 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Scene Parsing with Point-based Distance Metric Learning
Nov 06, 2018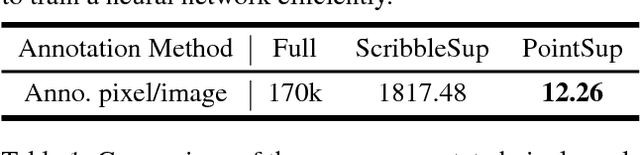

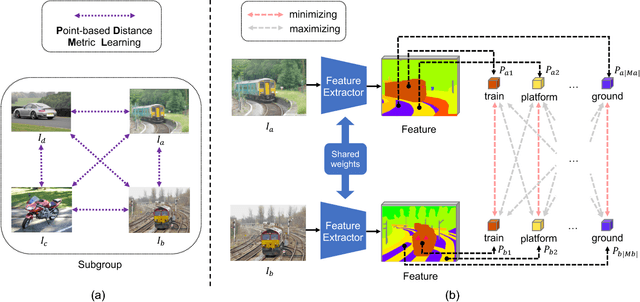
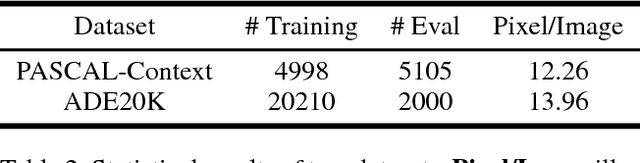
Semantic scene parsing is suffering from the fact that pixel-level annotations are hard to be collected. To tackle this issue, we propose a Point-based Distance Metric Learning (PDML) in this paper. PDML does not require dense annotated masks and only leverages several labeled points that are much easier to obtain to guide the training process. Concretely, we leverage semantic relationship among the annotated points by encouraging the feature representations of the intra- and inter-category points to keep consistent, i.e. points within the same category should have more similar feature representations compared to those from different categories. We formulate such a characteristic into a simple distance metric loss, which collaborates with the point-wise cross-entropy loss to optimize the deep neural networks. Furthermore, to fully exploit the limited annotations, distance metric learning is conducted across different training images instead of simply adopting an image-dependent manner. We conduct extensive experiments on two challenging scene parsing benchmarks of PASCAL-Context and ADE 20K to validate the effectiveness of our PDML, and competitive mIoU scores are achieved.
SG-One: Similarity Guidance Network for One-Shot Semantic Segmentation
Oct 26, 2018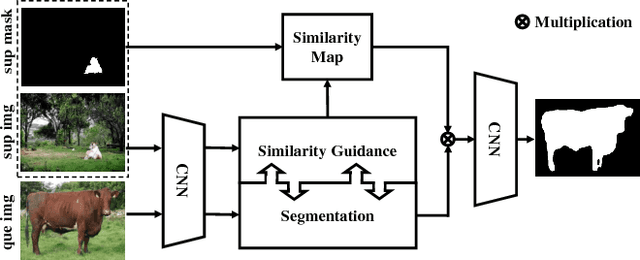

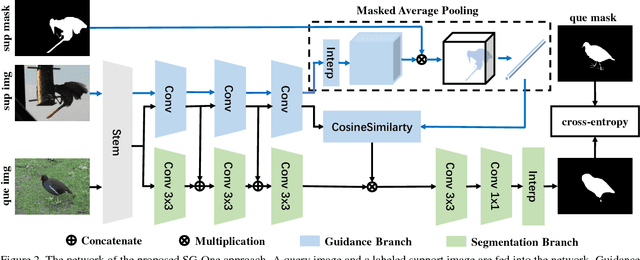
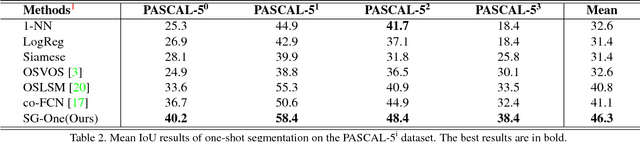
One-shot semantic segmentation poses a challenging task of recognizing the object regions from unseen categories with only one annotated example as supervision. In this paper, we propose a simple yet effective Similarity Guidance network to tackle the One-shot (SG-One) segmentation problem. We aim at predicting the segmentation mask of a query image with the reference to one densely labeled support image. To obtain the robust representative feature of the support image, we firstly propose a masked average pooling strategy for producing the guidance features using only the pixels belonging to the support image. We then leverage the cosine similarity to build the relationship between the guidance features and features of pixels from the query image. In this way, the possibilities embedded in the produced similarity maps can be adopted to guide the process of segmenting objects. Furthermore, our SG-One is a unified framework which can efficiently process both support and query images within one network and be learned in an end-to-end manner. We conduct extensive experiments on Pascal VOC 2012. In particular, our SG-One achieves the mIoU score of 46.3%, which outperforms the state-of-the-art.
Horizontal Pyramid Matching for Person Re-identification
Sep 20, 2018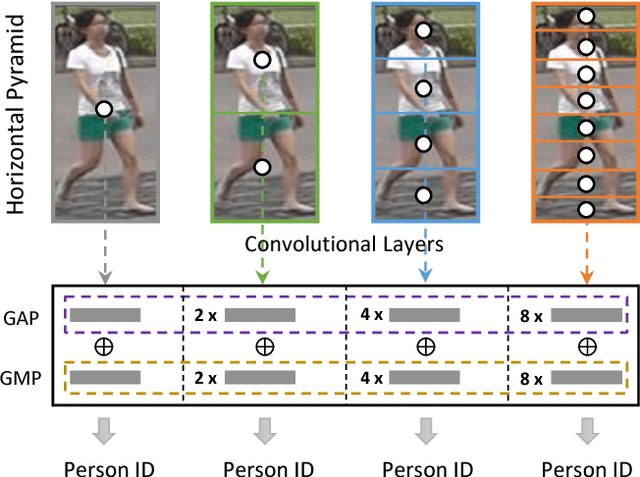
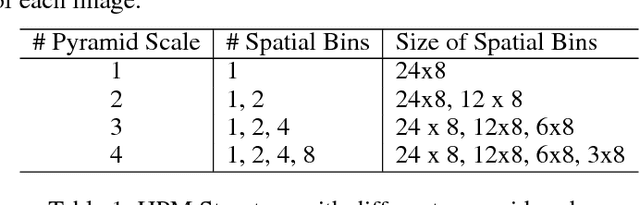

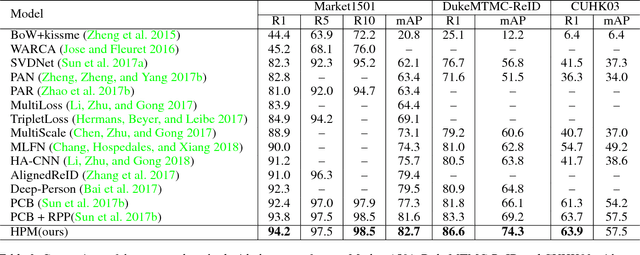
Despite the remarkable recent progress, person Re-identification (Re-ID) approaches are still suffering from the failure cases where the discriminative body parts are missing. To mitigate such cases, we propose a simple yet effective Horizontal Pyramid Matching (HPM) approach to fully exploit various partial information of a given person, so that correct person candidates can be still identified even if some key parts are missing. Within the HPM, we make the following contributions to produce a more robust feature representation for the Re-ID task: 1) we learn to classify using partial feature representations at different horizontal pyramid scales, which successfully enhance the discriminative capabilities of various person parts; 2) we exploit average and max pooling strategies to account for person-specific discriminative information in a global-local manner; 3) we introduce a novel horizontal erasing operation during training to further resist the problem of missing parts and boost the robustness of feature representations. Extensive experiments are conducted on three popular benchmarks including Market-1501, DukeMTMC-reID and CUHK03. We achieve mAP scores of 83.1%, 74.5% and 59.7% on these benchmarks, which are the new state-of-the-arts.
Devil in the Details: Towards Accurate Single and Multiple Human Parsing
Sep 17, 2018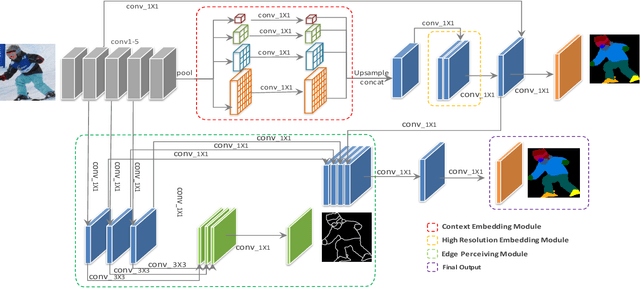
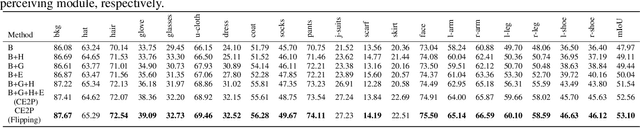
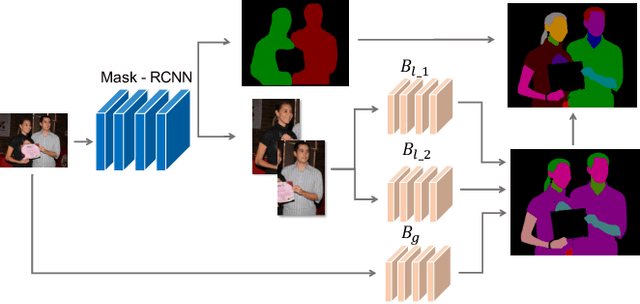
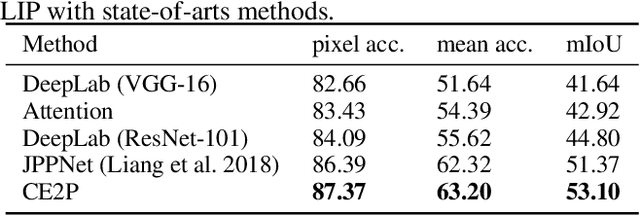
Human parsing has received considerable interest due to its wide application potentials. Nevertheless, it is still unclear how to develop an accurate human parsing system in an efficient and elegant way. In this paper, we identify several useful properties, including feature resolution, global context information and edge details, and perform rigorous analyses to reveal how to leverage them to benefit the human parsing task. The advantages of these useful properties finally result in a simple yet effective Context Embedding with Edge Perceiving (CE2P) framework for single human parsing. Our CE2P is end-to-end trainable and can be easily adopted for conducting multiple human parsing. Benefiting the superiority of CE2P, we achieved the 1st places on all three human parsing benchmarks. Without any bells and whistles, we achieved 56.50\% (mIoU), 45.31\% (mean $AP^r$) and 33.34\% ($AP^p_{0.5}$) in LIP, CIHP and MHP v2.0, which outperform the state-of-the-arts more than 2.06\%, 3.81\% and 1.87\%, respectively. We hope our CE2P will serve as a solid baseline and help ease future research in single/multiple human parsing. Code has been made available at \url{https://github.com/liutinglt/CE2P}.
YouTube-VOS: A Large-Scale Video Object Segmentation Benchmark
Sep 06, 2018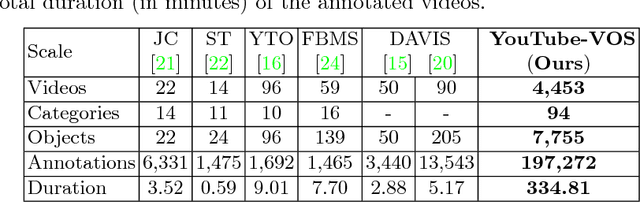

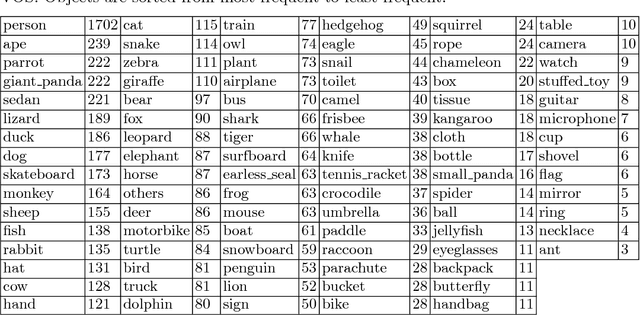
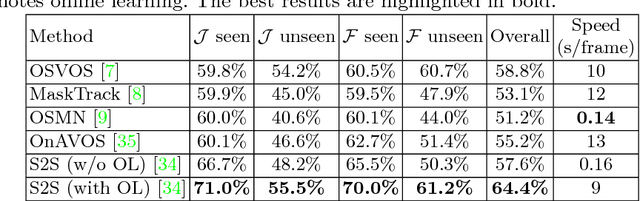
Learning long-term spatial-temporal features are critical for many video analysis tasks. However, existing video segmentation methods predominantly rely on static image segmentation techniques, and methods capturing temporal dependency for segmentation have to depend on pretrained optical flow models, leading to suboptimal solutions for the problem. End-to-end sequential learning to explore spatialtemporal features for video segmentation is largely limited by the scale of available video segmentation datasets, i.e., even the largest video segmentation dataset only contains 90 short video clips. To solve this problem, we build a new large-scale video object segmentation dataset called YouTube Video Object Segmentation dataset (YouTube-VOS). Our dataset contains 4,453 YouTube video clips and 94 object categories. This is by far the largest video object segmentation dataset to our knowledge and has been released at http://youtube-vos.org. We further evaluate several existing state-of-the-art video object segmentation algorithms on this dataset which aims to establish baselines for the development of new algorithms in the future.
YouTube-VOS: Sequence-to-Sequence Video Object Segmentation
Sep 03, 2018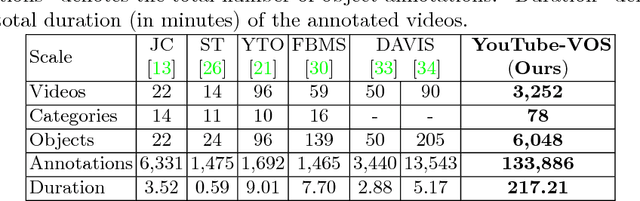

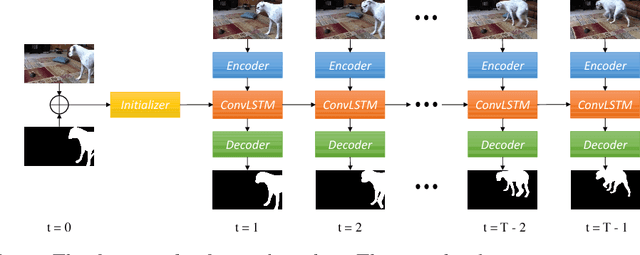
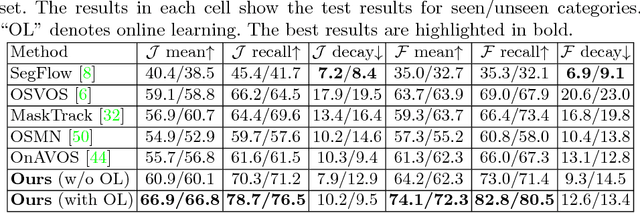
Learning long-term spatial-temporal features are critical for many video analysis tasks. However, existing video segmentation methods predominantly rely on static image segmentation techniques, and methods capturing temporal dependency for segmentation have to depend on pretrained optical flow models, leading to suboptimal solutions for the problem. End-to-end sequential learning to explore spatial-temporal features for video segmentation is largely limited by the scale of available video segmentation datasets, i.e., even the largest video segmentation dataset only contains 90 short video clips. To solve this problem, we build a new large-scale video object segmentation dataset called YouTube Video Object Segmentation dataset (YouTube-VOS). Our dataset contains 3,252 YouTube video clips and 78 categories including common objects and human activities. This is by far the largest video object segmentation dataset to our knowledge and we have released it at https://youtube-vos.org. Based on this dataset, we propose a novel sequence-to-sequence network to fully exploit long-term spatial-temporal information in videos for segmentation. We demonstrate that our method is able to achieve the best results on our YouTube-VOS test set and comparable results on DAVIS 2016 compared to the current state-of-the-art methods. Experiments show that the large scale dataset is indeed a key factor to the success of our model.
Learning Hierarchical Semantic Image Manipulation through Structured Representations
Aug 28, 2018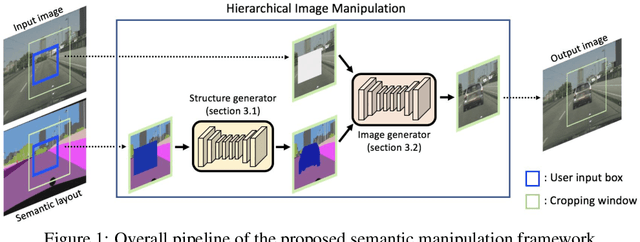


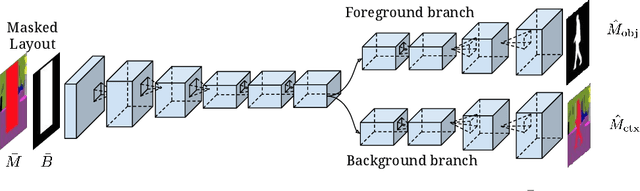
Understanding, reasoning, and manipulating semantic concepts of images have been a fundamental research problem for decades. Previous work mainly focused on direct manipulation on natural image manifold through color strokes, key-points, textures, and holes-to-fill. In this work, we present a novel hierarchical framework for semantic image manipulation. Key to our hierarchical framework is that we employ a structured semantic layout as our intermediate representation for manipulation. Initialized with coarse-level bounding boxes, our structure generator first creates pixel-wise semantic layout capturing the object shape, object-object interactions, and object-scene relations. Then our image generator fills in the pixel-level textures guided by the semantic layout. Such framework allows a user to manipulate images at object-level by adding, removing, and moving one bounding box at a time. Experimental evaluations demonstrate the advantages of the hierarchical manipulation framework over existing image generation and context hole-filing models, both qualitatively and quantitatively. Benefits of the hierarchical framework are further demonstrated in applications such as semantic object manipulation, interactive image editing, and data-driven image manipulation.
Wide Activation for Efficient and Accurate Image Super-Resolution
Aug 27, 2018
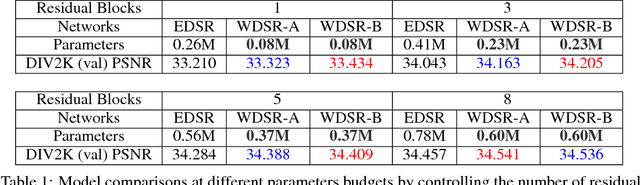

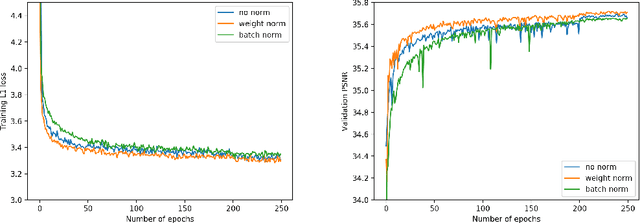
In this report we demonstrate that with same parameters and computational budgets, models with wider features before ReLU activation have significantly better performance for single image super-resolution (SISR). The resulted SR residual network has a slim identity mapping pathway with wider (\(2\times\) to \(4\times\)) channels before activation in each residual block. To further widen activation (\(6\times\) to \(9\times\)) without computational overhead, we introduce linear low-rank convolution into SR networks and achieve even better accuracy-efficiency tradeoffs. In addition, compared with batch normalization or no normalization, we find training with weight normalization leads to better accuracy for deep super-resolution networks. Our proposed SR network \textit{WDSR} achieves better results on large-scale DIV2K image super-resolution benchmark in terms of PSNR with same or lower computational complexity. Based on WDSR, our method also won 1st places in NTIRE 2018 Challenge on Single Image Super-Resolution in all three realistic tracks. Experiments and ablation studies support the importance of wide activation for image super-resolution. Code is released at: https://github.com/JiahuiYu/wdsr_ntire2018
Self-produced Guidance for Weakly-supervised Object Localization
Aug 05, 2018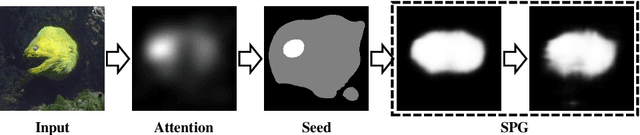
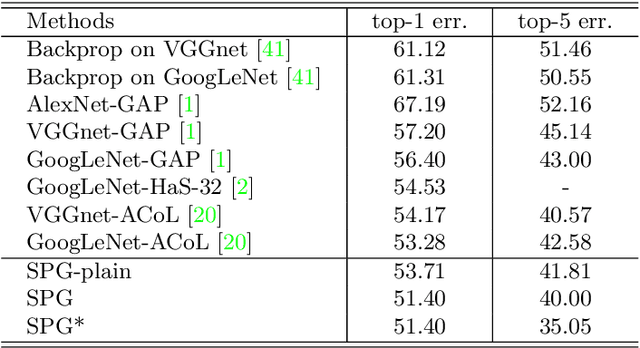
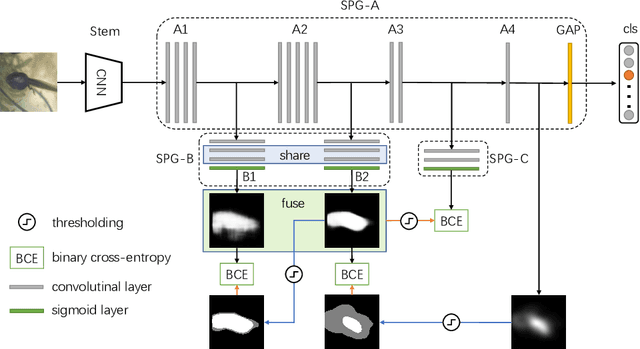
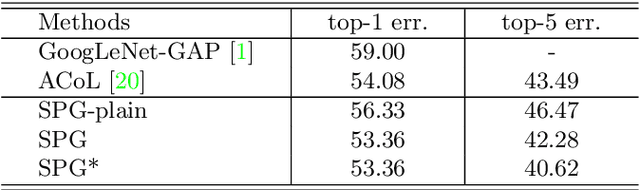
Weakly supervised methods usually generate localization results based on attention maps produced by classification networks. However, the attention maps exhibit the most discriminative parts of the object which are small and sparse. We propose to generate Self-produced Guidance (SPG) masks which separate the foreground, the object of interest, from the background to provide the classification networks with spatial correlation information of pixels. A stagewise approach is proposed to incorporate high confident object regions to learn the SPG masks. The high confident regions within attention maps are utilized to progressively learn the SPG masks. The masks are then used as an auxiliary pixel-level supervision to facilitate the training of classification networks. Extensive experiments on ILSVRC demonstrate that SPG is effective in producing high-quality object localizations maps. Particularly, the proposed SPG achieves the Top-1 localization error rate of 43.83% on the ILSVRC validation set, which is a new state-of-the-art error rate.
Revisiting RCNN: On Awakening the Classification Power of Faster RCNN
Jul 14, 2018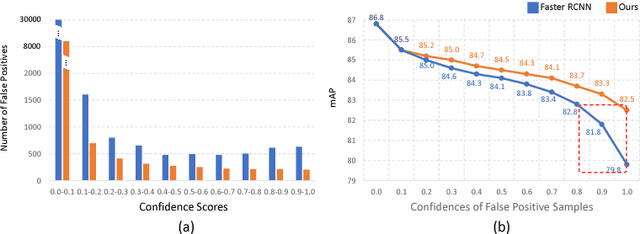
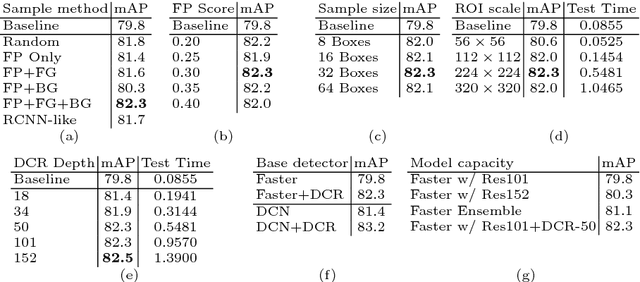
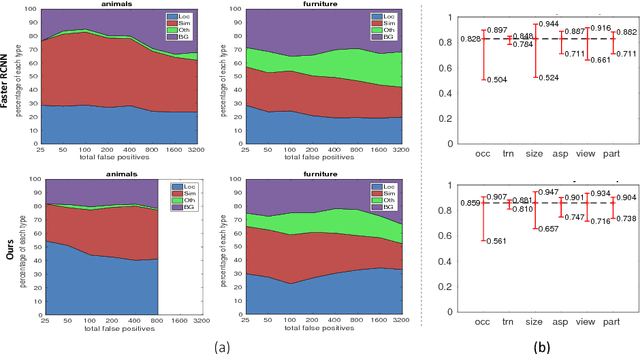
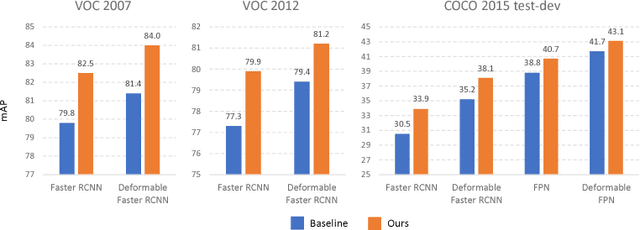
Recent region-based object detectors are usually built with separate classification and localization branches on top of shared feature extraction networks. In this paper, we analyze failure cases of state-of-the-art detectors and observe that most hard false positives result from classification instead of localization. We conjecture that: (1) Shared feature representation is not optimal due to the mismatched goals of feature learning for classification and localization; (2) multi-task learning helps, yet optimization of the multi-task loss may result in sub-optimal for individual tasks; (3) large receptive field for different scales leads to redundant context information for small objects.We demonstrate the potential of detector classification power by a simple, effective, and widely-applicable Decoupled Classification Refinement (DCR) network. DCR samples hard false positives from the base classifier in Faster RCNN and trains a RCNN-styled strong classifier. Experiments show new state-of-the-art results on PASCAL VOC and COCO without any bells and whistles.