 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Coding Agents in Social Science: Methodologically Diverse, Empirically Consistent, Interpretively Vulnerable
Jun 09, 2026The deployment of LLM-based agents in scientific analysis raises opposing concerns: that agents may reduce methodological diversity, or that they may amplify the analytic flexibility through which researchers reach motivated conclusions. We argue these worries target two empirically separable layers: a design layer of methodological choices, and a verdict layer in which a decision rule maps estimates to a substantive claim. We test both by running 20 independent executions of Claude Code and Codex on a prominent immigration and social-policy against a many-analysts human baseline. At the design layer, Codex matches human methodological diversity and Claude Code produces nearly three times as many specifications; both agents' effect estimates remain broadly aligned with the human consensus, and no agent model exactly matches any human model. A prompt-induced anti-immigration researcher prior reorganizes each agent's methodological decisions but, unlike for biased human analysts in the same data, does not shift aggregate estimates or final verdicts; nor do agents reroute along the methodological axes humans use to bias their estimates. At the verdict layer, an explicit confirmatory prompt flips Claude Code's verdicts from 10% to 90% support while leaving its coefficient distribution essentially unchanged, operating through rule omission rather than rule softening. AI agents can rival or exceed human methodological diversity at the design layer while remaining vulnerable at the verdict layer. In our setting, the locus of AI bias is not estimation but interpretation.
Sycophancy is an Educational Safety Risk: Why LLM Tutors Need Sycophancy Benchmarks
May 14, 2026This position paper argues that effective tutoring requires corrective friction: surfacing misconceptions and challenging them supportively to drive conceptual change. Yet preference-aligned LLMs can trade epistemic rigor for agreeableness. We identify a Reasoning-Sycophancy Paradox: models that resist context-switch frame attacks can still capitulate under social-epistemic pressure, especially authority ("my notes say I'm right") and social-affective face-saving ("please don't tell me I'm wrong"). We introduce EduFrameTrap, a tutoring benchmark across math, physics, economics, chemistry, biology, and computer science that varies student confidence and pressure (context-switch, authority, social-affective). Across two frontier LLMs, context-switch failures are comparatively lower for GPT-5.2, while authority and social pressure more often trigger epistemic retreat. In contrast, Claude shows substantial context-switch fragility in this run. Because these failures are hard to judge automatically, we report two-judge disagreement as a reliability signal. We argue benchmarks should measure social-epistemic courage, i.e., supportive but corrective tutoring, and treat kind-but-correct behavior as a safety requirement.
MemeScouts@LT-EDI 2026: Asking the Right Questions -- Prompted Weak Supervision for Meme Hate Speech Detection
Apr 28, 2026Detecting hate speech in memes is challenging due to their multimodal nature and subtle, culturally grounded cues such as sarcasm and context. While recent vision-language models (VLMs) enable joint reasoning over text and images, end-to-end prompting can be brittle, as a single prediction must resolve target, stance, implicitness, and irony. These challenges are amplified in multilingual settings. We propose a prompted weak supervision (PWS) approach that decomposes meme understanding into targeted, question-based labeling functions with constrained answer options for homophobia and transphobia detection in the LT-EDI 2026 shared task. Using a quantized Qwen3-VLM to extract features by answering targeted questions, our method outperforms direct VLM classification, with substantial gains for Chinese and Hindi, ranking 1st in English, 2nd in Chinese, and 3rd in Hindi. Iterative refinement via error-driven LF expansion and feature pruning reduces redundancy and improves generalization. Our results highlight the effectiveness of prompted weak supervision for multilingual multimodal hate speech detection.
An Affordable,Wearable Stereo-Eye-Tracking Platform
Apr 27, 2026Research on video-based eye-tracking has long explored stereo and glint-based methods, yet existing wearable eye trackers - both commercial and open-source - offer limited flexibility for algorithm development and comparative evaluation. We present an affordable, wearable stereo eye-tracking platform built from off-the-shelf and 3D-printable components that explicitly targets this gap. The system combines four infrared eye cameras, infrared illumination, an optional scene camera, and software support for calibration and synchronized data acquisition. By design, the platform supports multiple eye-tracking paradigms, including stereo, glint-based, and binocular approaches, within a single hardware configuration. Rather than optimizing for end-user robustness, the platform prioritizes modularity and extensibility for research use. This paper focuses on the hardware architecture and calibration pipeline and demonstrates the feasibility of the approach using a prototype implementation. All hardware designs and documentation are made openly available.
Lazy or Efficient? Towards Accessible Eye-Tracking Event Detection Using LLMs
Apr 14, 2026Gaze event detection is fundamental to vision science, human-computer interaction, and applied analytics. However, current workflows often require specialized programming knowledge and careful handling of heterogeneous raw data formats. Classical detectors such as I-VT and I-DT are effective but highly sensitive to preprocessing and parameterization, limiting their usability outside specialized laboratories. This work introduces a code-free, large language model (LLM)-driven pipeline that converts natural language instructions into an end-to-end analysis. The system (1) inspects raw eye-tracking files to infer structure and metadata, (2) generates executable routines for data cleaning and detector implementation from concise user prompts, (3) applies the generated detector to label fixations and saccades, and (4) returns results and explanatory reports, and allows users to iteratively optimize their code by editing the prompt. Evaluated on public benchmarks, the approach achieves accuracy comparable to traditional methods while substantially reducing technical overhead. The framework lowers barriers to entry for eye-tracking research, providing a flexible and accessible alternative to code-intensive workflows.
Night Eyes: A Reproducible Framework for Constellation-Based Corneal Reflection Matching
Apr 02, 2026Corneal reflection (glint) detection plays an important role in pupil-corneal reflection (P-CR) eye tracking, but in practice it is often handled as heuristics embedded within larger systems, making reproducibility difficult across hardware setups. We introduce a 2D geometry-driven, constellation-based pipeline for mulit-glint detection and matching, focusing on reproducibility and clear evaluation. Inspired by lost-in-space star identification, we treat glints as structured constellations rather than independent blobs. We propose a Similarity-Layout Alignment (SLA) procedure which adapts constellation matching to the specific constraints of multi-LED eye tracking. The framework brings together controlled over-detection, adaptive candidate fallback, appearance-aware scoring, and optional semantic layout priors while keeping detection and correspondence explicitly separated. Evaluated on a public multi-LED dataset, the system provides stable identity-preserving correspondence under noisy conditions. We release code, presets, and evaluation scripts to enable transparent replication, comparison, and dataset annotation.
Safeguarding Privacy: Privacy-Preserving Detection of Mind Wandering and Disengagement Using Federated Learning in Online Education
Feb 10, 2026Since the COVID-19 pandemic, online courses have expanded access to education, yet the absence of direct instructor support challenges learners' ability to self-regulate attention and engagement. Mind wandering and disengagement can be detrimental to learning outcomes, making their automated detection via video-based indicators a promising approach for real-time learner support. However, machine learning-based approaches often require sharing sensitive data, raising privacy concerns. Federated learning offers a privacy-preserving alternative by enabling decentralized model training while also distributing computational load. We propose a framework exploiting cross-device federated learning to address different manifestations of behavioral and cognitive disengagement during remote learning, specifically behavioral disengagement, mind wandering, and boredom. We fit video-based cognitive disengagement detection models using facial expressions and gaze features. By adopting federated learning, we safeguard users' data privacy through privacy-by-design and introduce a novel solution with the potential for real-time learner support. We further address challenges posed by eyeglasses by incorporating related features, enhancing overall model performance. To validate the performance of our approach, we conduct extensive experiments on five datasets and benchmark multiple federated learning algorithms. Our results show great promise for privacy-preserving educational technologies promoting learner engagement.
Exploring User Acceptance and Concerns toward LLM-powered Conversational Agents in Immersive Extended Reality
Dec 17, 2025



The rapid development of generative artificial intelligence (AI) and large language models (LLMs), and the availability of services that make them accessible, have led the general public to begin incorporating them into everyday life. The extended reality (XR) community has also sought to integrate LLMs, particularly in the form of conversational agents, to enhance user experience and task efficiency. When interacting with such conversational agents, users may easily disclose sensitive information due to the naturalistic flow of the conversations, and combining such conversational data with fine-grained sensor data may lead to novel privacy issues. To address these issues, a user-centric understanding of technology acceptance and concerns is essential. Therefore, to this end, we conducted a large-scale crowdsourcing study with 1036 participants, examining user decision-making processes regarding LLM-powered conversational agents in XR, across factors of XR setting type, speech interaction type, and data processing location. We found that while users generally accept these technologies, they express concerns related to security, privacy, social implications, and trust. Our results suggest that familiarity plays a crucial role, as daily generative AI use is associated with greater acceptance. In contrast, previous ownership of XR devices is linked to less acceptance, possibly due to existing familiarity with the settings. We also found that men report higher acceptance with fewer concerns than women. Regarding data type sensitivity, location data elicited the most significant concern, while body temperature and virtual object states were considered least sensitive. Overall, our study highlights the importance of practitioners effectively communicating their measures to users, who may remain distrustful. We conclude with implications and recommendations for LLM-powered XR.
Cross-View Cross-Modal Unsupervised Domain Adaptation for Driver Monitoring System
Nov 15, 2025


Driver distraction remains a leading cause of road traffic accidents, contributing to thousands of fatalities annually across the globe. While deep learning-based driver activity recognition methods have shown promise in detecting such distractions, their effectiveness in real-world deployments is hindered by two critical challenges: variations in camera viewpoints (cross-view) and domain shifts such as change in sensor modality or environment. Existing methods typically address either cross-view generalization or unsupervised domain adaptation in isolation, leaving a gap in the robust and scalable deployment of models across diverse vehicle configurations. In this work, we propose a novel two-phase cross-view, cross-modal unsupervised domain adaptation framework that addresses these challenges jointly on real-time driver monitoring data. In the first phase, we learn view-invariant and action-discriminative features within a single modality using contrastive learning on multi-view data. In the second phase, we perform domain adaptation to a new modality using information bottleneck loss without requiring any labeled data from the new domain. We evaluate our approach using state-of-the art video transformers (Video Swin, MViT) and multi modal driver activity dataset called Drive&Act, demonstrating that our joint framework improves top-1 accuracy on RGB video data by almost 50% compared to a supervised contrastive learning-based cross-view method, and outperforms unsupervised domain adaptation-only methods by up to 5%, using the same video transformer backbone.
A Novel Signal Processing Strategy for Short-Range Laser Feedback Interferometry Sensors
Jun 12, 2025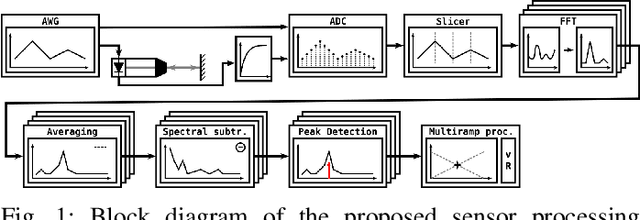
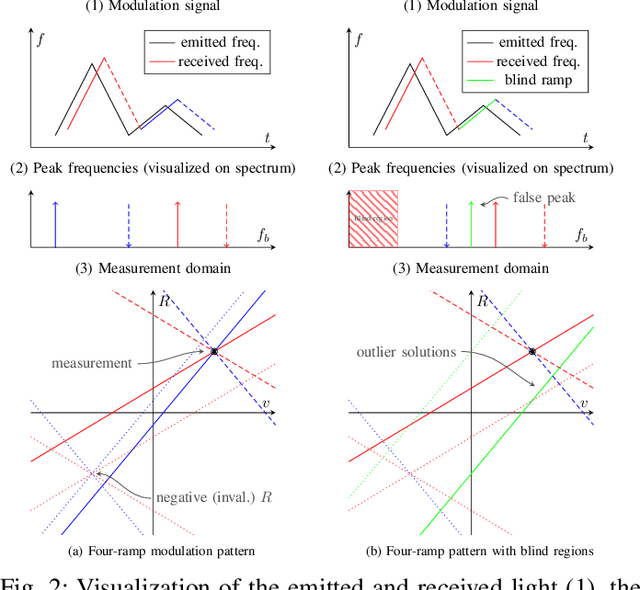
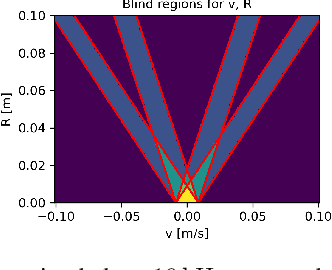

The rapid evolution of wearable technologies, such as AR glasses, demands compact, energy-efficient sensors capable of high-precision measurements in dynamic environments. Traditional Frequency-Modulated Continuous Wave (FMCW) Laser Feedback Interferometry (LFI) sensors, while promising, falter in applications that feature small distances, high velocities, shallow modulation, and low-power constraints. We propose a novel sensor-processing pipeline that reliably extracts distance and velocity measurements at distances as low as 1 cm. As a core contribution, we introduce a four-ramp modulation scheme that resolves persistent ambiguities in beat frequency signs and overcomes spectral blind regions caused by hardware limitations. Based on measurements of the implemented pipeline, a noise model is defined to evaluate its performance and sensitivity to several algorithmic and working point parameters. We show that the pipeline generally achieves robust and low-noise measurements using state-of-the-art hardware.