 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
Apr 20, 2026Chain-of-Thought (CoT) reasoning has become a powerful driver of trajectory prediction in VLA-based autonomous driving, yet its autoregressive nature imposes a latency cost that is prohibitive for real-time deployment. Latent CoT methods attempt to close this gap by compressing reasoning into continuous hidden states, but consistently fall short of their explicit counterparts. We suggest that this is due to purely linguistic latent representations compressing a symbolic abstraction of the world, rather than the causal dynamics that actually govern driving. Thus, we present OneVL (One-step latent reasoning and planning with Vision-Language explanations), a unified VLA and World Model framework that routes reasoning through compact latent tokens supervised by dual auxiliary decoders. Alongside a language decoder that reconstructs text CoT, we introduce a visual world model decoder that predicts future-frame tokens, forcing the latent space to internalize the causal dynamics of road geometry, agent motion, and environmental change. A three-stage training pipeline progressively aligns these latents with trajectory, language, and visual objectives, ensuring stable joint optimization. At inference, the auxiliary decoders are discarded and all latent tokens are prefilled in a single parallel pass, matching the speed of answer-only prediction. Across four benchmarks, OneVL becomes the first latent CoT method to surpass explicit CoT, delivering state-of-the-art accuracy at answer-only latency, and providing direct evidence that tighter compression, when guided in both language and world-model supervision, produces more generalizable representations than verbose token-by-token reasoning. Project Page: https://xiaomi-embodied-intelligence.github.io/OneVL
CREval: An Automated Interpretable Evaluation for Creative Image Manipulation under Complex Instructions
Mar 27, 2026Instruction-based multimodal image manipulation has recently made rapid progress. However, existing evaluation methods lack a systematic and human-aligned framework for assessing model performance on complex and creative editing tasks. To address this gap, we propose CREval, a fully automated question-answer (QA)-based evaluation pipeline that overcomes the incompleteness and poor interpretability of opaque Multimodal Large Language Models (MLLMs) scoring. Simultaneously, we introduce CREval-Bench, a comprehensive benchmark specifically designed for creative image manipulation under complex instructions. CREval-Bench covers three categories and nine creative dimensions, comprising over 800 editing samples and 13K evaluation queries. Leveraging this pipeline and benchmark, we systematically evaluate a diverse set of state-of-the-art open and closed-source models. The results reveal that while closed-source models generally outperform open-source ones on complex and creative tasks, all models still struggle to complete such edits effectively. In addition, user studies demonstrate strong consistency between CREval's automated metrics and human judgments. Therefore, CREval provides a reliable foundation for evaluating image editing models on complex and creative image manipulation tasks, and highlights key challenges and opportunities for future research.
Chain of Mindset: Reasoning with Adaptive Cognitive Modes
Feb 10, 2026Human problem-solving is never the repetition of a single mindset, by which we mean a distinct mode of cognitive processing. When tackling a specific task, we do not rely on a single mindset; instead, we integrate multiple mindsets within the single solution process. However, existing LLM reasoning methods fall into a common trap: they apply the same fixed mindset across all steps, overlooking that different stages of solving the same problem require fundamentally different mindsets. This single-minded assumption prevents models from reaching the next level of intelligence. To address this limitation, we propose Chain of Mindset (CoM), a training-free agentic framework that enables step-level adaptive mindset orchestration. CoM decomposes reasoning into four functionally heterogeneous mindsets: Spatial, Convergent, Divergent, and Algorithmic. A Meta-Agent dynamically selects the optimal mindset based on the evolving reasoning state, while a bidirectional Context Gate filters cross-module information flow to maintain effectiveness and efficiency. Experiments across six challenging benchmarks spanning mathematics, code generation, scientific QA, and spatial reasoning demonstrate that CoM achieves state-of-the-art performance, outperforming the strongest baseline by 4.96\% and 4.72\% in overall accuracy on Qwen3-VL-32B-Instruct and Gemini-2.0-Flash, while balancing reasoning efficiency. Our code is publicly available at \href{https://github.com/QuantaAlpha/chain-of-mindset}{https://github.com/QuantaAlpha/chain-of-mindset}.
QuantaAlpha: An Evolutionary Framework for LLM-Driven Alpha Mining
Feb 06, 2026Financial markets are noisy and non-stationary, making alpha mining highly sensitive to noise in backtesting results and sudden market regime shifts. While recent agentic frameworks improve alpha mining automation, they often lack controllable multi-round search and reliable reuse of validated experience. To address these challenges, we propose QuantaAlpha, an evolutionary alpha mining framework that treats each end-to-end mining run as a trajectory and improves factors through trajectory-level mutation and crossover operations. QuantaAlpha localizes suboptimal steps in each trajectory for targeted revision and recombines complementary high-reward segments to reuse effective patterns, enabling structured exploration and refinement across mining iterations. During factor generation, QuantaAlpha enforces semantic consistency across the hypothesis, factor expression, and executable code, while constraining the complexity and redundancy of the generated factor to mitigate crowding. Extensive experiments on the China Securities Index 300 (CSI 300) demonstrate consistent gains over strong baseline models and prior agentic systems. When utilizing GPT-5.2, QuantaAlpha achieves an Information Coefficient (IC) of 0.1501, with an Annualized Rate of Return (ARR) of 27.75% and a Maximum Drawdown (MDD) of 7.98%. Moreover, factors mined on CSI 300 transfer effectively to the China Securities Index 500 (CSI 500) and the Standard & Poor's 500 Index (S&P 500), delivering 160% and 137% cumulative excess return over four years, respectively, which indicates strong robustness of QuantaAlpha under market distribution shifts.
Explore Briefly, Then Decide: Mitigating LLM Overthinking via Cumulative Entropy Regulation
Oct 02, 2025



Large Language Models (LLMs) have demonstrated remarkable reasoning abilities on complex problems using long Chain-of-Thought (CoT) reasoning. However, they often suffer from overthinking, meaning generating unnecessarily lengthy reasoning steps for simpler problems. This issue may degrade the efficiency of the models and make them difficult to adapt the reasoning depth to the complexity of problems. To address this, we introduce a novel metric Token Entropy Cumulative Average (TECA), which measures the extent of exploration throughout the reasoning process. We further propose a novel reasoning paradigm -- Explore Briefly, Then Decide -- with an associated Cumulative Entropy Regulation (CER) mechanism. This paradigm leverages TECA to help the model dynamically determine the optimal point to conclude its thought process and provide a final answer, thus achieving efficient reasoning. Experimental results across diverse mathematical benchmarks show that our approach substantially mitigates overthinking without sacrificing problem-solving ability. With our thinking paradigm, the average response length decreases by up to 71% on simpler datasets, demonstrating the effectiveness of our method in creating a more efficient and adaptive reasoning process.
Adaptive Substructure-Aware Expert Model for Molecular Property Prediction
Apr 08, 2025Molecular property prediction is essential for applications such as drug discovery and toxicity assessment. While Graph Neural Networks (GNNs) have shown promising results by modeling molecules as molecular graphs, their reliance on data-driven learning limits their ability to generalize, particularly in the presence of data imbalance and diverse molecular substructures. Existing methods often overlook the varying contributions of different substructures to molecular properties, treating them uniformly. To address these challenges, we propose ASE-Mol, a novel GNN-based framework that leverages a Mixture-of-Experts (MoE) approach for molecular property prediction. ASE-Mol incorporates BRICS decomposition and significant substructure awareness to dynamically identify positive and negative substructures. By integrating a MoE architecture, it reduces the adverse impact of negative motifs while improving adaptability to positive motifs. Experimental results on eight benchmark datasets demonstrate that ASE-Mol achieves state-of-the-art performance, with significant improvements in both accuracy and interpretability.
Knowledge-enhanced Relation Graph and Task Sampling for Few-shot Molecular Property Prediction
May 24, 2024



Recently, few-shot molecular property prediction (FSMPP) has garnered increasing attention. Despite impressive breakthroughs achieved by existing methods, they often overlook the inherent many-to-many relationships between molecules and properties, which limits their performance. For instance, similar substructures of molecules can inspire the exploration of new compounds. Additionally, the relationships between properties can be quantified, with high-related properties providing more information in exploring the target property than those low-related. To this end, this paper proposes a novel meta-learning FSMPP framework (KRGTS), which comprises the Knowledge-enhanced Relation Graph module and the Task Sampling module. The knowledge-enhanced relation graph module constructs the molecule-property multi-relation graph (MPMRG) to capture the many-to-many relationships between molecules and properties. The task sampling module includes a meta-training task sampler and an auxiliary task sampler, responsible for scheduling the meta-training process and sampling high-related auxiliary tasks, respectively, thereby achieving efficient meta-knowledge learning and reducing noise introduction. Empirically, extensive experiments on five datasets demonstrate the superiority of KRGTS over a variety of state-of-the-art methods. The code is available in https://github.com/Vencent-Won/KRGTS-public.
Multi-Modal Representation Learning for Molecular Property Prediction: Sequence, Graph, Geometry
Jan 09, 2024Molecular property prediction refers to the task of labeling molecules with some biochemical properties, playing a pivotal role in the drug discovery and design process. Recently, with the advancement of machine learning, deep learning-based molecular property prediction has emerged as a solution to the resource-intensive nature of traditional methods, garnering significant attention. Among them, molecular representation learning is the key factor for molecular property prediction performance. And there are lots of sequence-based, graph-based, and geometry-based methods that have been proposed. However, the majority of existing studies focus solely on one modality for learning molecular representations, failing to comprehensively capture molecular characteristics and information. In this paper, a novel multi-modal representation learning model, which integrates the sequence, graph, and geometry characteristics, is proposed for molecular property prediction, called SGGRL. Specifically, we design a fusion layer to fusion the representation of different modalities. Furthermore, to ensure consistency across modalities, SGGRL is trained to maximize the similarity of representations for the same molecule while minimizing similarity for different molecules. To verify the effectiveness of SGGRL, seven molecular datasets, and several baselines are used for evaluation and comparison. The experimental results demonstrate that SGGRL consistently outperforms the baselines in most cases. This further underscores the capability of SGGRL to comprehensively capture molecular information. Overall, the proposed SGGRL model showcases its potential to revolutionize molecular property prediction by leveraging multi-modal representation learning to extract diverse and comprehensive molecular insights. Our code is released at https://github.com/Vencent-Won/SGGRL.
Development of a Swarm UAV Simulator Integrating Realistic Motion Control Models For Disaster Operations
Nov 01, 2017

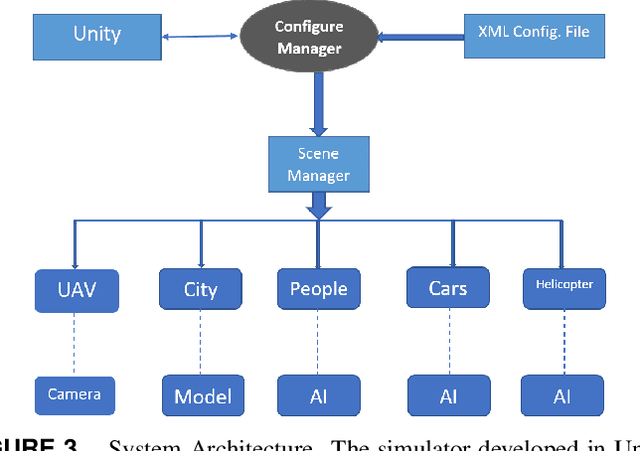
Simulation environments for Unmanned Aerial Vehicles (UAVs) can be very useful for prototyping user interfaces and training personnel that will operate UAVs in the real world. The realistic operation of such simulations will only enhance the value of such training. In this paper, we present the integration of a model-based waypoint navigation controller into the Reno Rescue Simulator for the purposes of providing a more realistic user interface in simulated environments. We also present potential uses for such simulations, even for real-world operation of UAVs.