 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Space and Time with Diffusion Models
Jul 10, 2024We present 4DiM, a cascaded diffusion model for 4D novel view synthesis (NVS), conditioned on one or more images of a general scene, and a set of camera poses and timestamps. To overcome challenges due to limited availability of 4D training data, we advocate joint training on 3D (with camera pose), 4D (pose+time) and video (time but no pose) data and propose a new architecture that enables the same. We further advocate the calibration of SfM posed data using monocular metric depth estimators for metric scale camera control. For model evaluation, we introduce new metrics to enrich and overcome shortcomings of current evaluation schemes, demonstrating state-of-the-art results in both fidelity and pose control compared to existing diffusion models for 3D NVS, while at the same time adding the ability to handle temporal dynamics. 4DiM is also used for improved panorama stitching, pose-conditioned video to video translation, and several other tasks. For an overview see https://4d-diffusion.github.io
Guiding Image Captioning Models Toward More Specific Captions
Jul 31, 2023



Image captioning is conventionally formulated as the task of generating captions for images that match the distribution of reference image-caption pairs. However, reference captions in standard captioning datasets are short and may not uniquely identify the images they describe. These problems are further exacerbated when models are trained directly on image-alt text pairs collected from the internet. In this work, we show that it is possible to generate more specific captions with minimal changes to the training process. We implement classifier-free guidance for an autoregressive captioning model by fine-tuning it to estimate both conditional and unconditional distributions over captions. The guidance scale applied at decoding controls a trade-off between maximizing $p(\mathrm{caption}|\mathrm{image})$ and $p(\mathrm{image}|\mathrm{caption})$. Compared to standard greedy decoding, decoding with a guidance scale of 2 substantially improves reference-free metrics such as CLIPScore (0.808 vs. 0.775) and caption$\to$image retrieval performance in the CLIP embedding space (recall@1 44.6% vs. 26.5%), but worsens standard reference-based captioning metrics (e.g., CIDEr 78.6 vs 126.1). We further explore the use of language models to guide the decoding process, obtaining small improvements over the Pareto frontier of reference-free vs. reference-based captioning metrics that arises from classifier-free guidance, and substantially improving the quality of captions generated from a model trained only on minimally curated web data.
FIT: Far-reaching Interleaved Transformers
May 25, 2023



We present FIT: a transformer-based architecture with efficient self-attention and adaptive computation. Unlike original transformers, which operate on a single sequence of data tokens, we divide the data tokens into groups, with each group being a shorter sequence of tokens. We employ two types of transformer layers: local layers operate on data tokens within each group, while global layers operate on a smaller set of introduced latent tokens. These layers, comprising the same set of self-attention and feed-forward layers as standard transformers, are interleaved, and cross-attention is used to facilitate information exchange between data and latent tokens within the same group. The attention complexity is $O(n^2)$ locally within each group of size $n$, but can reach $O(L^{{4}/{3}})$ globally for sequence length of $L$. The efficiency can be further enhanced by relying more on global layers that perform adaptive computation using a smaller set of latent tokens. FIT is a versatile architecture and can function as an encoder, diffusion decoder, or autoregressive decoder. We provide initial evidence demonstrating its effectiveness in high-resolution image understanding and generation tasks. Notably, FIT exhibits potential in performing end-to-end training on gigabit-scale data, such as 6400$\times$6400 images, or 160K tokens (after patch tokenization), within a memory capacity of 16GB, without requiring specific optimizations or model parallelism.
A Generalist Framework for Panoptic Segmentation of Images and Videos
Oct 12, 2022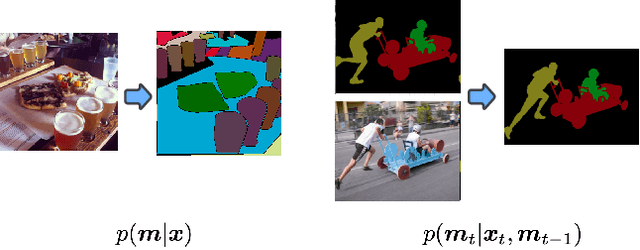
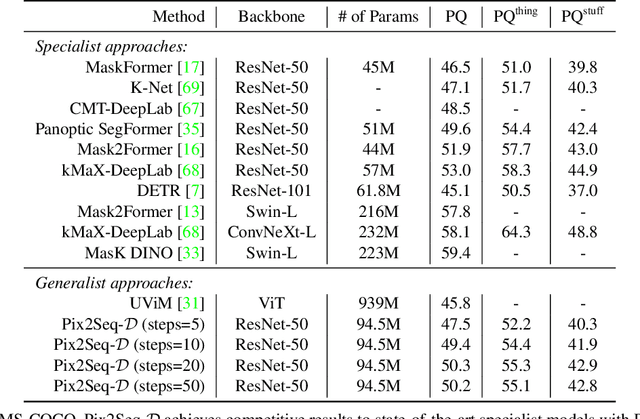
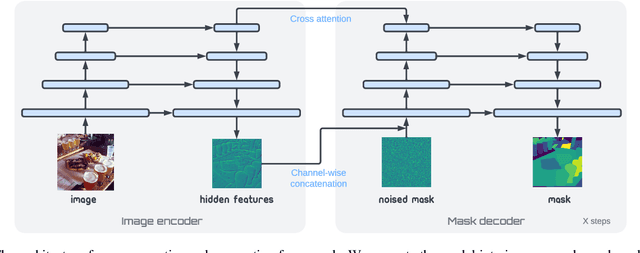
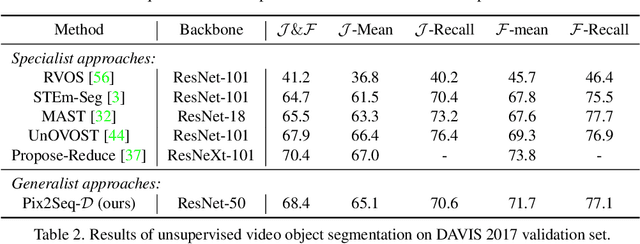
Panoptic segmentation assigns semantic and instance ID labels to every pixel of an image. As permutations of instance IDs are also valid solutions, the task requires learning of high-dimensional one-to-many mapping. As a result, state-of-the-art approaches use customized architectures and task-specific loss functions. We formulate panoptic segmentation as a discrete data generation problem, without relying on inductive bias of the task. A diffusion model based on analog bits is used to model panoptic masks, with a simple, generic architecture and loss function. By simply adding past predictions as a conditioning signal, our method is capable of modeling video (in a streaming setting) and thereby learns to track object instances automatically. With extensive experiments, we demonstrate that our generalist approach can perform competitively to state-of-the-art specialist methods in similar settings.
A Unified Sequence Interface for Vision Tasks
Jun 15, 2022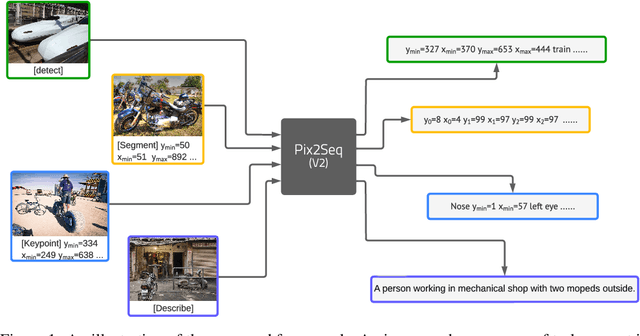
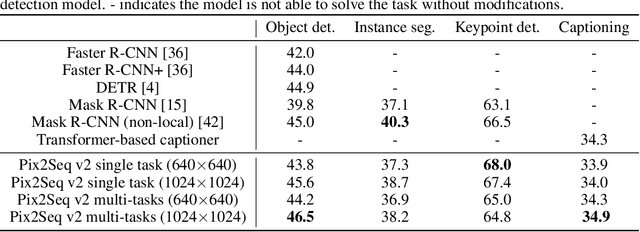
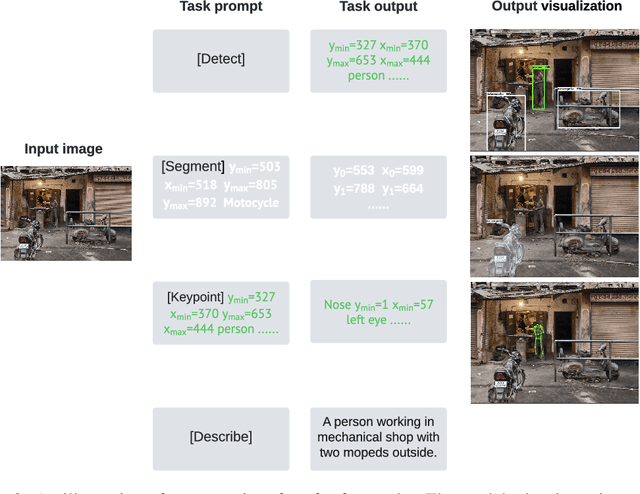

While language tasks are naturally expressed in a single, unified, modeling framework, i.e., generating sequences of tokens, this has not been the case in computer vision. As a result, there is a proliferation of distinct architectures and loss functions for different vision tasks. In this work we show that a diverse set of "core" computer vision tasks can also be unified if formulated in terms of a shared pixel-to-sequence interface. We focus on four tasks, namely, object detection, instance segmentation, keypoint detection, and image captioning, all with diverse types of outputs, e.g., bounding boxes or dense masks. Despite that, by formulating the output of each task as a sequence of discrete tokens with a unified interface, we show that one can train a neural network with a single model architecture and loss function on all these tasks, with no task-specific customization. To solve a specific task, we use a short prompt as task description, and the sequence output adapts to the prompt so it can produce task-specific output. We show that such a model can achieve competitive performance compared to well-established task-specific models.
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
May 23, 2022

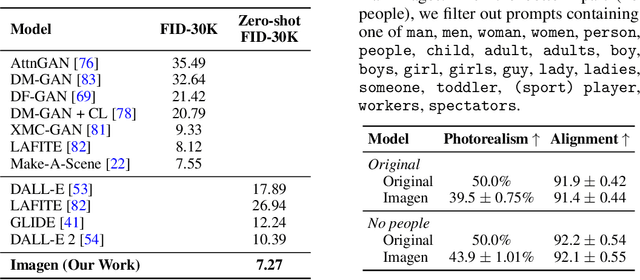
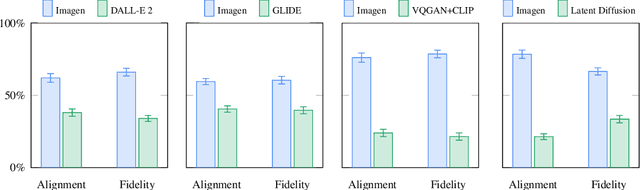
We present Imagen, a text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding. Imagen builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation. Our key discovery is that generic large language models (e.g. T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis: increasing the size of the language model in Imagen boosts both sample fidelity and image-text alignment much more than increasing the size of the image diffusion model. Imagen achieves a new state-of-the-art FID score of 7.27 on the COCO dataset, without ever training on COCO, and human raters find Imagen samples to be on par with the COCO data itself in image-text alignment. To assess text-to-image models in greater depth, we introduce DrawBench, a comprehensive and challenging benchmark for text-to-image models. With DrawBench, we compare Imagen with recent methods including VQ-GAN+CLIP, Latent Diffusion Models, and DALL-E 2, and find that human raters prefer Imagen over other models in side-by-side comparisons, both in terms of sample quality and image-text alignment. See https://imagen.research.google/ for an overview of the results.
Pix2seq: A Language Modeling Framework for Object Detection
Sep 22, 2021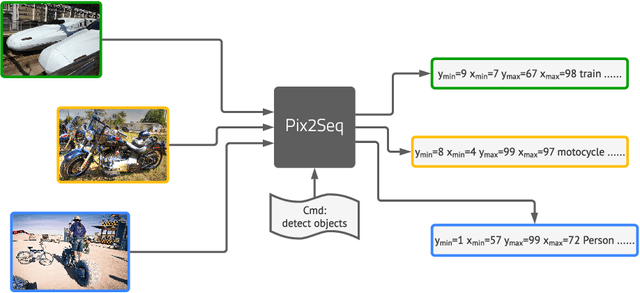
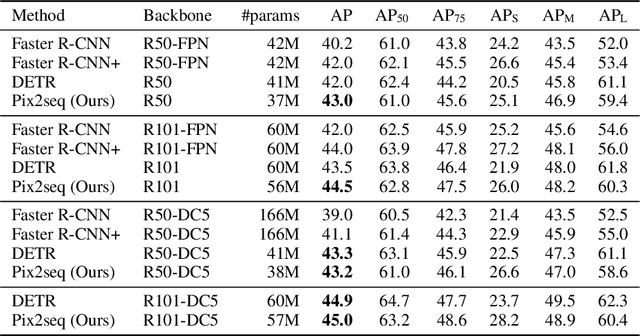
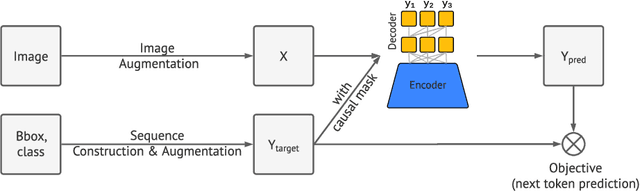
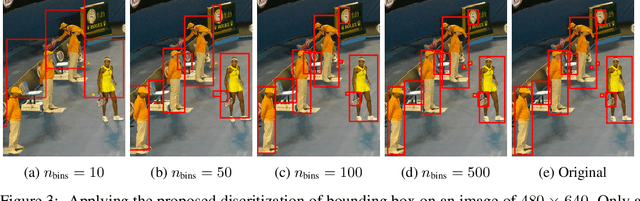
This paper presents Pix2Seq, a simple and generic framework for object detection. Unlike existing approaches that explicitly integrate prior knowledge about the task, we simply cast object detection as a language modeling task conditioned on the observed pixel inputs. Object descriptions (e.g., bounding boxes and class labels) are expressed as sequences of discrete tokens, and we train a neural net to perceive the image and generate the desired sequence. Our approach is based mainly on the intuition that if a neural net knows about where and what the objects are, we just need to teach it how to read them out. Beyond the use of task-specific data augmentations, our approach makes minimal assumptions about the task, yet it achieves competitive results on the challenging COCO dataset, compared to highly specialized and well optimized detection algorithms.
Intriguing Properties of Contrastive Losses
Nov 05, 2020

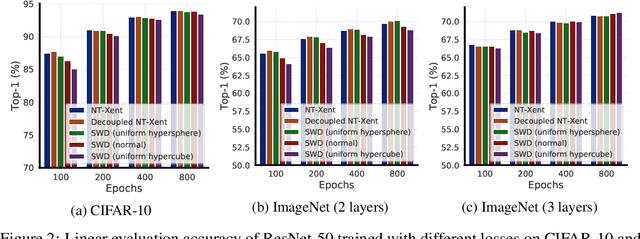
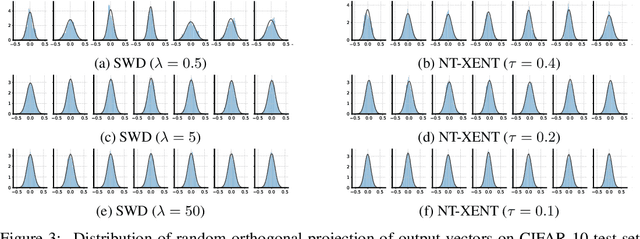
Contrastive loss and its variants have become very popular recently for learning visual representations without supervision. In this work, we first generalize the standard contrastive loss based on cross entropy to a broader family of losses that share an abstract form of $\mathcal{L}_{\text{alignment}} + \lambda \mathcal{L}_{\text{distribution}}$, where hidden representations are encouraged to (1) be aligned under some transformations/augmentations, and (2) match a prior distribution of high entropy. We show that various instantiations of the generalized loss perform similarly under the presence of a multi-layer non-linear projection head, and the temperature scaling ($\tau$) widely used in the standard contrastive loss is (within a range) inversely related to the weighting ($\lambda$) between the two loss terms. We then study an intriguing phenomenon of feature suppression among competing features shared acros augmented views, such as "color distribution" vs "object class". We construct datasets with explicit and controllable competing features, and show that, for contrastive learning, a few bits of easy-to-learn shared features could suppress, and even fully prevent, the learning of other sets of competing features. Interestingly, this characteristic is much less detrimental in autoencoders based on a reconstruction loss. Existing contrastive learning methods critically rely on data augmentation to favor certain sets of features than others, while one may wish that a network would learn all competing features as much as its capacity allows.
Big Bidirectional Insertion Representations for Documents
Oct 29, 2019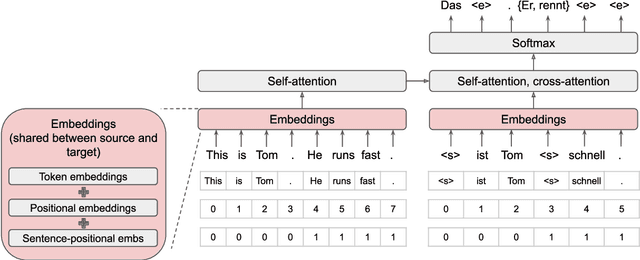
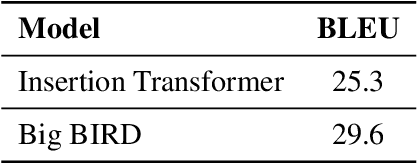

The Insertion Transformer is well suited for long form text generation due to its parallel generation capabilities, requiring $O(\log_2 n)$ generation steps to generate $n$ tokens. However, modeling long sequences is difficult, as there is more ambiguity captured in the attention mechanism. This work proposes the Big Bidirectional Insertion Representations for Documents (Big BIRD), an insertion-based model for document-level translation tasks. We scale up the insertion-based models to long form documents. Our key contribution is introducing sentence alignment via sentence-positional embeddings between the source and target document. We show an improvement of +4.3 BLEU on the WMT'19 English$\rightarrow$German document-level translation task compared with the Insertion Transformer baseline.
Which Algorithmic Choices Matter at Which Batch Sizes? Insights From a Noisy Quadratic Model
Jul 09, 2019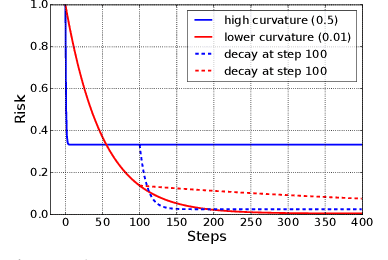
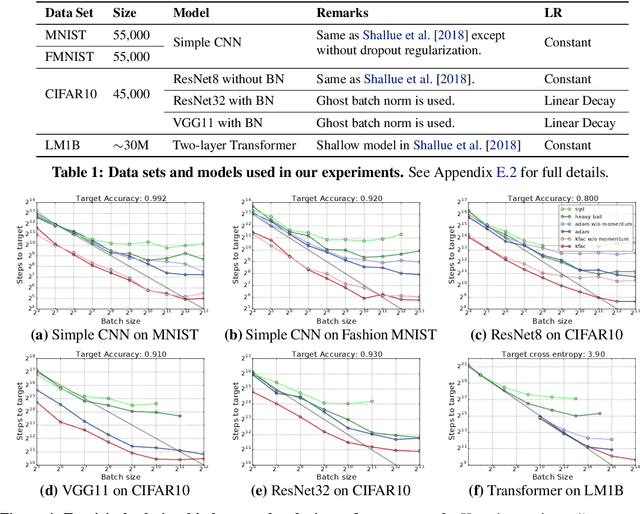
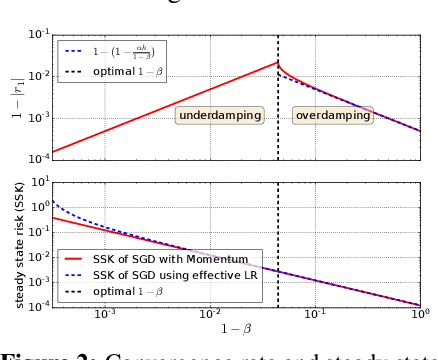
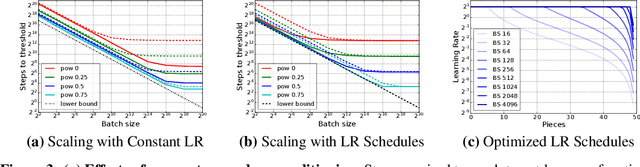
Increasing the batch size is a popular way to speed up neural network training, but beyond some critical batch size, larger batch sizes yield diminishing returns. In this work, we study how the critical batch size changes based on properties of the optimization algorithm, including acceleration and preconditioning, through two different lenses: large scale experiments, and analysis of a simple noisy quadratic model (NQM). We experimentally demonstrate that optimization algorithms that employ preconditioning, specifically Adam and K-FAC, result in much larger critical batch sizes than stochastic gradient descent with momentum. We also demonstrate that the NQM captures many of the essential features of real neural network training, despite being drastically simpler to work with. The NQM predicts our results with preconditioned optimizers, previous results with accelerated gradient descent, and other results around optimal learning rates and large batch training, making it a useful tool to generate testable predictions about neural network optimization.