 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrdinal Regression via Binary Preference vs Simple Regression: Statistical and Experimental Perspectives
Jul 06, 2022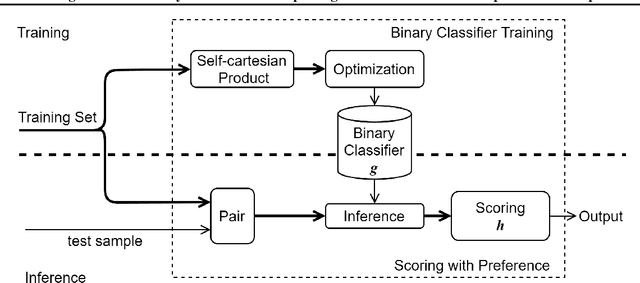

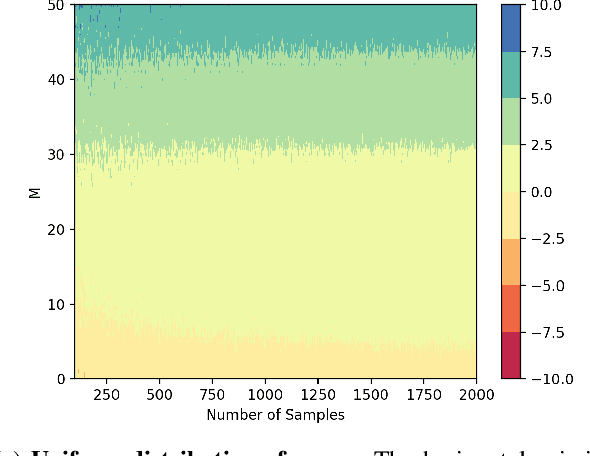
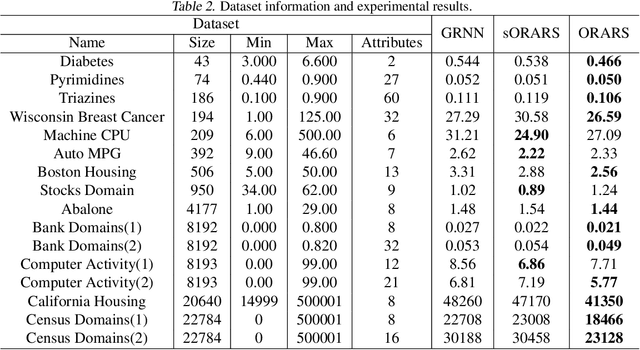
Ordinal regression with anchored reference samples (ORARS) has been proposed for predicting the subjective Mean Opinion Score (MOS) of input stimuli automatically. The ORARS addresses the MOS prediction problem by pairing a test sample with each of the pre-scored anchored reference samples. A trained binary classifier is then used to predict which sample, test or anchor, is better statistically. Posteriors of the binary preference decision are then used to predict the MOS of the test sample. In this paper, rigorous framework, analysis, and experiments to demonstrate that ORARS are advantageous over simple regressions are presented. The contributions of this work are: 1) Show that traditional regression can be reformulated into multiple preference tests to yield a better performance, which is confirmed with simulations experimentally; 2) Generalize ORARS to other regression problems and verify its effectiveness; 3) Provide some prerequisite conditions which can insure proper application of ORARS.
NaturalSpeech: End-to-End Text to Speech Synthesis with Human-Level Quality
May 10, 2022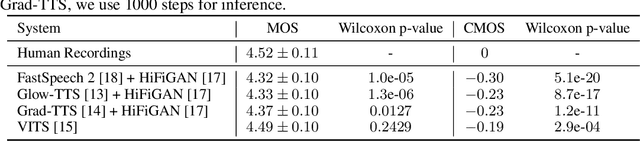
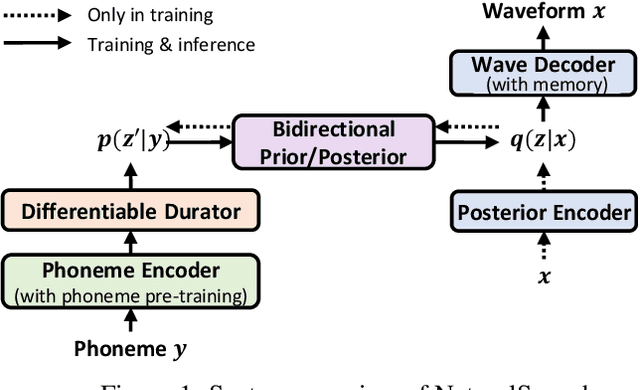
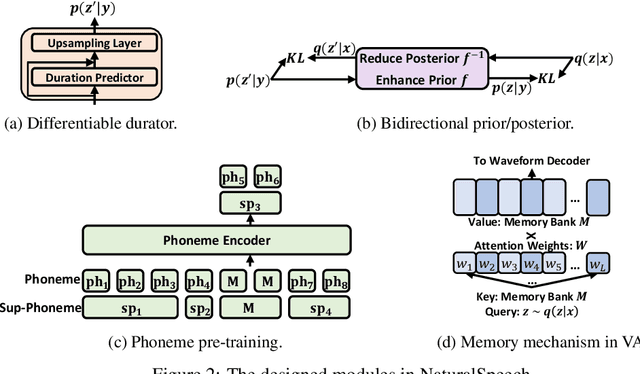
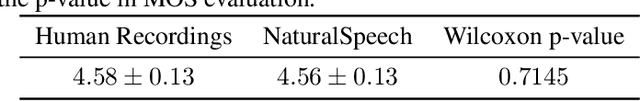
Text to speech (TTS) has made rapid progress in both academia and industry in recent years. Some questions naturally arise that whether a TTS system can achieve human-level quality, how to define/judge that quality and how to achieve it. In this paper, we answer these questions by first defining the human-level quality based on the statistical significance of subjective measure and introducing appropriate guidelines to judge it, and then developing a TTS system called NaturalSpeech that achieves human-level quality on a benchmark dataset. Specifically, we leverage a variational autoencoder (VAE) for end-to-end text to waveform generation, with several key modules to enhance the capacity of the prior from text and reduce the complexity of the posterior from speech, including phoneme pre-training, differentiable duration modeling, bidirectional prior/posterior modeling, and a memory mechanism in VAE. Experiment evaluations on popular LJSpeech dataset show that our proposed NaturalSpeech achieves -0.01 CMOS (comparative mean opinion score) to human recordings at the sentence level, with Wilcoxon signed rank test at p-level p >> 0.05, which demonstrates no statistically significant difference from human recordings for the first time on this dataset.
An Approach to Mispronunciation Detection and Diagnosis with Acoustic, Phonetic and Linguistic (APL) Embeddings
Oct 14, 2021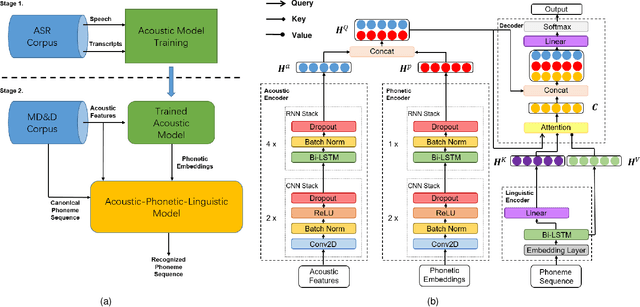
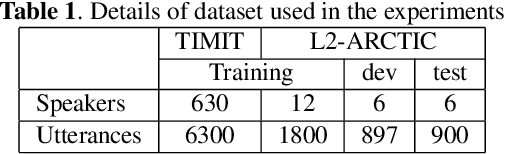
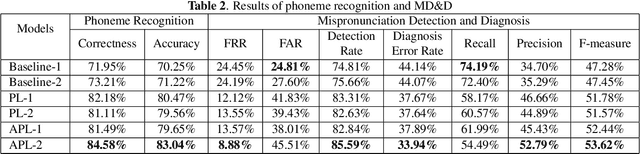
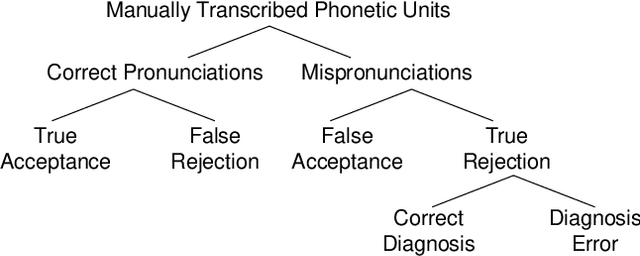
Many mispronunciation detection and diagnosis (MD&D) research approaches try to exploit both the acoustic and linguistic features as input. Yet the improvement of the performance is limited, partially due to the shortage of large amount annotated training data at the phoneme level. Phonetic embeddings, extracted from ASR models trained with huge amount of word level annotations, can serve as a good representation of the content of input speech, in a noise-robust and speaker-independent manner. These embeddings, when used as implicit phonetic supplementary information, can alleviate the data shortage of explicit phoneme annotations. We propose to utilize Acoustic, Phonetic and Linguistic (APL) embedding features jointly for building a more powerful MD\&D system. Experimental results obtained on the L2-ARCTIC database show the proposed approach outperforms the baseline by 9.93%, 10.13% and 6.17% on the detection accuracy, diagnosis error rate and the F-measure, respectively.
A Survey on Neural Speech Synthesis
Jul 23, 2021

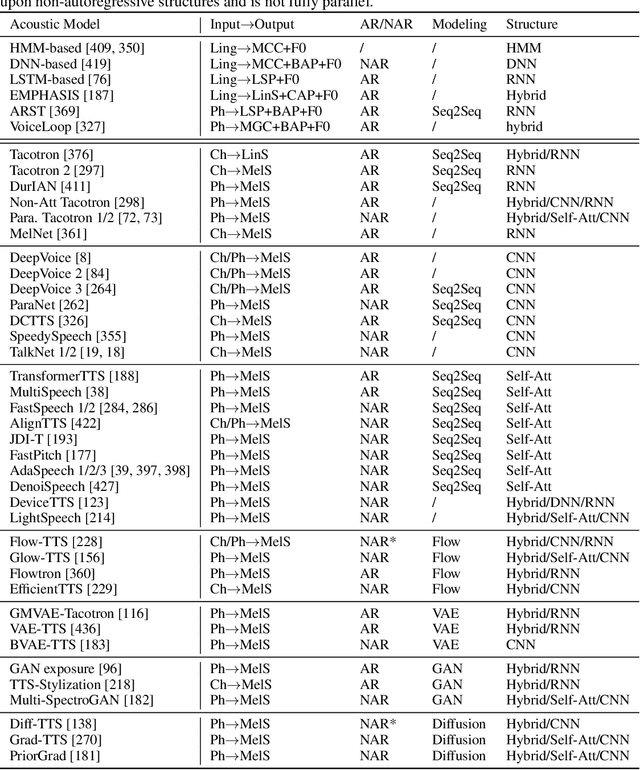
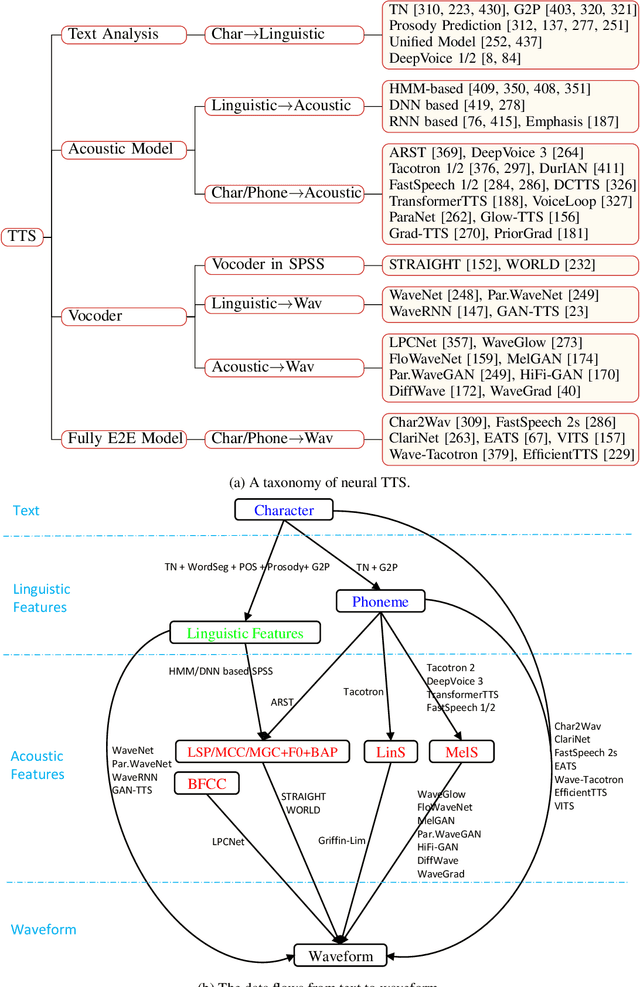
Text to speech (TTS), or speech synthesis, which aims to synthesize intelligible and natural speech given text, is a hot research topic in speech, language, and machine learning communities and has broad applications in the industry. As the development of deep learning and artificial intelligence, neural network-based TTS has significantly improved the quality of synthesized speech in recent years. In this paper, we conduct a comprehensive survey on neural TTS, aiming to provide a good understanding of current research and future trends. We focus on the key components in neural TTS, including text analysis, acoustic models and vocoders, and several advanced topics, including fast TTS, low-resource TTS, robust TTS, expressive TTS, and adaptive TTS, etc. We further summarize resources related to TTS (e.g., datasets, opensource implementations) and discuss future research directions. This survey can serve both academic researchers and industry practitioners working on TTS.
MBNet: MOS Prediction for Synthesized Speech with Mean-Bias Network
Feb 27, 2021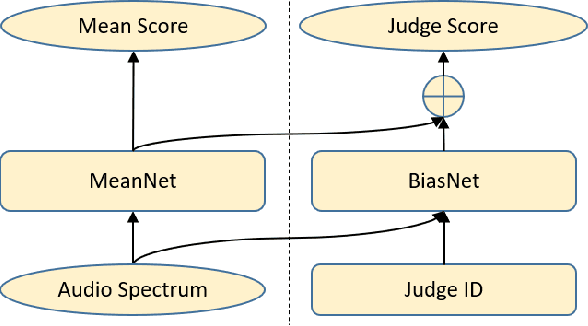


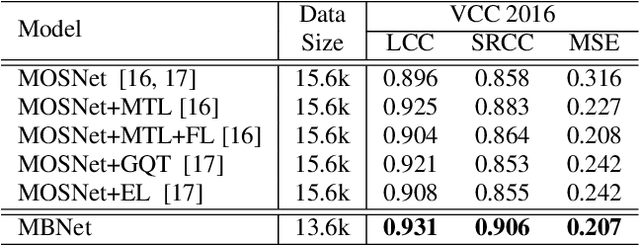
Mean opinion score (MOS) is a popular subjective metric to assess the quality of synthesized speech, and usually involves multiple human judges to evaluate each speech utterance. To reduce the labor cost in MOS test, multiple methods have been proposed to automatically predict MOS scores. To our knowledge, for a speech utterance, all previous works only used the average of multiple scores from different judges as the training target and discarded the score of each individual judge, which did not well exploit the precious MOS training data. In this paper, we propose MBNet, a MOS predictor with a mean subnet and a bias subnet to better utilize every judge score in MOS datasets, where the mean subnet is used to predict the mean score of each utterance similar to that in previous works, and the bias subnet to predict the bias score (the difference between the mean score and each individual judge score) and capture the personal preference of individual judges. Experiments show that compared with MOSNet baseline that only leverages mean score for training, MBNet improves the system-level spearmans rank correlation co-efficient (SRCC) by 2.9% on VCC 2018 dataset and 6.7% on VCC 2016 dataset.
Improving pronunciation assessment via ordinal regression with anchored reference samples
Oct 26, 2020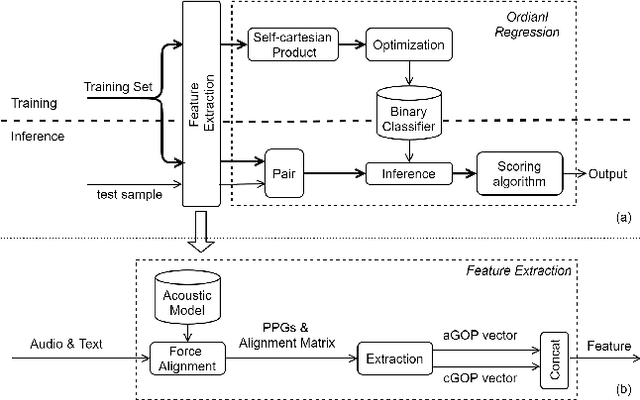
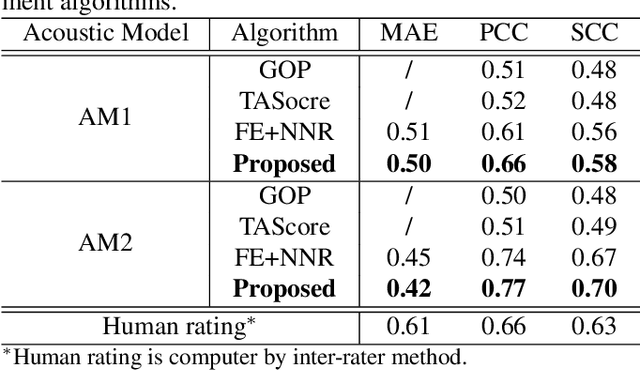
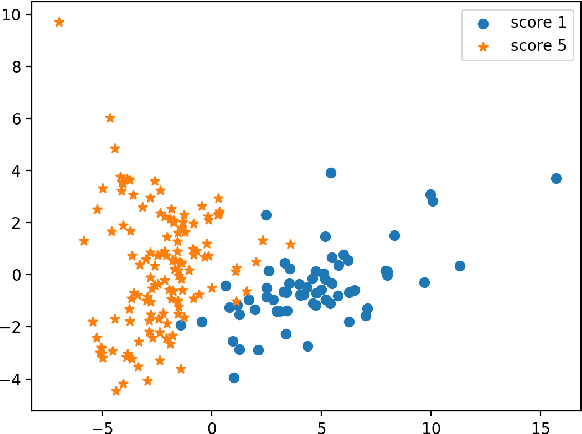
Sentence level pronunciation assessment is important for Computer Assisted Language Learning (CALL). Traditional speech pronunciation assessment, based on the Goodness of Pronunciation (GOP) algorithm, has some weakness in assessing a speech utterance: 1) Phoneme GOP scores cannot be easily translated into a sentence score with a simple average for effective assessment; 2) The rank ordering information has not been well exploited in GOP scoring for delivering a robust assessment and correlate well with a human rater's evaluations. In this paper, we propose two new statistical features, average GOP (aGOP) and confusion GOP (cGOP) and use them to train a binary classifier in Ordinal Regression with Anchored Reference Samples (ORARS). When the proposed approach is tested on Microsoft mTutor ESL Dataset, a relative improvement of Pearson correlation coefficient of 26.9% is obtained over the conventional GOP-based one. The performance is at a human-parity level or better than human raters.
Feature reinforcement with word embedding and parsing information in neural TTS
Jan 03, 2019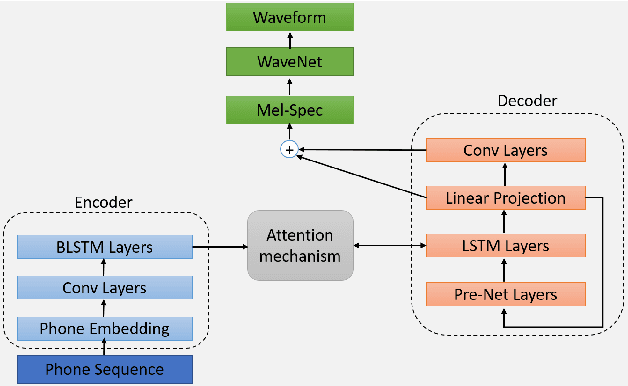
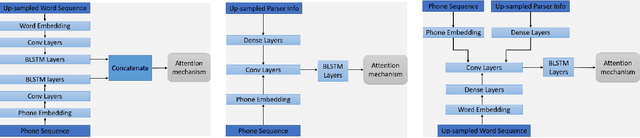
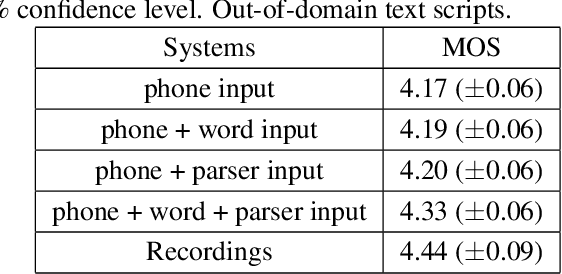
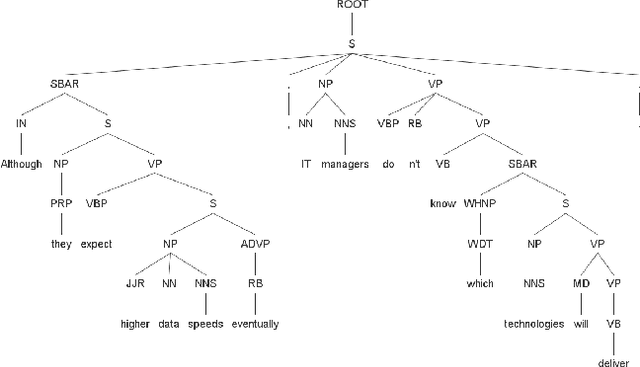
In this paper, we propose a feature reinforcement method under the sequence-to-sequence neural text-to-speech (TTS) synthesis framework. The proposed method utilizes the multiple input encoder to take three levels of text information, i.e., phoneme sequence, pre-trained word embedding, and grammatical structure of sentences from parser as the input feature for the neural TTS system. The added word and sentence level information can be viewed as the feature based pre-training strategy, which clearly enhances the model generalization ability. The proposed method not only improves the system robustness significantly but also improves the synthesized speech to near recording quality in our experiments for out-of-domain text.
Modeling Multi-speaker Latent Space to Improve Neural TTS: Quick Enrolling New Speaker and Enhancing Premium Voice
Dec 18, 2018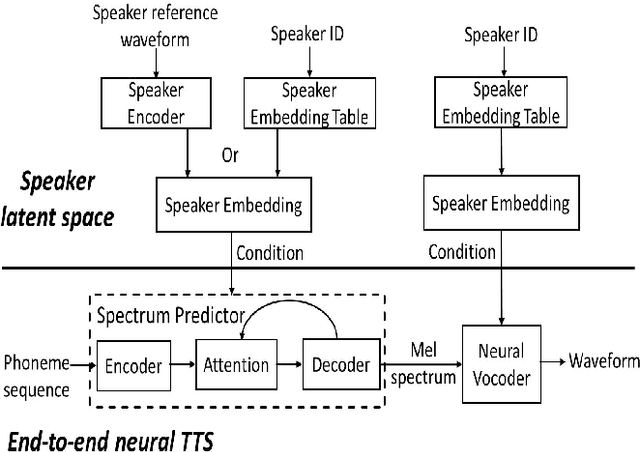

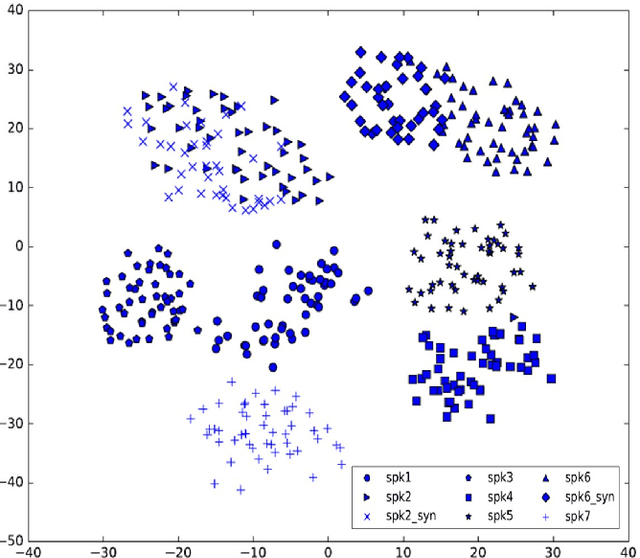

Neural TTS has shown it can generate high quality synthesized speech. In this paper, we investigate the multi-speaker latent space to improve neural TTS for adapting the system to new speakers with only several minutes of speech or enhancing a premium voice by utilizing the data from other speakers for richer contextual coverage and better generalization. A multi-speaker neural TTS model is built with the embedded speaker information in both spectral and speaker latent space. The experimental results show that, with less than 5 minutes of training data from a new speaker, the new model can achieve an MOS score of 4.16 in naturalness and 4.64 in speaker similarity close to human recordings (4.74). For a well-trained premium voice, we can achieve an MOS score of 4.5 for out-of-domain texts, which is comparable to an MOS of 4.58 for professional recordings, and significantly outperforms single speaker result of 4.28.