 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDA: Evolving and Distinct Anchors for Multimodal Motion Prediction
Dec 15, 2023



Motion prediction is a crucial task in autonomous driving, and one of its major challenges lands in the multimodality of future behaviors. Many successful works have utilized mixture models which require identification of positive mixture components, and correspondingly fall into two main lines: prediction-based and anchor-based matching. The prediction clustering phenomenon in prediction-based matching makes it difficult to pick representative trajectories for downstream tasks, while the anchor-based matching suffers from a limited regression capability. In this paper, we introduce a novel paradigm, named Evolving and Distinct Anchors (EDA), to define the positive and negative components for multimodal motion prediction based on mixture models. We enable anchors to evolve and redistribute themselves under specific scenes for an enlarged regression capacity. Furthermore, we select distinct anchors before matching them with the ground truth, which results in impressive scoring performance. Our approach enhances all metrics compared to the baseline MTR, particularly with a notable relative reduction of 13.5% in Miss Rate, resulting in state-of-the-art performance on the Waymo Open Motion Dataset. Code is available at https://github.com/Longzhong-Lin/EDA.
Sparse4D v3: Advancing End-to-End 3D Detection and Tracking
Nov 20, 2023



In autonomous driving perception systems, 3D detection and tracking are the two fundamental tasks. This paper delves deeper into this field, building upon the Sparse4D framework. We introduce two auxiliary training tasks (Temporal Instance Denoising and Quality Estimation) and propose decoupled attention to make structural improvements, leading to significant enhancements in detection performance. Additionally, we extend the detector into a tracker using a straightforward approach that assigns instance ID during inference, further highlighting the advantages of query-based algorithms. Extensive experiments conducted on the nuScenes benchmark validate the effectiveness of the proposed improvements. With ResNet50 as the backbone, we witnessed enhancements of 3.0\%, 2.2\%, and 7.6\% in mAP, NDS, and AMOTA, achieving 46.9\%, 56.1\%, and 49.0\%, respectively. Our best model achieved 71.9\% NDS and 67.7\% AMOTA on the nuScenes test set. Code will be released at \url{https://github.com/linxuewu/Sparse4D}.
DynStatF: An Efficient Feature Fusion Strategy for LiDAR 3D Object Detection
May 24, 2023



Augmenting LiDAR input with multiple previous frames provides richer semantic information and thus boosts performance in 3D object detection, However, crowded point clouds in multi-frames can hurt the precise position information due to the motion blur and inaccurate point projection. In this work, we propose a novel feature fusion strategy, DynStaF (Dynamic-Static Fusion), which enhances the rich semantic information provided by the multi-frame (dynamic branch) with the accurate location information from the current single-frame (static branch). To effectively extract and aggregate complimentary features, DynStaF contains two modules, Neighborhood Cross Attention (NCA) and Dynamic-Static Interaction (DSI), operating through a dual pathway architecture. NCA takes the features in the static branch as queries and the features in the dynamic branch as keys (values). When computing the attention, we address the sparsity of point clouds and take only neighborhood positions into consideration. NCA fuses two features at different feature map scales, followed by DSI providing the comprehensive interaction. To analyze our proposed strategy DynStaF, we conduct extensive experiments on the nuScenes dataset. On the test set, DynStaF increases the performance of PointPillars in NDS by a large margin from 57.7% to 61.6%. When combined with CenterPoint, our framework achieves 61.0% mAP and 67.7% NDS, leading to state-of-the-art performance without bells and whistles.
Sparse4D v2: Recurrent Temporal Fusion with Sparse Model
May 24, 2023



Sparse algorithms offer great flexibility for multi-view temporal perception tasks. In this paper, we present an enhanced version of Sparse4D, in which we improve the temporal fusion module by implementing a recursive form of multi-frame feature sampling. By effectively decoupling image features and structured anchor features, Sparse4D enables a highly efficient transformation of temporal features, thereby facilitating temporal fusion solely through the frame-by-frame transmission of sparse features. The recurrent temporal fusion approach provides two main benefits. Firstly, it reduces the computational complexity of temporal fusion from $O(T)$ to $O(1)$, resulting in significant improvements in inference speed and memory usage. Secondly, it enables the fusion of long-term information, leading to more pronounced performance improvements due to temporal fusion. Our proposed approach, Sparse4Dv2, further enhances the performance of the sparse perception algorithm and achieves state-of-the-art results on the nuScenes 3D detection benchmark. Code will be available at \url{https://github.com/linxuewu/Sparse4D}.
Master: Meta Style Transformer for Controllable Zero-Shot and Few-Shot Artistic Style Transfer
Apr 24, 2023



Transformer-based models achieve favorable performance in artistic style transfer recently thanks to its global receptive field and powerful multi-head/layer attention operations. Nevertheless, the over-paramerized multi-layer structure increases parameters significantly and thus presents a heavy burden for training. Moreover, for the task of style transfer, vanilla Transformer that fuses content and style features by residual connections is prone to content-wise distortion. In this paper, we devise a novel Transformer model termed as \emph{Master} specifically for style transfer. On the one hand, in the proposed model, different Transformer layers share a common group of parameters, which (1) reduces the total number of parameters, (2) leads to more robust training convergence, and (3) is readily to control the degree of stylization via tuning the number of stacked layers freely during inference. On the other hand, different from the vanilla version, we adopt a learnable scaling operation on content features before content-style feature interaction, which better preserves the original similarity between a pair of content features while ensuring the stylization quality. We also propose a novel meta learning scheme for the proposed model so that it can not only work in the typical setting of arbitrary style transfer, but also adaptable to the few-shot setting, by only fine-tuning the Transformer encoder layer in the few-shot stage for one specific style. Text-guided few-shot style transfer is firstly achieved with the proposed framework. Extensive experiments demonstrate the superiority of Master under both zero-shot and few-shot style transfer settings.
DeltaEdit: Exploring Text-free Training for Text-Driven Image Manipulation
Mar 11, 2023



Text-driven image manipulation remains challenging in training or inference flexibility. Conditional generative models depend heavily on expensive annotated training data. Meanwhile, recent frameworks, which leverage pre-trained vision-language models, are limited by either per text-prompt optimization or inference-time hyper-parameters tuning. In this work, we propose a novel framework named \textit{DeltaEdit} to address these problems. Our key idea is to investigate and identify a space, namely delta image and text space that has well-aligned distribution between CLIP visual feature differences of two images and CLIP textual embedding differences of source and target texts. Based on the CLIP delta space, the DeltaEdit network is designed to map the CLIP visual features differences to the editing directions of StyleGAN at training phase. Then, in inference phase, DeltaEdit predicts the StyleGAN's editing directions from the differences of the CLIP textual features. In this way, DeltaEdit is trained in a text-free manner. Once trained, it can well generalize to various text prompts for zero-shot inference without bells and whistles. Code is available at https://github.com/Yueming6568/DeltaEdit.
Goal-oriented Autonomous Driving
Dec 20, 2022



Modern autonomous driving system is characterized as modular tasks in sequential order, i.e., perception, prediction and planning. As sensors and hardware get improved, there is trending popularity to devise a system that can perform a wide diversity of tasks to fulfill higher-level intelligence. Contemporary approaches resort to either deploying standalone models for individual tasks, or designing a multi-task paradigm with separate heads. These might suffer from accumulative error or negative transfer effect. Instead, we argue that a favorable algorithm framework should be devised and optimized in pursuit of the ultimate goal, i.e. planning of the self-driving-car. Oriented at this goal, we revisit the key components within perception and prediction. We analyze each module and prioritize the tasks hierarchically, such that all these tasks contribute to planning (the goal). To this end, we introduce Unified Autonomous Driving (UniAD), the first comprehensive framework up-to-date that incorporates full-stack driving tasks in one network. It is exquisitely devised to leverage advantages of each module, and provide complementary feature abstractions for agent interaction from a global perspective. Tasks are communicated with unified query design to facilitate each other toward planning. We instantiate UniAD on the challenging nuScenes benchmark. With extensive ablations, the effectiveness of using such a philosophy is proven to surpass previous state-of-the-arts by a large margin in all aspects. The full suite of codebase and models would be available to facilitate future research in the community.
AdaCM: Adaptive ColorMLP for Real-Time Universal Photo-realistic Style Transfer
Dec 03, 2022Photo-realistic style transfer aims at migrating the artistic style from an exemplar style image to a content image, producing a result image without spatial distortions or unrealistic artifacts. Impressive results have been achieved by recent deep models. However, deep neural network based methods are too expensive to run in real-time. Meanwhile, bilateral grid based methods are much faster but still contain artifacts like overexposure. In this work, we propose the \textbf{Adaptive ColorMLP (AdaCM)}, an effective and efficient framework for universal photo-realistic style transfer. First, we find the complex non-linear color mapping between input and target domain can be efficiently modeled by a small multi-layer perceptron (ColorMLP) model. Then, in \textbf{AdaCM}, we adopt a CNN encoder to adaptively predict all parameters for the ColorMLP conditioned on each input content and style image pair. Experimental results demonstrate that AdaCM can generate vivid and high-quality stylization results. Meanwhile, our AdaCM is ultrafast and can process a 4K resolution image in 6ms on one V100 GPU.
Sparse4D: Multi-view 3D Object Detection with Sparse Spatial-Temporal Fusion
Nov 19, 2022



Bird-eye-view (BEV) based methods have made great progress recently in multi-view 3D detection task. Comparing with BEV based methods, sparse based methods lag behind in performance, but still have lots of non-negligible merits. To push sparse 3D detection further, in this work, we introduce a novel method, named Sparse4D, which does the iterative refinement of anchor boxes via sparsely sampling and fusing spatial-temporal features. (1) Sparse 4D Sampling: for each 3D anchor, we assign multiple 4D keypoints, which are then projected to multi-view/scale/timestamp image features to sample corresponding features; (2) Hierarchy Feature Fusion: we hierarchically fuse sampled features of different view/scale, different timestamp and different keypoints to generate high-quality instance feature. In this way, Sparse4D can efficiently and effectively achieve 3D detection without relying on dense view transformation nor global attention, and is more friendly to edge devices deployment. Furthermore, we introduce an instance-level depth reweight module to alleviate the ill-posed issue in 3D-to-2D projection. In experiment, our method outperforms all sparse based methods and most BEV based methods on detection task in the nuScenes dataset.
Towards Bidirectional Arbitrary Image Rescaling: Joint Optimization and Cycle Idempotence
Mar 08, 2022
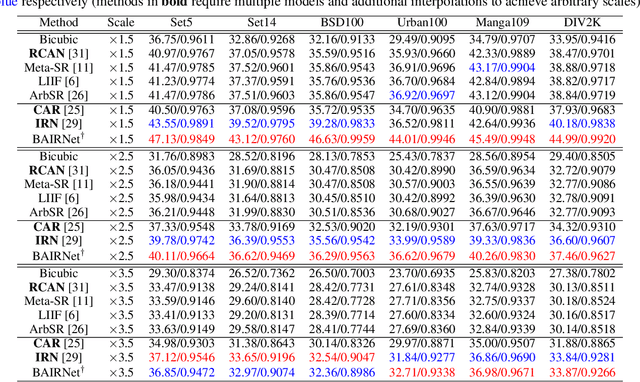
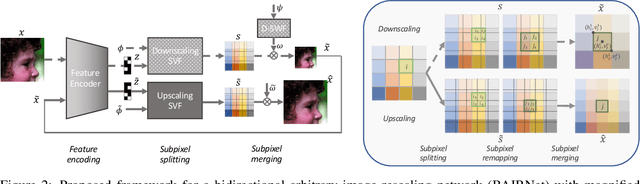

Deep learning based single image super-resolution models have been widely studied and superb results are achieved in upscaling low-resolution images with fixed scale factor and downscaling degradation kernel. To improve real world applicability of such models, there are growing interests to develop models optimized for arbitrary upscaling factors. Our proposed method is the first to treat arbitrary rescaling, both upscaling and downscaling, as one unified process. Using joint optimization of both directions, the proposed model is able to learn upscaling and downscaling simultaneously and achieve bidirectional arbitrary image rescaling. It improves the performance of current arbitrary upscaling models by a large margin while at the same time learns to maintain visual perception quality in downscaled images. The proposed model is further shown to be robust in cycle idempotence test, free of severe degradations in reconstruction accuracy when the downscaling-to-upscaling cycle is applied repetitively. This robustness is beneficial for image rescaling in the wild when this cycle could be applied to one image for multiple times. It also performs well on tests with arbitrary large scales and asymmetric scales, even when the model is not trained with such tasks. Extensive experiments are conducted to demonstrate the superior performance of our model.