 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPGNet: Semantic Prediction Guidance for Scene Parsing
Aug 26, 2019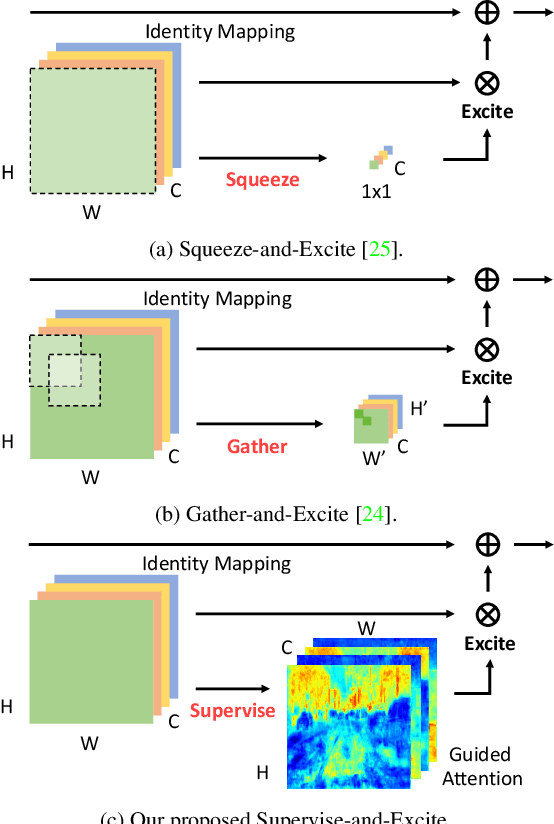
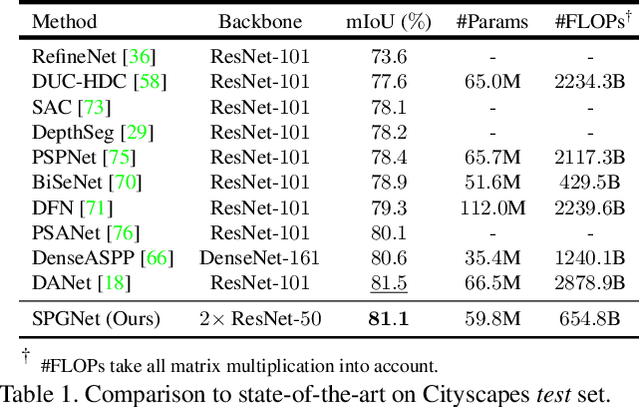
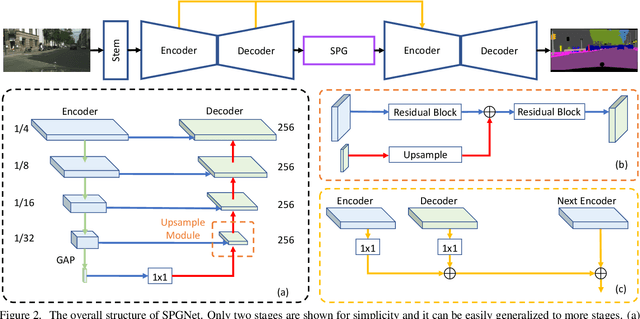

Multi-scale context module and single-stage encoder-decoder structure are commonly employed for semantic segmentation. The multi-scale context module refers to the operations to aggregate feature responses from a large spatial extent, while the single-stage encoder-decoder structure encodes the high-level semantic information in the encoder path and recovers the boundary information in the decoder path. In contrast, multi-stage encoder-decoder networks have been widely used in human pose estimation and show superior performance than their single-stage counterpart. However, few efforts have been attempted to bring this effective design to semantic segmentation. In this work, we propose a Semantic Prediction Guidance (SPG) module which learns to re-weight the local features through the guidance from pixel-wise semantic prediction. We find that by carefully re-weighting features across stages, a two-stage encoder-decoder network coupled with our proposed SPG module can significantly outperform its one-stage counterpart with similar parameters and computations. Finally, we report experimental results on the semantic segmentation benchmark Cityscapes, in which our SPGNet attains 81.1% on the test set using only 'fine' annotations.
SkyNet: A Champion Model for DAC-SDC on Low Power Object Detection
Jul 09, 2019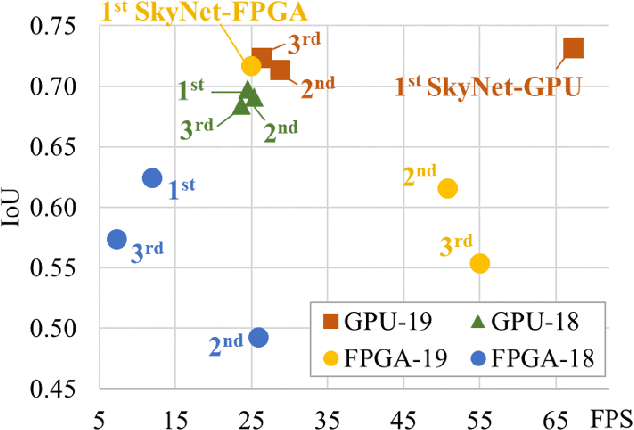
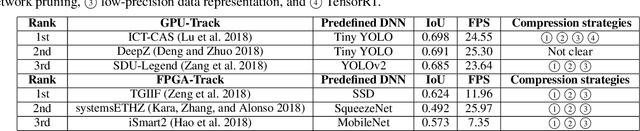

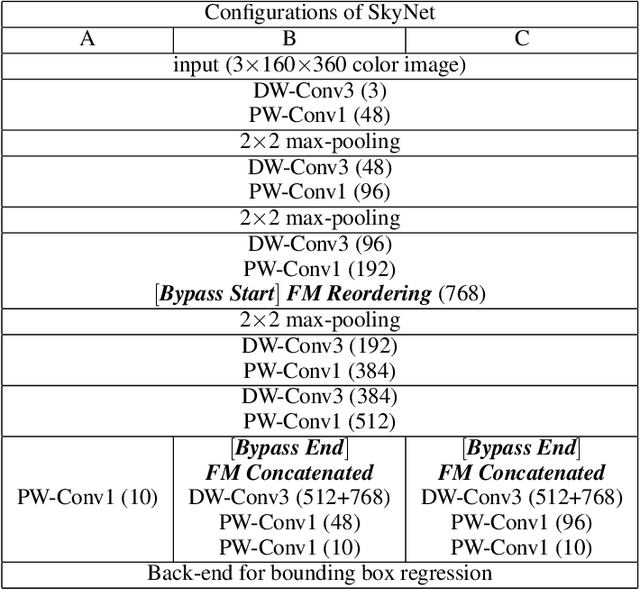
Developing artificial intelligence (AI) at the edge is always challenging, since edge devices have limited computation capability and memory resources but need to meet demanding requirements, such as real-time processing, high throughput performance, and high inference accuracy. To overcome these challenges, we propose SkyNet, an extremely lightweight DNN with 12 convolutional (Conv) layers and only 1.82 megabyte (MB) of parameters following a bottom-up DNN design approach. SkyNet is demonstrated in the 56th IEEE/ACM Design Automation Conference System Design Contest (DAC-SDC), a low power object detection challenge in images captured by unmanned aerial vehicles (UAVs). SkyNet won the first place award for both the GPU and FPGA tracks of the contest: we deliver 0.731 Intersection over Union (IoU) and 67.33 frames per second (FPS) on a TX2 GPU and deliver 0.716 IoU and 25.05 FPS on an Ultra96 FPGA.
High Frequency Residual Learning for Multi-Scale Image Classification
May 07, 2019

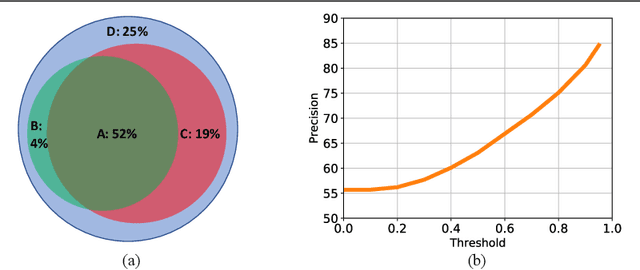
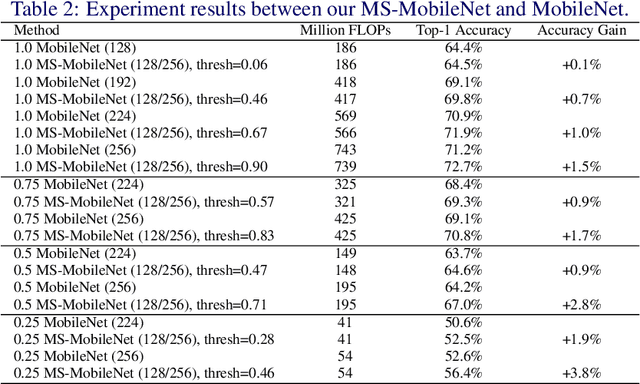
We present a novel high frequency residual learning framework, which leads to a highly efficient multi-scale network (MSNet) architecture for mobile and embedded vision problems. The architecture utilizes two networks: a low resolution network to efficiently approximate low frequency components and a high resolution network to learn high frequency residuals by reusing the upsampled low resolution features. With a classifier calibration module, MSNet can dynamically allocate computation resources during inference to achieve a better speed and accuracy trade-off. We evaluate our methods on the challenging ImageNet-1k dataset and observe consistent improvements over different base networks. On ResNet-18 and MobileNet with alpha=1.0, MSNet gains 1.5% accuracy over both architectures without increasing computations. On the more efficient MobileNet with alpha=0.25, our method gains 3.8% accuracy with the same amount of computations.
Towards Instance-level Image-to-Image Translation
May 05, 2019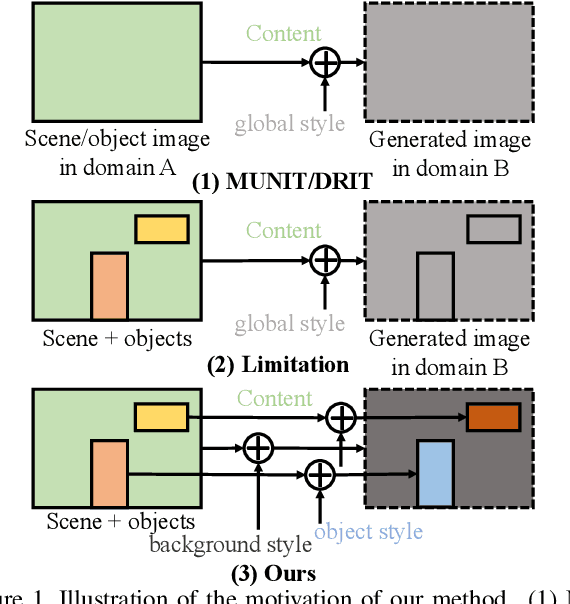
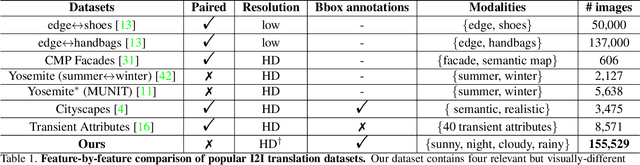
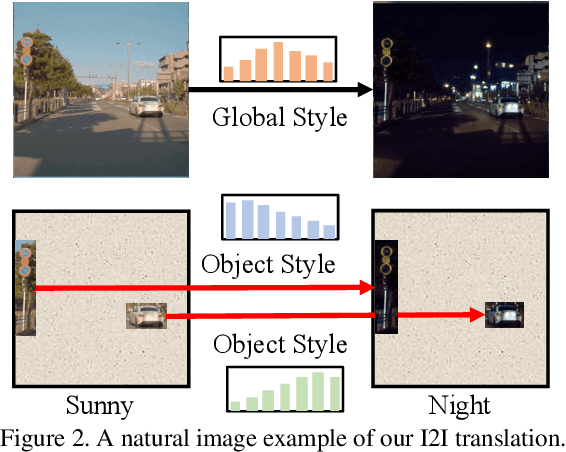
Unpaired Image-to-image Translation is a new rising and challenging vision problem that aims to learn a mapping between unaligned image pairs in diverse domains. Recent advances in this field like MUNIT and DRIT mainly focus on disentangling content and style/attribute from a given image first, then directly adopting the global style to guide the model to synthesize new domain images. However, this kind of approaches severely incurs contradiction if the target domain images are content-rich with multiple discrepant objects. In this paper, we present a simple yet effective instance-aware image-to-image translation approach (INIT), which employs the fine-grained local (instance) and global styles to the target image spatially. The proposed INIT exhibits three import advantages: (1) the instance-level objective loss can help learn a more accurate reconstruction and incorporate diverse attributes of objects; (2) the styles used for target domain of local/global areas are from corresponding spatial regions in source domain, which intuitively is a more reasonable mapping; (3) the joint training process can benefit both fine and coarse granularity and incorporates instance information to improve the quality of global translation. We also collect a large-scale benchmark for the new instance-level translation task. We observe that our synthetic images can even benefit real-world vision tasks like generic object detection.
When AWGN-based Denoiser Meets Real Noises
Apr 06, 2019
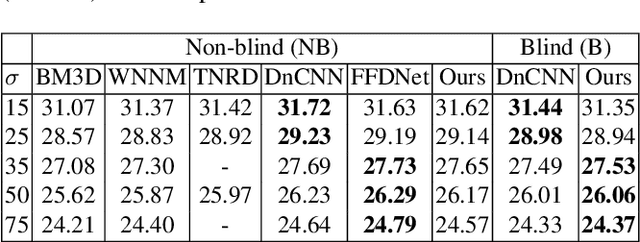

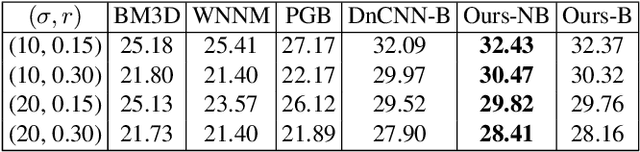
Discriminative learning based image denoisers have achieved promising performance on synthetic noise such as the additive Gaussian noise. However, their performance on images with real noise is often not satisfactory. The main reason is that real noises are mostly spatially/channel-correlated and spatial/channel-variant. In contrast, the synthetic Additive White Gaussian Noise (AWGN) adopted in most previous work is pixel-independent. In this paper, we propose a novel approach to boost the performance of a real image denoiser which is trained only with synthetic pixel-independent noise data. First, we train a deep model that consists of a noise estimator and a denoiser with mixed AWGN and Random Value Impulse Noise (RVIN). We then investigate Pixel-shuffle Down-sampling (PD) strategy to adapt the trained model to real noises. Extensive experiments demonstrate the effectiveness and generalization ability of the proposed approach. Notably, our method achieves state-of-the-art performance on real sRGB images in the DND benchmark. Codes are available at https://github.com/yzhouas/PD-Denoising-pytorch.
Network Slimming by Slimmable Networks: Towards One-Shot Architecture Search for Channel Numbers
Mar 27, 2019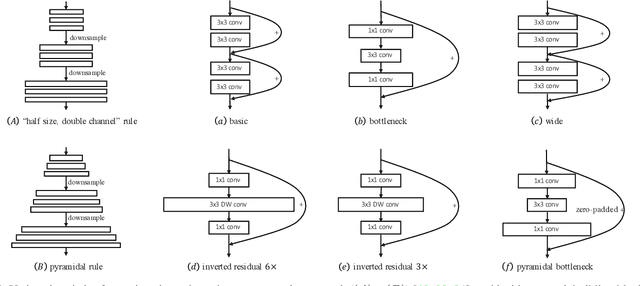
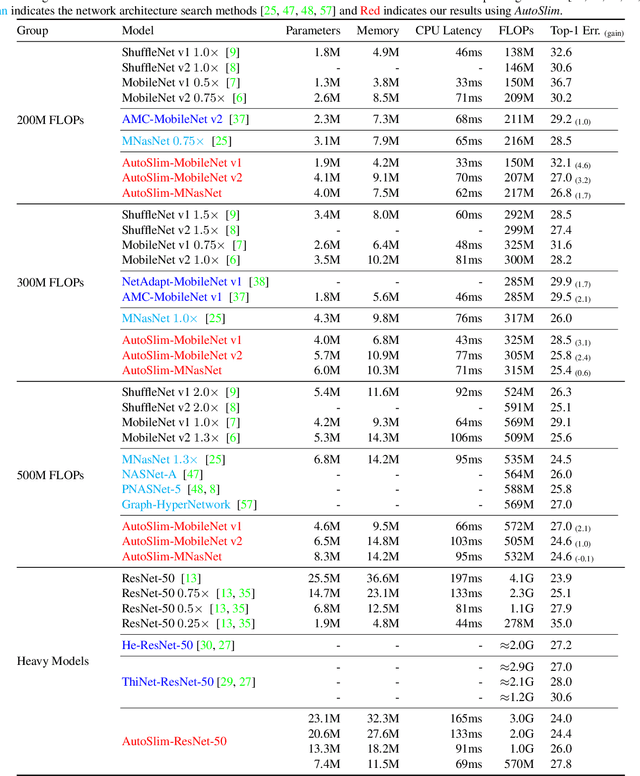
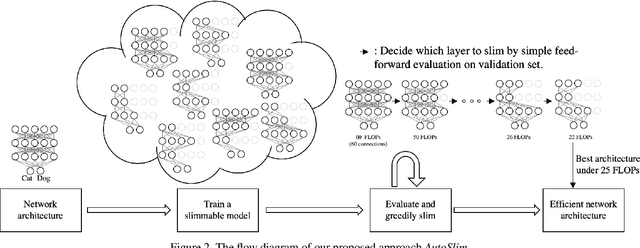
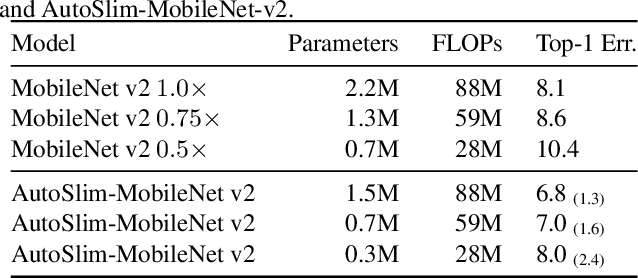
We study how to set channel numbers in a neural network to achieve better accuracy under constrained resources (e.g., FLOPs, latency, memory footprint or model size). A simple and one-shot solution, named AutoSlim, is presented. Instead of training many network samples and searching with reinforcement learning, we train a single slimmable network to approximate the network accuracy of different channel configurations. We then iteratively evaluate the trained slimmable model and greedily slim the layer with minimal accuracy drop. By this single pass, we can obtain the optimized channel configurations under different resource constraints. We present experiments with MobileNet v1, MobileNet v2, ResNet-50 and RL-searched MNasNet on ImageNet classification. We show significant improvements over their default channel configurations. We also achieve better accuracy than recent channel pruning methods and neural architecture search methods. Notably, by setting optimized channel numbers, our AutoSlim-MobileNet-v2 at 305M FLOPs achieves 74.2% top-1 accuracy, 2.4% better than default MobileNet-v2 (301M FLOPs), and even 0.2% better than RL-searched MNasNet (317M FLOPs). Our AutoSlim-ResNet-50 at 570M FLOPs, without depthwise convolutions, achieves 1.3% better accuracy than MobileNet-v1 (569M FLOPs). Code and models will be available at: https://github.com/JiahuiYu/slimmable_networks
Universally Slimmable Networks and Improved Training Techniques
Mar 12, 2019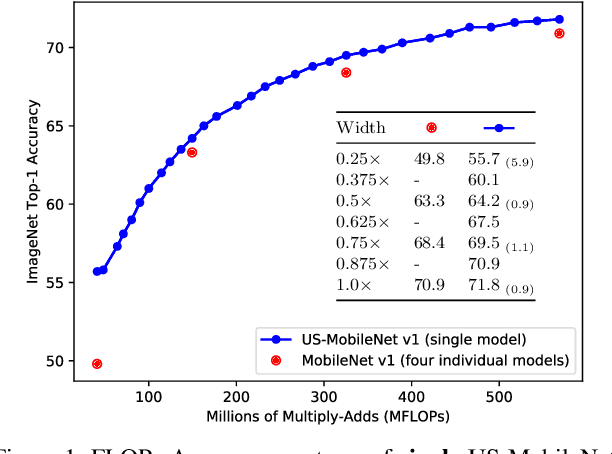
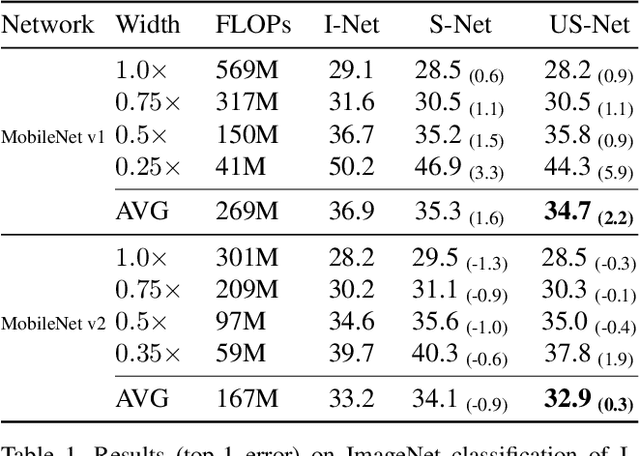

Slimmable networks are a family of neural networks that can instantly adjust the runtime width. The width can be chosen from a predefined widths set to adaptively optimize accuracy-efficiency trade-offs at runtime. In this work, we propose a systematic approach to train universally slimmable networks (US-Nets), extending slimmable networks to execute at arbitrary width, and generalizing to networks both with and without batch normalization layers. We further propose two improved training techniques for US-Nets, named the sandwich rule and inplace distillation, to enhance training process and boost testing accuracy. We show improved performance of universally slimmable MobileNet v1 and MobileNet v2 on ImageNet classification task, compared with individually trained ones and 4-switch slimmable network baselines. We also evaluate the proposed US-Nets and improved training techniques on tasks of image super-resolution and deep reinforcement learning. Extensive ablation experiments on these representative tasks demonstrate the effectiveness of our proposed methods. Our discovery opens up the possibility to directly evaluate FLOPs-Accuracy spectrum of network architectures. Code and models will be available at: https://github.com/JiahuiYu/slimmable_networks
Slimmable Neural Networks
Dec 21, 2018
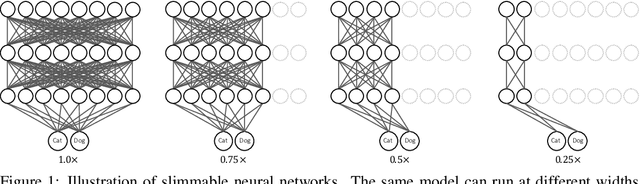

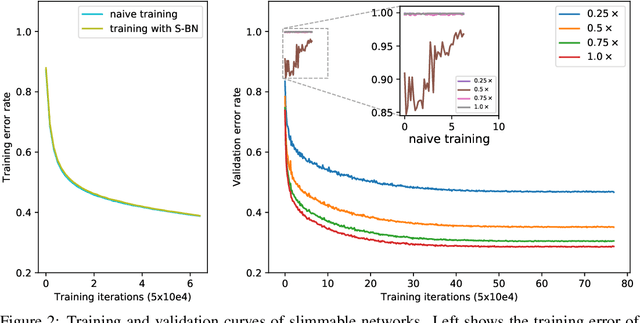
We present a simple and general method to train a single neural network executable at different widths (number of channels in a layer), permitting instant and adaptive accuracy-efficiency trade-offs at runtime. Instead of training individual networks with different width configurations, we train a shared network with switchable batch normalization. At runtime, the network can adjust its width on the fly according to on-device benchmarks and resource constraints, rather than downloading and offloading different models. Our trained networks, named slimmable neural networks, achieve similar (and in many cases better) ImageNet classification accuracy than individually trained models of MobileNet v1, MobileNet v2, ShuffleNet and ResNet-50 at different widths respectively. We also demonstrate better performance of slimmable models compared with individual ones across a wide range of applications including COCO bounding-box object detection, instance segmentation and person keypoint detection without tuning hyper-parameters. Lastly we visualize and discuss the learned features of slimmable networks. Code and models are available at: https://github.com/JiahuiYu/slimmable_networks
One Shot Domain Adaptation for Person Re-Identification
Nov 26, 2018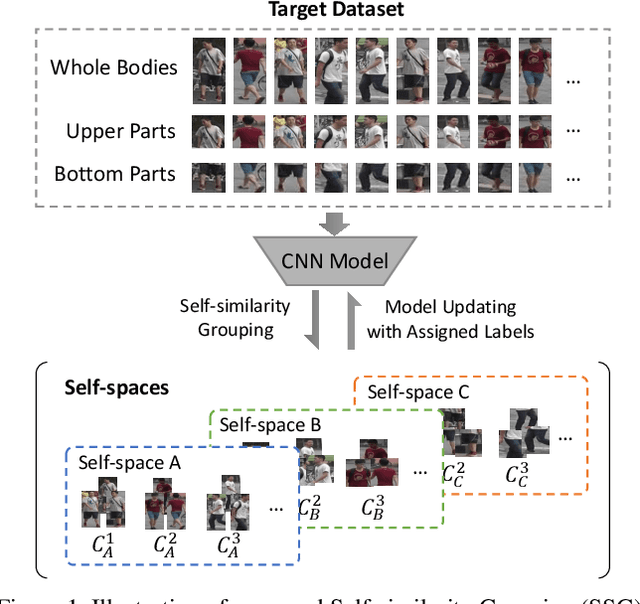
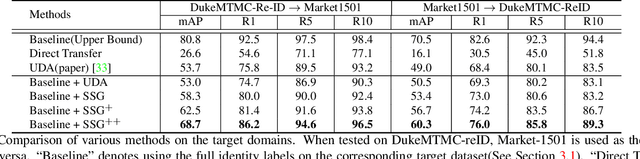
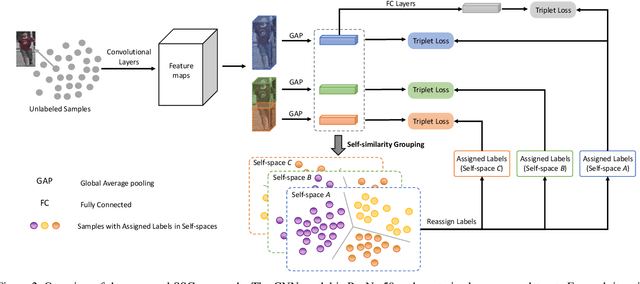
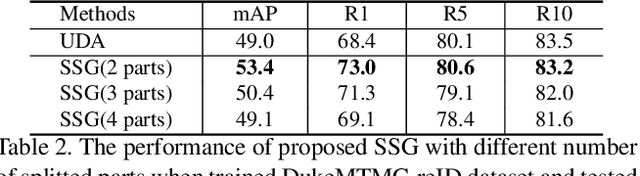
How to effectively address the domain adaptation problem is a challenging task for person re-identification (reID). In this work, we make the first endeavour to tackle this issue according to one shot learning. Given an annotated source training set and a target training set that only one instance for each category is annotated, we aim to achieve competitive re-ID performance on the testing set of the target domain. To this end, we introduce a similarity-guided strategy to progressively assign pseudo labels to unlabeled instances with different confidence scores, which are in turn leveraged as weights to guide the optimization as training goes on. Collaborating with a simple self-mining operation, we make significant improvement in the domain adaptation tasks of re-ID. In particular, we achieve the mAP of 71.5% in the adaptation task of DukeMTMC-reID to Market1501 with one shot setting, which outperforms the state-of-arts of unsupervised domain adaptation more than 17.8%. Under the five shots setting, we achieve competitive accuracy of the fully supervised setting on Market-1501. Code will be made available.
STA: Spatial-Temporal Attention for Large-Scale Video-based Person Re-Identification
Nov 09, 2018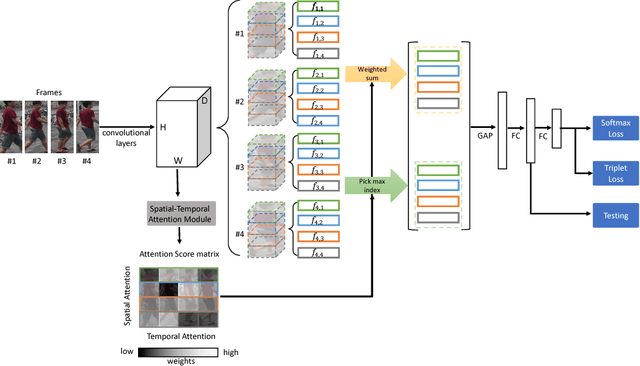
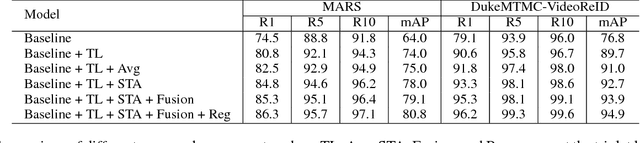
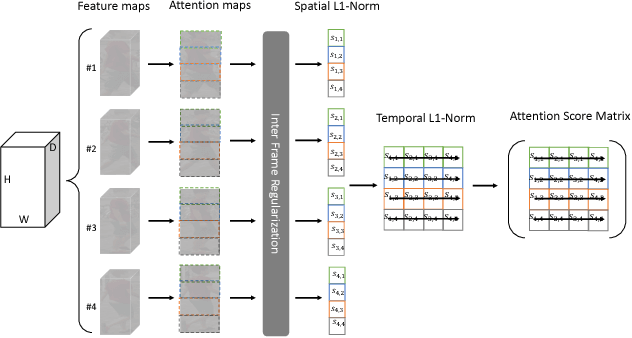
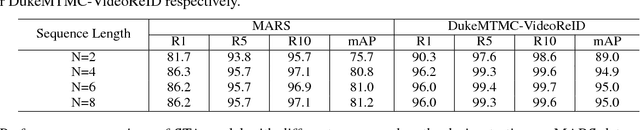
In this work, we propose a novel Spatial-Temporal Attention (STA) approach to tackle the large-scale person re-identification task in videos. Different from the most existing methods, which simply compute representations of video clips using frame-level aggregation (e.g. average pooling), the proposed STA adopts a more effective way for producing robust clip-level feature representation. Concretely, our STA fully exploits those discriminative parts of one target person in both spatial and temporal dimensions, which results in a 2-D attention score matrix via inter-frame regularization to measure the importances of spatial parts across different frames. Thus, a more robust clip-level feature representation can be generated according to a weighted sum operation guided by the mined 2-D attention score matrix. In this way, the challenging cases for video-based person re-identification such as pose variation and partial occlusion can be well tackled by the STA. We conduct extensive experiments on two large-scale benchmarks, i.e. MARS and DukeMTMC-VideoReID. In particular, the mAP reaches 87.7% on MARS, which significantly outperforms the state-of-the-arts with a large margin of more than 11.6%.