 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Combines Paraphrase: Teaching Pre-trained Models to Understand Rare Biomedical Words
Sep 14, 2022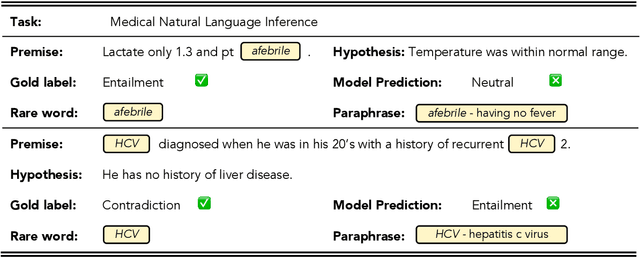
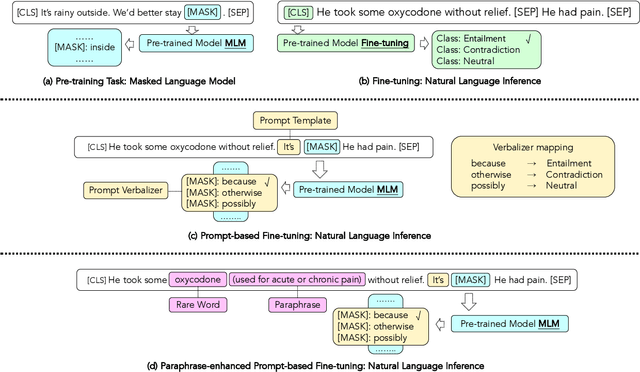
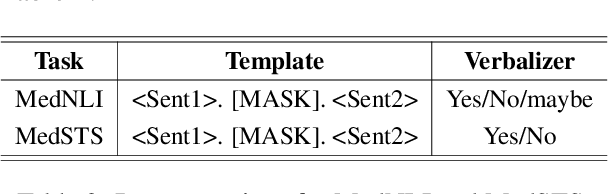
Prompt-based fine-tuning for pre-trained models has proven effective for many natural language processing tasks under few-shot settings in general domain. However, tuning with prompt in biomedical domain has not been investigated thoroughly. Biomedical words are often rare in general domain, but quite ubiquitous in biomedical contexts, which dramatically deteriorates the performance of pre-trained models on downstream biomedical applications even after fine-tuning, especially in low-resource scenarios. We propose a simple yet effective approach to helping models learn rare biomedical words during tuning with prompt. Experimental results show that our method can achieve up to 6% improvement in biomedical natural language inference task without any extra parameters or training steps using few-shot vanilla prompt settings.
SelF-Eval: Self-supervised Fine-grained Dialogue Evaluation
Aug 23, 2022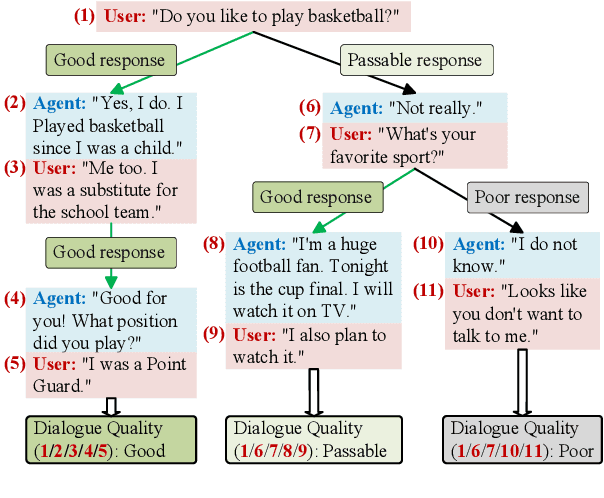
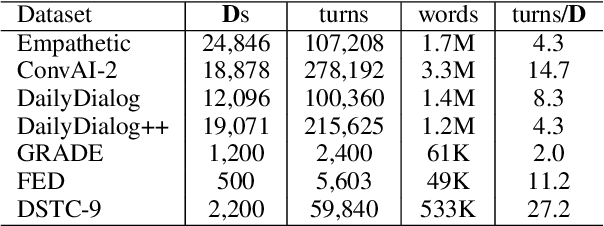
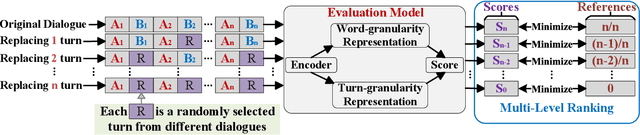
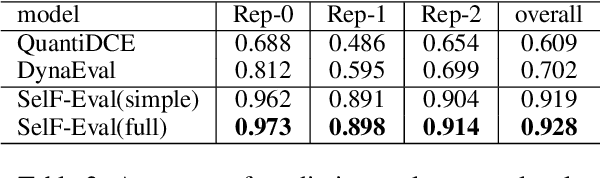
This paper introduces a novel Self-supervised Fine-grained Dialogue Evaluation framework (SelF-Eval). The core idea is to model the correlation between turn quality and the entire dialogue quality. We first propose a novel automatic data construction method that can automatically assign fine-grained scores for arbitrarily dialogue data. Then we train \textbf{SelF-Eval} with a multi-level contrastive learning schema which helps to distinguish different score levels. Experimental results on multiple benchmarks show that SelF-Eval is highly consistent with human evaluations and better than the state-of-the-art models. We give a detailed analysis of the experiments in this paper. Our code and data will be published on GitHub.
DiscrimLoss: A Universal Loss for Hard Samples and Incorrect Samples Discrimination
Aug 21, 2022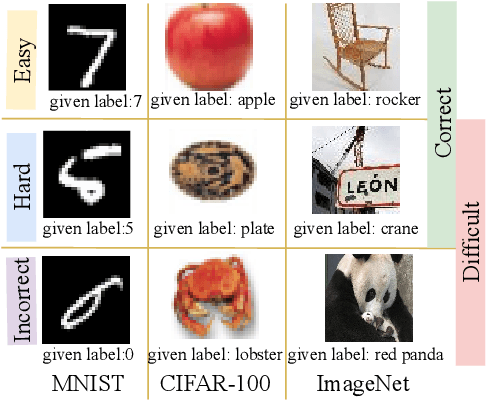
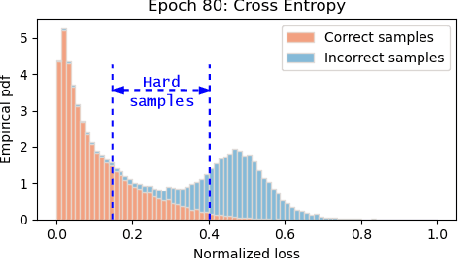
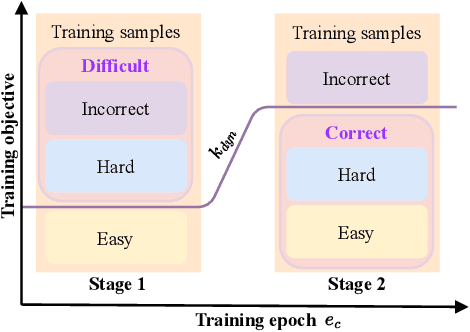
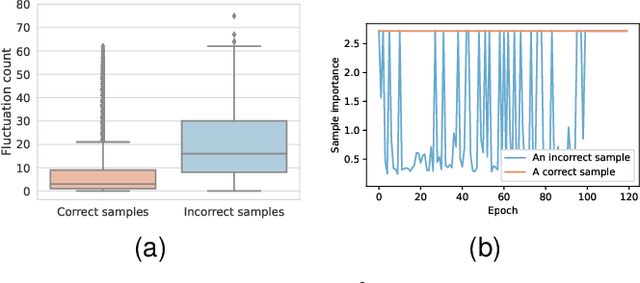
Given data with label noise (i.e., incorrect data), deep neural networks would gradually memorize the label noise and impair model performance. To relieve this issue, curriculum learning is proposed to improve model performance and generalization by ordering training samples in a meaningful (e.g., easy to hard) sequence. Previous work takes incorrect samples as generic hard ones without discriminating between hard samples (i.e., hard samples in correct data) and incorrect samples. Indeed, a model should learn from hard samples to promote generalization rather than overfit to incorrect ones. In this paper, we address this problem by appending a novel loss function DiscrimLoss, on top of the existing task loss. Its main effect is to automatically and stably estimate the importance of easy samples and difficult samples (including hard and incorrect samples) at the early stages of training to improve the model performance. Then, during the following stages, DiscrimLoss is dedicated to discriminating between hard and incorrect samples to improve the model generalization. Such a training strategy can be formulated dynamically in a self-supervised manner, effectively mimicking the main principle of curriculum learning. Experiments on image classification, image regression, text sequence regression, and event relation reasoning demonstrate the versatility and effectiveness of our method, particularly in the presence of diversified noise levels.
Text Difficulty Study: Do machines behave the same as humans regarding text difficulty?
Aug 14, 2022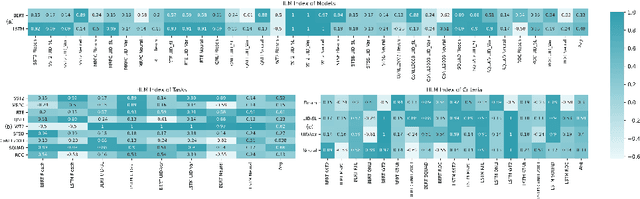
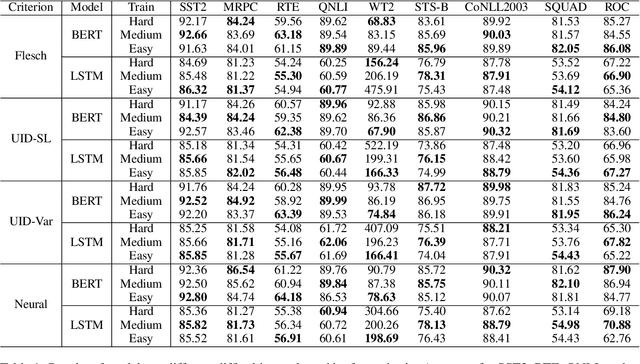
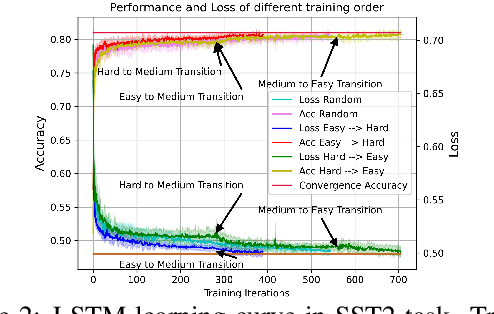
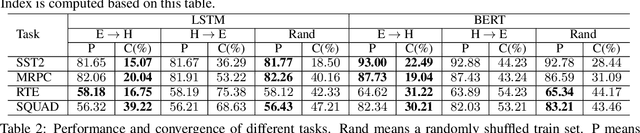
Given a task, human learns from easy to hard, whereas the model learns randomly. Undeniably, difficulty insensitive learning leads to great success in NLP, but little attention has been paid to the effect of text difficulty in NLP. In this research, we propose the Human Learning Matching Index (HLM Index) to investigate the effect of text difficulty. Experiment results show: (1) LSTM has more human-like learning behavior than BERT. (2) UID-SuperLinear gives the best evaluation of text difficulty among four text difficulty criteria. (3) Among nine tasks, some tasks' performance is related to text difficulty, whereas some are not. (4) Model trained on easy data performs best in easy and medium data, whereas trains on a hard level only perform well on hard data. (5) Training the model from easy to hard leads to fast convergence.
A Graph Enhanced BERT Model for Event Prediction
May 22, 2022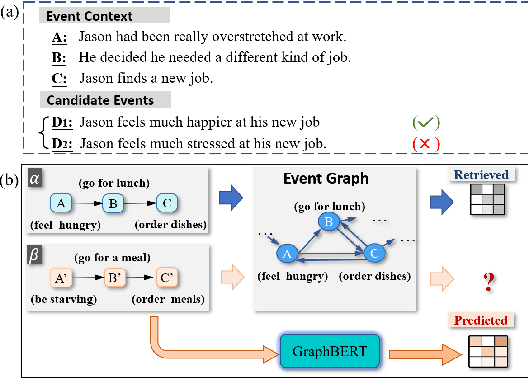
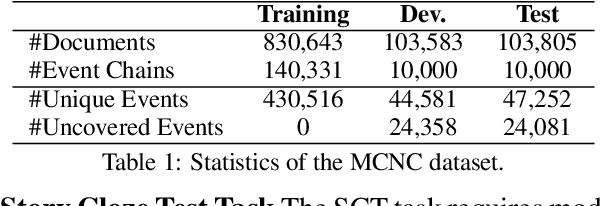
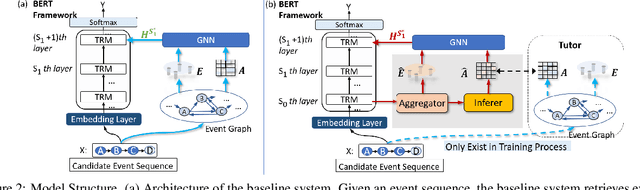
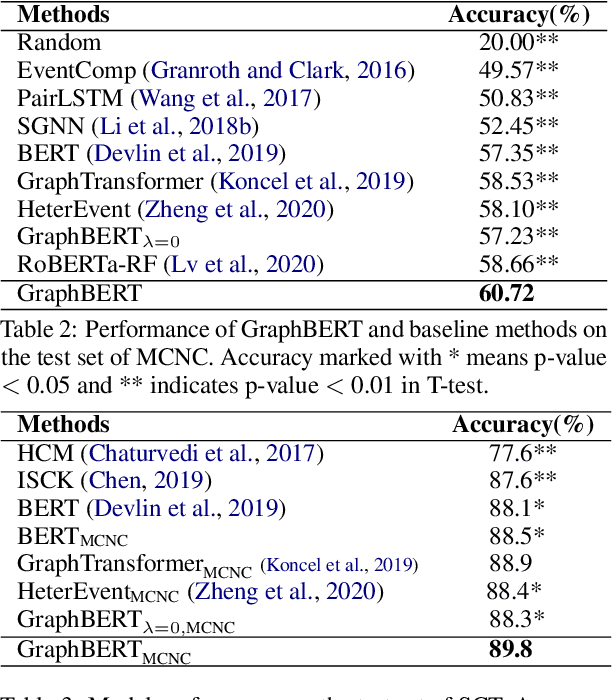
Predicting the subsequent event for an existing event context is an important but challenging task, as it requires understanding the underlying relationship between events. Previous methods propose to retrieve relational features from event graph to enhance the modeling of event correlation. However, the sparsity of event graph may restrict the acquisition of relevant graph information, and hence influence the model performance. To address this issue, we consider automatically building of event graph using a BERT model. To this end, we incorporate an additional structured variable into BERT to learn to predict the event connections in the training process. Hence, in the test process, the connection relationship for unseen events can be predicted by the structured variable. Results on two event prediction tasks: script event prediction and story ending prediction, show that our approach can outperform state-of-the-art baseline methods.
Explanation-Guided Fairness Testing through Genetic Algorithm
May 16, 2022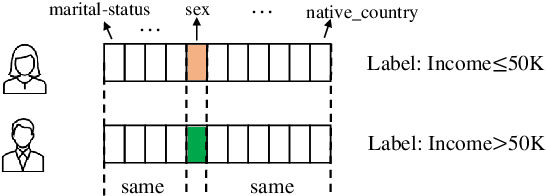
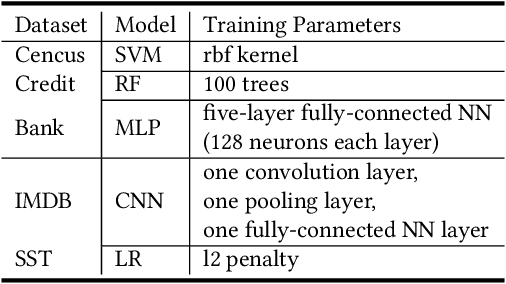
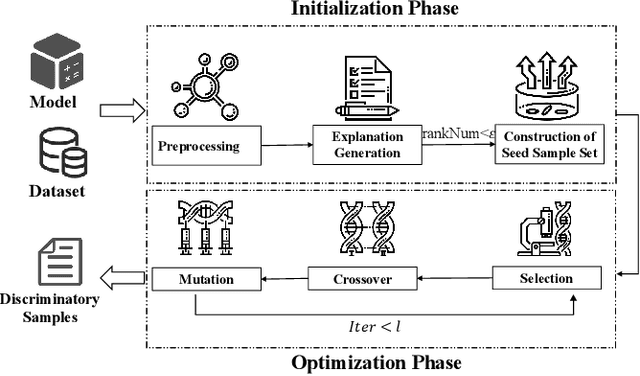
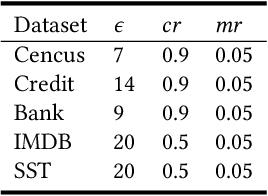
The fairness characteristic is a critical attribute of trusted AI systems. A plethora of research has proposed diverse methods for individual fairness testing. However, they are suffering from three major limitations, i.e., low efficiency, low effectiveness, and model-specificity. This work proposes ExpGA, an explanationguided fairness testing approach through a genetic algorithm (GA). ExpGA employs the explanation results generated by interpretable methods to collect high-quality initial seeds, which are prone to derive discriminatory samples by slightly modifying feature values. ExpGA then adopts GA to search discriminatory sample candidates by optimizing a fitness value. Benefiting from this combination of explanation results and GA, ExpGA is both efficient and effective to detect discriminatory individuals. Moreover, ExpGA only requires prediction probabilities of the tested model, resulting in a better generalization capability to various models. Experiments on multiple real-world benchmarks, including tabular and text datasets, show that ExpGA presents higher efficiency and effectiveness than four state-of-the-art approaches.
e-CARE: a New Dataset for Exploring Explainable Causal Reasoning
May 12, 2022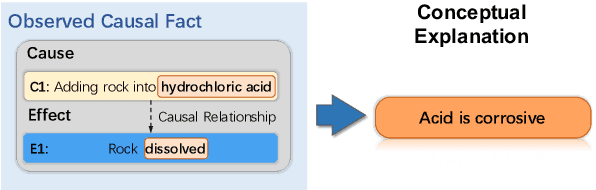
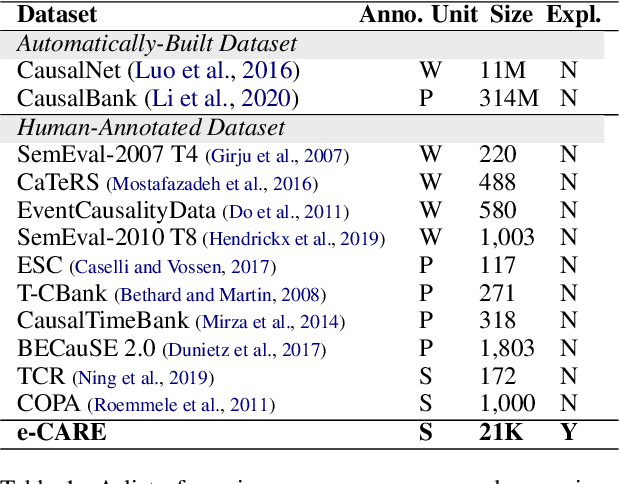
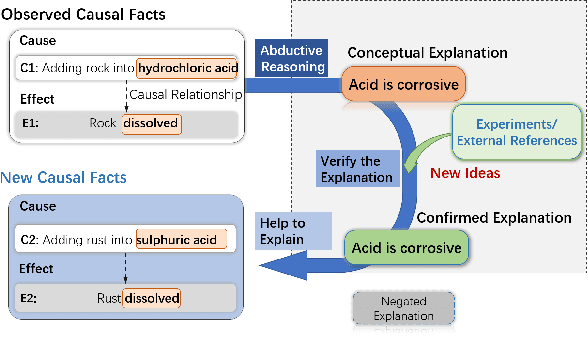
Understanding causality has vital importance for various Natural Language Processing (NLP) applications. Beyond the labeled instances, conceptual explanations of the causality can provide deep understanding of the causal facts to facilitate the causal reasoning process. However, such explanation information still remains absent in existing causal reasoning resources. In this paper, we fill this gap by presenting a human-annotated explainable CAusal REasoning dataset (e-CARE), which contains over 21K causal reasoning questions, together with natural language formed explanations of the causal questions. Experimental results show that generating valid explanations for causal facts still remains especially challenging for the state-of-the-art models, and the explanation information can be helpful for promoting the accuracy and stability of causal reasoning models.
Improving Pre-trained Language Models with Syntactic Dependency Prediction Task for Chinese Semantic Error Recognition
Apr 15, 2022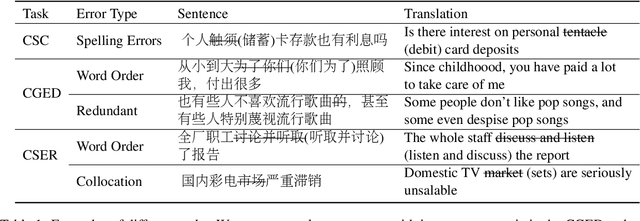
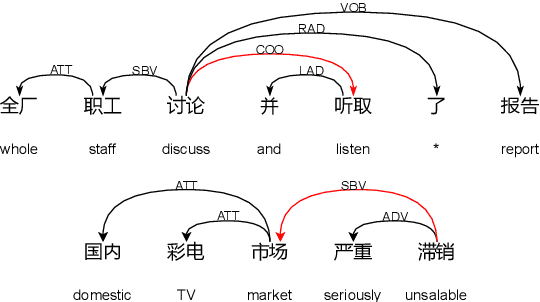

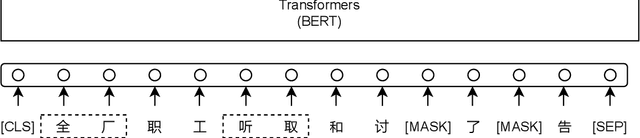
Existing Chinese text error detection mainly focuses on spelling and simple grammatical errors. These errors have been studied extensively and are relatively simple for humans. On the contrary, Chinese semantic errors are understudied and more complex that humans cannot easily recognize. The task of this paper is Chinese Semantic Error Recognition (CSER), a binary classification task to determine whether a sentence contains semantic errors. The current research has no effective method to solve this task. In this paper, we inherit the model structure of BERT and design several syntax-related pre-training tasks so that the model can learn syntactic knowledge. Our pre-training tasks consider both the directionality of the dependency structure and the diversity of the dependency relationship. Due to the lack of a published dataset for CSER, we build a high-quality dataset for CSER for the first time named Corpus of Chinese Linguistic Semantic Acceptability (CoCLSA). The experimental results on the CoCLSA show that our methods outperform universal pre-trained models and syntax-infused models.
Surrogate Gap Minimization Improves Sharpness-Aware Training
Mar 19, 2022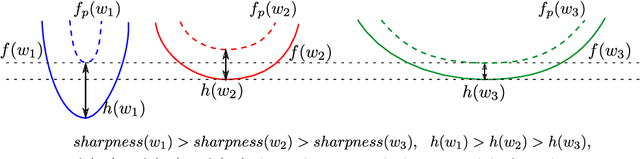
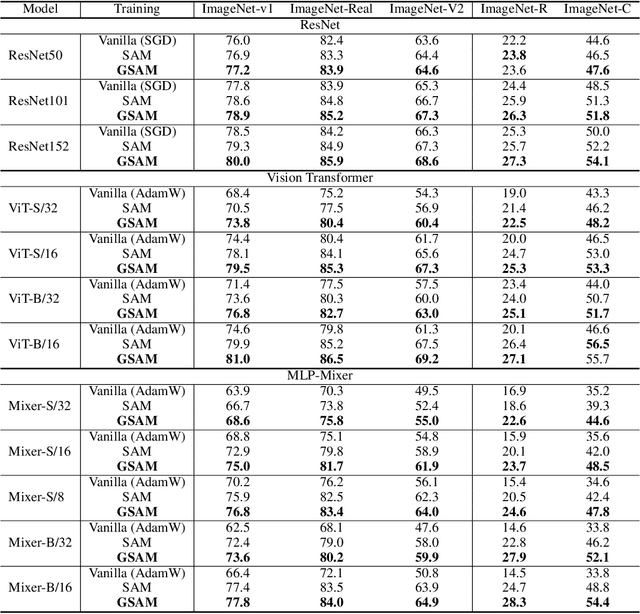


The recently proposed Sharpness-Aware Minimization (SAM) improves generalization by minimizing a \textit{perturbed loss} defined as the maximum loss within a neighborhood in the parameter space. However, we show that both sharp and flat minima can have a low perturbed loss, implying that SAM does not always prefer flat minima. Instead, we define a \textit{surrogate gap}, a measure equivalent to the dominant eigenvalue of Hessian at a local minimum when the radius of the neighborhood (to derive the perturbed loss) is small. The surrogate gap is easy to compute and feasible for direct minimization during training. Based on the above observations, we propose Surrogate \textbf{G}ap Guided \textbf{S}harpness-\textbf{A}ware \textbf{M}inimization (GSAM), a novel improvement over SAM with negligible computation overhead. Conceptually, GSAM consists of two steps: 1) a gradient descent like SAM to minimize the perturbed loss, and 2) an \textit{ascent} step in the \textit{orthogonal} direction (after gradient decomposition) to minimize the surrogate gap and yet not affect the perturbed loss. GSAM seeks a region with both small loss (by step 1) and low sharpness (by step 2), giving rise to a model with high generalization capabilities. Theoretically, we show the convergence of GSAM and provably better generalization than SAM. Empirically, GSAM consistently improves generalization (e.g., +3.2\% over SAM and +5.4\% over AdamW on ImageNet top-1 accuracy for ViT-B/32). Code is released at \url{ https://sites.google.com/view/gsam-iclr22/home}.
CLIP Models are Few-shot Learners: Empirical Studies on VQA and Visual Entailment
Mar 14, 2022
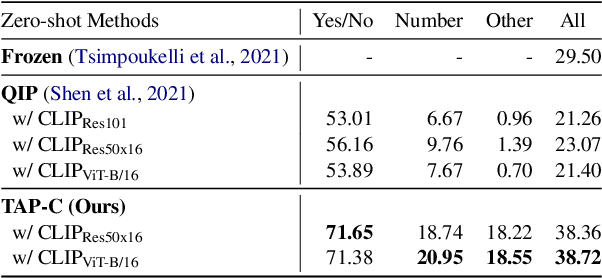
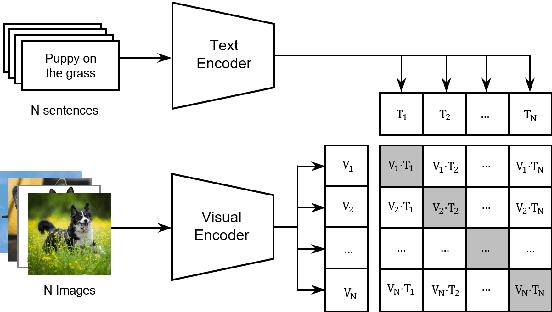
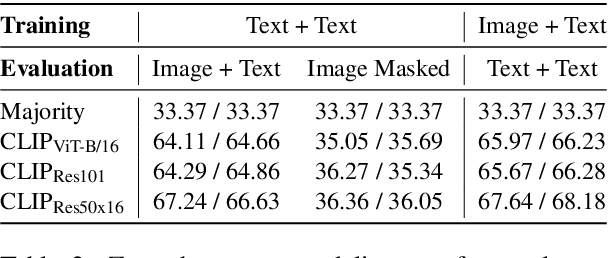
CLIP has shown a remarkable zero-shot capability on a wide range of vision tasks. Previously, CLIP is only regarded as a powerful visual encoder. However, after being pre-trained by language supervision from a large amount of image-caption pairs, CLIP itself should also have acquired some few-shot abilities for vision-language tasks. In this work, we empirically show that CLIP can be a strong vision-language few-shot learner by leveraging the power of language. We first evaluate CLIP's zero-shot performance on a typical visual question answering task and demonstrate a zero-shot cross-modality transfer capability of CLIP on the visual entailment task. Then we propose a parameter-efficient fine-tuning strategy to boost the few-shot performance on the vqa task. We achieve competitive zero/few-shot results on the visual question answering and visual entailment tasks without introducing any additional pre-training procedure.