 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEED: Dynamic Early Exit on Decoder for Accelerating Encoder-Decoder Transformer Models
Nov 15, 2023Encoder-decoder transformer models have achieved great success on various vision-language (VL) tasks, but they suffer from high inference latency. Typically, the decoder takes up most of the latency because of the auto-regressive decoding. To accelerate the inference, we propose an approach of performing Dynamic Early Exit on Decoder (DEED). We build a multi-exit encoder-decoder transformer model which is trained with deep supervision so that each of its decoder layers is capable of generating plausible predictions. In addition, we leverage simple yet practical techniques, including shared generation head and adaptation modules, to keep accuracy when exiting at shallow decoder layers. Based on the multi-exit model, we perform step-level dynamic early exit during inference, where the model may decide to use fewer decoder layers based on its confidence of the current layer at each individual decoding step. Considering different number of decoder layers may be used at different decoding steps, we compute deeper-layer decoder features of previous decoding steps just-in-time, which ensures the features from different decoding steps are semantically aligned. We evaluate our approach with two state-of-the-art encoder-decoder transformer models on various VL tasks. We show our approach can reduce overall inference latency by 30%-60% with comparable or even higher accuracy compared to baselines.
Dehazing-NeRF: Neural Radiance Fields from Hazy Images
Apr 22, 2023



Neural Radiance Field (NeRF) has received much attention in recent years due to the impressively high quality in 3D scene reconstruction and novel view synthesis. However, image degradation caused by the scattering of atmospheric light and object light by particles in the atmosphere can significantly decrease the reconstruction quality when shooting scenes in hazy conditions. To address this issue, we propose Dehazing-NeRF, a method that can recover clear NeRF from hazy image inputs. Our method simulates the physical imaging process of hazy images using an atmospheric scattering model, and jointly learns the atmospheric scattering model and a clean NeRF model for both image dehazing and novel view synthesis. Different from previous approaches, Dehazing-NeRF is an unsupervised method with only hazy images as the input, and also does not rely on hand-designed dehazing priors. By jointly combining the depth estimated from the NeRF 3D scene with the atmospheric scattering model, our proposed model breaks through the ill-posed problem of single-image dehazing while maintaining geometric consistency. Besides, to alleviate the degradation of image quality caused by information loss, soft margin consistency regularization, as well as atmospheric consistency and contrast discriminative loss, are addressed during the model training process. Extensive experiments demonstrate that our method outperforms the simple combination of single-image dehazing and NeRF on both image dehazing and novel view image synthesis.
Differentially Private Adaptive Optimization with Delayed Preconditioners
Dec 01, 2022Privacy noise may negate the benefits of using adaptive optimizers in differentially private model training. Prior works typically address this issue by using auxiliary information (e.g., public data) to boost the effectiveness of adaptive optimization. In this work, we explore techniques to estimate and efficiently adapt to gradient geometry in private adaptive optimization without auxiliary data. Motivated by the observation that adaptive methods can tolerate stale preconditioners, we propose differentially private adaptive training with delayed preconditioners (DP^2), a simple method that constructs delayed but less noisy preconditioners to better realize the benefits of adaptivity. Theoretically, we provide convergence guarantees for our method for both convex and non-convex problems, and analyze trade-offs between delay and privacy noise reduction. Empirically, we explore DP^2 across several real-world datasets, demonstrating that it can improve convergence speed by as much as 4x relative to non-adaptive baselines and match the performance of state-of-the-art optimization methods that require auxiliary data.
Coarse-Super-Resolution-Fine Network (CoSF-Net): A Unified End-to-End Neural Network for 4D-MRI with Simultaneous Motion Estimation and Super-Resolution
Nov 21, 2022



Four-dimensional magnetic resonance imaging (4D-MRI) is an emerging technique for tumor motion management in image-guided radiation therapy (IGRT). However, current 4D-MRI suffers from low spatial resolution and strong motion artifacts owing to the long acquisition time and patients' respiratory variations; these limitations, if not managed properly, can adversely affect treatment planning and delivery in IGRT. Herein, we developed a novel deep learning framework called the coarse-super-resolution-fine network (CoSF-Net) to achieve simultaneous motion estimation and super-resolution in a unified model. We designed CoSF-Net by fully excavating the inherent properties of 4D-MRI, with consideration of limited and imperfectly matched training datasets. We conducted extensive experiments on multiple real patient datasets to verify the feasibility and robustness of the developed network. Compared with existing networks and three state-of-the-art conventional algorithms, CoSF-Net not only accurately estimated the deformable vector fields between the respiratory phases of 4D-MRI but also simultaneously improved the spatial resolution of 4D-MRI with enhanced anatomic features, yielding 4D-MR images with high spatiotemporal resolution.
Domain-Adaptive Text Classification with Structured Knowledge from Unlabeled Data
Jun 20, 2022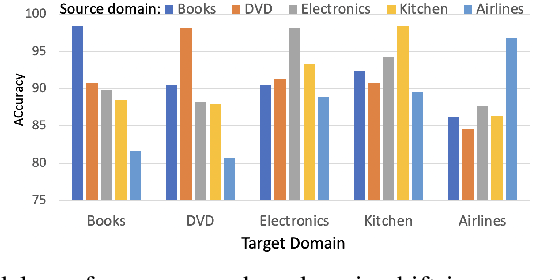
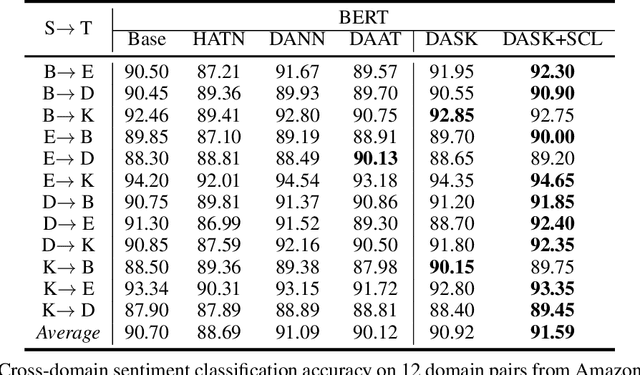
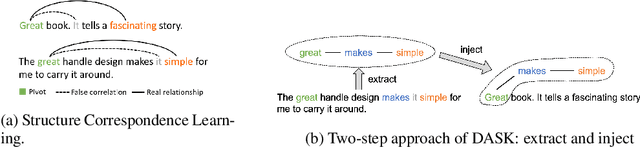
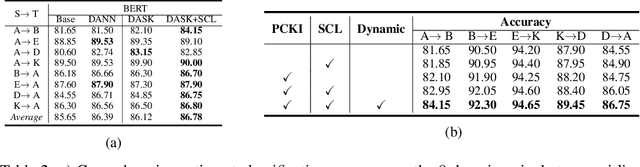
Domain adaptive text classification is a challenging problem for the large-scale pretrained language models because they often require expensive additional labeled data to adapt to new domains. Existing works usually fails to leverage the implicit relationships among words across domains. In this paper, we propose a novel method, called Domain Adaptation with Structured Knowledge (DASK), to enhance domain adaptation by exploiting word-level semantic relationships. DASK first builds a knowledge graph to capture the relationship between pivot terms (domain-independent words) and non-pivot terms in the target domain. Then during training, DASK injects pivot-related knowledge graph information into source domain texts. For the downstream task, these knowledge-injected texts are fed into a BERT variant capable of processing knowledge-injected textual data. Thanks to the knowledge injection, our model learns domain-invariant features for non-pivots according to their relationships with pivots. DASK ensures the pivots to have domain-invariant behaviors by dynamically inferring via the polarity scores of candidate pivots during training with pseudo-labels. We validate DASK on a wide range of cross-domain sentiment classification tasks and observe up to 2.9% absolute performance improvement over baselines for 20 different domain pairs. Code will be made available at https://github.com/hikaru-nara/DASK.
Motley: Benchmarking Heterogeneity and Personalization in Federated Learning
Jun 18, 2022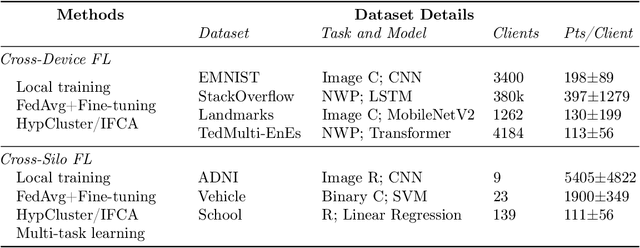

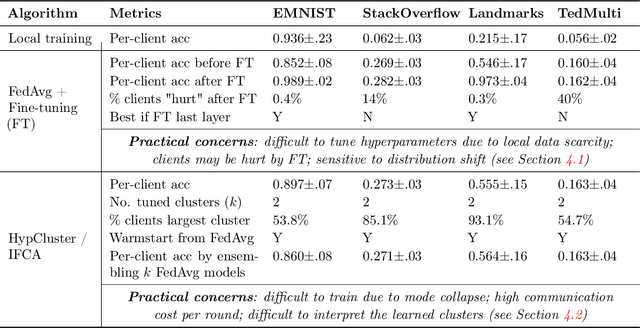
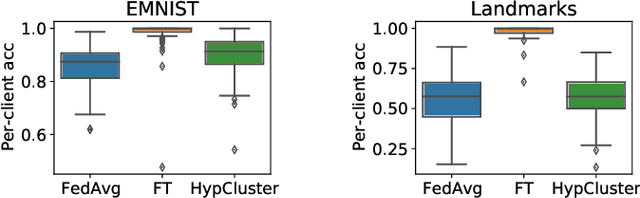
Personalized federated learning considers learning models unique to each client in a heterogeneous network. The resulting client-specific models have been purported to improve metrics such as accuracy, fairness, and robustness in federated networks. However, despite a plethora of work in this area, it remains unclear: (1) which personalization techniques are most effective in various settings, and (2) how important personalization truly is for realistic federated applications. To better answer these questions, we propose Motley, a benchmark for personalized federated learning. Motley consists of a suite of cross-device and cross-silo federated datasets from varied problem domains, as well as thorough evaluation metrics for better understanding the possible impacts of personalization. We establish baselines on the benchmark by comparing a number of representative personalized federated learning methods. These initial results highlight strengths and weaknesses of existing approaches, and raise several open questions for the community. Motley aims to provide a reproducible means with which to advance developments in personalized and heterogeneity-aware federated learning, as well as the related areas of transfer learning, meta-learning, and multi-task learning.
To Federate or Not To Federate: Incentivizing Client Participation in Federated Learning
May 30, 2022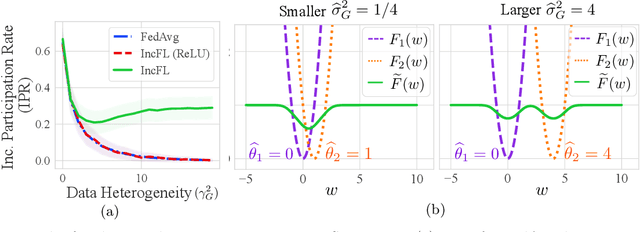
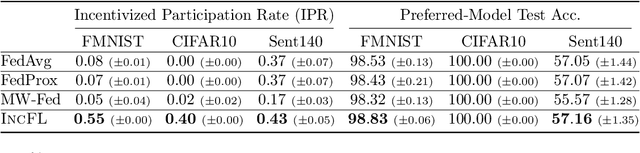
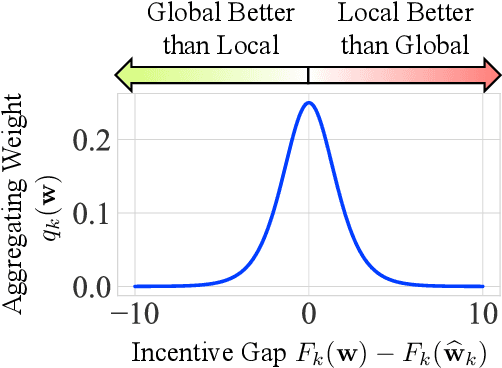
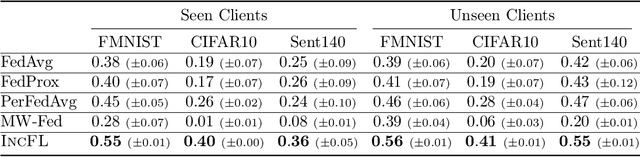
Federated learning (FL) facilitates collaboration between a group of clients who seek to train a common machine learning model without directly sharing their local data. Although there is an abundance of research on improving the speed, efficiency, and accuracy of federated training, most works implicitly assume that all clients are willing to participate in the FL framework. Due to data heterogeneity, however, the global model may not work well for some clients, and they may instead choose to use their own local model. Such disincentivization of clients can be problematic from the server's perspective because having more participating clients yields a better global model, and offers better privacy guarantees to the participating clients. In this paper, we propose an algorithm called IncFL that explicitly maximizes the fraction of clients who are incentivized to use the global model by dynamically adjusting the aggregation weights assigned to their updates. Our experiments show that IncFL increases the number of incentivized clients by 30-55% compared to standard federated training algorithms, and can also improve the generalization performance of the global model on unseen clients.
PreTraM: Self-Supervised Pre-training via Connecting Trajectory and Map
Apr 21, 2022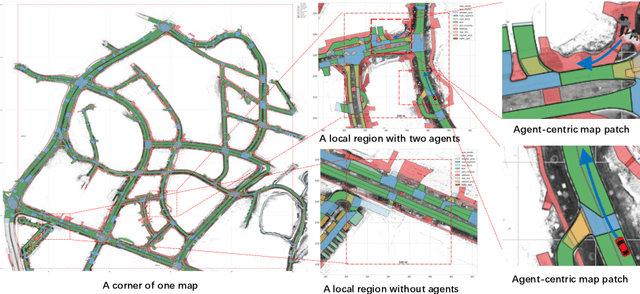
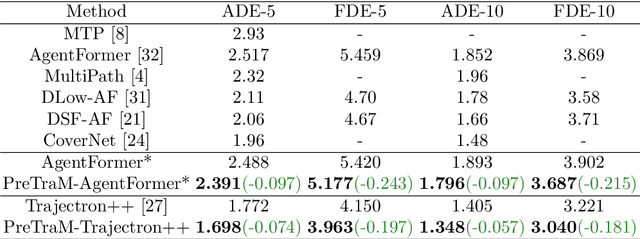
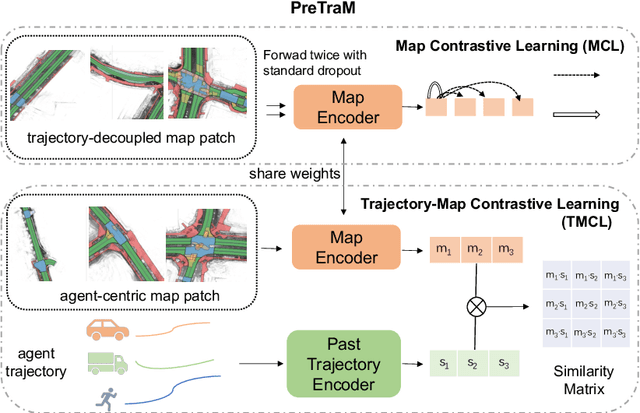

Deep learning has recently achieved significant progress in trajectory forecasting. However, the scarcity of trajectory data inhibits the data-hungry deep-learning models from learning good representations. While mature representation learning methods exist in computer vision and natural language processing, these pre-training methods require large-scale data. It is hard to replicate these approaches in trajectory forecasting due to the lack of adequate trajectory data (e.g., 34K samples in the nuScenes dataset). To work around the scarcity of trajectory data, we resort to another data modality closely related to trajectories-HD-maps, which is abundantly provided in existing datasets. In this paper, we propose PreTraM, a self-supervised pre-training scheme via connecting trajectories and maps for trajectory forecasting. Specifically, PreTraM consists of two parts: 1) Trajectory-Map Contrastive Learning, where we project trajectories and maps to a shared embedding space with cross-modal contrastive learning, and 2) Map Contrastive Learning, where we enhance map representation with contrastive learning on large quantities of HD-maps. On top of popular baselines such as AgentFormer and Trajectron++, PreTraM boosts their performance by 5.5% and 6.9% relatively in FDE-10 on the challenging nuScenes dataset. We show that PreTraM improves data efficiency and scales well with model size.
Private Adaptive Optimization with Side Information
Feb 12, 2022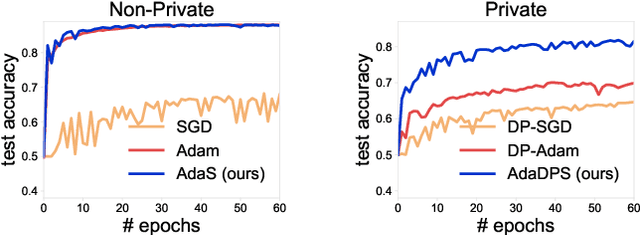

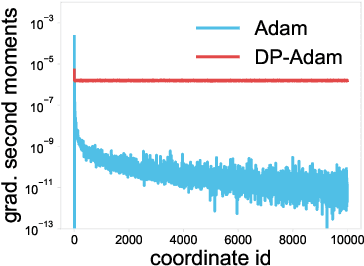
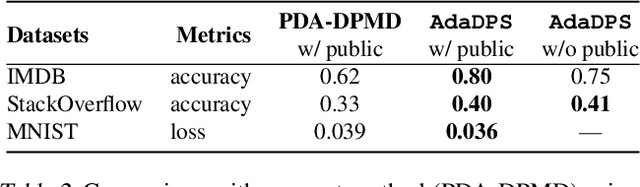
Adaptive optimization methods have become the default solvers for many machine learning tasks. Unfortunately, the benefits of adaptivity may degrade when training with differential privacy, as the noise added to ensure privacy reduces the effectiveness of the adaptive preconditioner. To this end, we propose AdaDPS, a general framework that uses non-sensitive side information to precondition the gradients, allowing the effective use of adaptive methods in private settings. We formally show AdaDPS reduces the amount of noise needed to achieve similar privacy guarantees, thereby improving optimization performance. Empirically, we leverage simple and readily available side information to explore the performance of AdaDPS in practice, comparing to strong baselines in both centralized and federated settings. Our results show that AdaDPS improves accuracy by 7.7% (absolute) on average -- yielding state-of-the-art privacy-utility trade-offs on large-scale text and image benchmarks.
Reinforced Meta-path Selection for Recommendation on Heterogeneous Information Networks
Dec 28, 2021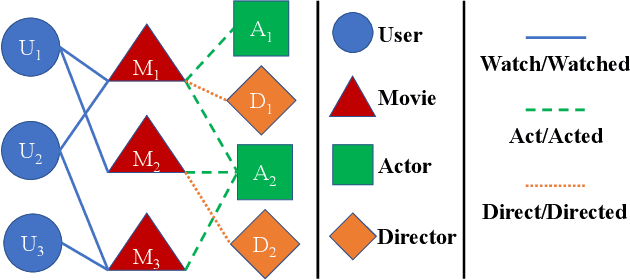
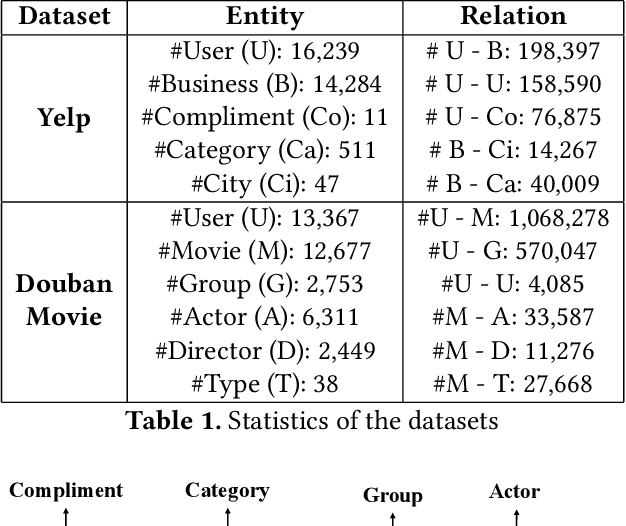
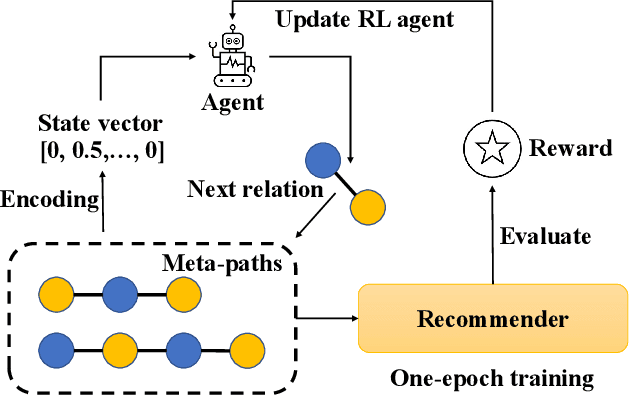
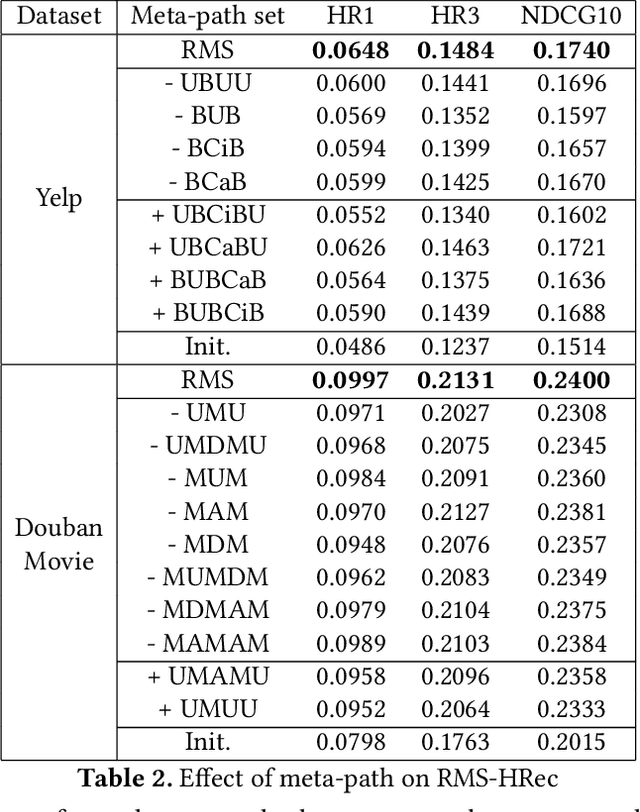
Heterogeneous Information Networks (HINs) capture complex relations among entities of various kinds and have been used extensively to improve the effectiveness of various data mining tasks, such as in recommender systems. Many existing HIN-based recommendation algorithms utilize hand-crafted meta-paths to extract semantic information from the networks. These algorithms rely on extensive domain knowledge with which the best set of meta-paths can be selected. For applications where the HINs are highly complex with numerous node and link types, the approach of hand-crafting a meta-path set is too tedious and error-prone. To tackle this problem, we propose the Reinforcement learning-based Meta-path Selection (RMS) framework to select effective meta-paths and to incorporate them into existing meta-path-based recommenders. To identify high-quality meta-paths, RMS trains a reinforcement learning (RL) based policy network(agent), which gets rewards from the performance on the downstream recommendation tasks. We design a HIN-based recommendation model, HRec, that effectively uses the meta-path information. We further integrate HRec with RMS and derive our recommendation solution, RMS-HRec, that automatically utilizes the effective meta-paths. Experiments on real datasets show that our algorithm can significantly improve the performance of recommendation models by capturing important meta-paths automatically.