 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Advise Humans By Leveraging Algorithm Discretion
Oct 26, 2022



Expert decision-makers (DMs) in high-stakes AI-advised (AIDeT) settings receive and reconcile recommendations from AI systems before making their final decisions. We identify distinct properties of these settings which are key to developing AIDeT models that effectively benefit team performance. First, DMs in AIDeT settings exhibit algorithm discretion behavior (ADB), i.e., an idiosyncratic tendency to imperfectly accept or reject algorithmic recommendations for any given decision task. Second, DMs incur contradiction costs from exerting decision-making resources (e.g., time and effort) when reconciling AI recommendations that contradict their own judgment. Third, the human's imperfect discretion and reconciliation costs introduce the need for the AI to offer advice selectively. We refer to the task of developing AI to advise humans in AIDeT settings as learning to advise and we address this task by first introducing the AIDeT-Learning Framework. Additionally, we argue that leveraging the human partner's ADB is key to maximizing the AIDeT's decision accuracy while regularizing for contradiction costs. Finally, we instantiate our framework to develop TeamRules (TR): an algorithm that produces rule-based models and recommendations for AIDeT settings. TR is optimized to selectively advise a human and to trade-off contradiction costs and team accuracy for a given environment by leveraging the human partner's ADB. Evaluations on synthetic and real-world benchmark datasets with a variety of simulated human accuracy and discretion behaviors show that TR robustly improves the team's objective across settings over interpretable, rule-based alternatives.
Selecting Better Samples from Pre-trained LLMs: A Case Study on Question Generation
Sep 22, 2022
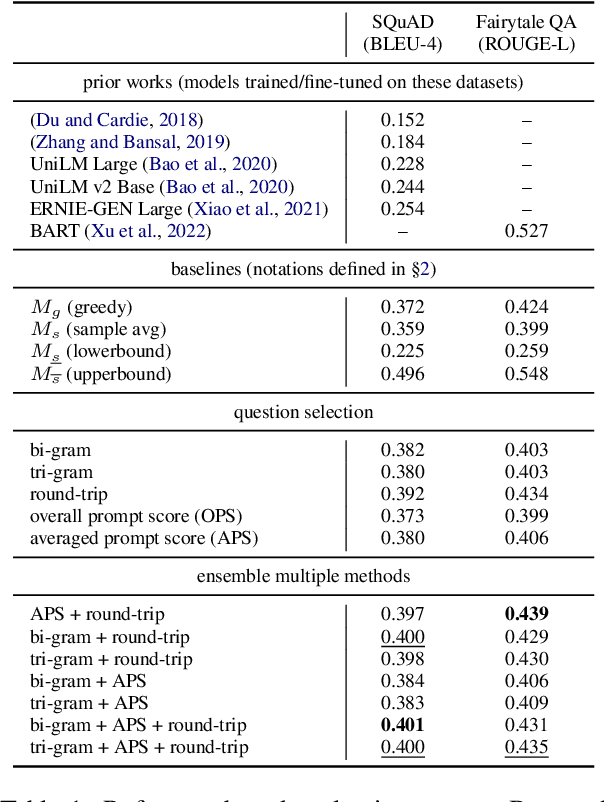
Large Language Models (LLMs) have in recent years demonstrated impressive prowess in natural language generation. A common practice to improve generation diversity is to sample multiple outputs from the model. However, there lacks a simple and robust way of selecting the best output from these stochastic samples. As a case study framed in the context of question generation, we propose two prompt-based approaches to selecting high-quality questions from a set of LLM-generated candidates. Our method works under the constraints of 1) a black-box (non-modifiable) question generation model and 2) lack of access to human-annotated references -- both of which are realistic limitations for real-world deployment of LLMs. With automatic as well as human evaluations, we empirically demonstrate that our approach can effectively select questions of higher qualities than greedy generation.
General-to-Specific Transfer Labeling for Domain Adaptable Keyphrase Generation
Aug 20, 2022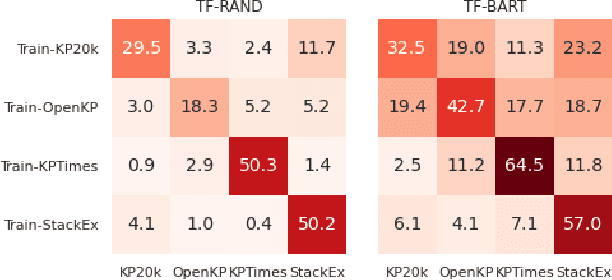
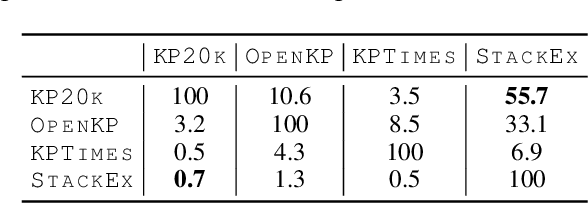
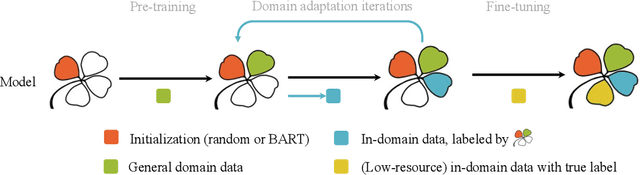
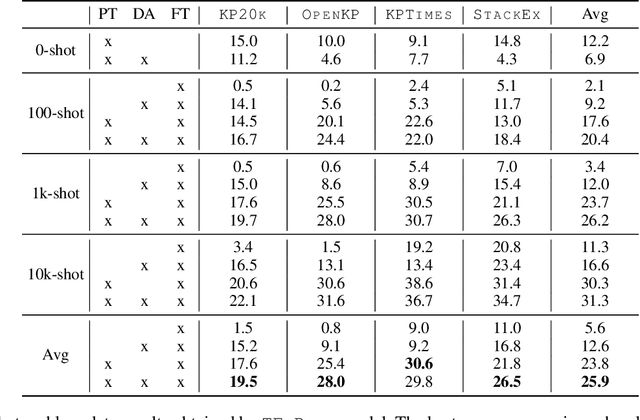
Training keyphrase generation (KPG) models requires a large amount of annotated data, which can be prohibitively expensive and often limited to specific domains. In this study, we first demonstrate that large distribution shifts among different domains severely hinder the transferability of KPG models. We then propose a three-stage pipeline, which gradually guides KPG models' learning focus from general syntactical features to domain-related semantics, in a data-efficient manner. With Domain-general Phrase pre-training, we pre-train Sequence-to-Sequence models with generic phrase annotations that are widely available on the web, which enables the models to generate phrases in a wide range of domains. The resulting model is then applied in the Transfer Labeling stage to produce domain-specific pseudo keyphrases, which help adapt models to a new domain. Finally, we fine-tune the model with limited data with true labels to fully adapt it to the target domain. Our experiment results show that the proposed process can produce good quality keyphrases in new domains and achieve consistent improvements after adaptation with limited in-domain annotated data.
Confidence Matters: Inspecting Backdoors in Deep Neural Networks via Distribution Transfer
Aug 13, 2022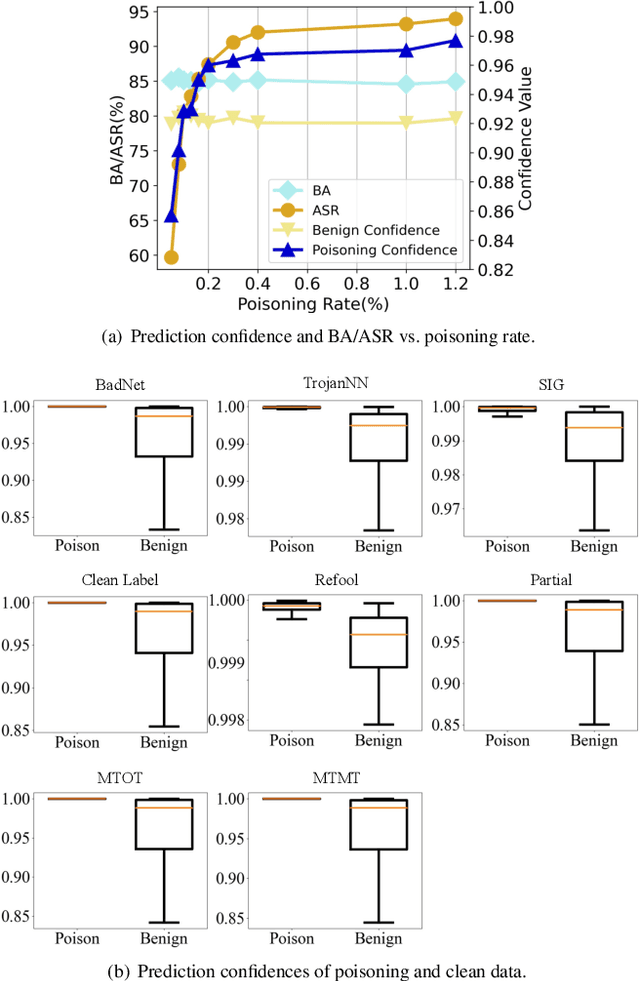
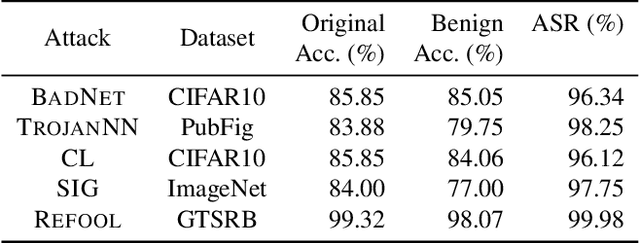
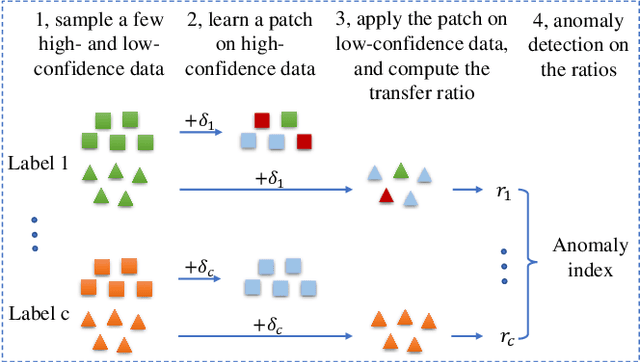

Backdoor attacks have been shown to be a serious security threat against deep learning models, and detecting whether a given model has been backdoored becomes a crucial task. Existing defenses are mainly built upon the observation that the backdoor trigger is usually of small size or affects the activation of only a few neurons. However, the above observations are violated in many cases especially for advanced backdoor attacks, hindering the performance and applicability of the existing defenses. In this paper, we propose a backdoor defense DTInspector built upon a new observation. That is, an effective backdoor attack usually requires high prediction confidence on the poisoned training samples, so as to ensure that the trained model exhibits the targeted behavior with a high probability. Based on this observation, DTInspector first learns a patch that could change the predictions of most high-confidence data, and then decides the existence of backdoor by checking the ratio of prediction changes after applying the learned patch on the low-confidence data. Extensive evaluations on five backdoor attacks, four datasets, and three advanced attacking types demonstrate the effectiveness of the proposed defense.
Dual Contrastive Attributed Graph Clustering Network
Jun 16, 2022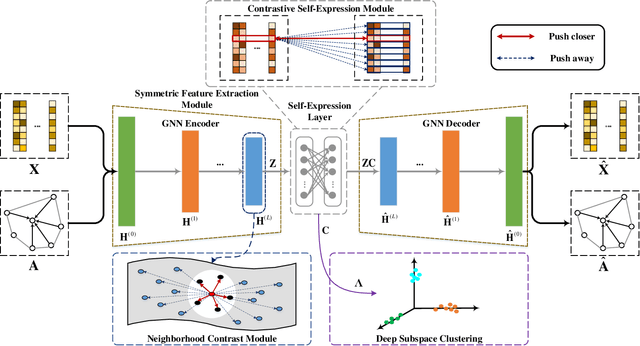
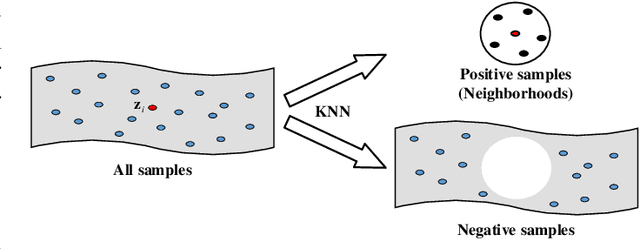

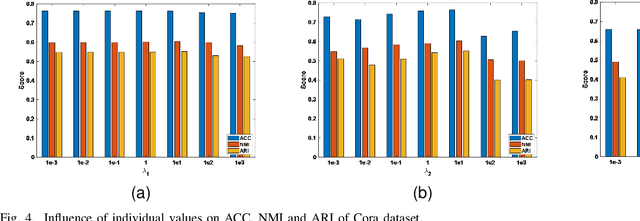
Attributed graph clustering is one of the most important tasks in graph analysis field, the goal of which is to group nodes with similar representations into the same cluster without manual guidance. Recent studies based on graph contrastive learning have achieved impressive results in processing graph-structured data. However, existing graph contrastive learning based methods 1) do not directly address the clustering task, since the representation learning and clustering process are separated; 2) depend too much on graph data augmentation, which greatly limits the capability of contrastive learning; 3) ignore the contrastive message for subspace clustering. To accommodate the aforementioned issues, we propose a generic framework called Dual Contrastive Attributed Graph Clustering Network (DCAGC). In DCAGC, by leveraging Neighborhood Contrast Module, the similarity of the neighbor nodes will be maximized and the quality of the node representation will be improved. Meanwhile, the Contrastive Self-Expression Module is built by minimizing the node representation before and after the reconstruction of the self-expression layer to obtain a discriminative self-expression matrix for spectral clustering. All the modules of DCAGC are trained and optimized in a unified framework, so the learned node representation contains clustering-oriented messages. Extensive experimental results on four attributed graph datasets show the superiority of DCAGC compared with 16 state-of-the-art clustering methods. The code of this paper is available at https://github.com/wangtong627/Dual-Contrastive-Attributed-Graph-Clustering-Network.
Multi-View Substructure Learning for Drug-Drug Interaction Prediction
Mar 28, 2022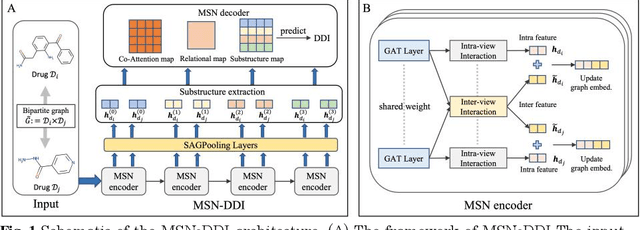
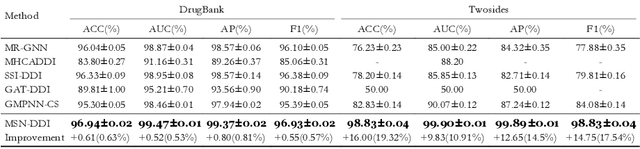
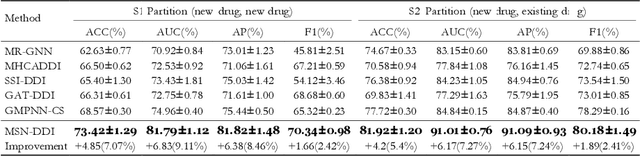
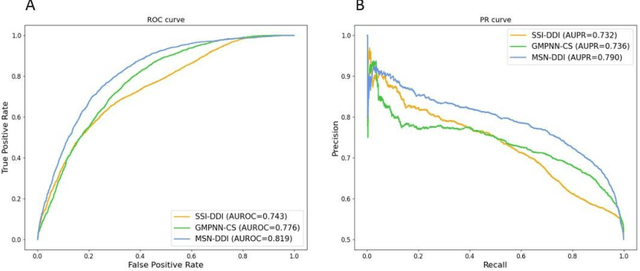
Drug-drug interaction (DDI) prediction provides a drug combination strategy for systemically effective treatment. Previous studies usually model drug information constrained on a single view such as the drug itself, leading to incomplete and noisy information, which limits the accuracy of DDI prediction. In this work, we propose a novel multi- view drug substructure network for DDI prediction (MSN-DDI), which learns chemical substructures from both the representations of the single drug (intra-view) and the drug pair (inter-view) simultaneously and utilizes the substructures to update the drug representation iteratively. Comprehensive evaluations demonstrate that MSN-DDI has almost solved DDI prediction for existing drugs by achieving a relatively improved accuracy of 19.32% and an over 99% accuracy under the transductive setting. More importantly, MSN-DDI exhibits better generalization ability to unseen drugs with a relatively improved accuracy of 7.07% under more challenging inductive scenarios. Finally, MSN-DDI improves prediction performance for real-world DDI applications to new drugs.
Better Language Model with Hypernym Class Prediction
Mar 21, 2022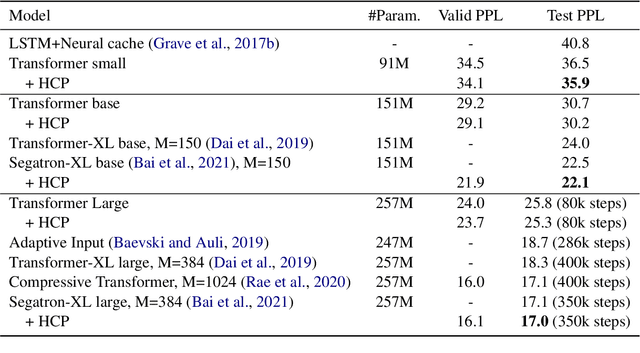
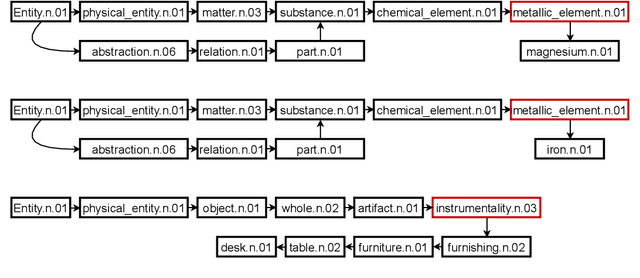
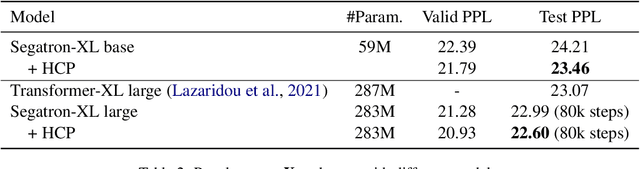
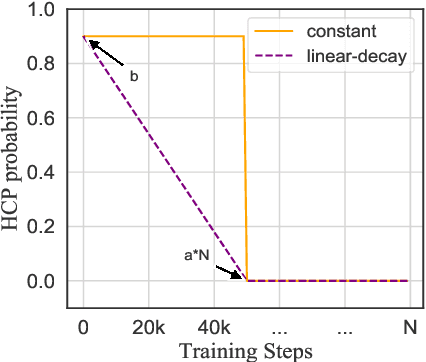
Class-based language models (LMs) have been long devised to address context sparsity in $n$-gram LMs. In this study, we revisit this approach in the context of neural LMs. We hypothesize that class-based prediction leads to an implicit context aggregation for similar words and thus can improve generalization for rare words. We map words that have a common WordNet hypernym to the same class and train large neural LMs by gradually annealing from predicting the class to token prediction during training. Empirically, this curriculum learning strategy consistently improves perplexity over various large, highly-performant state-of-the-art Transformer-based models on two datasets, WikiText-103 and Arxiv. Our analysis shows that the performance improvement is achieved without sacrificing performance on rare words. Finally, we document other attempts that failed to yield empirical gains, and discuss future directions for the adoption of class-based LMs on a larger scale.
Direct Molecular Conformation Generation
Feb 03, 2022
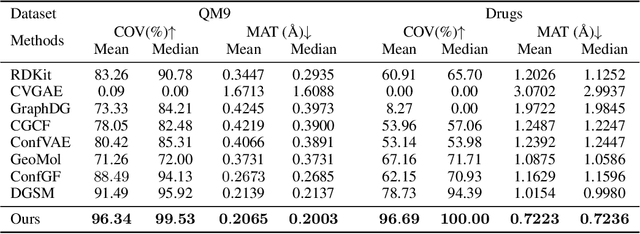
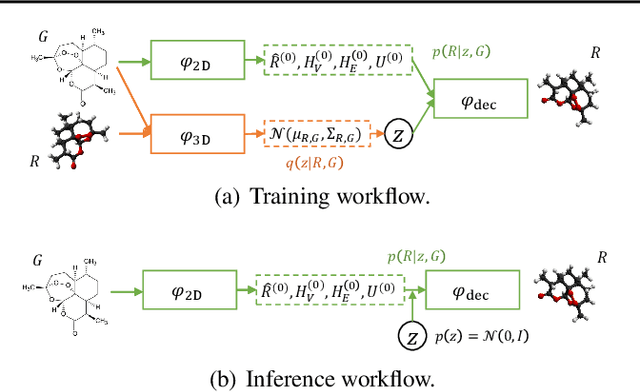
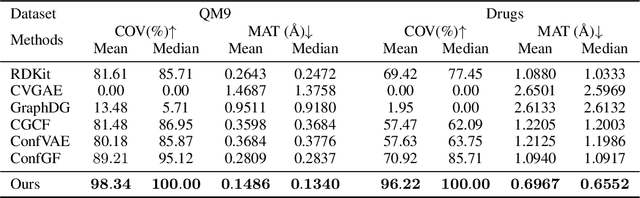
Molecular conformation generation aims to generate three-dimensional coordinates of all the atoms in a molecule and is an important task in bioinformatics and pharmacology. Previous distance-based methods first predict interatomic distances and then generate conformations based on them, which could result in conflicting distances. In this work, we propose a method that directly predicts the coordinates of atoms. We design a dedicated loss function for conformation generation, which is invariant to roto-translation of coordinates of conformations and permutation of symmetric atoms in molecules. We further design a backbone model that stacks multiple blocks, where each block refines the conformation generated by its preceding block. Our method achieves state-of-the-art results on four public benchmarks: on small-scale GEOM-QM9 and GEOM-Drugs which have $200$K training data, we can improve the previous best matching score by $3.5\%$ and $28.9\%$; on large-scale GEOM-QM9 and GEOM-Drugs which have millions of training data, those two improvements are $47.1\%$ and $36.3\%$. This shows the effectiveness of our method and the great potential of the direct approach. Our code is released at \url{https://github.com/DirectMolecularConfGen/DMCG}.
DenseGAP: Graph-Structured Dense Correspondence Learning with Anchor Points
Dec 13, 2021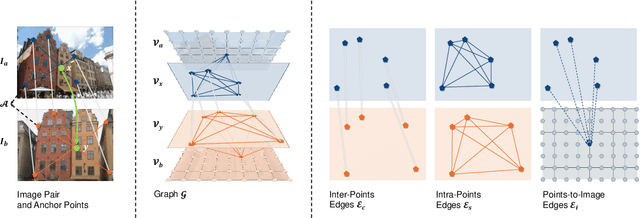
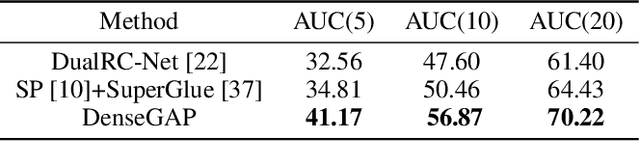

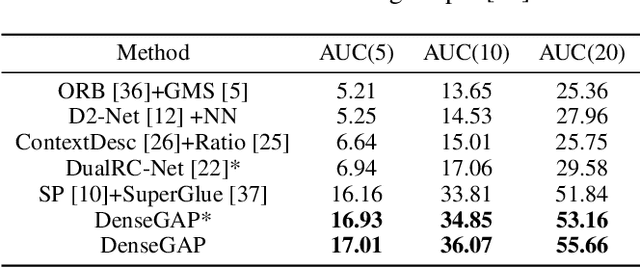
Establishing dense correspondence between two images is a fundamental computer vision problem, which is typically tackled by matching local feature descriptors. However, without global awareness, such local features are often insufficient for disambiguating similar regions. And computing the pairwise feature correlation across images is both computation-expensive and memory-intensive. To make the local features aware of the global context and improve their matching accuracy, we introduce DenseGAP, a new solution for efficient Dense correspondence learning with a Graph-structured neural network conditioned on Anchor Points. Specifically, we first propose a graph structure that utilizes anchor points to provide sparse but reliable prior on inter- and intra-image context and propagates them to all image points via directed edges. We also design a graph-structured network to broadcast multi-level contexts via light-weighted message-passing layers and generate high-resolution feature maps at low memory cost. Finally, based on the predicted feature maps, we introduce a coarse-to-fine framework for accurate correspondence prediction using cycle consistency. Our feature descriptors capture both local and global information, thus enabling a continuous feature field for querying arbitrary points at high resolution. Through comprehensive ablative experiments and evaluations on large-scale indoor and outdoor datasets, we demonstrate that our method advances the state-of-the-art of correspondence learning on most benchmarks.
Backdoor Attack through Frequency Domain
Nov 30, 2021


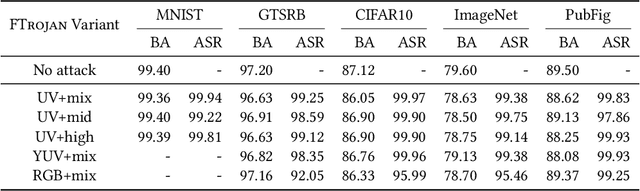
Backdoor attacks have been shown to be a serious threat against deep learning systems such as biometric authentication and autonomous driving. An effective backdoor attack could enforce the model misbehave under certain predefined conditions, i.e., triggers, but behave normally otherwise. However, the triggers of existing attacks are directly injected in the pixel space, which tend to be detectable by existing defenses and visually identifiable at both training and inference stages. In this paper, we propose a new backdoor attack FTROJAN through trojaning the frequency domain. The key intuition is that triggering perturbations in the frequency domain correspond to small pixel-wise perturbations dispersed across the entire image, breaking the underlying assumptions of existing defenses and making the poisoning images visually indistinguishable from clean ones. We evaluate FTROJAN in several datasets and tasks showing that it achieves a high attack success rate without significantly degrading the prediction accuracy on benign inputs. Moreover, the poisoning images are nearly invisible and retain high perceptual quality. We also evaluate FTROJAN against state-of-the-art defenses as well as several adaptive defenses that are designed on the frequency domain. The results show that FTROJAN can robustly elude or significantly degenerate the performance of these defenses.