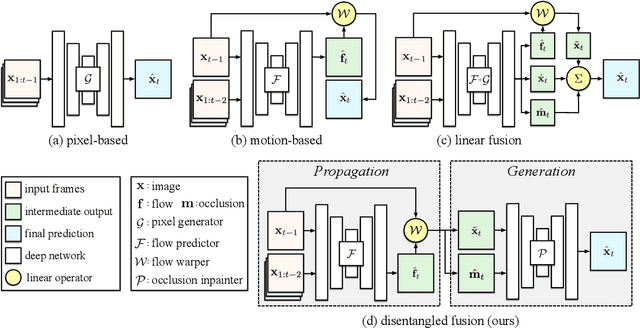
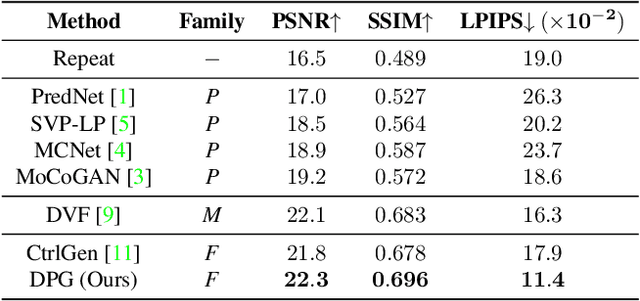
Learning to predict future video frames is a challenging task. Recent approaches for natural scenes directly predict pixels via inferring appearance flow and using flow-guided warping. Such models excel when motion estimates are accurate, but the motion may be ambiguous or erroneous in many real scenes. When scene motion exposes new regions of the scene, motion-based prediction yields poor results. However, learning to predict novel pixels directly can also require a prohibitive amount of training. In this work, we present a confidence-aware spatial-temporal context encoder for video prediction called Flow-Grounded Video Prediction (FGVP), in which motion propagation and novel pixel generation are first disentangled and then fused according to computed flow uncertainty map. For regions where motion-based prediction shows low-confidence, our model uses a conditional context encoder to hallucinate appropriate content. We test our methods on the standard CalTech Pedestrian dataset and the more challenging KITTI Flow dataset of larger motions and occlusions. Our methods produce both sharp and natural predictions compared to previous works, achieving the state-of-the-art performance on both datasets.
Joint Monocular 3D Vehicle Detection and Tracking
Dec 02, 2018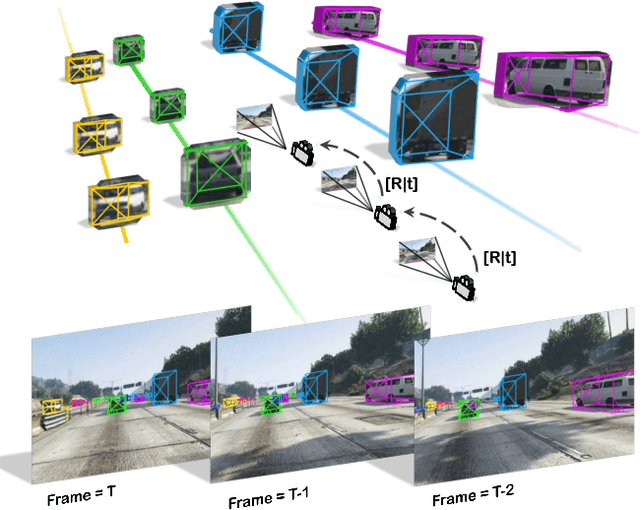
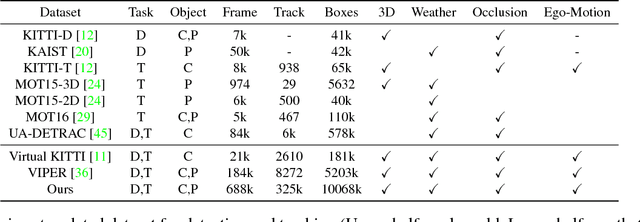
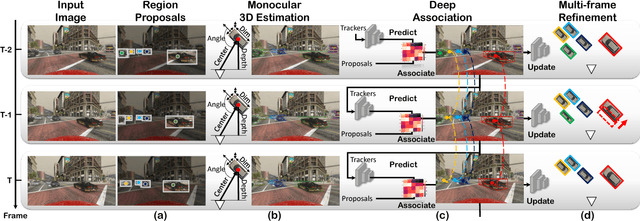
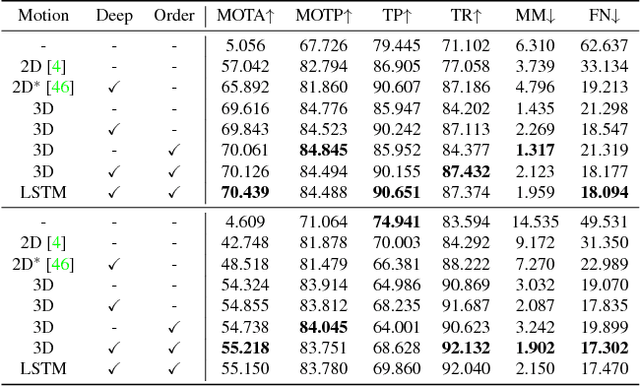
3D vehicle detection and tracking from a monocular camera requires detecting and associating vehicles, and estimating their locations and extents together. It is challenging because vehicles are in constant motion and it is practically impossible to recover the 3D positions from a single image. In this paper, we propose a novel framework that jointly detects and tracks 3D vehicle bounding boxes. Our approach leverages 3D pose estimation to learn 2D patch association overtime and uses temporal information from tracking to obtain stable 3D estimation. Our method also leverages 3D box depth ordering and motion to link together the tracks of occluded objects. We train our system on realistic 3D virtual environments, collecting a new diverse, large-scale and densely annotated dataset with accurate 3D trajectory annotations. Our experiments demonstrate that our method benefits from inferring 3D for both data association and tracking robustness, leveraging our dynamic 3D tracking dataset.
Modular Architecture for StarCraft II with Deep Reinforcement Learning
Nov 08, 2018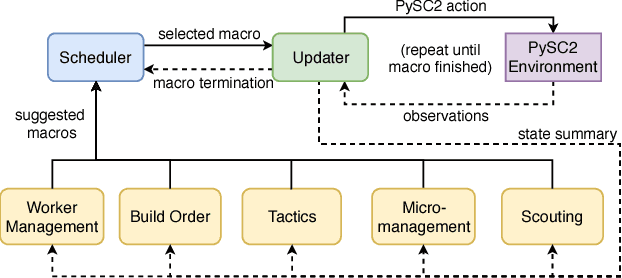

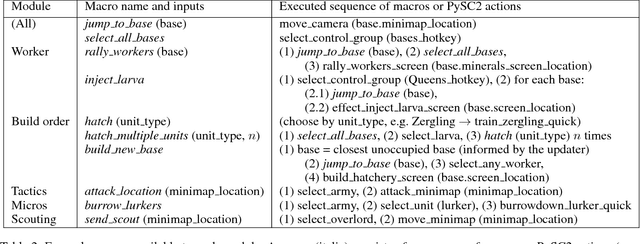
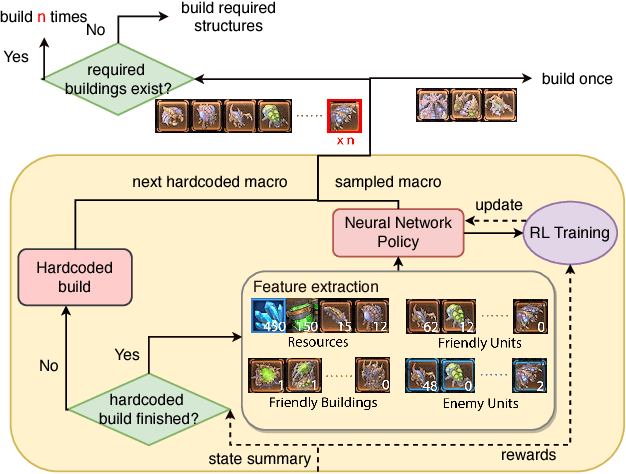
We present a novel modular architecture for StarCraft II AI. The architecture splits responsibilities between multiple modules that each control one aspect of the game, such as build-order selection or tactics. A centralized scheduler reviews macros suggested by all modules and decides their order of execution. An updater keeps track of environment changes and instantiates macros into series of executable actions. Modules in this framework can be optimized independently or jointly via human design, planning, or reinforcement learning. We apply deep reinforcement learning techniques to training two out of six modules of a modular agent with self-play, achieving 94% or 87% win rates against the "Harder" (level 5) built-in Blizzard bot in Zerg vs. Zerg matches, with or without fog-of-war.
Speaker-Follower Models for Vision-and-Language Navigation
Oct 27, 2018
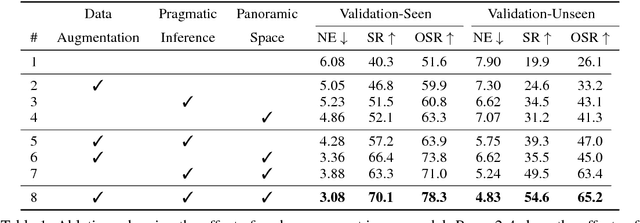
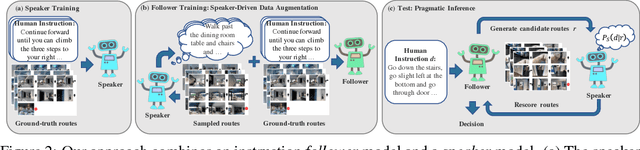
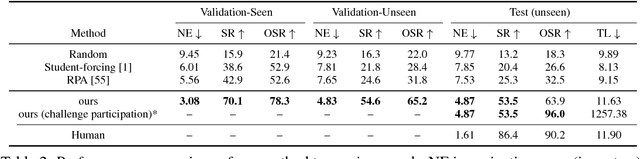
Navigation guided by natural language instructions presents a challenging reasoning problem for instruction followers. Natural language instructions typically identify only a few high-level decisions and landmarks rather than complete low-level motor behaviors; much of the missing information must be inferred based on perceptual context. In machine learning settings, this is doubly challenging: it is difficult to collect enough annotated data to enable learning of this reasoning process from scratch, and also difficult to implement the reasoning process using generic sequence models. Here we describe an approach to vision-and-language navigation that addresses both these issues with an embedded speaker model. We use this speaker model to (1) synthesize new instructions for data augmentation and to (2) implement pragmatic reasoning, which evaluates how well candidate action sequences explain an instruction. Both steps are supported by a panoramic action space that reflects the granularity of human-generated instructions. Experiments show that all three components of this approach---speaker-driven data augmentation, pragmatic reasoning and panoramic action space---dramatically improve the performance of a baseline instruction follower, more than doubling the success rate over the best existing approach on a standard benchmark.
Toward Multimodal Image-to-Image Translation
Oct 24, 2018

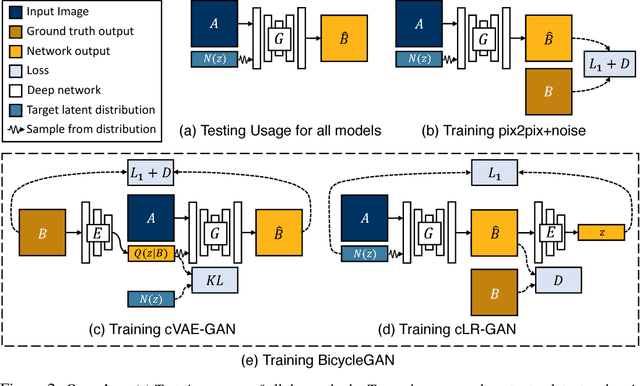
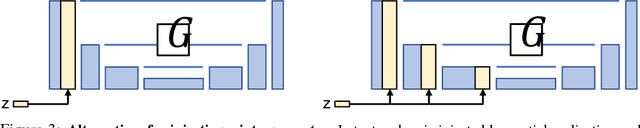
Many image-to-image translation problems are ambiguous, as a single input image may correspond to multiple possible outputs. In this work, we aim to model a \emph{distribution} of possible outputs in a conditional generative modeling setting. The ambiguity of the mapping is distilled in a low-dimensional latent vector, which can be randomly sampled at test time. A generator learns to map the given input, combined with this latent code, to the output. We explicitly encourage the connection between output and the latent code to be invertible. This helps prevent a many-to-one mapping from the latent code to the output during training, also known as the problem of mode collapse, and produces more diverse results. We explore several variants of this approach by employing different training objectives, network architectures, and methods of injecting the latent code. Our proposed method encourages bijective consistency between the latent encoding and output modes. We present a systematic comparison of our method and other variants on both perceptual realism and diversity.