 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Generative Utility of Cyclic Conditionals
Aug 03, 2021
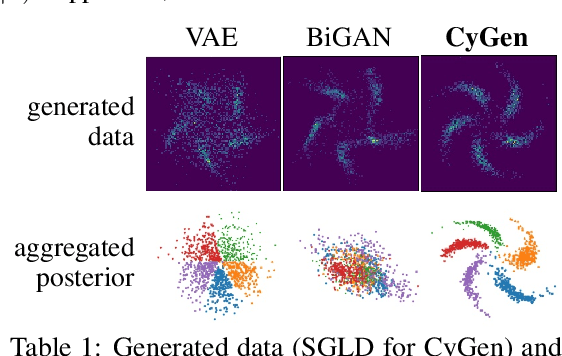
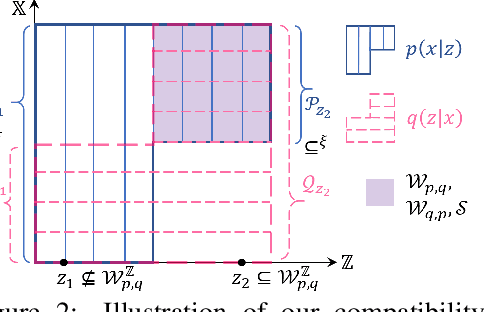

We study whether and how can we model a joint distribution $p(x,z)$ using two conditional models $p(x|z)$ and $q(z|x)$ that form a cycle. This is motivated by the observation that deep generative models, in addition to a likelihood model $p(x|z)$, often also use an inference model $q(z|x)$ for data representation, but they rely on a usually uninformative prior distribution $p(z)$ to define a joint distribution, which may render problems like posterior collapse and manifold mismatch. To explore the possibility to model a joint distribution using only $p(x|z)$ and $q(z|x)$, we study their compatibility and determinacy, corresponding to the existence and uniqueness of a joint distribution whose conditional distributions coincide with them. We develop a general theory for novel and operable equivalence criteria for compatibility, and sufficient conditions for determinacy. Based on the theory, we propose the CyGen framework for cyclic-conditional generative modeling, including methods to enforce compatibility and use the determined distribution to fit and generate data. With the prior constraint removed, CyGen better fits data and captures more representative features, supported by experiments showing better generation and downstream classification performance.
A Survey on Neural Speech Synthesis
Jul 23, 2021

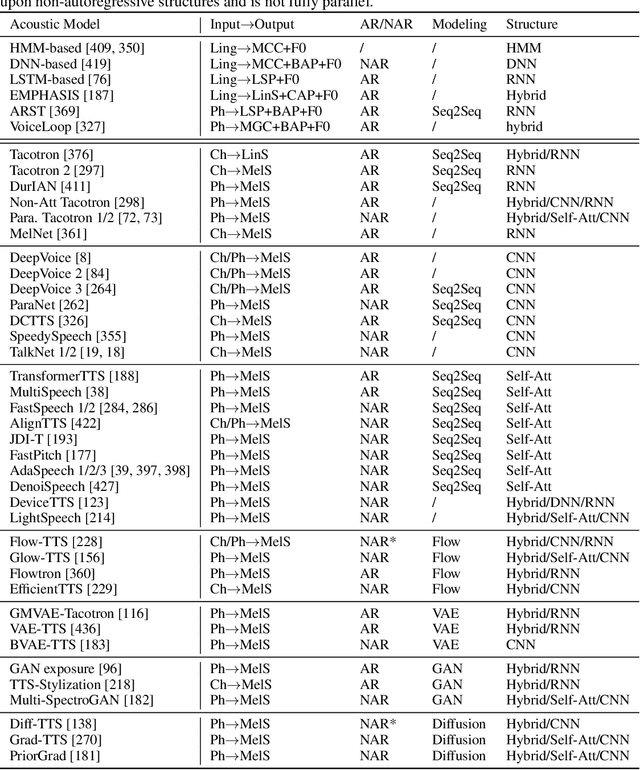
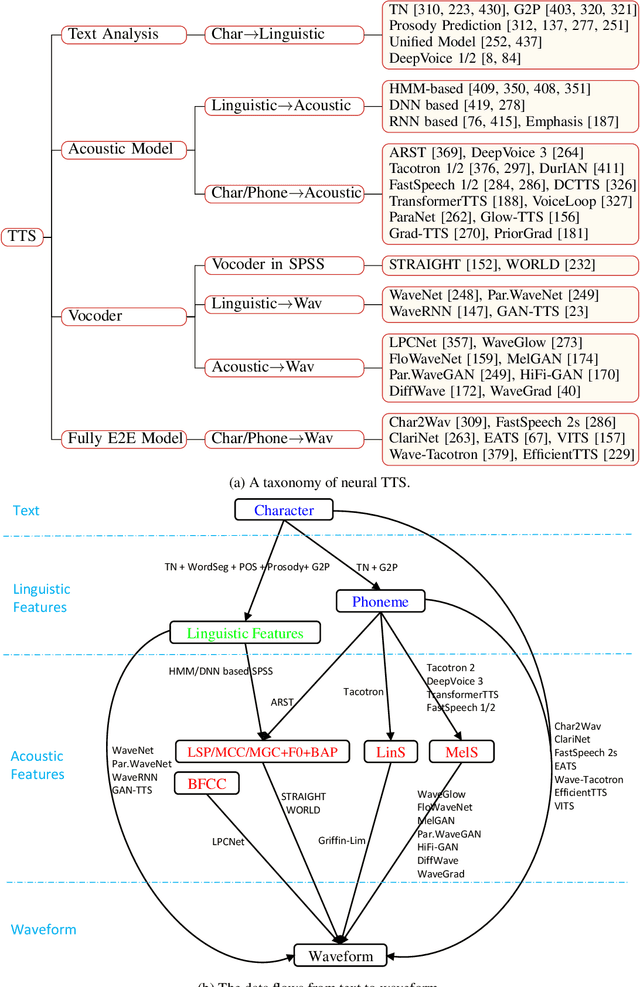
Text to speech (TTS), or speech synthesis, which aims to synthesize intelligible and natural speech given text, is a hot research topic in speech, language, and machine learning communities and has broad applications in the industry. As the development of deep learning and artificial intelligence, neural network-based TTS has significantly improved the quality of synthesized speech in recent years. In this paper, we conduct a comprehensive survey on neural TTS, aiming to provide a good understanding of current research and future trends. We focus on the key components in neural TTS, including text analysis, acoustic models and vocoders, and several advanced topics, including fast TTS, low-resource TTS, robust TTS, expressive TTS, and adaptive TTS, etc. We further summarize resources related to TTS (e.g., datasets, opensource implementations) and discuss future research directions. This survey can serve both academic researchers and industry practitioners working on TTS.
A Survey on Low-Resource Neural Machine Translation
Jul 09, 2021



Neural approaches have achieved state-of-the-art accuracy on machine translation but suffer from the high cost of collecting large scale parallel data. Thus, a lot of research has been conducted for neural machine translation (NMT) with very limited parallel data, i.e., the low-resource setting. In this paper, we provide a survey for low-resource NMT and classify related works into three categories according to the auxiliary data they used: (1) exploiting monolingual data of source and/or target languages, (2) exploiting data from auxiliary languages, and (3) exploiting multi-modal data. We hope that our survey can help researchers to better understand this field and inspire them to design better algorithms, and help industry practitioners to choose appropriate algorithms for their applications.
AdaSpeech 3: Adaptive Text to Speech for Spontaneous Style
Jul 06, 2021
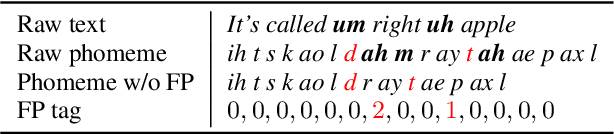

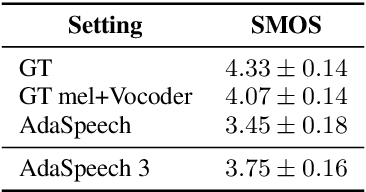
While recent text to speech (TTS) models perform very well in synthesizing reading-style (e.g., audiobook) speech, it is still challenging to synthesize spontaneous-style speech (e.g., podcast or conversation), mainly because of two reasons: 1) the lack of training data for spontaneous speech; 2) the difficulty in modeling the filled pauses (um and uh) and diverse rhythms in spontaneous speech. In this paper, we develop AdaSpeech 3, an adaptive TTS system that fine-tunes a well-trained reading-style TTS model for spontaneous-style speech. Specifically, 1) to insert filled pauses (FP) in the text sequence appropriately, we introduce an FP predictor to the TTS model; 2) to model the varying rhythms, we introduce a duration predictor based on mixture of experts (MoE), which contains three experts responsible for the generation of fast, medium and slow speech respectively, and fine-tune it as well as the pitch predictor for rhythm adaptation; 3) to adapt to other speaker timbre, we fine-tune some parameters in the decoder with few speech data. To address the challenge of lack of training data, we mine a spontaneous speech dataset to support our research this work and facilitate future research on spontaneous TTS. Experiments show that AdaSpeech 3 synthesizes speech with natural FP and rhythms in spontaneous styles, and achieves much better MOS and SMOS scores than previous adaptive TTS systems.
Causally Invariant Predictor with Shift-Robustness
Jul 05, 2021


This paper proposes an invariant causal predictor that is robust to distribution shift across domains and maximally reserves the transferable invariant information. Based on a disentangled causal factorization, we formulate the distribution shift as soft interventions in the system, which covers a wide range of cases for distribution shift as we do not make prior specifications on the causal structure or the intervened variables. Instead of imposing regularizations to constrain the invariance of the predictor, we propose to predict by the intervened conditional expectation based on the do-operator and then prove that it is invariant across domains. More importantly, we prove that the proposed predictor is the robust predictor that minimizes the worst-case quadratic loss among the distributions of all domains. For empirical learning, we propose an intuitive and flexible estimating method based on data regeneration and present a local causal discovery procedure to guide the regeneration step. The key idea is to regenerate data such that the regenerated distribution is compatible with the intervened graph, which allows us to incorporate standard supervised learning methods with the regenerated data. Experimental results on both synthetic and real data demonstrate the efficacy of our predictor in improving the predictive accuracy and robustness across domains.
DeepRapper: Neural Rap Generation with Rhyme and Rhythm Modeling
Jul 05, 2021
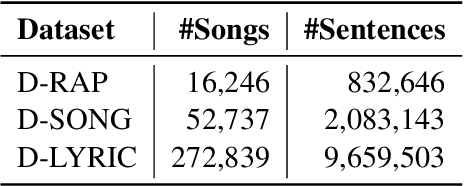
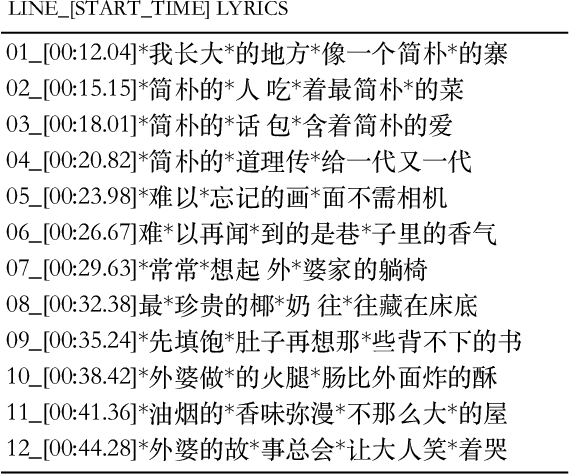

Rap generation, which aims to produce lyrics and corresponding singing beats, needs to model both rhymes and rhythms. Previous works for rap generation focused on rhyming lyrics but ignored rhythmic beats, which are important for rap performance. In this paper, we develop DeepRapper, a Transformer-based rap generation system that can model both rhymes and rhythms. Since there is no available rap dataset with rhythmic beats, we develop a data mining pipeline to collect a large-scale rap dataset, which includes a large number of rap songs with aligned lyrics and rhythmic beats. Second, we design a Transformer-based autoregressive language model which carefully models rhymes and rhythms. Specifically, we generate lyrics in the reverse order with rhyme representation and constraint for rhyme enhancement and insert a beat symbol into lyrics for rhythm/beat modeling. To our knowledge, DeepRapper is the first system to generate rap with both rhymes and rhythms. Both objective and subjective evaluations demonstrate that DeepRapper generates creative and high-quality raps with rhymes and rhythms. Code will be released on GitHub.
Supervised Off-Policy Ranking
Jul 03, 2021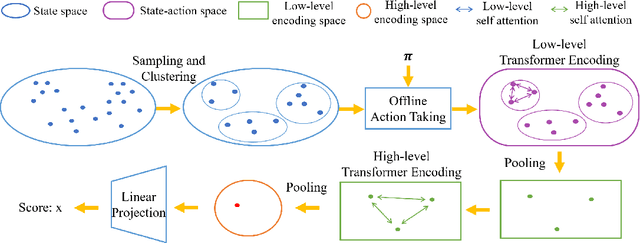

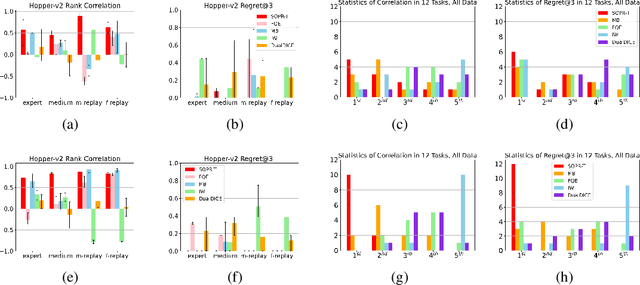
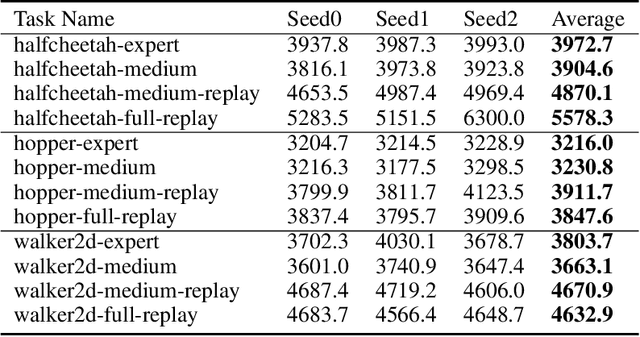
Off-policy evaluation (OPE) leverages data generated by other policies to evaluate a target policy. Previous OPE methods mainly focus on precisely estimating the true performance of a policy. We observe that in many applications, (1) the end goal of OPE is to compare two or multiple candidate policies and choose a good one, which is actually a much simpler task than evaluating their true performance; and (2) there are usually multiple policies that have been deployed in real-world systems and thus whose true performance is known through serving real users. Inspired by the two observations, in this work, we define a new problem, supervised off-policy ranking (SOPR), which aims to rank a set of new/target policies based on supervised learning by leveraging off-policy data and policies with known performance. We further propose a method for supervised off-policy ranking that learns a policy scoring model by correctly ranking training policies with known performance rather than estimating their precise performance. Our method leverages logged states and policies to learn a Transformer based model that maps offline interaction data including logged states and the actions taken by a target policy on these states to a score. Experiments on different games, datasets, training policy sets, and test policy sets show that our method outperforms strong baseline OPE methods in terms of both rank correlation and performance gap between the truly best and the best of the ranked top three policies. Furthermore, our method is more stable than baseline methods.
Regularized OFU: an Efficient UCB Estimator forNon-linear Contextual Bandit
Jun 29, 2021
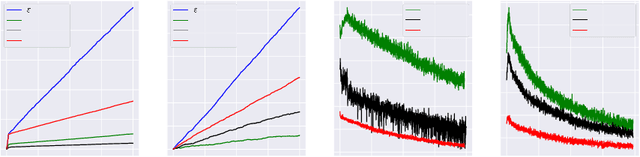
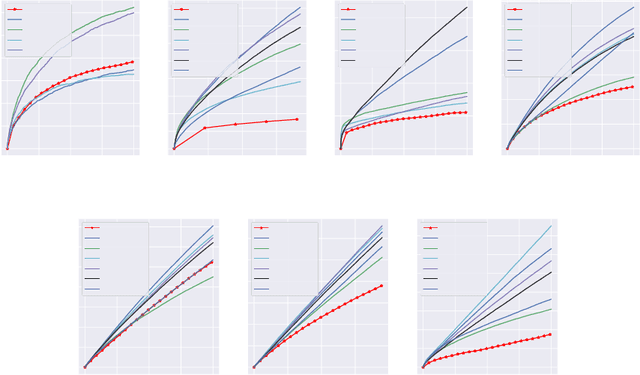

Balancing exploration and exploitation (EE) is a fundamental problem in contex-tual bandit. One powerful principle for EE trade-off isOptimism in Face of Uncer-tainty(OFU), in which the agent takes the action according to an upper confidencebound (UCB) of reward. OFU has achieved (near-)optimal regret bound for lin-ear/kernel contextual bandits. However, it is in general unknown how to deriveefficient and effective EE trade-off methods for non-linearcomplex tasks, suchas contextual bandit with deep neural network as the reward function. In thispaper, we propose a novel OFU algorithm namedregularized OFU(ROFU). InROFU, we measure the uncertainty of the reward by a differentiable function andcompute the upper confidence bound by solving a regularized optimization prob-lem. We prove that, for multi-armed bandit, kernel contextual bandit and neuraltangent kernel bandit, ROFU achieves (near-)optimal regret bounds with certainuncertainty measure, which theoretically justifies its effectiveness on EE trade-off.Importantly, ROFU admits a very efficient implementation with gradient-basedoptimizer, which easily extends to general deep neural network models beyondneural tangent kernel, in sharp contrast with previous OFU methods. The em-pirical evaluation demonstrates that ROFU works extremelywell for contextualbandits under various settings.
R-Drop: Regularized Dropout for Neural Networks
Jun 28, 2021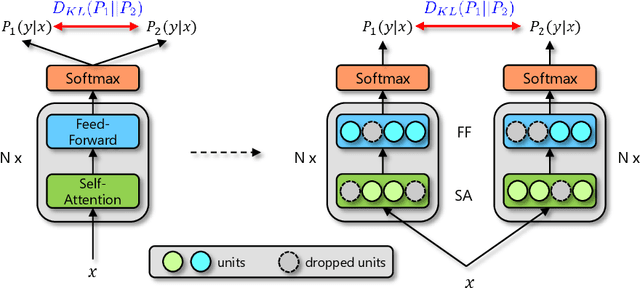

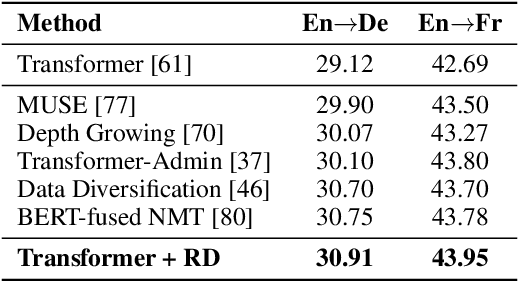
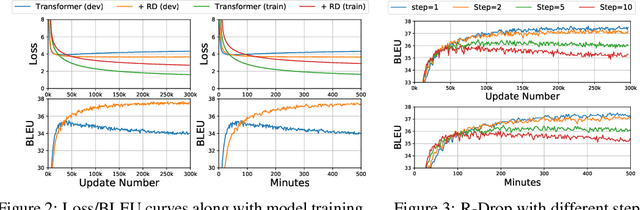
Dropout is a powerful and widely used technique to regularize the training of deep neural networks. In this paper, we introduce a simple regularization strategy upon dropout in model training, namely R-Drop, which forces the output distributions of different sub models generated by dropout to be consistent with each other. Specifically, for each training sample, R-Drop minimizes the bidirectional KL-divergence between the output distributions of two sub models sampled by dropout. Theoretical analysis reveals that R-Drop reduces the freedom of the model parameters and complements dropout. Experiments on $\bf{5}$ widely used deep learning tasks ($\bf{18}$ datasets in total), including neural machine translation, abstractive summarization, language understanding, language modeling, and image classification, show that R-Drop is universally effective. In particular, it yields substantial improvements when applied to fine-tune large-scale pre-trained models, e.g., ViT, RoBERTa-large, and BART, and achieves state-of-the-art (SOTA) performances with the vanilla Transformer model on WMT14 English$\to$German translation ($\bf{30.91}$ BLEU) and WMT14 English$\to$French translation ($\bf{43.95}$ BLEU), even surpassing models trained with extra large-scale data and expert-designed advanced variants of Transformer models. Our code is available at GitHub{\url{https://github.com/dropreg/R-Drop}}.
Large Scale Private Learning via Low-rank Reparametrization
Jun 28, 2021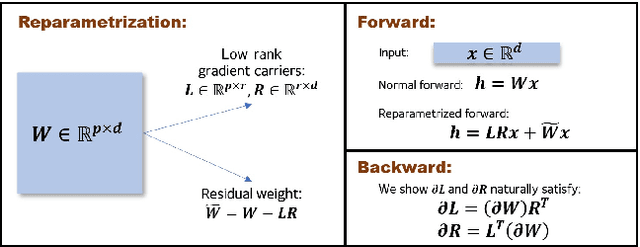

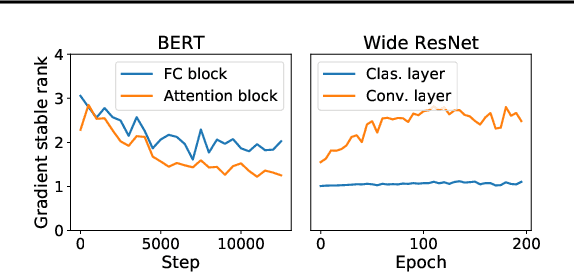
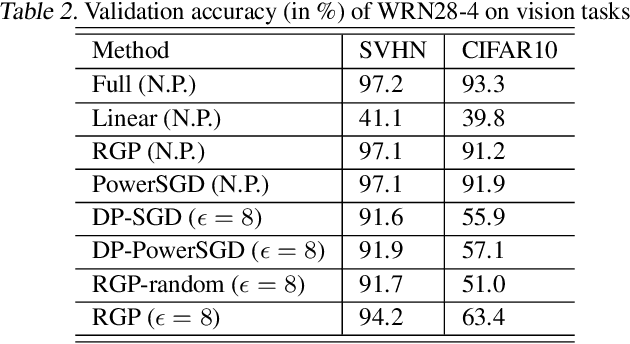
We propose a reparametrization scheme to address the challenges of applying differentially private SGD on large neural networks, which are 1) the huge memory cost of storing individual gradients, 2) the added noise suffering notorious dimensional dependence. Specifically, we reparametrize each weight matrix with two \emph{gradient-carrier} matrices of small dimension and a \emph{residual weight} matrix. We argue that such reparametrization keeps the forward/backward process unchanged while enabling us to compute the projected gradient without computing the gradient itself. To learn with differential privacy, we design \emph{reparametrized gradient perturbation (RGP)} that perturbs the gradients on gradient-carrier matrices and reconstructs an update for the original weight from the noisy gradients. Importantly, we use historical updates to find the gradient-carrier matrices, whose optimality is rigorously justified under linear regression and empirically verified with deep learning tasks. RGP significantly reduces the memory cost and improves the utility. For example, we are the first able to apply differential privacy on the BERT model and achieve an average accuracy of $83.9\%$ on four downstream tasks with $\epsilon=8$, which is within $5\%$ loss compared to the non-private baseline but enjoys much lower privacy leakage risk.