 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACT: Privileged Trace Co-Training for Multi-Turn Tool-Use Agents
Jun 15, 2026Multi-turn tool-use agents must reason, call tools, and adapt to observations across several interaction turns. Post-training such agents is challenging, as reinforcement learning often suffers from sparse rewards and weak credit assignment despite matching the prompt-only inference setting, while supervised fine-tuning on expert traces provides dense process supervision but can over-constrain the model to fixed trajectories. To tackle this, we propose PACT, a Privileged trAce Co-Training framework for multi-turn tool-use agents. The key idea is to use expert traces only as training-time optimization signals rather than rollout-time hints. PACT keeps rollout generation prompt-only, then uses expert traces to guide optimization through two complementary signals: a trace-conditioned RL surrogate that evaluates prompt-only rollouts under expert-trace context, and a component-aware SFT loss that supervises reasoning prefixes and tool-calls with annealed strength. To reduce over-reliance on the training-only trace context, PACT further introduces a prompt-only anchoring. We also provide a latent-trace view that connects the two trace-based objectives and explains how expert traces can guide optimization without being used during rollout generation. Experiments on FTRL, BFCL, and ToolHop show that PACT consistently improves over strong SFT- and RL-based baselines, highlighting the value of privileged trace co-training for multi-turn tool-use learning.
VFIG: Vectorizing Complex Figures in SVG with Vision-Language Models
Mar 25, 2026Scalable Vector Graphics (SVG) are an essential format for technical illustration and digital design, offering precise resolution independence and flexible semantic editability. In practice, however, original vector source files are frequently lost or inaccessible, leaving only "flat" rasterized versions (e.g., PNG or JPEG) that are difficult to modify or scale. Manually reconstructing these figures is a prohibitively labor-intensive process, requiring specialized expertise to recover the original geometric intent. To bridge this gap, we propose VFIG, a family of Vision-Language Models trained for complex and high-fidelity figure-to-SVG conversion. While this task is inherently data-driven, existing datasets are typically small-scale and lack the complexity of professional diagrams. We address this by introducing VFIG-DATA, a large-scale dataset of 66K high-quality figure-SVG pairs, curated from a diverse mix of real-world paper figures and procedurally generated diagrams. Recognizing that SVGs are composed of recurring primitives and hierarchical local structures, we introduce a coarse-to-fine training curriculum that begins with supervised fine-tuning (SFT) to learn atomic primitives and transitions to reinforcement learning (RL) refinement to optimize global diagram fidelity, layout consistency, and topological edge cases. Finally, we introduce VFIG-BENCH, a comprehensive evaluation suite with novel metrics designed to measure the structural integrity of complex figures. VFIG achieves state-of-the-art performance among open-source models and performs on par with GPT-5.2, achieving a VLM-Judge score of 0.829 on VFIG-BENCH.
Dual Contrastive Attributed Graph Clustering Network
Jun 16, 2022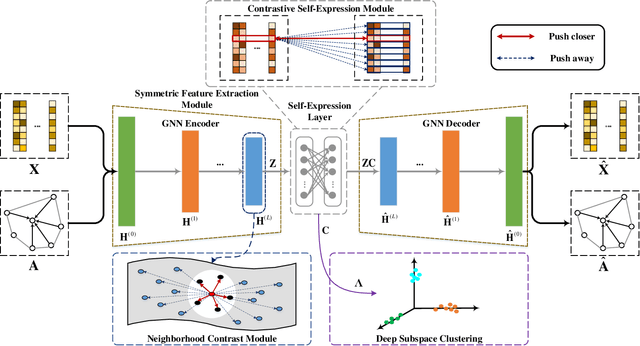
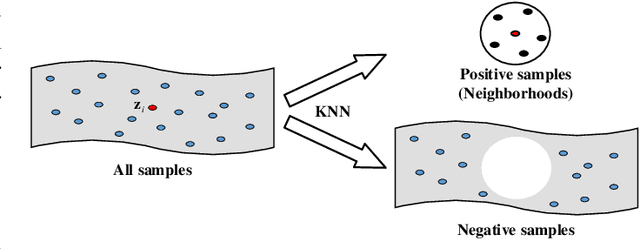

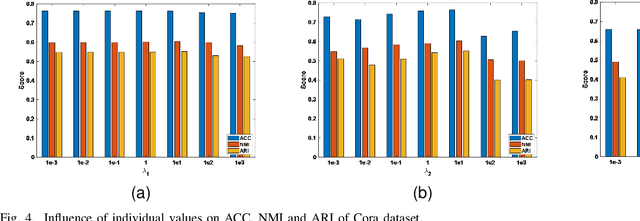
Attributed graph clustering is one of the most important tasks in graph analysis field, the goal of which is to group nodes with similar representations into the same cluster without manual guidance. Recent studies based on graph contrastive learning have achieved impressive results in processing graph-structured data. However, existing graph contrastive learning based methods 1) do not directly address the clustering task, since the representation learning and clustering process are separated; 2) depend too much on graph data augmentation, which greatly limits the capability of contrastive learning; 3) ignore the contrastive message for subspace clustering. To accommodate the aforementioned issues, we propose a generic framework called Dual Contrastive Attributed Graph Clustering Network (DCAGC). In DCAGC, by leveraging Neighborhood Contrast Module, the similarity of the neighbor nodes will be maximized and the quality of the node representation will be improved. Meanwhile, the Contrastive Self-Expression Module is built by minimizing the node representation before and after the reconstruction of the self-expression layer to obtain a discriminative self-expression matrix for spectral clustering. All the modules of DCAGC are trained and optimized in a unified framework, so the learned node representation contains clustering-oriented messages. Extensive experimental results on four attributed graph datasets show the superiority of DCAGC compared with 16 state-of-the-art clustering methods. The code of this paper is available at https://github.com/wangtong627/Dual-Contrastive-Attributed-Graph-Clustering-Network.