 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoder Denoising Pretraining for Semantic Segmentation
May 23, 2022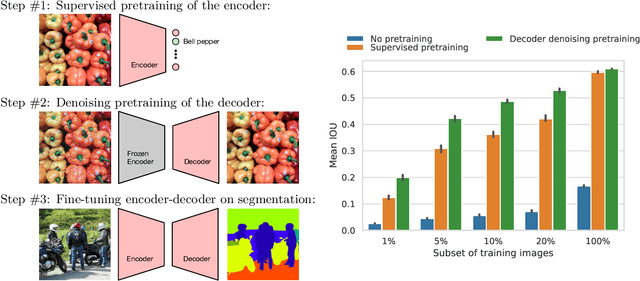
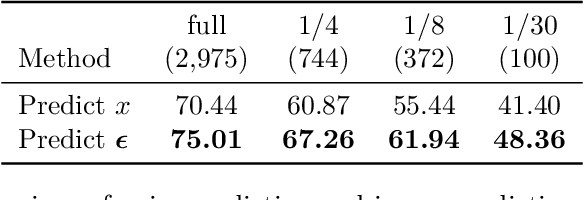
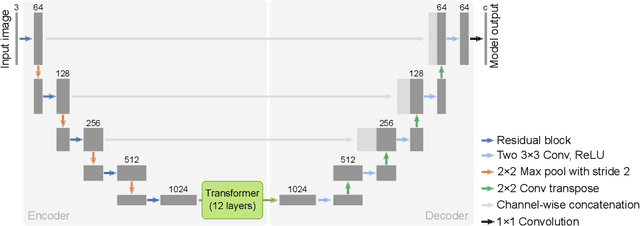
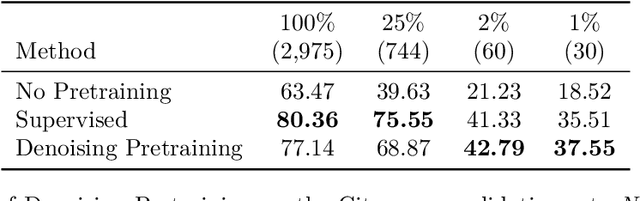
Semantic segmentation labels are expensive and time consuming to acquire. Hence, pretraining is commonly used to improve the label-efficiency of segmentation models. Typically, the encoder of a segmentation model is pretrained as a classifier and the decoder is randomly initialized. Here, we argue that random initialization of the decoder can be suboptimal, especially when few labeled examples are available. We propose a decoder pretraining approach based on denoising, which can be combined with supervised pretraining of the encoder. We find that decoder denoising pretraining on the ImageNet dataset strongly outperforms encoder-only supervised pretraining. Despite its simplicity, decoder denoising pretraining achieves state-of-the-art results on label-efficient semantic segmentation and offers considerable gains on the Cityscapes, Pascal Context, and ADE20K datasets.
Robust and Efficient Medical Imaging with Self-Supervision
May 19, 2022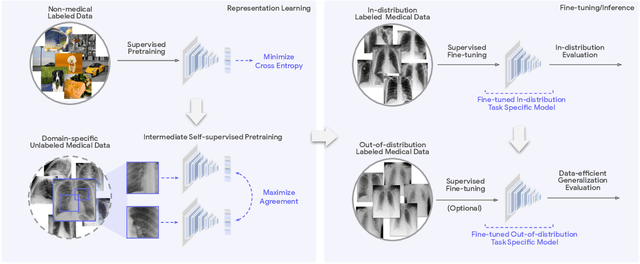
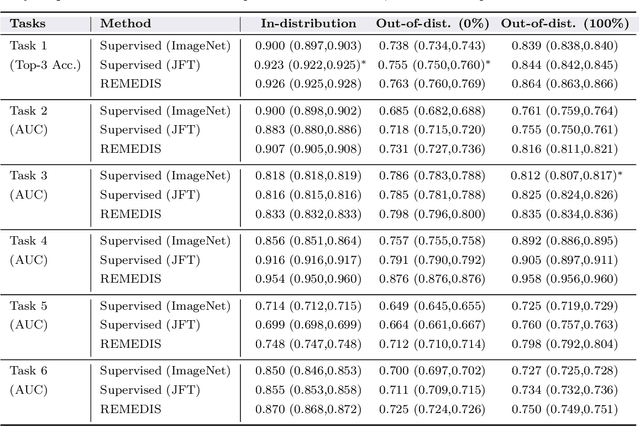
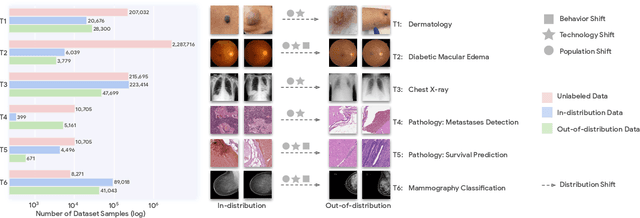

Recent progress in Medical Artificial Intelligence (AI) has delivered systems that can reach clinical expert level performance. However, such systems tend to demonstrate sub-optimal "out-of-distribution" performance when evaluated in clinical settings different from the training environment. A common mitigation strategy is to develop separate systems for each clinical setting using site-specific data [1]. However, this quickly becomes impractical as medical data is time-consuming to acquire and expensive to annotate [2]. Thus, the problem of "data-efficient generalization" presents an ongoing difficulty for Medical AI development. Although progress in representation learning shows promise, their benefits have not been rigorously studied, specifically for out-of-distribution settings. To meet these challenges, we present REMEDIS, a unified representation learning strategy to improve robustness and data-efficiency of medical imaging AI. REMEDIS uses a generic combination of large-scale supervised transfer learning with self-supervised learning and requires little task-specific customization. We study a diverse range of medical imaging tasks and simulate three realistic application scenarios using retrospective data. REMEDIS exhibits significantly improved in-distribution performance with up to 11.5% relative improvement in diagnostic accuracy over a strong supervised baseline. More importantly, our strategy leads to strong data-efficient generalization of medical imaging AI, matching strong supervised baselines using between 1% to 33% of retraining data across tasks. These results suggest that REMEDIS can significantly accelerate the life-cycle of medical imaging AI development thereby presenting an important step forward for medical imaging AI to deliver broad impact.
From Heavy Rain Removal to Detail Restoration: A Faster and Better Network
May 07, 2022
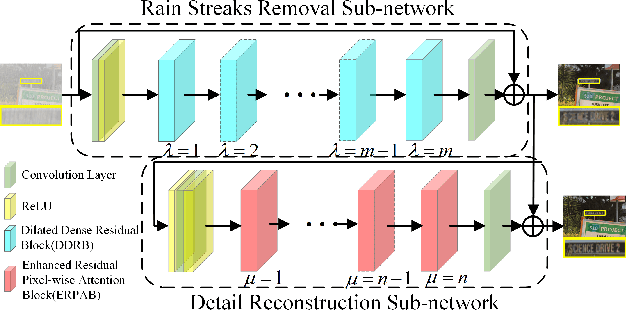
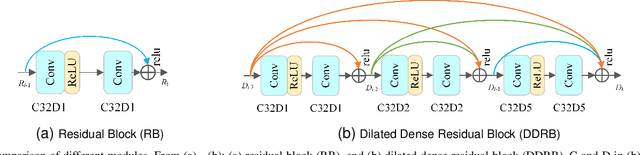
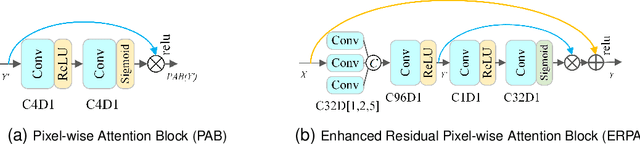
The dense rain accumulation in heavy rain can significantly wash out images and thus destroy the background details of images. Although existing deep rain removal models lead to improved performance for heavy rain removal, we find that most of them ignore the detail reconstruction accuracy of rain-free images. In this paper, we propose a dual-stage progressive enhancement network (DPENet) to achieve effective deraining with structure-accurate rain-free images. Two main modules are included in our framework, namely a rain streaks removal network (R$^2$Net) and a detail reconstruction network (DRNet). The former aims to achieve accurate rain removal, and the latter is designed to recover the details of rain-free images. We introduce two main strategies within our networks to achieve trade-off between the effectiveness of deraining and the detail restoration of rain-free images. Firstly, a dilated dense residual block (DDRB) within the rain streaks removal network is presented to aggregate high/low level features of heavy rain. Secondly, an enhanced residual pixel-wise attention block (ERPAB) within the detail reconstruction network is designed for context information aggregation. We also propose a comprehensive loss function to highlight the marginal and regional accuracy of rain-free images. Extensive experiments on benchmark public datasets show both efficiency and effectiveness of the proposed method in achieving structure-preserving rain-free images for heavy rain removal. The source code and pre-trained models can be found at \url{https://github.com/wybchd/DPENet}.
Improving Contrastive Learning on Imbalanced Seed Data via Open-World Sampling
Nov 01, 2021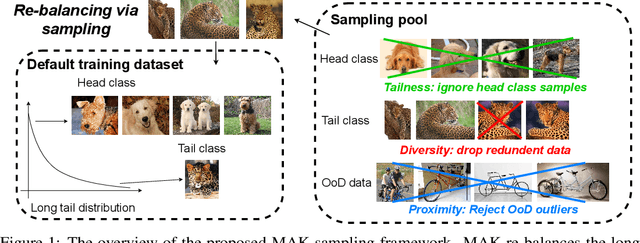
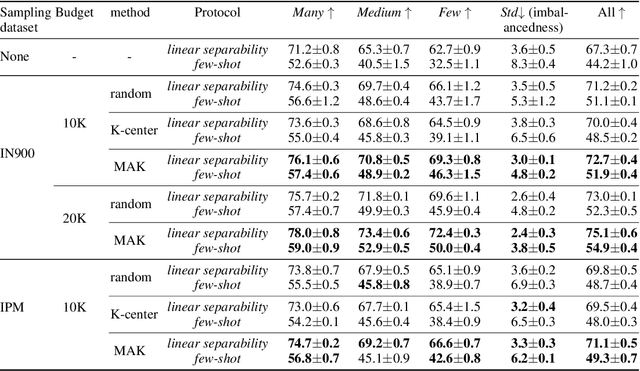
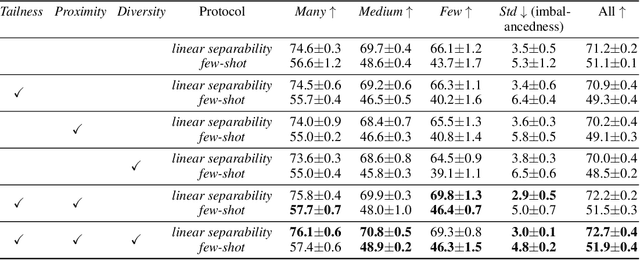
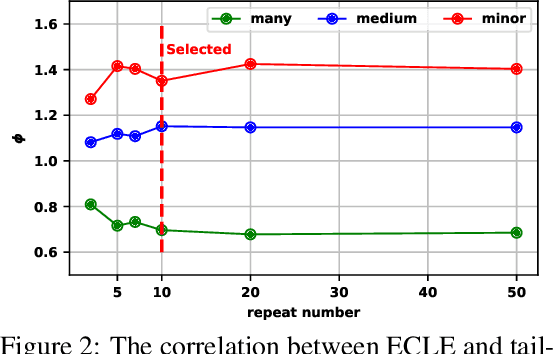
Contrastive learning approaches have achieved great success in learning visual representations with few labels of the target classes. That implies a tantalizing possibility of scaling them up beyond a curated "seed" benchmark, to incorporating more unlabeled images from the internet-scale external sources to enhance its performance. However, in practice, larger amount of unlabeled data will require more computing resources due to the bigger model size and longer training needed. Moreover, open-world unlabeled data usually follows an implicit long-tail class or attribute distribution, many of which also do not belong to the target classes. Blindly leveraging all unlabeled data hence can lead to the data imbalance as well as distraction issues. This motivates us to seek a principled approach to strategically select unlabeled data from an external source, in order to learn generalizable, balanced and diverse representations for relevant classes. In this work, we present an open-world unlabeled data sampling framework called Model-Aware K-center (MAK), which follows three simple principles: (1) tailness, which encourages sampling of examples from tail classes, by sorting the empirical contrastive loss expectation (ECLE) of samples over random data augmentations; (2) proximity, which rejects the out-of-distribution outliers that may distract training; and (3) diversity, which ensures diversity in the set of sampled examples. Empirically, using ImageNet-100-LT (without labels) as the seed dataset and two "noisy" external data sources, we demonstrate that MAK can consistently improve both the overall representation quality and the class balancedness of the learned features, as evaluated via linear classifier evaluation on full-shot and few-shot settings. The code is available at: \url{https://github.com/VITA-Group/MAK
TiKick: Towards Playing Multi-agent Football Full Games from Single-agent Demonstrations
Oct 19, 2021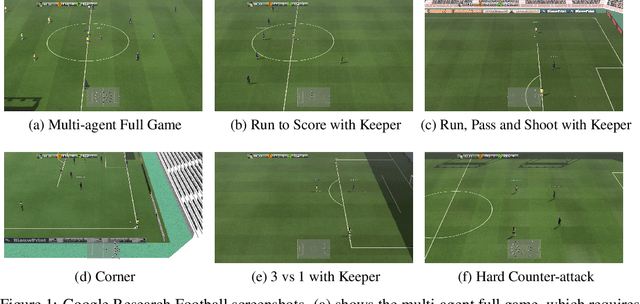

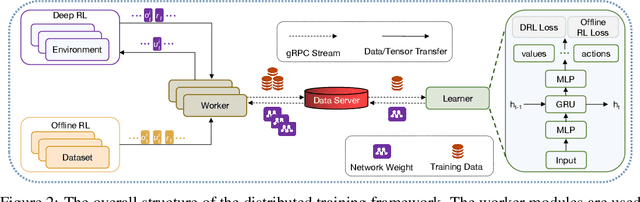
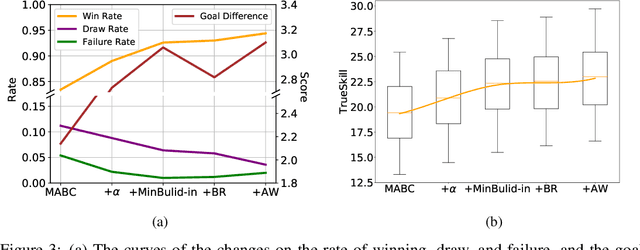
Deep reinforcement learning (DRL) has achieved super-human performance on complex video games (e.g., StarCraft II and Dota II). However, current DRL systems still suffer from challenges of multi-agent coordination, sparse rewards, stochastic environments, etc. In seeking to address these challenges, we employ a football video game, e.g., Google Research Football (GRF), as our testbed and develop an end-to-end learning-based AI system (denoted as TiKick) to complete this challenging task. In this work, we first generated a large replay dataset from the self-playing of single-agent experts, which are obtained from league training. We then developed a distributed learning system and new offline algorithms to learn a powerful multi-agent AI from the fixed single-agent dataset. To the best of our knowledge, Tikick is the first learning-based AI system that can take over the multi-agent Google Research Football full game, while previous work could either control a single agent or experiment on toy academic scenarios. Extensive experiments further show that our pre-trained model can accelerate the training process of the modern multi-agent algorithm and our method achieves state-of-the-art performances on various academic scenarios.
Understanding and Improving Robustness of Vision Transformers through Patch-based Negative Augmentation
Oct 15, 2021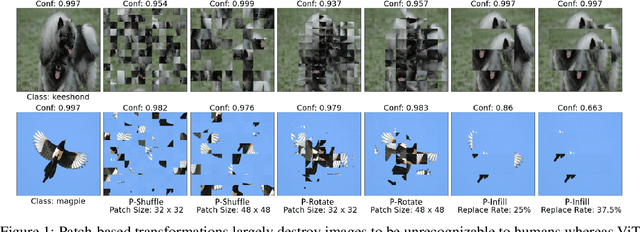

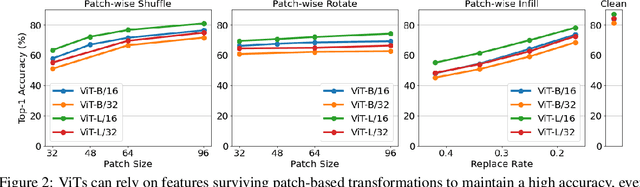
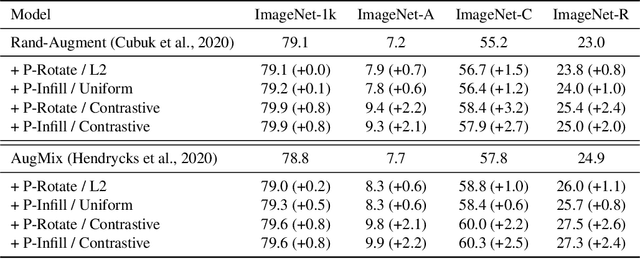
We investigate the robustness of vision transformers (ViTs) through the lens of their special patch-based architectural structure, i.e., they process an image as a sequence of image patches. We find that ViTs are surprisingly insensitive to patch-based transformations, even when the transformation largely destroys the original semantics and makes the image unrecognizable by humans. This indicates that ViTs heavily use features that survived such transformations but are generally not indicative of the semantic class to humans. Further investigations show that these features are useful but non-robust, as ViTs trained on them can achieve high in-distribution accuracy, but break down under distribution shifts. From this understanding, we ask: can training the model to rely less on these features improve ViT robustness and out-of-distribution performance? We use the images transformed with our patch-based operations as negatively augmented views and offer losses to regularize the training away from using non-robust features. This is a complementary view to existing research that mostly focuses on augmenting inputs with semantic-preserving transformations to enforce models' invariance. We show that patch-based negative augmentation consistently improves robustness of ViTs across a wide set of ImageNet based robustness benchmarks. Furthermore, we find our patch-based negative augmentation are complementary to traditional (positive) data augmentation, and together boost the performance further. All the code in this work will be open-sourced.
Ranking Cost: Building An Efficient and Scalable Circuit Routing Planner with Evolution-Based Optimization
Oct 08, 2021
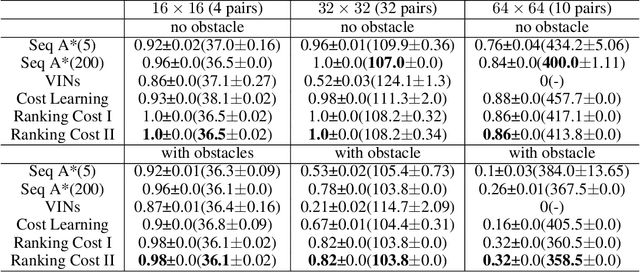

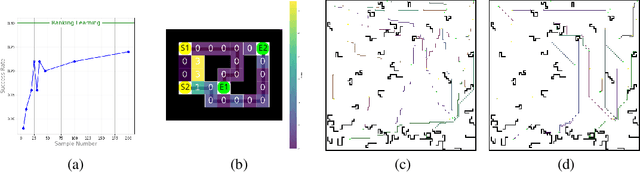
Circuit routing has been a historically challenging problem in designing electronic systems such as very large-scale integration (VLSI) and printed circuit boards (PCBs). The main challenge is that connecting a large number of electronic components under specific design rules involves a very large search space. Early solutions are typically designed with hard-coded heuristics, which suffer from problems of non-optimal solutions and lack of flexibility for new design needs. Although a few learning-based methods have been proposed recently, they are typically cumbersome and hard to extend to large-scale applications. In this work, we propose a new algorithm for circuit routing, named Ranking Cost, which innovatively combines search-based methods (i.e., A* algorithm) and learning-based methods (i.e., Evolution Strategies) to form an efficient and trainable router. In our method, we introduce a new set of variables called cost maps, which can help the A* router to find out proper paths to achieve the global objective. We also train a ranking parameter, which can produce the ranking order and further improve the performance of our method. Our algorithm is trained in an end-to-end manner and does not use any artificial data or human demonstration. In the experiments, we compare with the sequential A* algorithm and a canonical reinforcement learning approach, and results show that our method outperforms these baselines with higher connectivity rates and better scalability.
Pix2seq: A Language Modeling Framework for Object Detection
Sep 22, 2021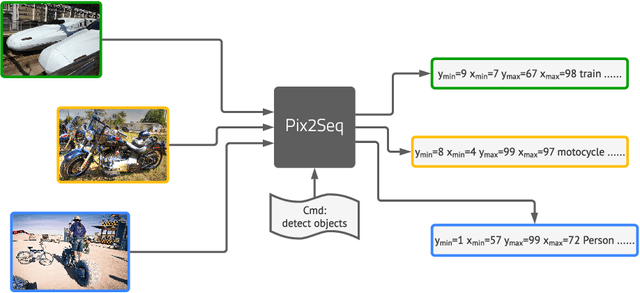
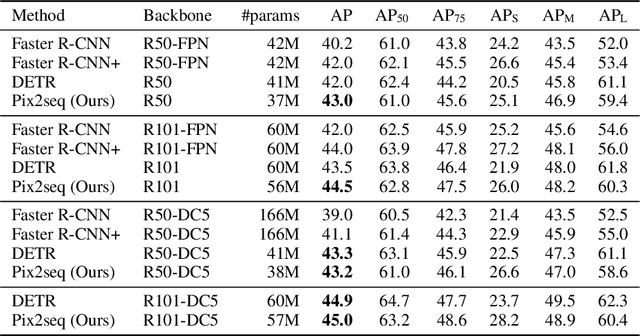
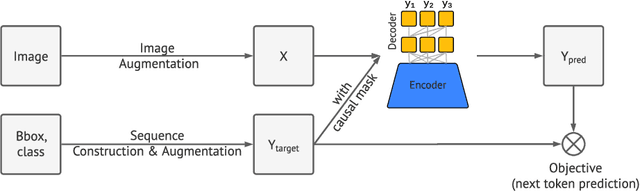
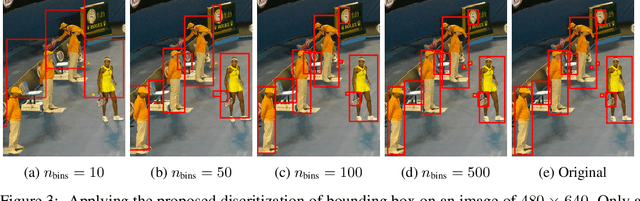
This paper presents Pix2Seq, a simple and generic framework for object detection. Unlike existing approaches that explicitly integrate prior knowledge about the task, we simply cast object detection as a language modeling task conditioned on the observed pixel inputs. Object descriptions (e.g., bounding boxes and class labels) are expressed as sequences of discrete tokens, and we train a neural net to perceive the image and generate the desired sequence. Our approach is based mainly on the intuition that if a neural net knows about where and what the objects are, we just need to teach it how to read them out. Beyond the use of task-specific data augmentations, our approach makes minimal assumptions about the task, yet it achieves competitive results on the challenging COCO dataset, compared to highly specialized and well optimized detection algorithms.
MURAL: Multimodal, Multitask Retrieval Across Languages
Sep 10, 2021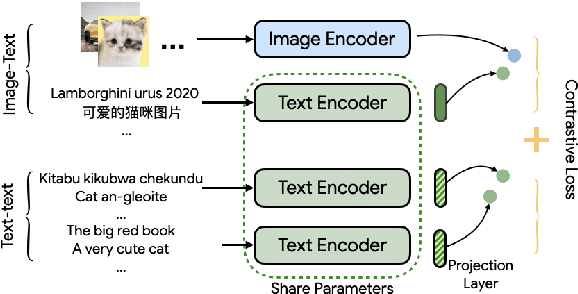
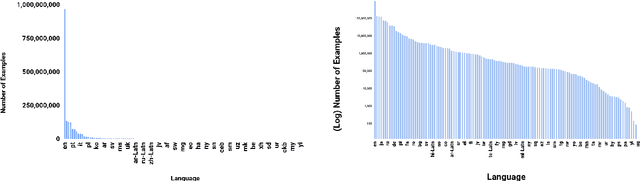
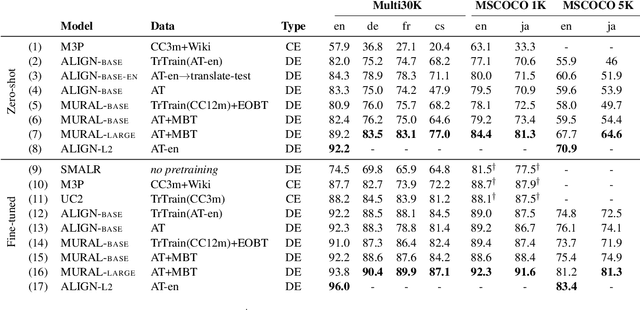
Both image-caption pairs and translation pairs provide the means to learn deep representations of and connections between languages. We use both types of pairs in MURAL (MUltimodal, MUltitask Representations Across Languages), a dual encoder that solves two tasks: 1) image-text matching and 2) translation pair matching. By incorporating billions of translation pairs, MURAL extends ALIGN (Jia et al. PMLR'21)--a state-of-the-art dual encoder learned from 1.8 billion noisy image-text pairs. When using the same encoders, MURAL's performance matches or exceeds ALIGN's cross-modal retrieval performance on well-resourced languages across several datasets. More importantly, it considerably improves performance on under-resourced languages, showing that text-text learning can overcome a paucity of image-caption examples for these languages. On the Wikipedia Image-Text dataset, for example, MURAL-base improves zero-shot mean recall by 8.1% on average for eight under-resourced languages and by 6.8% on average when fine-tuning. We additionally show that MURAL's text representations cluster not only with respect to genealogical connections but also based on areal linguistics, such as the Balkan Sprachbund.
Improved Transformer for High-Resolution GANs
Jun 14, 2021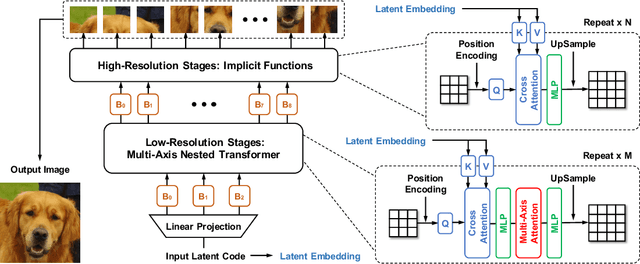
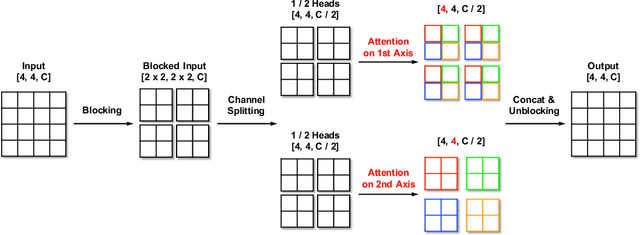
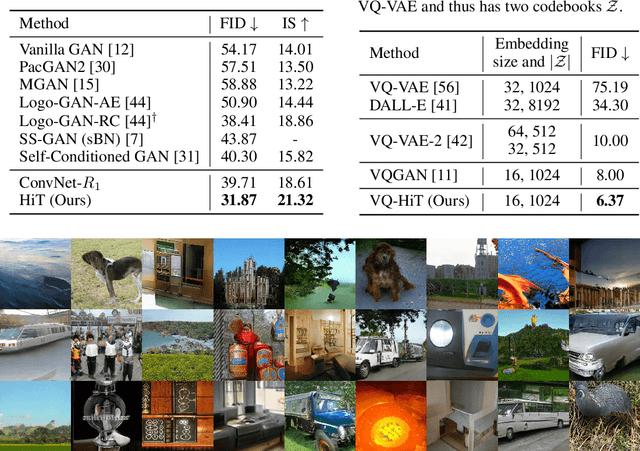

Attention-based models, exemplified by the Transformer, can effectively model long range dependency, but suffer from the quadratic complexity of self-attention operation, making them difficult to be adopted for high-resolution image generation based on Generative Adversarial Networks (GANs). In this paper, we introduce two key ingredients to Transformer to address this challenge. First, in low-resolution stages of the generative process, standard global self-attention is replaced with the proposed multi-axis blocked self-attention which allows efficient mixing of local and global attention. Second, in high-resolution stages, we drop self-attention while only keeping multi-layer perceptrons reminiscent of the implicit neural function. To further improve the performance, we introduce an additional self-modulation component based on cross-attention. The resulting model, denoted as HiT, has a linear computational complexity with respect to the image size and thus directly scales to synthesizing high definition images. We show in the experiments that the proposed HiT achieves state-of-the-art FID scores of 31.87 and 2.95 on unconditional ImageNet $128 \times 128$ and FFHQ $256 \times 256$, respectively, with a reasonable throughput. We believe the proposed HiT is an important milestone for generators in GANs which are completely free of convolutions.